AWS DOP無料問題集です。正解と解説を確認する際は右側のボタンを押下してください。
問題集の完全版は以下Udemyにて発売しているためお買い求めください。問題集への質問はUdemyのQA機能もしくはUdemyのメッセージにて承ります。Udemyの問題1から10問抜粋しております。
多くの方にご好評いただき、講師評価 4.5/5.0 を獲得できております。ありがとうございます。

特別価格: 通常2,600円 → 1,500円
講師クーポン適用で42%OFF
講師クーポン【全出題範囲網羅+詳細解説】AWS DOP-C02日本語実践問題225問(DevOps Engineer Pro)
この資格を活かしたキャリア情報
DOP資格の取得後にどんなキャリアが開けるか、詳しくはこちら:
→ DOP合格者の転職市場価値と求人傾向
AWS資格全体のキャリア活用法:
→ AWS資格は転職・キャリアアップでどう活きる?資格別市場価値と実体験
問題文:
