AWS MLA無料問題集です。正解と解説を確認する際は右側のボタンを押下してください。
問題集の完全版は以下Udemyにて発売しているためお買い求めください。問題集への質問はUdemyのQA機能もしくはUdemyのメッセージにて承ります。Udemyの問題1から10問抜粋しております。
多くの方にご好評いただき、講師評価 4.5/5.0 を獲得できております。ありがとうございます。

特別価格: 通常2,600円 → 1,500円
講師クーポン適用で42%OFF
この資格を活かしたキャリア情報
MLA資格の取得後にどんなキャリアが開けるか、詳しくはこちら:
→ MLA合格者の転職市場価値と求人傾向
AWS資格全体のキャリア活用法:
→ AWS資格は転職・キャリアアップでどう活きる?資格別市場価値と実体験
講師クーポン【図解付き詳細解説】AWS MLA-C01完全攻略問題集 | 構成図&グラフ解説付き

問題文:
ある医療画像診断企業がAmazon SageMakerを使用してWebベースのAI診断支援アプリケーションを構築しています。このアプリケーションは、ML実験、トレーニング、中央モデルレジストリ、モデルデプロイ、モデル監視の機能を提供します。アプリケーションは、MLライフサイクル中にトレーニングデータの安全で分離された使用を確保する必要があります。トレーニングデータはAmazon S3に保存されています。企業は、アプリケーション内で異なるバージョンの診断モデルを管理するために中央モデルレジストリを使用する必要があります。最小限の運用オーバーヘッドでこの要件を満たすには、どのアクションを実行すればよいですか。
選択肢:
A. 各診断モデルに対して個別のAmazon Elastic Container Registry(Amazon ECR)リポジトリを作成する。
B. Amazon Elastic Container Registry(Amazon ECR)と各モデルバージョン用の一意のタグを使用する。
C. SageMaker Model Registryとモデルグループを使用してモデルをカタログ化する。
D. SageMaker Model Registryと各モデルバージョン用の一意のタグを使用する。
正解:C
A. 各診断モデルに対して個別のAmazon Elastic Container Registry(Amazon ECR)リポジトリを作成する。
不正解 Amazon ECRはコンテナイメージを保存するためのサービスであり、モデルのバージョン管理やカタログ化には適していません。各モデルごとにリポジトリを作成する方法は運用オーバーヘッドが大きく、モデルレジストリとしての機能も限定的です。
B. Amazon Elastic Container Registry(Amazon ECR)と各モデルバージョン用の一意のタグを使用する。
不正解 ECRはコンテナイメージのレジストリであり、SageMakerモデルの管理には専用のサービスを使用する方が適切です。タグによる管理は運用オーバーヘッドが大きく、モデルのバージョン管理や承認ワークフローなどの機能も提供されません。
C. SageMaker Model Registryとモデルグループを使用してモデルをカタログ化する。
正解 SageMaker Model Registryは、モデルのバージョン管理、メタデータの保存、承認ワークフローの実装など、モデル管理に必要な機能を提供するマネージドサービスです。モデルグループを使用することで、関連するモデルを論理的にグループ化し、各モデルバージョンを効率的に管理できます。運用オーバーヘッドが最小限で、SageMakerの他の機能と統合されています。
D. SageMaker Model Registryと各モデルバージョン用の一意のタグを使用する。
不正解 SageMaker Model Registryはモデルグループの概念を提供しており、タグによる管理よりも構造化された方法でモデルを管理できます。タグのみに依存する方法は、モデルグループの機能を活用できず、運用オーバーヘッドも大きくなります。
全体的な説明
問われている要件
- 中央モデルレジストリを使用して異なるバージョンの診断モデルを管理する
- 最小限の運用オーバーヘッドで実現する
- SageMakerベースのAI診断支援アプリケーションに統合する
- モデルのバージョン管理とカタログ化を効率的に行う
前提知識
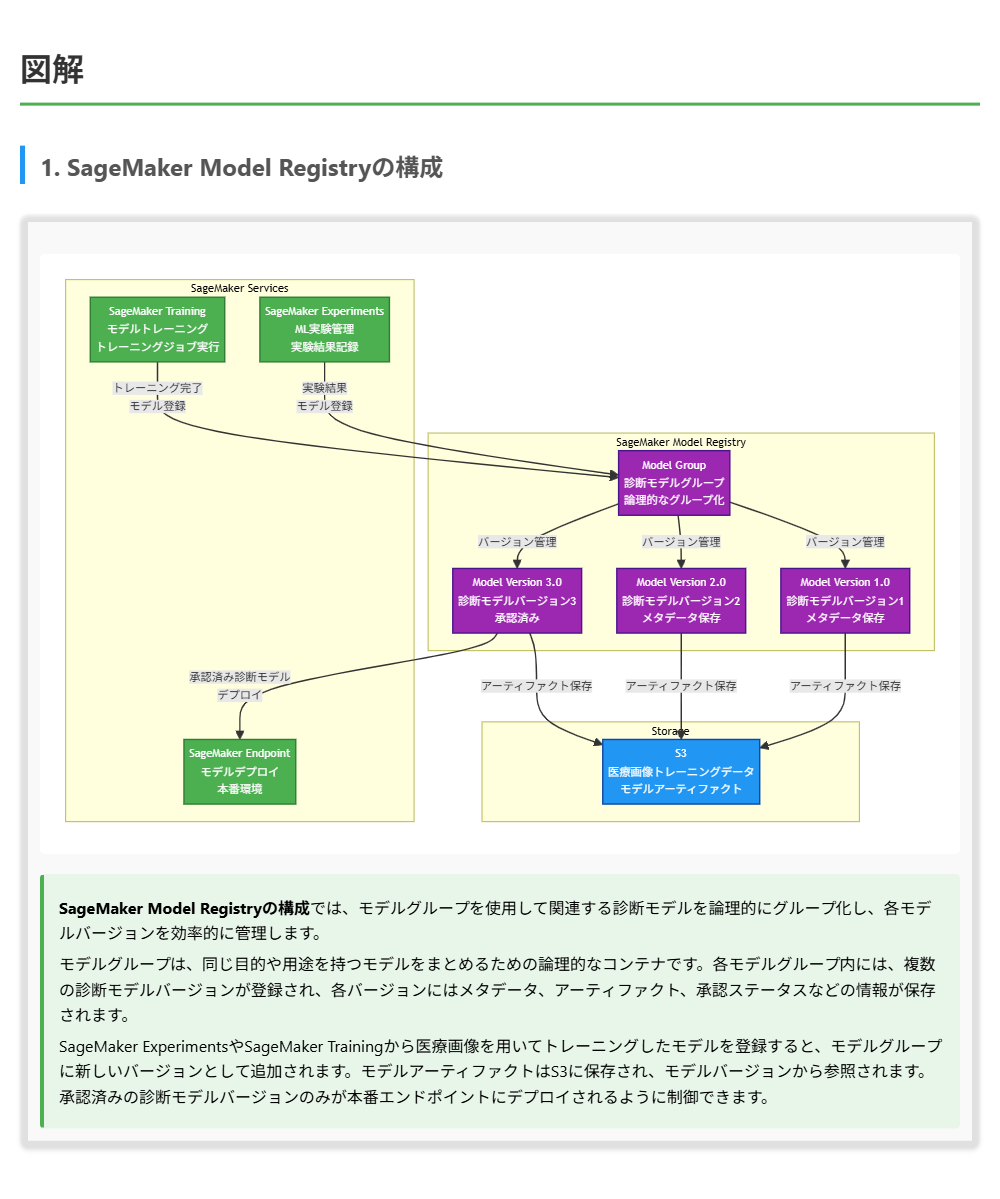
SageMaker Model Registryについて
SageMaker Model Registryは、機械学習モデルのライフサイクル管理を支援するマネージドサービスです。モデルグループを使用して関連するモデルを論理的にグループ化し、各モデルバージョンのメタデータ、アーティファクト、承認ステータスを管理できます。モデルバージョンごとに説明、メトリクス、承認ステータスなどの情報を保存し、承認ワークフローを実装することで、本番環境へのデプロイを制御できます。SageMaker PipelinesやSageMaker Experimentsと統合されており、MLOpsワークフローに組み込みやすい設計となっています。
Amazon ECRについて
Amazon ECRは、Dockerコンテナイメージを保存、管理、デプロイするためのマネージドコンテナレジストリサービスです。ECRはコンテナイメージのバージョン管理やタグ付けをサポートしていますが、機械学習モデル専用の機能は提供していません。モデルのメタデータ管理、承認ワークフロー、モデル監視との統合などの機能はなく、モデルレジストリとして使用するには不十分です。
モデル管理の運用オーバーヘッドについて
運用オーバーヘッドとは、システムを運用するために必要な手作業や管理作業の量を指します。専用のマネージドサービスを使用することで、インフラストラクチャの管理、スケーリング、セキュリティパッチの適用などの作業をAWSに委ねることができ、運用オーバーヘッドを削減できます。カスタムソリューションや汎用サービスを組み合わせて実装する場合、これらの作業を自社で行う必要があり、運用オーバーヘッドが増加します。
解くための考え方
この問題では、中央モデルレジストリを使用してモデルのバージョン管理を行う必要があり、かつ最小限の運用オーバーヘッドで実現することが求められています。
SageMaker Model Registryは、モデル管理に特化したマネージドサービスであり、モデルグループの概念を使用してモデルを論理的にグループ化し、各モデルバージョンを効率的に管理できます。モデルバージョンごとのメタデータ管理、承認ワークフローの実装、SageMakerの他の機能との統合など、モデル管理に必要な機能が一元的に提供されています。マネージドサービスであるため、インフラストラクチャの管理やスケーリングなどの運用作業が不要で、運用オーバーヘッドが最小限です。
一方、Amazon ECRを使用する方法は、コンテナイメージの保存には適していますが、モデル管理に特化した機能は提供されていません。各モデルごとにリポジトリを作成する方法や、タグを使用して管理する方法は、運用オーバーヘッドが大きく、モデルのバージョン管理や承認ワークフローなどの機能も実装する必要があります。
したがって、最小限の運用オーバーヘッドで中央モデルレジストリを実現するには、SageMaker Model Registryとモデルグループを使用することが最適解となります。
参考資料
問題文:
あるゲーム開発企業がAmazon SageMakerを使用してWebベースのAIアプリケーションを構築しています。このアプリケーションは、ML実験、トレーニング、中央モデルレジストリ、モデルデプロイ、モデル監視の機能を提供します。アプリケーションは、MLライフサイクル中にトレーニングデータの安全で分離された使用を確保する必要があります。トレーニングデータはAmazon S3に保存されています。企業はプレイヤー行動予測モデルの改善のため、連続したトレーニングジョブを実験しています。これらのジョブのインフラストラクチャ起動時間を最小限に抑えるには、どのようにすればよいですか。
選択肢:
A. Managed Spot Trainingを使用する。
B. SageMaker managed warm poolsを使用する。
C. SageMaker Training Compilerを使用する。
D. SageMaker distributed data parallelism(SMDDP)ライブラリを使用する。
正解:B
A. Managed Spot Trainingを使用する。
不正解 Managed Spot Trainingは、未使用のEC2インスタンスを利用してトレーニングコストを削減する機能です。起動時間の短縮ではなく、コスト削減が主な目的であり、インスタンスが中断される可能性があるため、連続したトレーニングジョブの起動時間を最小限に抑えるには適していません。
B. SageMaker managed warm poolsを使用する。
正解 SageMaker managed warm poolsは、トレーニングジョブの実行に使用されるコンピューティングリソースを事前にウォームアップ状態で保持する機能です。連続したトレーニングジョブを送信すると、SageMakerは自動的にウォームプールからインスタンスを再利用するため、インスタンスの起動や初期化にかかる時間を大幅に短縮できます。これにより、インフラストラクチャの起動時間を最小限に抑えることができます。
C. SageMaker Training Compilerを使用する。
不正解 SageMaker Training Compilerは、トレーニングスクリプトを最適化してトレーニング時間を短縮するコンパイラです。インフラストラクチャの起動時間ではなく、トレーニングの実行時間を短縮するための機能であり、連続したトレーニングジョブの起動時間を最小限に抑える目的には適していません。
D. SageMaker distributed data parallelism(SMDDP)ライブラリを使用する。
不正解 SMDDPライブラリは、大規模なデータセットに対して分散データ並列トレーニングを実行するためのライブラリです。トレーニングのパフォーマンス向上が主な目的であり、インフラストラクチャの起動時間を短縮する機能は提供していません。
全体的な説明
問われている要件
- 連続したトレーニングジョブのインフラストラクチャ起動時間を最小限に抑える
- 実験段階での複数のトレーニングジョブを効率的に実行する
- 起動時間の短縮により、実験のサイクル時間を短縮する
- 運用オーバーヘッドを最小限に抑える
前提知識
SageMaker managed warm poolsについて
SageMaker managed warm poolsは、トレーニングジョブの実行に使用されるコンピューティングリソースを事前にウォームアップ状態で保持する機能です。ウォームプールに保持されたインスタンスは、起動と初期化が完了した状態で待機しており、新しいトレーニングジョブが送信されると、これらのインスタンスを即座に再利用できます。これにより、インスタンスの起動、AMIの読み込み、コンテナイメージのダウンロード、ネットワークの初期化などにかかる時間を大幅に短縮できます。連続したトレーニングジョブを送信する場合、SageMakerは自動的にウォームプールからインスタンスを再利用するため、各ジョブの起動時間が短縮されます。ウォームプールは、トレーニングジョブの終了後も一定期間保持され、後続のジョブで再利用されます。
Managed Spot Trainingについて
Managed Spot Trainingは、未使用のEC2 Spotインスタンスを利用してトレーニングコストを最大90%削減する機能です。Spotインスタンスは中断される可能性があるため、チェックポイント機能を使用してトレーニングの状態を保存し、中断後に再開できるようになっています。コスト削減が主な目的であり、起動時間の短縮は期待できません。むしろ、Spotインスタンスの割り当て待ちや中断による再起動により、トレーニング時間が延長される可能性があります。
SageMaker Training Compilerについて
SageMaker Training Compilerは、PyTorchやTensorFlowのトレーニングスクリプトを最適化して、トレーニング時間を最大50%短縮するコンパイラです。トレーニングスクリプトのコンパイルと最適化により、GPUの利用率を向上させ、トレーニングの実行時間を短縮します。インフラストラクチャの起動時間には影響せず、トレーニングの実行フェーズでの最適化に焦点を当てています。
SageMaker distributed data parallelism(SMDDP)について
SMDDPライブラリは、大規模なデータセットに対して複数のGPUやインスタンスを使用して分散データ並列トレーニングを実行するためのライブラリです。データを複数のワーカーに分散し、各ワーカーでモデルのコピーをトレーニングすることで、トレーニング時間を短縮します。トレーニングのパフォーマンス向上が主な目的であり、インフラストラクチャの起動時間を短縮する機能は提供していません。
解くための考え方
この問題では、連続したトレーニングジョブのインフラストラクチャ起動時間を最小限に抑えることが求められています。
通常、トレーニングジョブを実行する際には、EC2インスタンスの起動、AMIの読み込み、コンテナイメージのダウンロード、ネットワークの初期化など、複数のステップが必要です。これらのステップには数分から十数分の時間がかかることがあり、連続して複数のトレーニングジョブを実行する場合、各ジョブごとにこの起動時間が発生することになります。
SageMaker managed warm poolsを使用すると、これらの初期化が完了したインスタンスを事前にウォームアップ状態で保持できます。連続したトレーニングジョブを送信すると、SageMakerは自動的にウォームプールからインスタンスを再利用するため、起動や初期化にかかる時間を大幅に短縮できます。これにより、実験のサイクル時間を短縮し、より迅速に結果を得ることができます。
一方、Managed Spot Trainingはコスト削減が主な目的であり、起動時間の短縮には寄与しません。SageMaker Training CompilerやSMDDPライブラリは、トレーニングの実行時間を短縮するための機能であり、インフラストラクチャの起動時間には影響しません。
したがって、連続したトレーニングジョブのインフラストラクチャ起動時間を最小限に抑えるには、SageMaker managed warm poolsを使用することが最適解となります。
参考資料
問題文:
ある物流企業がAmazon SageMakerを使用してWebベースの需要予測AIアプリケーションを構築しています。このアプリケーションは、ML実験、トレーニング、中央モデルレジストリ、モデルデプロイ、モデル監視の機能を提供します。アプリケーションは、MLライフサイクル中にトレーニングデータの安全で分離された使用を確保する必要があります。トレーニングデータはAmazon S3に保存されています。企業は、承認されたモデルのみが本番エンドポイントにデプロイされることを確保するための手動承認ベースのワークフローを実装する必要があります。この要件を満たすソリューションはどれですか。
選択肢:
A. モデル登録時に承認プロセスを促進するためにSageMaker Experimentsを使用する。
B. 中央モデルレジストリでSageMaker ML Lineage Trackingを使用し、承認プロセスの追跡エンティティを作成する。
C. モデルのパフォーマンスを評価し、承認を管理するためにSageMaker Model Monitorを使用する。
D. SageMaker Pipelinesを使用する。モデルバージョンが登録されたら、AWS SDKを使用して承認ステータスを「承認済み」に変更する。
正解:D
A. モデル登録時に承認プロセスを促進するためにSageMaker Experimentsを使用する。
不正解 SageMaker Experimentsは、ML実験の実行、パラメータの追跡、メトリクスの記録などの機能を提供しますが、モデルの承認ワークフローやデプロイメントの制御機能は提供していません。実験の管理と追跡が主な目的であり、承認ベースのデプロイメントワークフローを実装するには不十分です。
B. 中央モデルレジストリでSageMaker ML Lineage Trackingを使用し、承認プロセスの追跡エンティティを作成する。
不正解 SageMaker ML Lineage Trackingは、MLアーティファクト間の関係を追跡し、データの出所や変換履歴を記録する機能です。モデルの承認ステータスを追跡することはできますが、承認ワークフローを実装したり、承認されていないモデルのデプロイメントを制御したりする機能は提供していません。
C. モデルのパフォーマンスを評価し、承認を管理するためにSageMaker Model Monitorを使用する。
不正解 SageMaker Model Monitorは、デプロイされたモデルのパフォーマンスを監視し、データドリフトや品質の問題を検出する機能です。モデルの監視が主な目的であり、デプロイ前の承認ワークフローを実装したり、承認されていないモデルのデプロイメントを制御したりする機能は提供していません。
D. SageMaker Pipelinesを使用する。モデルバージョンが登録されたら、AWS SDKを使用して承認ステータスを「承認済み」に変更する。
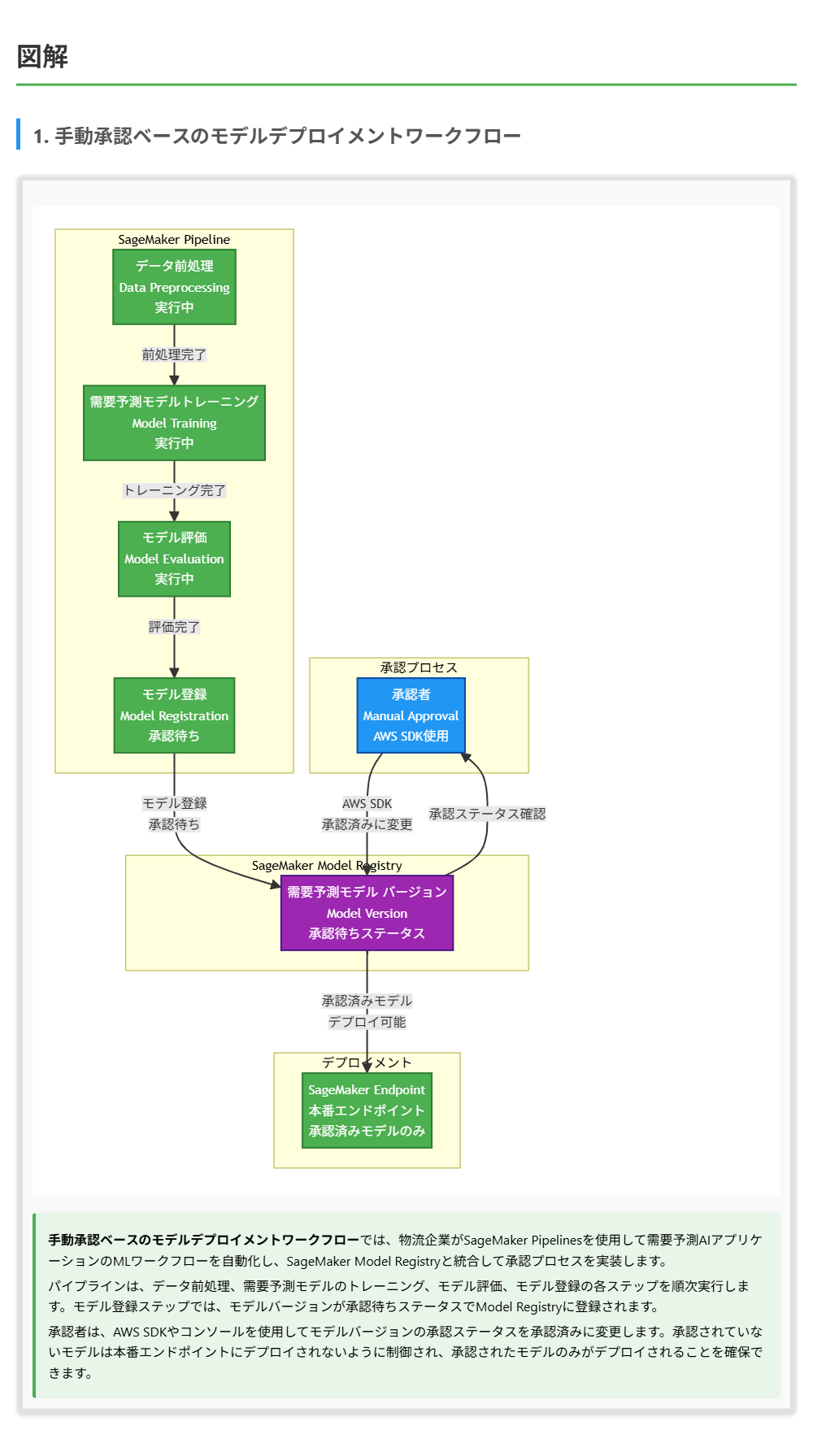
正解 SageMaker Pipelinesは、MLワークフローを自動化するためのサービスであり、モデルのトレーニング、評価、登録、デプロイメントなどのステップをパイプラインとして定義できます。SageMaker Model Registryと統合されており、モデルバージョンが登録された後、AWS SDKを使用して承認ステータスを承認済みに変更することで、手動承認ベースのワークフローを実装できます。承認されていないモデルは本番エンドポイントにデプロイされないように制御でき、承認されたモデルのみがデプロイされることを確保できます。
全体的な説明
問われている要件
- 手動承認ベースのワークフローを実装する
- 承認されたモデルのみが本番エンドポイントにデプロイされることを確保する
- モデル登録後の承認プロセスを制御する
- 承認されていないモデルのデプロイメントを防止する
前提知識
SageMaker Pipelinesについて
SageMaker Pipelinesは、MLワークフローを自動化するためのマネージドサービスです。データの前処理、モデルのトレーニング、評価、登録、デプロイメントなどのステップをパイプラインとして定義し、実行を自動化できます。パイプラインは、条件分岐、パラメータの受け渡し、エラーハンドリングなどの機能をサポートしており、複雑なワークフローを実装できます。SageMaker Model Registryと統合されており、モデルバージョンの登録や承認ステータスの管理を自動化できます。AWS SDKを使用して、パイプラインの実行中や実行後に承認ステータスを変更することで、手動承認ベースのワークフローを実装できます。
SageMaker Model Registryの承認ステータスについて
SageMaker Model Registryでは、各モデルバージョンに承認ステータスを設定できます。承認ステータスには、手動承認待ち、承認済み、却下などの値があります。承認ステータスが承認済みに設定されていないモデルは、本番エンドポイントにデプロイされないように制御できます。AWS SDKを使用して、モデルバージョンの承認ステータスをプログラム的に変更でき、手動承認プロセスを実装できます。
SageMaker Experimentsについて
SageMaker Experimentsは、ML実験の実行、パラメータの追跡、メトリクスの記録、実験の比較などの機能を提供するサービスです。実験の管理と追跡が主な目的であり、モデルの承認ワークフローやデプロイメントの制御機能は提供していません。実験の結果を記録し、最適なモデルを選択するための情報を提供しますが、承認ベースのデプロイメントワークフローを実装するには不十分です。
SageMaker ML Lineage Trackingについて
SageMaker ML Lineage Trackingは、MLアーティファクト間の関係を追跡し、データの出所や変換履歴を記録する機能です。モデルのトレーニングに使用されたデータセット、前処理スクリプト、トレーニングジョブ、評価結果などの関係を追跡し、モデルの再現性や監査性を向上させます。モデルの承認ステータスを追跡することはできますが、承認ワークフローを実装したり、承認されていないモデルのデプロイメントを制御したりする機能は提供していません。
SageMaker Model Monitorについて
SageMaker Model Monitorは、デプロイされたモデルのパフォーマンスを監視し、データドリフトや品質の問題を検出する機能です。本番環境でモデルが期待通りに動作しているかを継続的に監視し、問題が検出された場合にアラートを送信します。モデルの監視が主な目的であり、デプロイ前の承認ワークフローを実装したり、承認されていないモデルのデプロイメントを制御したりする機能は提供していません。
解くための考え方
この問題では、手動承認ベースのワークフローを実装し、承認されたモデルのみが本番エンドポイントにデプロイされることを確保する必要があります。
SageMaker Pipelinesは、MLワークフローを自動化するためのサービスであり、SageMaker Model Registryと統合されています。モデルバージョンが登録された後、AWS SDKを使用して承認ステータスを承認済みに変更することで、手動承認ベースのワークフローを実装できます。パイプラインの実行中に、承認待ちの状態でモデルを登録し、承認者がAWS SDKやコンソールを使用して承認ステータスを承認済みに変更するまでの間、モデルのデプロイメントを制御できます。承認されていないモデルは本番エンドポイントにデプロイされないように制御でき、承認されたモデルのみがデプロイされることを確保できます。
一方、SageMaker Experimentsは実験の管理と追跡が主な目的であり、承認ワークフローやデプロイメントの制御機能は提供していません。SageMaker ML Lineage Trackingは、モデルの承認ステータスを追跡することはできますが、承認ワークフローを実装したり、デプロイメントを制御したりする機能は提供していません。SageMaker Model Monitorは、デプロイ後の監視が主な目的であり、デプロイ前の承認ワークフローを実装する機能は提供していません。
したがって、手動承認ベースのワークフローを実装し、承認されたモデルのみが本番エンドポイントにデプロイされることを確保するには、SageMaker PipelinesとAWS SDKを使用して承認ステータスを管理することが最適解となります。
参考資料
問題文:
ある医療系企業がAmazon SageMakerを使用してWebベースのAI診断支援アプリケーションを構築しています。このアプリケーションは、ML実験、トレーニング、中央モデルレジストリ、モデルデプロイ、モデル監視の機能を提供します。アプリケーションは、MLライフサイクル中に患者データの安全で分離された使用を確保する必要があります。トレーニングデータはAmazon S3に保存されています。企業は、アプリケーションからリアルタイムエンドポイントにデプロイされたモデルのバイアスドリフトを監視するオンデマンドワークフローを実行する必要があります。この要件を満たすには、どのアクションを実行すればよいですか。
選択肢:
A. SageMaker Clarifyジョブを実行するAWS Lambda関数を呼び出すようにアプリケーションを設定する。
B. sagemaker-model-monitor-analyzerビルトインSageMakerイメージをプルするAWS Lambda関数を呼び出す。
C. AWS Glue Data Qualityを使用してバイアスを監視する。
D. SageMakerノートブックを使用してバイアスを比較する。
正解:A
A. SageMaker Clarifyジョブを実行するAWS Lambda関数を呼び出すようにアプリケーションを設定する。
正解 SageMaker Clarifyは、モデルのバイアスや公平性の問題を検出するためのサービスです。AWS Lambda関数を使用してSageMaker Clarifyジョブを実行することで、オンデマンドでバイアスドリフトを監視できます。Lambda関数は、スケジュールやイベントに基づいてトリガーでき、リアルタイムエンドポイントにデプロイされたモデルのバイアスドリフトを定期的に監視できます。SageMaker Clarifyは、トレーニングデータと本番データの間のバイアスの変化を検出し、バイアスドリフトを監視する機能を提供します。
B. sagemaker-model-monitor-analyzerビルトインSageMakerイメージをプルするAWS Lambda関数を呼び出す。
不正解 SageMaker Model Monitorのアナライザーイメージは、データドリフトや品質の問題を検出するために使用されますが、バイアスドリフトの監視には適していません。バイアスドリフトの監視には、SageMaker Clarifyの専用機能を使用する必要があります。Model Monitorは、入力データの分布の変化やモデルの予測品質の低下を検出しますが、バイアスや公平性の問題を検出する機能は提供していません。
C. AWS Glue Data Qualityを使用してバイアスを監視する。
不正解 AWS Glue Data Qualityは、データの品質を評価し、データ品質ルールを定義してデータの整合性をチェックするサービスです。データの欠損値、重複、異常値などの問題を検出しますが、機械学習モデルのバイアスドリフトを監視する機能は提供していません。バイアスドリフトの監視には、SageMaker Clarifyの専用機能を使用する必要があります。
D. SageMakerノートブックを使用してバイアスを比較する。
不正解 SageMakerノートブックを使用してバイアスを比較することは技術的には可能ですが、この問題の要件を満たすには不十分です。主な理由は以下の通りです:
1. 自動化の欠如: ノートブック自体は手動で実行する必要があり、スケジュールやイベントに基づいて自動的に実行することはできません。ノートブック内のコードを自動化するには、SageMaker ProcessingジョブやLambda関数として実行する必要がありますが、その場合「ノートブックを使用する」というより「ノートブック内のコードを使用する」という表現になります。
2. オンデマンドワークフローの要件: 問題文では「オンデマンドワークフロー」として実行する必要があります。ノートブックを手動で実行する方法では、この要件を満たすことができません。
3. 運用オーバーヘッド: ノートブックベースのソリューションは、運用オーバーヘッドが大きく、スケーラブルな監視ワークフローを実装するには適していません。一方、Lambda関数を使用した方法は、サーバーレスで自動スケーリングされ、運用オーバーヘッドが最小限です。
4. 最適解との比較: 正解(Lambda + SageMaker Clarify)は、オンデマンドで自動実行でき、運用オーバーヘッドが最小限で、スケーラブルな監視ワークフローを実装できます。これが要件を満たす最適解となります。
全体的な説明
問われている要件
- リアルタイムエンドポイントにデプロイされたモデルのバイアスドリフトを監視する
- オンデマンドワークフローとして実行する
- バイアスドリフトを自動的に検出する
- 運用オーバーヘッドを最小限に抑える
前提知識
SageMaker Clarifyについて
SageMaker Clarifyは、機械学習モデルのバイアスや公平性の問題を検出するためのサービスです。トレーニングデータと本番データの間のバイアスの変化を検出し、バイアスドリフトを監視する機能を提供します。バイアスメトリクスとして、前処理バイアス、後処理バイアス、インプロセッシングバイアスなどを計算し、モデルの公平性を評価できます。SageMaker Clarifyジョブは、バッチ処理として実行でき、AWS Lambda関数から呼び出すことで、オンデマンドでバイアスドリフトを監視できます。リアルタイムエンドポイントにデプロイされたモデルに対して、定期的にバイアスドリフトを監視し、問題が検出された場合にアラートを送信できます。
AWS Lambdaについて
AWS Lambdaは、サーバーレスでコードを実行するサービスです。スケジュールやイベントに基づいて自動的に実行でき、SageMaker Clarifyジョブを呼び出すことで、オンデマンドでバイアスドリフトを監視するワークフローを実装できます。Lambda関数は、EventBridge(旧CloudWatch Events)を使用してスケジュール実行でき、定期的にバイアスドリフトを監視できます。運用オーバーヘッドが最小限で、スケーラブルな監視ワークフローを実装できます。
SageMaker Model Monitorについて
SageMaker Model Monitorは、デプロイされたモデルのパフォーマンスを監視し、データドリフトや品質の問題を検出する機能です。入力データの分布の変化やモデルの予測品質の低下を検出しますが、バイアスや公平性の問題を検出する機能は提供していません。Model Monitorは、データドリフトの監視に特化しており、バイアスドリフトの監視には適していません。
AWS Glue Data Qualityについて
AWS Glue Data Qualityは、データの品質を評価し、データ品質ルールを定義してデータの整合性をチェックするサービスです。データの欠損値、重複、異常値などの問題を検出しますが、機械学習モデルのバイアスドリフトを監視する機能は提供していません。データの品質評価が主な目的であり、モデルのバイアスや公平性の問題を検出する機能はありません。
SageMakerノートブックについて
SageMakerノートブックは、Jupyterノートブック環境を提供し、データの探索、モデルの開発、実験の実行などに使用できます。ノートブック内でSageMaker Clarifyジョブを実行するコードを書くことは技術的には可能ですが、この問題の要件を満たすには不十分です。
ノートブックの自動化に関する制約:
- ノートブック自体は手動で実行する必要があり、スケジュールやイベントに基づいて自動的に実行することはできません
- ノートブック内のコードを自動化するには、SageMaker ProcessingジョブやLambda関数として実行する必要がありますが、その場合「ノートブックを使用する」というより「ノートブック内のコードを使用する」という表現になります
- ノートブックベースのソリューションは、運用オーバーヘッドが大きく、スケーラブルな監視ワークフローを実装するには適していません
要件との比較:
- 「オンデマンドワークフロー」の要件: ノートブックを手動で実行する方法では満たせません
- 「運用オーバーヘッドを最小限に抑える」要件: Lambda関数を使用した方法の方が、サーバーレスで自動スケーリングされ、運用オーバーヘッドが最小限です
解くための考え方
この問題では、リアルタイムエンドポイントにデプロイされたモデルのバイアスドリフトを監視するオンデマンドワークフローを実装する必要があります。
バイアスドリフトの監視には、SageMaker Clarifyの専用機能を使用する必要があります。SageMaker Clarifyは、トレーニングデータと本番データの間のバイアスの変化を検出し、バイアスドリフトを監視する機能を提供します。AWS Lambda関数を使用してSageMaker Clarifyジョブを実行することで、オンデマンドでバイアスドリフトを監視できます。Lambda関数は、EventBridgeを使用してスケジュール実行でき、定期的にバイアスドリフトを監視できます。運用オーバーヘッドが最小限で、スケーラブルな監視ワークフローを実装できます。
一方、SageMaker Model Monitorのアナライザーイメージは、データドリフトや品質の問題を検出するために使用されますが、バイアスドリフトの監視には適していません。AWS Glue Data Qualityは、データの品質評価が主な目的であり、モデルのバイアスドリフトを監視する機能は提供していません。
SageMakerノートブックを使用した方法については、技術的にはノートブック内でSageMaker Clarifyジョブを実行するコードを書くことは可能ですが、以下の理由で要件を満たすには不十分です:
- ノートブック自体は手動で実行する必要があり、「オンデマンドワークフロー」として自動化するには不十分です
- ノートブック内のコードを自動化するには、別の方法(Lambda、Processing、Pipelinesなど)が必要ですが、その場合「ノートブックを使用する」というより「ノートブック内のコードを使用する」という表現になります
- 運用オーバーヘッドが大きく、スケーラブルな監視ワークフローを実装するには適していません
したがって、リアルタイムエンドポイントにデプロイされたモデルのバイアスドリフトを監視するオンデマンドワークフローを実装するには、AWS Lambda関数を使用してSageMaker Clarifyジョブを実行することが最適解となります。
参考資料
問題文:
ある物流企業は、Amazon S3に配送履歴データを.csvファイルとして保存しています。.csvファイル内の一部の行と列のみが入力されており、列にはラベルが付いていません。MLエンジニアは、企業がMLモデルのトレーニングに使用できるようにデータを準備して保存する必要があります。このタスクを実行するために、以下のリストから正しいステップを選択して順序付けます。各ステップは1回選択するか、まったく選択しないかのいずれかです。(3つ選択して順序付け)
・Amazon SageMakerバッチ変換ジョブを作成してデータクリーニングと特徴量エンジニアリングを行う
・結果のデータをAmazon S3に保存する
・Amazon Athenaを使用してスキーマと利用可能な列を推論する
・AWS Glueクローラーを使用してスキーマと利用可能な列を推論する
・AWS Glue DataBrewを使用してデータクリーニングと特徴量エンジニアリングを行う
選択肢:
A.
Step 1: AWS Glueクローラーを使用してスキーマと利用可能な列を推論する
Step 2: AWS Glue DataBrewを使用してデータクリーニングと特徴量エンジニアリングを行う
Step 3: 結果のデータをAmazon S3に保存する
B.
Step 1: Amazon Athenaを使用してスキーマと利用可能な列を推論する
Step 2: AWS Glue DataBrewを使用してデータクリーニングと特徴量エンジニアリングを行う
Step 3: 結果のデータをAmazon S3に保存する
C.
Step 1: AWS Glueクローラーを使用してスキーマと利用可能な列を推論する
Step 2: Amazon SageMakerバッチ変換ジョブを作成してデータクリーニングと特徴量エンジニアリングを行う
Step 3: 結果のデータをAmazon S3に保存する
D.
Step 1: AWS Glue DataBrewを使用してデータクリーニングと特徴量エンジニアリングを行う
Step 2: AWS Glueクローラーを使用してスキーマと利用可能な列を推論する
Step 3: 結果のデータをAmazon S3に保存する
E.
Step 1: AWS Glueクローラーを使用してスキーマと利用可能な列を推論する
Step 2: 結果のデータをAmazon S3に保存する
Step 3: AWS Glue DataBrewを使用してデータクリーニングと特徴量エンジニアリングを行う
F.
Step 1: Amazon Athenaを使用してスキーマと利用可能な列を推論する
Step 2: Amazon SageMakerバッチ変換ジョブを作成してデータクリーニングと特徴量エンジニアリングを行う
Step 3: 結果のデータをAmazon S3に保存する
正解:A
A.
Step 1: AWS Glueクローラーを使用してスキーマと利用可能な列を推論する
Step 2: AWS Glue DataBrewを使用してデータクリーニングと特徴量エンジニアリングを行う
Step 3: 結果のデータをAmazon S3に保存する
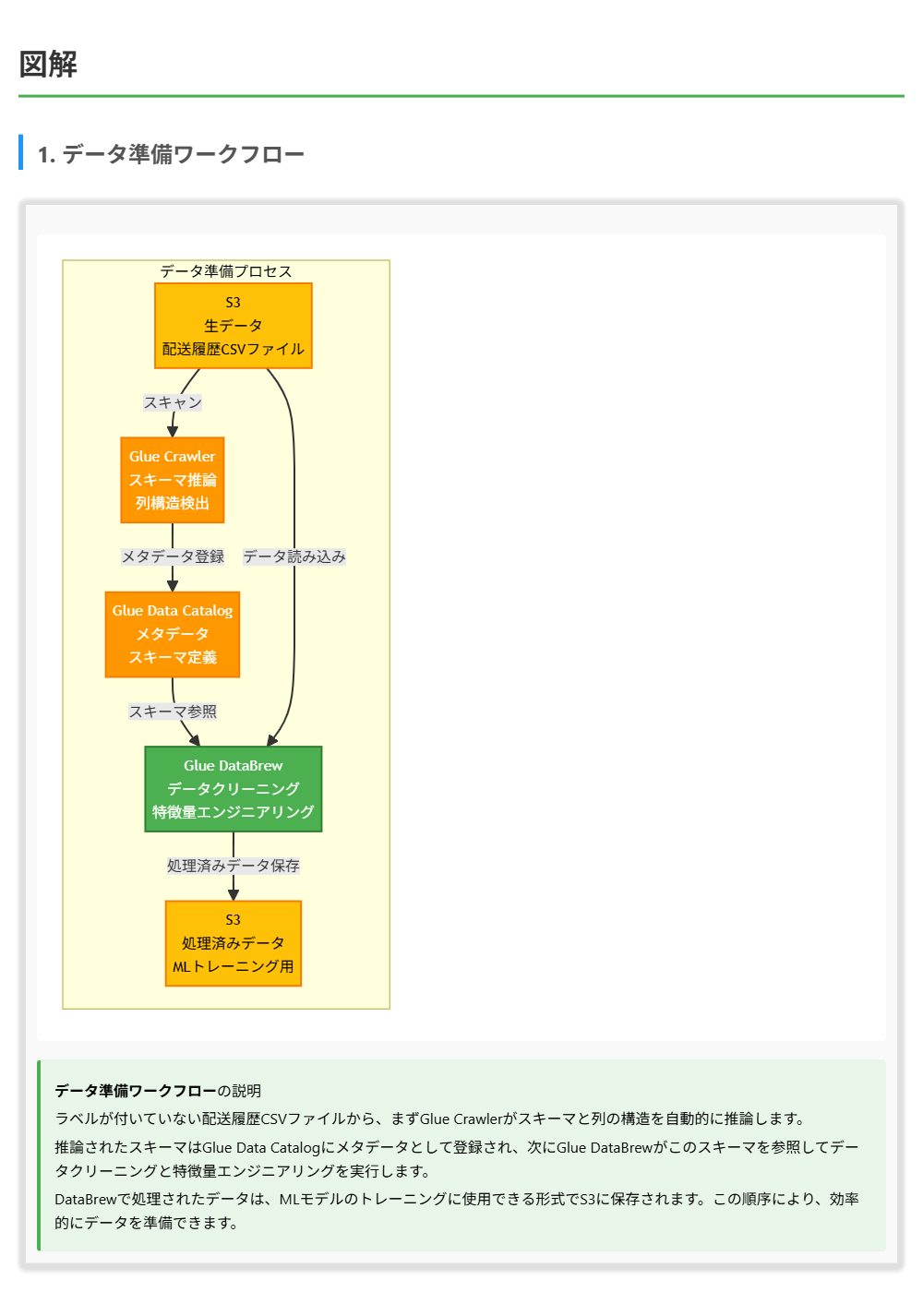
正解 ラベルが付いていない.csvファイルからスキーマを推論するには、AWS Glueクローラーが最適です。クローラーはS3内のデータをスキャンし、スキーマと列の構造を自動的に推論します。次に、AWS Glue DataBrewは、データクリーニングと特徴量エンジニアリングを視覚的なインターフェースで実行できるサービスです。DataBrewは、欠損値の処理、データ型の変換、特徴量の作成などの作業を効率的に行えます。最後に、処理されたデータをS3に保存することで、MLモデルのトレーニングに使用できる形式でデータを準備できます。
B.
Step 1: Amazon Athenaを使用してスキーマと利用可能な列を推論する
Step 2: AWS Glue DataBrewを使用してデータクリーニングと特徴量エンジニアリングを行う
Step 3: 結果のデータをAmazon S3に保存する
不正解 Amazon Athenaは、S3内のデータに対してSQLクエリを実行するサービスです。Athenaはスキーマを推論する機能を提供していません。Athenaを使用するには、事前にスキーマを定義する必要があり、ラベルが付いていない.csvファイルからスキーマを推論するタスクには適していません。スキーマの推論には、AWS Glueクローラーを使用する必要があります。
C.
Step 1: AWS Glueクローラーを使用してスキーマと利用可能な列を推論する
Step 2: Amazon SageMakerバッチ変換ジョブを作成してデータクリーニングと特徴量エンジニアリングを行う
Step 3: 結果のデータをAmazon S3に保存する
不正解 Amazon SageMakerバッチ変換ジョブは、既にトレーニング済みのモデルを使用して大量のデータに対してバッチ推論を実行するためのサービスです。データクリーニングや特徴量エンジニアリングのためのサービスではありません。データクリーニングと特徴量エンジニアリングには、AWS Glue DataBrewのような専用のサービスを使用する方が適切です。
D.
Step 1: AWS Glue DataBrewを使用してデータクリーニングと特徴量エンジニアリングを行う
Step 2: AWS Glueクローラーを使用してスキーマと利用可能な列を推論する
Step 3: 結果のデータをAmazon S3に保存する
不正解 スキーマが推論されていない状態でデータクリーニングと特徴量エンジニアリングを実行することは非効率的です。まず、AWS Glueクローラーを使用してスキーマと列の構造を推論し、データの構造を理解してから、データクリーニングと特徴量エンジニアリングを実行する必要があります。順序が逆になっているため、適切なワークフローではありません。
E.
Step 1: AWS Glueクローラーを使用してスキーマと利用可能な列を推論する
Step 2: 結果のデータをAmazon S3に保存する
Step 3: AWS Glue DataBrewを使用してデータクリーニングと特徴量エンジニアリングを行う
不正解 スキーマを推論した直後にデータをS3に保存しても、データクリーニングや特徴量エンジニアリングが行われていないため、MLモデルのトレーニングに使用できる形式になっていません。データクリーニングと特徴量エンジニアリングを実行してから、処理されたデータをS3に保存する必要があります。順序が不適切です。
F.
Step 1: Amazon Athenaを使用してスキーマと利用可能な列を推論する
Step 2: Amazon SageMakerバッチ変換ジョブを作成してデータクリーニングと特徴量エンジニアリングを行う
Step 3: 結果のデータをAmazon S3に保存する
不正解 Amazon Athenaはスキーマを推論する機能を提供しておらず、Amazon SageMakerバッチ変換ジョブはデータクリーニングや特徴量エンジニアリングのためのサービスではありません。この組み合わせは、ラベルが付いていない.csvファイルからスキーマを推論し、データをクリーニングしてMLモデルのトレーニングに使用できる形式に準備するタスクには適していません。
全体的な説明
問われている要件
- ラベルが付いていない.csvファイルからスキーマと列の構造を推論する
- データクリーニングと特徴量エンジニアリングを実行する
- 処理されたデータをMLモデルのトレーニングに使用できる形式で保存する
- 適切な順序で各ステップを実行する
前提知識
AWS Glueクローラーについて
AWS Glueクローラーは、データソースをスキャンしてスキーマと列の構造を自動的に推論するサービスです。S3内の.csvファイルやその他のデータソースをスキャンし、データ型、列名、パーティション情報などを検出して、AWS Glue Data Catalogにメタデータを保存します。ラベルが付いていないデータからスキーマを推論する場合、クローラーはデータの内容を分析して、適切なデータ型と列の構造を推論します。クローラーは、複数のファイルをスキャンして、共通のスキーマを推論することもできます。
AWS Glue DataBrewについて
AWS Glue DataBrewは、データクリーニングと特徴量エンジニアリングを視覚的なインターフェースで実行できるサービスです。コードを書かずに、データの欠損値の処理、データ型の変換、異常値の検出と処理、特徴量の作成などの作業を実行できます。DataBrewは、250以上の組み込み変換を提供し、データの品質を向上させ、MLモデルのトレーニングに適した形式にデータを準備できます。処理されたデータは、S3やその他のデータストアに保存できます。
Amazon Athenaについて
Amazon Athenaは、S3内のデータに対して標準的なSQLクエリを実行するサーバーレスなインタラクティブクエリサービスです。Athenaは、事前に定義されたスキーマに基づいてクエリを実行しますが、スキーマを推論する機能は提供していません。Athenaを使用するには、AWS Glue Data Catalogにスキーマを登録するか、テーブル定義を作成する必要があります。したがって、ラベルが付いていないデータからスキーマを推論するタスクには適していません。
Amazon SageMakerバッチ変換ジョブについて
Amazon SageMakerバッチ変換ジョブは、既にトレーニング済みのモデルを使用して大量のデータに対してバッチ推論を実行するためのサービスです。モデルを使用してデータに対して予測を実行し、結果をS3に保存します。データクリーニングや特徴量エンジニアリングのためのサービスではなく、推論の実行に特化しています。
データ準備のワークフローについて
MLモデルのトレーニングに使用するデータを準備する際は、適切な順序で各ステップを実行する必要があります。まず、データの構造を理解するためにスキーマを推論し、次にデータクリーニングと特徴量エンジニアリングを実行して、最後に処理されたデータを保存します。この順序を守ることで、効率的にデータを準備できます。
解くための考え方
この問題では、ラベルが付いていない.csvファイルからスキーマを推論し、データをクリーニングして特徴量エンジニアリングを実行し、MLモデルのトレーニングに使用できる形式でデータを保存する必要があります。
まず、スキーマと列の構造を推論する必要があります。AWS Glueクローラーは、S3内のデータをスキャンしてスキーマを自動的に推論する機能を提供しており、ラベルが付いていないデータからスキーマを推論するタスクに最適です。Amazon Athenaは、スキーマを推論する機能を提供していないため、このタスクには適していません。
次に、データクリーニングと特徴量エンジニアリングを実行する必要があります。AWS Glue DataBrewは、視覚的なインターフェースでデータクリーニングと特徴量エンジニアリングを実行できるサービスであり、このタスクに最適です。Amazon SageMakerバッチ変換ジョブは、推論の実行に特化したサービスであり、データクリーニングや特徴量エンジニアリングのためのサービスではありません。
最後に、処理されたデータをS3に保存することで、MLモデルのトレーニングに使用できる形式でデータを準備できます。
したがって、正しい順序は、AWS Glueクローラーを使用してスキーマを推論し、次にAWS Glue DataBrewを使用してデータクリーニングと特徴量エンジニアリングを実行し、最後に処理されたデータをS3に保存するという順序となります。
参考資料
問題文:
物流会社のMLエンジニアは、大規模言語モデル(LLM)を使用してAmazon Bedrock上で配送状況照会チャットボットを構築しています。以下のリストから各説明に対して正しい生成AI用語を選択します。各用語は1回選択するか、まったく選択しないかのいずれかです。
用語:
・埋め込み(Embedding)
・検索拡張生成(Retrieval Augmented Generation、RAG)
・温度(Temperature)
・トークン(Token)
説明:
・説明1: LLMが処理するデータの基本的な単位のテキスト表現
・説明2: テキストの意味を含む高次元ベクトル
・説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること
選択肢:
A.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: トークン(Token)
説明2: テキストの意味を含む高次元ベクトル: 埋め込み(Embedding)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: 検索拡張生成(Retrieval Augmented Generation、RAG)
B.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: 埋め込み(Embedding)
説明2: テキストの意味を含む高次元ベクトル: トークン(Token)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: 検索拡張生成(Retrieval Augmented Generation、RAG)
C.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: トークン(Token)
説明2: テキストの意味を含む高次元ベクトル: 検索拡張生成(Retrieval Augmented Generation、RAG)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: 埋め込み(Embedding)
D.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: 検索拡張生成(Retrieval Augmented Generation、RAG)
説明2: テキストの意味を含む高次元ベクトル: 埋め込み(Embedding)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: トークン(Token)
E.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: トークン(Token)
説明2: テキストの意味を含む高次元ベクトル: 検索拡張生成(Retrieval Augmented Generation、RAG)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: 埋め込み(Embedding)
F.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: 温度(Temperature)
説明2: テキストの意味を含む高次元ベクトル: 埋め込み(Embedding)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: 検索拡張生成(Retrieval Augmented Generation、RAG)
正解:A
A.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: トークン(Token)
説明2: テキストの意味を含む高次元ベクトル: 埋め込み(Embedding)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: 検索拡張生成(Retrieval Augmented Generation、RAG)
正解
Tokenは、LLMがテキストを処理する際の基本的な単位のテキスト表現です。Tokenは、単語、文字、または単語の一部を表すことができ、LLMがテキストを理解し処理するために使用されます。例えば、「こんにちは」というテキストは、複数のTokenに分割される可能性があります。Tokenの数は、LLMの入力と出力の長さを制限するために使用され、多くのLLMサービスでは、使用されたToken数に基づいて課金されます。
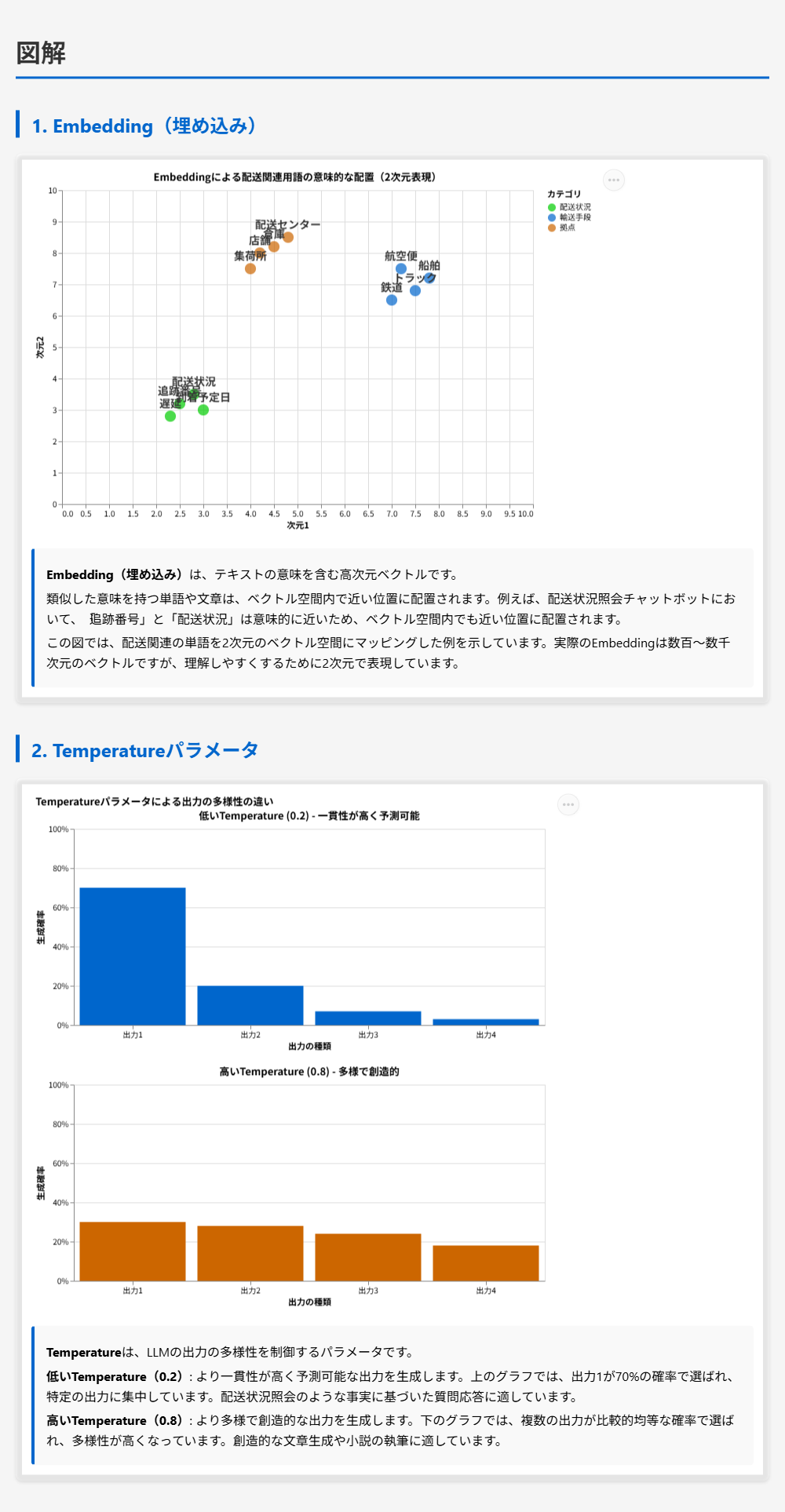
Embeddingは、テキストの意味を含む高次元ベクトルです。Embeddingは、テキスト、画像、音声などのデータを、意味を保持した数値ベクトルに変換する技術であり、類似した意味を持つデータは、ベクトル空間内で近い位置に配置されます。例えば、ユーザーが「犬」という単語を検索した場合、Embeddingによって「犬」という単語が数値ベクトルに変換され、類似した意味を持つ「ペット」や「動物」などの単語のベクトルと近い位置に配置されます。これにより、意味的に類似したデータを検索したり、分類したりすることが可能になります。
Retrieval Augmented Generation(RAG)は、生成された応答を改善するために追加のデータソースから情報を豊富化する手法です。RAGは、外部の知識ベースから関連情報を取得し、それをLLMのプロンプトに組み込むことで、より正確で最新の回答を生成します。例えば、配送状況データベースを検索して、その情報をLLMのプロンプトに追加することで、LLMが学習したデータに含まれていない最新の配送情報を基に回答を生成できます。
B.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: 埋め込み(Embedding)
説明2: テキストの意味を含む高次元ベクトル: トークン(Token)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: 検索拡張生成(Retrieval Augmented Generation、RAG)
不正解
Embeddingは、テキストの意味を含む高次元ベクトルであり、LLMが処理するデータの基本的な単位のテキスト表現ではありません。LLMが処理するデータの基本的な単位のテキスト表現は、Tokenです。Tokenは、単語、文字、または単語の一部を表すことができ、LLMがテキストを理解し処理するために使用されます。また、Tokenは、テキストの意味を含む高次元ベクトルではなく、テキストの基本的な単位の表現です。
C.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: トークン(Token)
説明2: テキストの意味を含む高次元ベクトル: 検索拡張生成(Retrieval Augmented Generation、RAG)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: 埋め込み(Embedding)
不正解
RAGは、生成された応答を改善するために追加のデータソースから情報を豊富化する手法であり、テキストの意味を含む高次元ベクトルではありません。テキストの意味を含む高次元ベクトルは、Embeddingです。Embeddingは、テキスト、画像、音声などのデータを、意味を保持した数値ベクトルに変換する技術であり、類似した意味を持つデータは、ベクトル空間内で近い位置に配置されます。また、Embeddingは、生成された応答を改善するために追加のデータソースから情報を豊富化する手法ではなく、データの意味的な表現を数値ベクトルで表現する技術です。
D.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: 検索拡張生成(Retrieval Augmented Generation、RAG)
説明2: テキストの意味を含む高次元ベクトル: 埋め込み(Embedding)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: トークン(Token)
不正解
RAGは、生成された応答を改善するために追加のデータソースから情報を豊富化する手法であり、LLMが処理するデータの基本的な単位のテキスト表現ではありません。LLMが処理するデータの基本的な単位のテキスト表現は、Tokenです。Tokenは、単語、文字、または単語の一部を表すことができ、LLMがテキストを理解し処理するために使用されます。また、Tokenは、生成された応答を改善するために追加のデータソースから情報を豊富化する手法ではなく、テキストの基本的な単位の表現です。
E.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: トークン(Token)
説明2: テキストの意味を含む高次元ベクトル: 検索拡張生成(Retrieval Augmented Generation、RAG)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: 埋め込み(Embedding)
不正解
RAGは、生成された応答を改善するために追加のデータソースから情報を豊富化する手法であり、テキストの意味を含む高次元ベクトルではありません。テキストの意味を含む高次元ベクトルは、Embeddingです。Embeddingは、テキスト、画像、音声などのデータを、意味を保持した数値ベクトルに変換する技術であり、類似した意味を持つデータは、ベクトル空間内で近い位置に配置されます。また、Embeddingは、生成された応答を改善するために追加のデータソースから情報を豊富化する手法ではなく、データの意味的な表現を数値ベクトルで表現する技術です。
F.
説明1: LLMが処理するデータの基本的な単位のテキスト表現: 温度(Temperature)
説明2: テキストの意味を含む高次元ベクトル: 埋め込み(Embedding)
説明3: 生成された応答を改善するために追加のデータソースから情報を豊富化すること: 検索拡張生成(Retrieval Augmented Generation、RAG)
不正解
Temperatureは、LLMの出力の多様性を制御するパラメータであり、LLMが処理するデータの基本的な単位のテキスト表現ではありません。LLMが処理するデータの基本的な単位のテキスト表現は、Tokenです。Tokenは、単語、文字、または単語の一部を表すことができ、LLMがテキストを理解し処理するために使用されます。また、Temperatureは、生成された応答を改善するために追加のデータソースから情報を豊富化する手法ではなく、LLMの出力の多様性を制御するパラメータです。
全体的な説明
問われている要件
- 生成AIアプリケーションで使用される用語の定義を理解する
- 各用語がどのような機能や役割を持つかを把握する
- 用語と説明を正しく対応付ける
前提知識
Tokenについて
Tokenは、LLMがテキストを処理する際の基本的な単位のテキスト表現です。Tokenは、単語、文字、または単語の一部を表すことができ、LLMがテキストを理解し処理するために使用されます。例えば、「こんにちは」というテキストは、複数のTokenに分割される可能性があります。Tokenの数は、LLMの入力と出力の長さを制限するために使用されます。多くのLLMでは、入力と出力の合計Token数に上限があり、この上限を超えるとエラーが発生します。Tokenは、LLMのコスト計算にも使用され、多くのLLMサービスでは、使用されたToken数に基づいて課金されます。
Embeddingについて
Embeddingは、テキストの意味を含む高次元ベクトルです。Embeddingは、テキスト、画像、音声などのデータを、意味を保持した数値ベクトルに変換する技術であり、類似した意味を持つデータは、ベクトル空間内で近い位置に配置されます。例えば、ユーザーが「犬」という単語を検索した場合、Embeddingによって「犬」という単語が数値ベクトルに変換され、類似した意味を持つ「ペット」や「動物」などの単語のベクトルと近い位置に配置されます。これにより、意味的に類似したデータを検索したり、分類したりすることが可能になります。Embeddingは、機械学習モデル、特に自然言語処理や画像認識の分野で広く使用されています。ベクトル空間内では、意味的に類似したデータが近い位置に配置され、意味的に異なるデータが遠い位置に配置されます。
Retrieval Augmented Generation (RAG)について
Retrieval Augmented Generation(RAG)は、生成された応答を改善するために追加のデータソースから情報を豊富化する手法です。RAGは、外部の知識ベースから関連情報を取得し、それをLLMのプロンプトに組み込むことで、より正確で最新の回答を生成します。RAGの基本的な流れは、まず、ユーザーの質問に基づいて外部の知識ベースから関連情報を検索します。次に、検索された情報をLLMのプロンプトに追加します。最後に、LLMが追加された情報を基に回答を生成します。RAGを使用することで、LLMが学習したデータに含まれていない最新の情報を基に回答を生成できたり、LLMが推測ではなく事実に基づいた回答を生成できたりします。例えば、社内のドキュメントを検索して、その情報をLLMのプロンプトに追加することで、社内の最新の情報を基に回答を生成できます。
Temperatureについて
Temperatureは、LLMの出力の多様性を制御するパラメータです。Temperatureの値は0から1の範囲で設定され、値が高いほど、LLMはより多様で創造的な出力を生成します。一方、値が低いほど、より一貫性が高く予測可能な出力を生成します。例えば、創造的な文章生成や小説の執筆では、高いTemperatureを使用して、より多様で創造的な文章を生成します。一方、事実に基づいた質問応答やコード生成では、低いTemperatureを使用して、より一貫性が高く予測可能な出力を生成します。Temperatureは、LLMの出力のランダム性を制御するため、同じプロンプトに対して異なる回答を生成したい場合は高いTemperatureを使用し、一貫した回答を生成したい場合は低いTemperatureを使用します。
解くための考え方
この問題では、生成AIアプリケーションで使用される用語の定義を理解し、各説明に対して正しい用語を選択する必要があります。
まず、各用語の定義を確認します。Tokenは、LLMがテキストを処理する際の基本的な単位のテキスト表現です。Embeddingは、テキストの意味を含む高次元ベクトルです。RAGは、生成された応答を改善するために追加のデータソースから情報を豊富化する手法です。Temperatureは、LLMの出力の多様性を制御するパラメータです。
次に、各説明がどの用語に該当するかを判断します。説明1は、LLMが処理するデータの基本的な単位のテキスト表現について説明しているため、Tokenに該当します。説明2は、テキストの意味を含む高次元ベクトルについて説明しているため、Embeddingに該当します。説明3は、生成された応答を改善するために追加のデータソースから情報を豊富化することについて説明しているため、RAGに該当します。
したがって、説明1に対してトークン(Token)、説明2に対して埋め込み(Embedding)、説明3に対して検索拡張生成(RAG)を選択するのが正解となります。
参考資料
問題文:
MLエンジニアは、医療グループ向けに患者の再入院リスクを予測するモデルを開発しています。トレーニングデータセットには、診療記録ログ、患者プロファイル、オンプレミスのMySQLデータベースからのテーブルが含まれています。診療記録ログと患者プロファイルはAmazon S3に保存されています。データセットには、モデルのアルゴリズムの学習に影響を与えるクラスの不均衡があります。さらに、多くの特徴には相互依存関係があります。アルゴリズムは、データ内のすべての望ましい基礎パターンを捉えていません。様々なデータソースからデータを集約できるAWSサービスまたは機能はどれですか。
選択肢:
A. Amazon Redshift
B. Amazon Kinesis Data Streams
C. Amazon DynamoDB
D. AWS Lake Formation
正解:D
A. Amazon Redshift
不正解 Amazon Redshiftは、クラウドベースのデータウェアハウスサービスであり、大規模なデータセットの分析とクエリを実行するために使用されます。Redshiftは、データの保存と分析に焦点を当てていますが、様々なデータソース(S3、オンプレミスのMySQLデータベースなど)からデータを自動的に集約する機能を提供していません。Redshiftにデータをロードするには、AWS Glue、Amazon EMR、AWS DMSなどの別のサービスを使用して、各データソースから個別にデータを抽出、変換、ロードする必要があります。Redshiftは主にデータ分析とクエリ処理に特化しており、データ統合やデータレイクの構築には適していません。
B. Amazon Kinesis Data Streams
不正解 Amazon Kinesis Data Streamsは、リアルタイムでストリーミングデータを収集、処理、分析するためのサービスです。Kinesis Data Streamsは、リアルタイムのストリーミングデータの処理に適していますが、オンプレミスのMySQLデータベースやS3内の診療記録ログ、患者プロファイルなどの様々なデータソースからデータを集約する機能は提供していません。また、Kinesis Data Streamsは主にストリーミングデータに焦点を当てており、バッチデータやデータベースからのデータの集約には適していません。
C. Amazon DynamoDB
不正解 Amazon DynamoDBは、NoSQLデータベースサービスであり、アプリケーションのデータを保存および取得するために使用されます。DynamoDBは、様々なデータソースからデータを自動的に集約する機能を提供していません。DynamoDBにデータを保存するには、各データソースから個別にデータを読み込み、DynamoDBに書き込む必要があります。また、DynamoDBは主にアプリケーションのデータストアとして使用され、データ統合やデータレイクの構築には適していません。
D. AWS Lake Formation
正解 AWS Lake Formationは、様々なデータソースからデータを集約し、セキュアなデータレイクを構築するためのマネージドサービスです。Lake Formationは、S3内のデータ、オンプレミスのデータベース、その他のデータソースからデータを自動的に収集し、統合されたデータレイクを作成できます。Lake Formationは、データソース間の接続、データの変換、メタデータの管理、セキュリティとアクセス制御などを自動化します。また、Lake Formationは、様々なデータソースからのデータを統合し、MLモデルのトレーニングに使用できる形式でデータを提供できます。
全体的な説明
問われている要件
- 様々なデータソース(診療記録ログ、患者プロファイル、MySQLデータベース)からデータを集約する
- データを統合された形式で保存し、MLモデルのトレーニングに使用できるようにする
- データソース間の統合とメタデータ管理を効率的に行う
- セキュアなデータアクセスとガバナンスを実現する
前提知識
AWS Lake Formationについて
AWS Lake Formationは、様々なデータソースからデータを集約し、セキュアなデータレイクを構築するためのマネージドサービスです。Lake Formationは、S3内のデータ、オンプレミスのデータベース、その他のデータソースからデータを自動的に収集し、統合されたデータレイクを作成できます。Lake Formationは、データソース間の接続、データの変換、メタデータの管理、セキュリティとアクセス制御などを自動化します。Lake Formationは、AWS Glueクローラーと統合されており、様々なデータソースを自動的に検出し、データカタログにメタデータを登録できます。また、Lake Formationは、データレイクへのアクセスを制御し、セキュアなデータ共有を実現します。
Amazon Redshiftについて
Amazon Redshiftは、クラウドベースのデータウェアハウスサービスであり、ペタバイト規模のデータセットの分析とクエリを高速に実行するために使用されます。Redshiftは、列指向ストレージと並列処理を使用して、大規模なデータセットに対する複雑なクエリを高速に実行できます。しかし、Redshiftは、様々なデータソース(S3、オンプレミスのMySQLデータベースなど)からデータを自動的に集約する機能を提供していません。Redshiftにデータをロードするには、AWS Glue、Amazon EMR、AWS DMS、またはCOPYコマンドを使用して、各データソースから個別にデータを抽出、変換、ロードする必要があります。Redshiftは主にデータ分析とクエリ処理に特化しており、データ統合やデータレイクの構築には適していません。
Amazon Kinesis Data Streamsについて
Amazon Kinesis Data Streamsは、リアルタイムでストリーミングデータを収集、処理、分析するためのサービスです。Kinesis Data Streamsは、アプリケーション、ウェブサイト、モバイルデバイスなどからリアルタイムのデータストリームを収集し、処理できます。Kinesis Data Streamsは、リアルタイムのストリーミングデータの処理に適していますが、オンプレミスのMySQLデータベースやS3内の診療記録ログ、患者プロファイルなどの様々なデータソースからデータを集約する機能は提供していません。また、Kinesis Data Streamsは主にストリーミングデータに焦点を当てており、バッチデータやデータベースからのデータの集約には適していません。
Amazon DynamoDBについて
Amazon DynamoDBは、NoSQLデータベースサービスであり、アプリケーションのデータを保存および取得するために使用されます。DynamoDBは、高パフォーマンス、スケーラブル、可用性の高いデータベースを提供し、アプリケーションのバックエンドデータストアとして使用されます。DynamoDBは、様々なデータソースからデータを自動的に集約する機能を提供していません。DynamoDBにデータを保存するには、各データソースから個別にデータを読み込み、DynamoDBに書き込む必要があります。また、DynamoDBは主にアプリケーションのデータストアとして使用され、データ統合やデータレイクの構築には適していません。
データレイクとデータ統合について
データレイクは、様々な形式とスキーマの大量のデータを保存するための集中型リポジトリです。データレイクは、構造化データ、半構造化データ、非構造化データを保存でき、MLモデルのトレーニングや分析に使用できます。データ統合は、様々なデータソースからデータを収集し、統合された形式で保存するプロセスです。データ統合には、データソース間の接続、データの変換、メタデータの管理、セキュリティとアクセス制御などが含まれます。データレイクとデータ統合を組み合わせることで、様々なデータソースからのデータを効率的に管理し、MLモデルのトレーニングに使用できます。
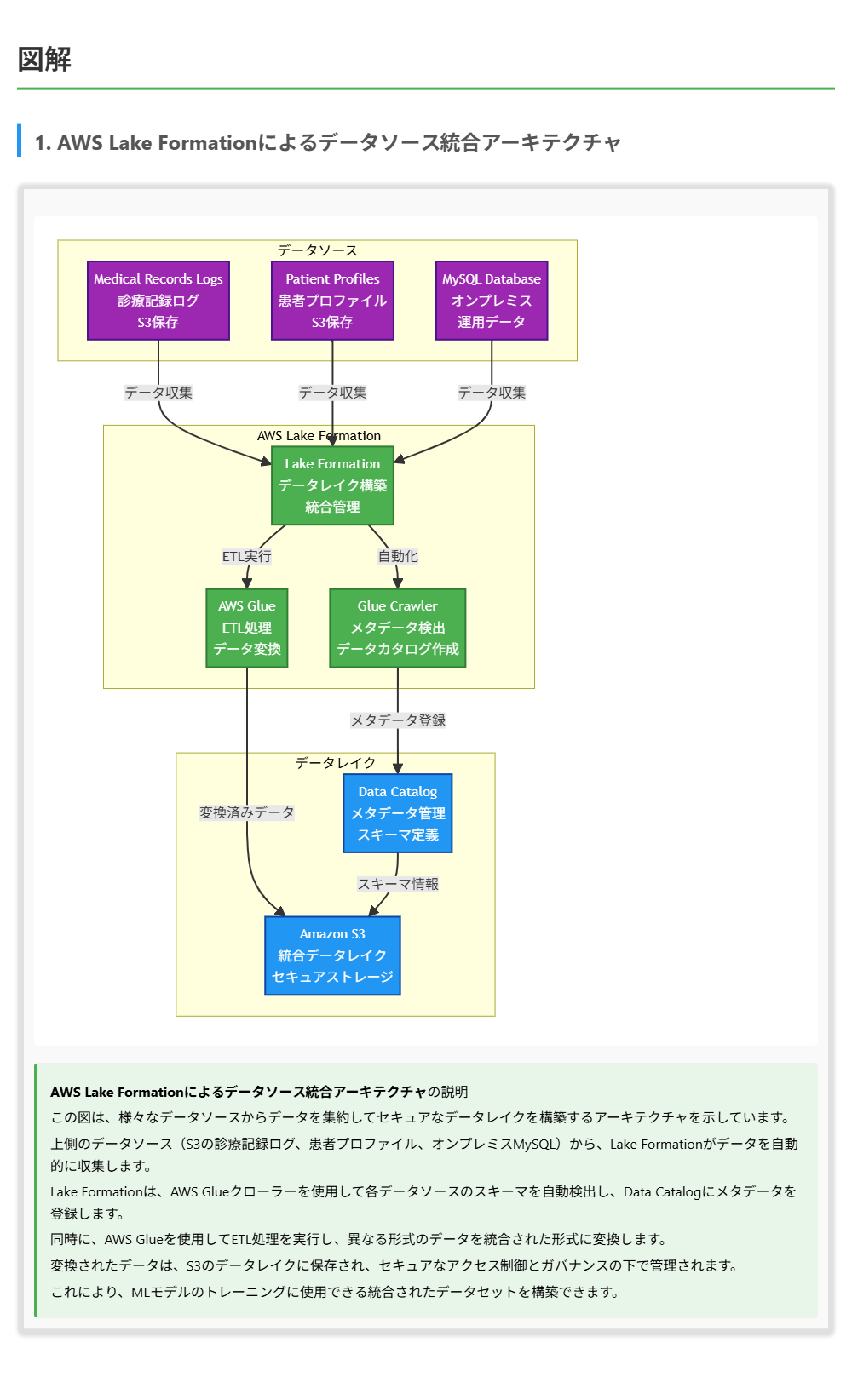
解くための考え方
この問題では、様々なデータソース(診療記録ログ、患者プロファイル、MySQLデータベース)からデータを集約するAWSサービスを選択する必要があります。
まず、各選択肢の機能を確認します。Amazon Redshiftは、データウェアハウスサービスであり、大規模なデータセットの分析に適していますが、様々なデータソースからデータを自動的に集約する機能は提供していません。Redshiftにデータをロードするには、別のサービスを使用して各データソースから個別にデータを抽出、変換、ロードする必要があります。Amazon Kinesis Data Streamsは、リアルタイムのストリーミングデータの処理に適していますが、様々なデータソースからデータを集約する機能は提供していません。Amazon DynamoDBは、NoSQLデータベースサービスであり、様々なデータソースからデータを自動的に集約する機能は提供していません。
一方、AWS Lake Formationは、様々なデータソースからデータを集約し、セキュアなデータレイクを構築するためのマネージドサービスです。Lake Formationは、S3内のデータ、オンプレミスのデータベース、その他のデータソースからデータを自動的に収集し、統合されたデータレイクを作成できます。Lake Formationは、データソース間の接続、データの変換、メタデータの管理、セキュリティとアクセス制御などを自動化します。
したがって、様々なデータソースからデータを集約できるAWSサービスは、AWS Lake Formationとなります。
参考資料
問題文:
ケーススタディ – MLエンジニアがAWS上でオンラインゲームの不正行為検出モデルを開発しています。トレーニングデータセットには、プレイヤーの操作ログ、プレイヤープロファイル、オンプレミスのMySQLデータベースからのテーブルが含まれています。プレイヤーの操作ログとプレイヤープロファイルはAmazon S3に保存されています。データセットにはクラス不均衡があり(不正行為を行うプレイヤーは全体のごく一部)、モデルのアルゴリズムの学習に影響を与えています。また、多くの特徴量には相互依存関係があります。アルゴリズムはデータ内の望ましい根本的なパターンをすべて捉えていません。 データが集約された後、MLエンジニアはデータ内の異常を自動的に検出し、結果を可視化するソリューションを実装する必要があります。これらの要件を満たすソリューションはどれですか。
選択肢:
A. Amazon Athenaを使用して異常を自動的に検出し、結果を可視化する。
B. Amazon Redshift Spectrumを使用して異常を自動的に検出する。Amazon QuickSightを使用して結果を可視化する。
C. Amazon SageMaker Data Wranglerを使用して異常を自動的に検出し、結果を可視化する。
D. AWS Batchを使用して異常を自動的に検出する。Amazon QuickSightを使用して結果を可視化する。
正解:C
A. Amazon Athenaを使用して異常を自動的に検出し、結果を可視化する。
不正解 Amazon AthenaはS3内のデータに対してSQLクエリを実行するサーバーレスなインタラクティブクエリサービスです。Athenaは異常検出のための組み込み機能を提供しておらず、データの可視化機能も限定的です。異常検出を実装するには、SQLクエリを手動で作成する必要があり、運用オーバーヘッドが大きくなります。
B. Amazon Redshift Spectrumを使用して異常を自動的に検出する。Amazon QuickSightを使用して結果を可視化する。
不正解 Amazon Redshift Spectrumは、S3内のデータに対してSQLクエリを実行するサービスですが、異常検出のための組み込み機能は提供していません。Redshift SpectrumとQuickSightを組み合わせる方法は、異常検出のロジックを手動で実装する必要があり、運用オーバーヘッドが大きく、自動的な異常検出と可視化の要件を効率的に満たすことができません。
C. Amazon SageMaker Data Wranglerを使用して異常を自動的に検出し、結果を可視化する。
正解 Amazon SageMaker Data Wranglerは、データの前処理、特徴量エンジニアリング、異常検出、データ可視化を統合的に実行できるサービスです。Data Wranglerは、異常検出のための組み込み機能を提供しており、統計的手法や機械学習ベースの手法を使用して異常を自動的に検出できます。また、データの可視化機能も統合されており、異常検出の結果をグラフやチャートで直感的に確認できます。SageMakerの他の機能と統合されており、MLワークフローに組み込みやすい設計となっています。
D. AWS Batchを使用して異常を自動的に検出する。Amazon QuickSightを使用して結果を可視化する。
不正解 AWS Batchは、大規模なバッチコンピューティングジョブを実行するためのサービスですが、異常検出のための組み込み機能は提供していません。異常検出のロジックを自分で実装し、コンテナイメージとして実行する必要があります。この方法は、開発と運用の両面で大きなオーバーヘッドが発生し、自動的な異常検出と可視化の要件を効率的に満たすことができません。
全体的な説明
問われている要件
- データ内の異常を自動的に検出する
- 異常検出の結果を可視化する
- 集約されたデータに対して異常検出と可視化を実行する
- 運用オーバーヘッドを最小限に抑える
前提知識
Amazon SageMaker Data Wranglerについて
Amazon SageMaker Data Wranglerは、データの前処理、特徴量エンジニアリング、異常検出、データ可視化を統合的に実行できるサービスです。Data Wranglerは、視覚的なインターフェースでデータフローを構築でき、250を超える組み込み変換を提供しています。異常検出機能では、統計的手法や機械学習ベースの手法を使用して異常を自動的に検出でき、検出結果を視覚的に確認できます。処理されたデータは、SageMakerの他の機能やS3などに直接出力でき、MLワークフローに組み込みやすい設計となっています。
Amazon Athenaについて
Amazon Athenaは、S3内のデータに対して標準的なSQLクエリを実行するサーバーレスなインタラクティブクエリサービスです。Athenaは、事前に定義されたスキーマに基づいてクエリを実行しますが、異常検出のための組み込み機能は提供しておらず、データの可視化機能も限定的です。異常検出を実装するには、SQLクエリを手動で作成する必要があり、運用オーバーヘッドが大きくなります。Athenaは、データの分析やクエリ実行に特化したサービスであり、異常検出と可視化を統合的に実行するタスクには適していません。
Amazon Redshift Spectrumについて
Amazon Redshift Spectrumは、S3内のデータに対してSQLクエリを実行するサービスですが、Amazon Redshiftクラスターに接続する必要があります。Redshift Spectrumは、異常検出のための組み込み機能を提供しておらず、異常検出のロジックを手動で実装する必要があります。また、Redshift SpectrumとAmazon QuickSightを組み合わせる方法は、複数のサービスを管理する必要があり、運用オーバーヘッドが大きくなります。
AWS Batchについて
AWS Batchは、大規模なバッチコンピューティングジョブを実行するためのマネージドサービスです。AWS Batchは、異常検出のための組み込み機能は提供しておらず、異常検出のロジックを自分で実装し、コンテナイメージとして実行する必要があります。この方法は、開発と運用の両面で大きなオーバーヘッドが発生し、自動的な異常検出と可視化の要件を効率的に満たすことができません。
異常検出と可視化の統合について
異常検出と可視化を統合的に実行するには、データの前処理、異常検出、可視化の各ステップを効率的に連携させる必要があります。専用のサービスを使用することで、これらのステップを一元的に管理でき、運用オーバーヘッドを削減できます。複数のサービスを組み合わせる方法は、サービス間の連携やデータの受け渡しなどの作業が必要となり、運用オーバーヘッドが増加します。
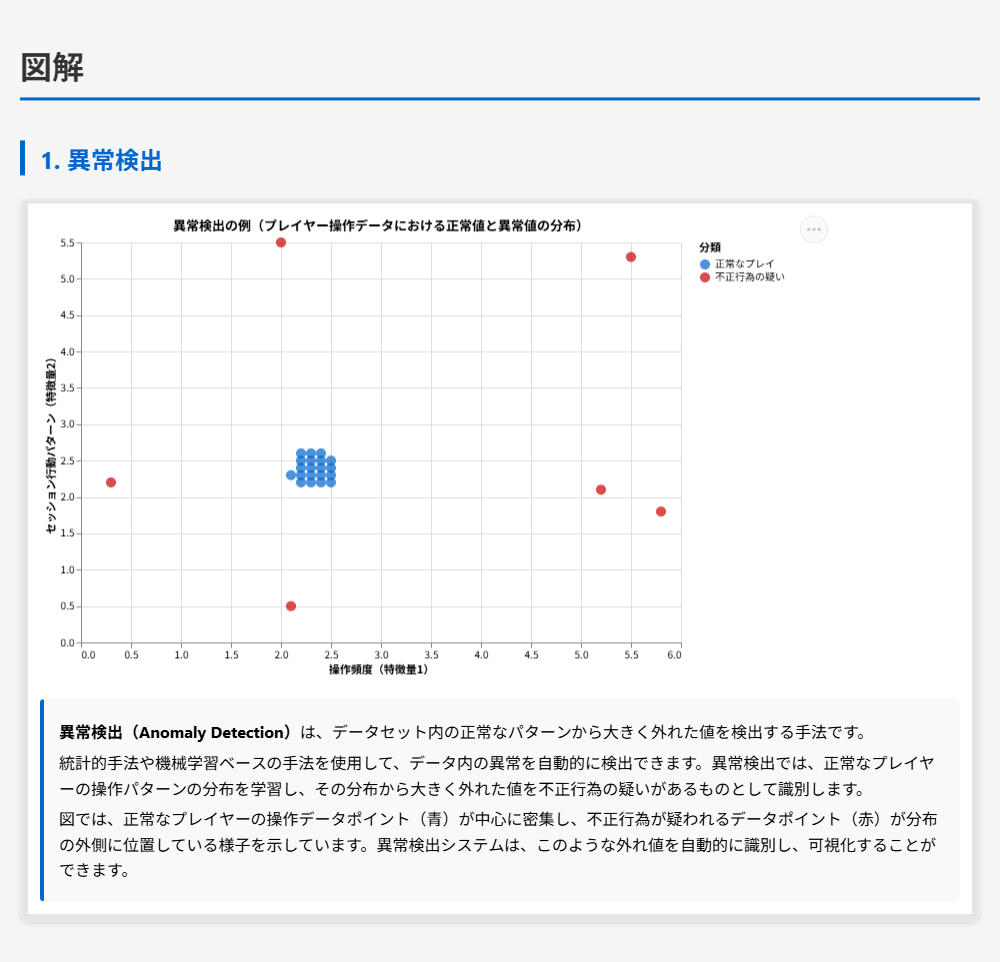
解くための考え方
この問題では、データ内の異常を自動的に検出し、結果を可視化するソリューションを実装する必要があります。要件として、異常検出と可視化を統合的に実行し、運用オーバーヘッドを最小限に抑えることが求められています。
Amazon SageMaker Data Wranglerは、データの前処理、特徴量エンジニアリング、異常検出、データ可視化を統合的に実行できるサービスです。Data Wranglerは、異常検出のための組み込み機能を提供しており、統計的手法や機械学習ベースの手法を使用して異常を自動的に検出できます。また、データの可視化機能も統合されており、異常検出の結果をグラフやチャートで直感的に確認できます。SageMakerの他の機能と統合されており、MLワークフローに組み込みやすい設計となっています。
一方、Amazon Athenaを使用する方法は、S3内のデータに対してSQLクエリを実行することはできますが、異常検出のための組み込み機能は提供しておらず、データの可視化機能も限定的です。異常検出を実装するには、SQLクエリを手動で作成する必要があり、運用オーバーヘッドが大きくなります。
Amazon Redshift SpectrumとAmazon QuickSightを組み合わせる方法は、複数のサービスを管理する必要があり、異常検出のロジックを手動で実装する必要があるため、運用オーバーヘッドが大きくなります。
AWS BatchとAmazon QuickSightを組み合わせる方法は、異常検出のロジックを自分で実装し、コンテナイメージとして実行する必要があり、開発と運用の両面で大きなオーバーヘッドが発生します。
したがって、異常を自動的に検出し、結果を可視化するソリューションを実装するには、Amazon SageMaker Data Wranglerを使用することが最適解となります。
参考資料
問題文:
ケーススタディ – MLエンジニアが保険会社で保険金請求の不正検出モデルをAWS上で開発しています。トレーニングデータセットには、請求記録、契約者プロファイル、オンプレミスのMySQLデータベースからのテーブルが含まれています。請求記録と契約者プロファイルはAmazon S3に保存されています。データセットにはクラス不均衡があり、モデルのアルゴリズムの学習に影響を与えています。また、多くの特徴量には相互依存関係があります。アルゴリズムはデータ内の望ましい根本的なパターンをすべて捉えていません。 トレーニングデータセットにはカテゴリカルデータと数値データが含まれています。MLエンジニアは、モデルの精度を最大化するためにトレーニングデータセットを準備する必要があります。最小限の運用オーバーヘッドでこの要件を満たすアクションはどれですか。
選択肢:
A. AWS Glueを使用してカテゴリカルデータを数値データに変換する。
B. AWS Glueを使用して数値データをカテゴリカルデータに変換する。
C. Amazon SageMaker Data Wranglerを使用してカテゴリカルデータを数値データに変換する。
D. Amazon SageMaker Data Wranglerを使用して数値データをカテゴリカルデータに変換する。
正解:C
A. AWS Glueを使用してカテゴリカルデータを数値データに変換する。
不正解 AWS Glueは、データ変換のためのETLサービスですが、データ変換のロジックを手動で実装する必要があります。カテゴリカルデータを数値データに変換するには、Glueジョブを作成し、変換ロジックをコーディングする必要があり、運用オーバーヘッドが大きくなります。また、データの可視化や変換結果の確認などの機能も限定的です。
B. AWS Glueを使用して数値データをカテゴリカルデータに変換する。
不正解 機械学習モデルの精度を最大化するためには、通常、カテゴリカルデータを数値データに変換する必要があります。数値データをカテゴリカルデータに変換することは、モデルの精度を向上させるのではなく、むしろ精度を低下させる可能性があります。また、AWS Glueを使用する方法は、変換ロジックを手動で実装する必要があり、運用オーバーヘッドが大きくなります。
C. Amazon SageMaker Data Wranglerを使用してカテゴリカルデータを数値データに変換する。
正解 Amazon SageMaker Data Wranglerは、データの前処理と特徴量エンジニアリングを視覚的なインターフェースで実行できるサービスです。Data Wranglerは、カテゴリカルデータを数値データに変換するための組み込み機能を提供しており、ワンホットエンコーディングやラベルエンコーディングなどの手法を簡単に適用できます。視覚的なインターフェースでデータ変換を実行でき、変換結果を即座に確認できるため、運用オーバーヘッドが最小限です。SageMakerの他の機能と統合されており、MLワークフローに組み込みやすい設計となっています。
D. Amazon SageMaker Data Wranglerを使用して数値データをカテゴリカルデータに変換する。
不正解 機械学習モデルの精度を最大化するためには、通常、カテゴリカルデータを数値データに変換する必要があります。数値データをカテゴリカルデータに変換することは、モデルの精度を向上させるのではなく、むしろ精度を低下させる可能性があります。モデルのアルゴリズムは、数値データの方が効率的に処理できるため、カテゴリカルデータを数値データに変換することが一般的なベストプラクティスです。
全体的な説明
問われている要件
- カテゴリカルデータと数値データが含まれるトレーニングデータセットを準備する
- モデルの精度を最大化する
- 最小限の運用オーバーヘッドで実現する
- データ変換を効率的に実行する
前提知識
カテゴリカルデータと数値データの変換について
機械学習モデルの多くは、数値データを直接処理できるように設計されています。カテゴリカルデータ(例: 性別、商品カテゴリ、地域など)は、そのままではモデルが処理できないため、数値データに変換する必要があります。主な変換手法には、ワンホットエンコーディング(各カテゴリを0または1の値を持つ新しい列に変換)、ラベルエンコーディング(各カテゴリを数値にマッピング)、ターゲットエンコーディング(カテゴリごとの目的変数の平均値を使用)などがあります。適切な変換を行うことで、モデルの精度を向上させることができます。
Amazon SageMaker Data Wranglerについて
Amazon SageMaker Data Wranglerは、データの前処理、特徴量エンジニアリング、データ可視化を統合的に実行できるサービスです。Data Wranglerは、視覚的なインターフェースでデータフローを構築でき、250を超える組み込み変換を提供しています。カテゴリカルデータを数値データに変換するための組み込み機能を提供しており、ワンホットエンコーディングやラベルエンコーディングなどの手法を簡単に適用できます。変換結果を即座に確認でき、SageMakerの他の機能と統合されており、MLワークフローに組み込みやすい設計となっています。
AWS Glueについて
AWS Glueは、データの抽出、変換、ロード(ETL)を実行するためのマネージドサービスです。Glueは、PythonやScalaを使用してデータ変換のロジックを実装できますが、データ変換のロジックを手動でコーディングする必要があります。Glueは、大規模なデータ処理に適していますが、データ変換のロジックを実装するための運用オーバーヘッドが大きくなります。また、データの可視化や変換結果の確認などの機能も限定的です。
データ前処理の運用オーバーヘッドについて
運用オーバーヘッドとは、システムを運用するために必要な手作業や管理作業の量を指します。視覚的なインターフェースでデータ変換を実行できるサービスを使用することで、コーディング作業を削減し、変換結果を即座に確認できるため、運用オーバーヘッドを削減できます。一方、データ変換のロジックを手動で実装する必要がある場合、開発と運用の両面で大きなオーバーヘッドが発生します。
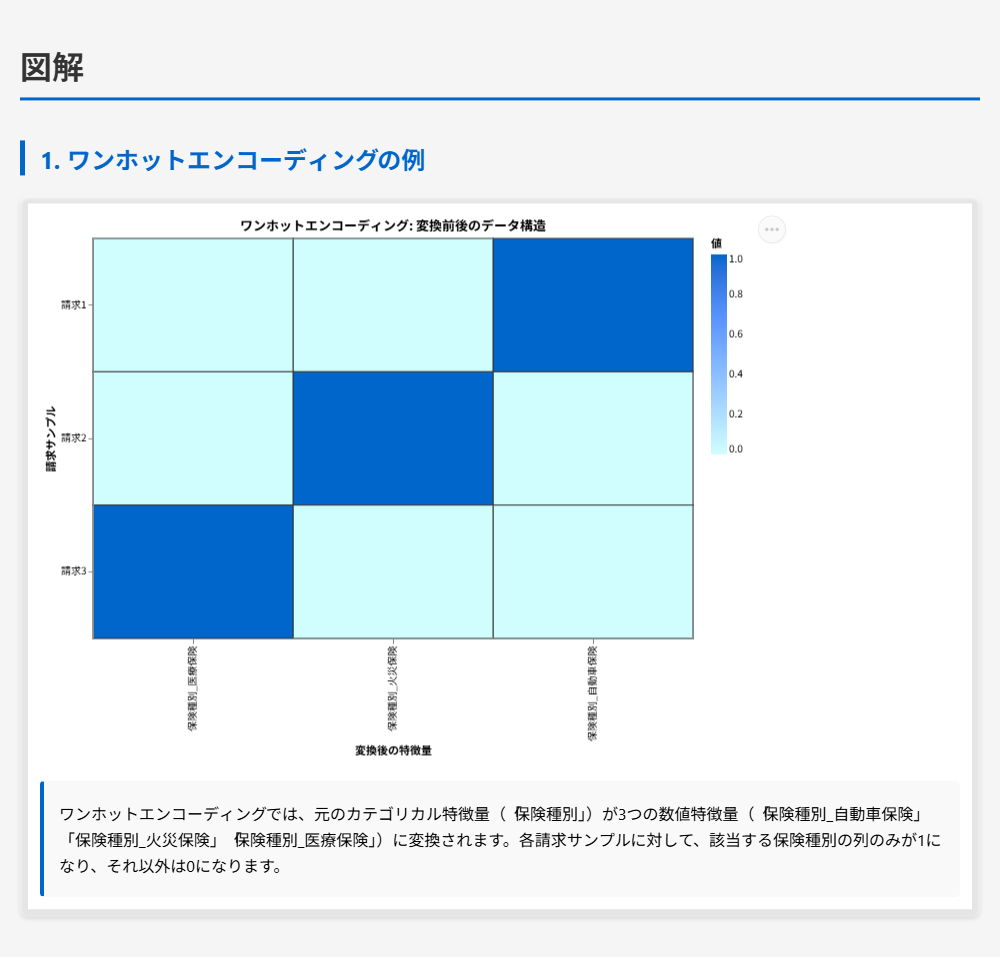
解くための考え方
この問題では、カテゴリカルデータと数値データが含まれるトレーニングデータセットを準備し、モデルの精度を最大化する必要があります。また、最小限の運用オーバーヘッドで実現することが求められています。
機械学習モデルの精度を最大化するためには、通常、カテゴリカルデータを数値データに変換する必要があります。モデルのアルゴリズムは、数値データの方が効率的に処理できるため、カテゴリカルデータを数値データに変換することが一般的なベストプラクティスです。数値データをカテゴリカルデータに変換することは、モデルの精度を向上させるのではなく、むしろ精度を低下させる可能性があります。
Amazon SageMaker Data Wranglerは、カテゴリカルデータを数値データに変換するための組み込み機能を提供しており、ワンホットエンコーディングやラベルエンコーディングなどの手法を簡単に適用できます。視覚的なインターフェースでデータ変換を実行でき、変換結果を即座に確認できるため、運用オーバーヘッドが最小限です。SageMakerの他の機能と統合されており、MLワークフローに組み込みやすい設計となっています。
一方、AWS Glueを使用する方法は、データ変換のロジックを手動で実装する必要があり、Glueジョブを作成し、変換ロジックをコーディングする必要があります。この方法は、運用オーバーヘッドが大きく、データの可視化や変換結果の確認などの機能も限定的です。
したがって、最小限の運用オーバーヘッドでカテゴリカルデータを数値データに変換し、モデルの精度を最大化するには、Amazon SageMaker Data Wranglerを使用することが最適解となります。
参考資料
問題文:
ケーススタディ – MLエンジニアがAWS上でモバイルゲームの不正アカウント検出モデルを開発しています。トレーニングデータセットには、ゲームセッションログ、プレイヤープロファイル、オンプレミスのMySQLデータベースからの課金履歴テーブルが含まれています。ゲームセッションログとプレイヤープロファイルはAmazon S3に保存されています。データセットにはクラス不均衡があり、モデルのアルゴリズムの学習に影響を与えています。また、多くの特徴量には相互依存関係があります。アルゴリズムはデータ内の望ましい根本的なパターンをすべて捉えていません。 MLエンジニアがモデルをトレーニングする前に、MLエンジニアは不均衡なデータの問題を解決する必要があります。最小限の運用努力でこの要件を満たすソリューションはどれですか。
選択肢:
A. Amazon Athenaを使用して不均衡に寄与するパターンを特定する。データセットをそれに応じて調整する。
B. Amazon SageMaker Studio Classicの組み込みアルゴリズムを使用して不均衡データセットを処理する。
C. AWS Glue DataBrewの組み込み機能を使用して少数クラスをオーバーサンプリングする。
D. Amazon SageMaker Data Wranglerのバランスデータ操作を使用して少数クラスをオーバーサンプリングする。
正解:D
A. Amazon Athenaを使用して不均衡に寄与するパターンを特定する。データセットをそれに応じて調整する。
不正解 Amazon Athenaは、S3内のデータに対してSQLクエリを実行するサービスですが、クラス不均衡の問題を解決するための組み込み機能は提供していません。不均衡に寄与するパターンを特定し、データセットを調整する作業は手動で行う必要があり、運用努力が大きくなります。また、Athenaはクラス不均衡を解決するための高度な機能(例: オーバーサンプリング)を提供していません。
B. Amazon SageMaker Studio Classicの組み込みアルゴリズムを使用して不均衡データセットを処理する。
不正解 Amazon SageMaker Studio Classicの組み込みアルゴリズムは、モデルのトレーニングに使用されますが、クラス不均衡の問題を解決するための前処理機能は提供していません。クラス不均衡の問題は、モデルをトレーニングする前のデータ前処理段階で解決する必要があります。組み込みアルゴリズムを使用しても、不均衡なデータセットの問題は解決されません。
C. AWS Glue DataBrewの組み込み機能を使用して少数クラスをオーバーサンプリングする。
不正解 AWS Glue DataBrewは、データクリーニングと特徴量エンジニアリングを実行できるサービスですが、クラス不均衡を解決するためのオーバーサンプリング機能は提供していません。DataBrewは、データの変換やクリーニングに特化したサービスであり、クラス不均衡の問題を解決するための専用機能はありません。
D. Amazon SageMaker Data Wranglerのバランスデータ操作を使用して少数クラスをオーバーサンプリングする。
正解 Amazon SageMaker Data Wranglerは、クラス不均衡を解決するためのバランスデータ操作を提供しています。この操作を使用することで、少数クラスをオーバーサンプリングし、クラス間の不均衡を解消できます。Data Wranglerは、視覚的なインターフェースでデータバランシングを実行でき、設定を簡単に調整できるため、運用努力が最小限です。SageMakerの他の機能と統合されており、MLワークフローに組み込みやすい設計となっています。
全体的な説明
問われている要件
- クラス不均衡の問題を解決する
- モデルをトレーニングする前にデータセットを調整する
- 最小限の運用努力で実現する
- 少数クラスを適切に処理する
前提知識
クラス不均衡について
クラス不均衡とは、データセット内のクラス(カテゴリ)の分布が偏っている状態を指します。例えば、不正アカウント検出の問題では、不正なアカウントが正常なアカウントよりもはるかに少ない場合、クラス不均衡が発生します。クラス不均衡が発生すると、モデルは多数派のクラスに偏って学習し、少数派のクラスを適切に予測できなくなります。クラス不均衡を解決する主な手法には、オーバーサンプリング(少数クラスのサンプルを増やす)、アンダーサンプリング(多数クラスのサンプルを減らす)、合成サンプルの生成(SMOTEなど)があります。
Amazon SageMaker Data Wranglerについて
Amazon SageMaker Data Wranglerは、データの前処理、特徴量エンジニアリング、データバランシングを統合的に実行できるサービスです。Data Wranglerは、クラス不均衡を解決するためのバランスデータ操作を提供しており、少数クラスをオーバーサンプリングし、クラス間の不均衡を解消できます。視覚的なインターフェースでデータバランシングを実行でき、設定を簡単に調整できるため、運用努力が最小限です。バランスデータ操作では、SMOTEやランダムオーバーサンプリングなどの手法を選択でき、クラス間の比率を調整できます。
Amazon Athenaについて
Amazon Athenaは、S3内のデータに対して標準的なSQLクエリを実行するサーバーレスなインタラクティブクエリサービスです。Athenaは、クラス不均衡の問題を解決するための組み込み機能は提供しておらず、不均衡に寄与するパターンを特定し、データセットを調整する作業は手動で行う必要があります。Athenaは、データの分析やクエリ実行に特化したサービスであり、クラス不均衡を解決するための前処理機能はありません。
Amazon SageMaker Studio Classicについて
Amazon SageMaker Studio Classicは、機械学習モデルの開発、トレーニング、デプロイを統合的に実行できる環境です。SageMaker Studio Classicには、組み込みアルゴリズムが用意されていますが、クラス不均衡の問題を解決するための前処理機能は提供していません。クラス不均衡の問題は、モデルをトレーニングする前のデータ前処理段階で解決する必要があります。
AWS Glue DataBrewについて
AWS Glue DataBrewは、データクリーニングと特徴量エンジニアリングを視覚的なインターフェースで実行できるサービスです。DataBrewは、データの変換やクリーニングに特化したサービスですが、クラス不均衡を解決するためのオーバーサンプリング機能は提供していません。DataBrewは、データの品質向上や特徴量の作成に適していますが、クラス不均衡の問題を解決するための専用機能はありません。
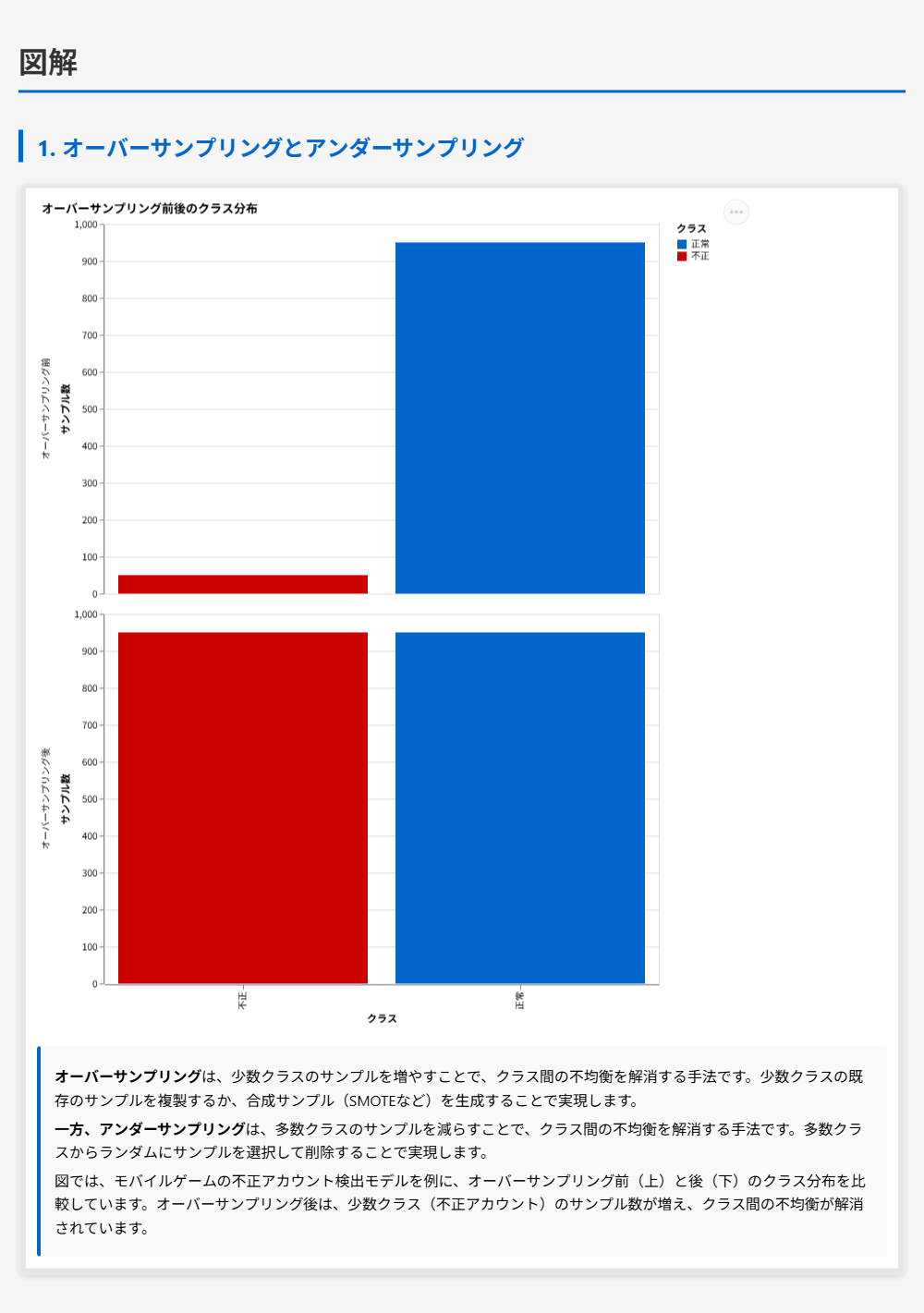
解くための考え方
この問題では、クラス不均衡の問題を解決し、モデルをトレーニングする前にデータセットを調整する必要があります。また、最小限の運用努力で実現することが求められています。
クラス不均衡の問題を解決するには、通常、少数クラスをオーバーサンプリングするか、多数クラスをアンダーサンプリングする必要があります。オーバーサンプリングは、少数クラスのサンプルを増やすことで、クラス間の不均衡を解消する手法です。
Amazon SageMaker Data Wranglerは、クラス不均衡を解決するためのバランスデータ操作を提供しています。この操作を使用することで、少数クラスをオーバーサンプリングし、クラス間の不均衡を解消できます。Data Wranglerは、視覚的なインターフェースでデータバランシングを実行でき、設定を簡単に調整できるため、運用努力が最小限です。バランスデータ操作では、SMOTEやランダムオーバーサンプリングなどの手法を選択でき、クラス間の比率を調整できます。
一方、Amazon Athenaを使用する方法は、クラス不均衡の問題を解決するための組み込み機能は提供しておらず、不均衡に寄与するパターンを特定し、データセットを調整する作業は手動で行う必要があります。この方法は、運用努力が大きく、クラス不均衡を解決するための高度な機能も提供されていません。
Amazon SageMaker Studio Classicの組み込みアルゴリズムを使用する方法は、クラス不均衡の問題を解決するための前処理機能は提供しておらず、クラス不均衡の問題はモデルをトレーニングする前のデータ前処理段階で解決する必要があります。
AWS Glue DataBrewを使用する方法は、クラス不均衡を解決するためのオーバーサンプリング機能は提供しておらず、クラス不均衡の問題を解決するための専用機能はありません。
したがって、最小限の運用努力でクラス不均衡の問題を解決するには、Amazon SageMaker Data Wranglerのバランスデータ操作を使用して少数クラスをオーバーサンプリングすることが最適解となります。
参考資料
スポンサーリンク
以下スポンサーリンクです。
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。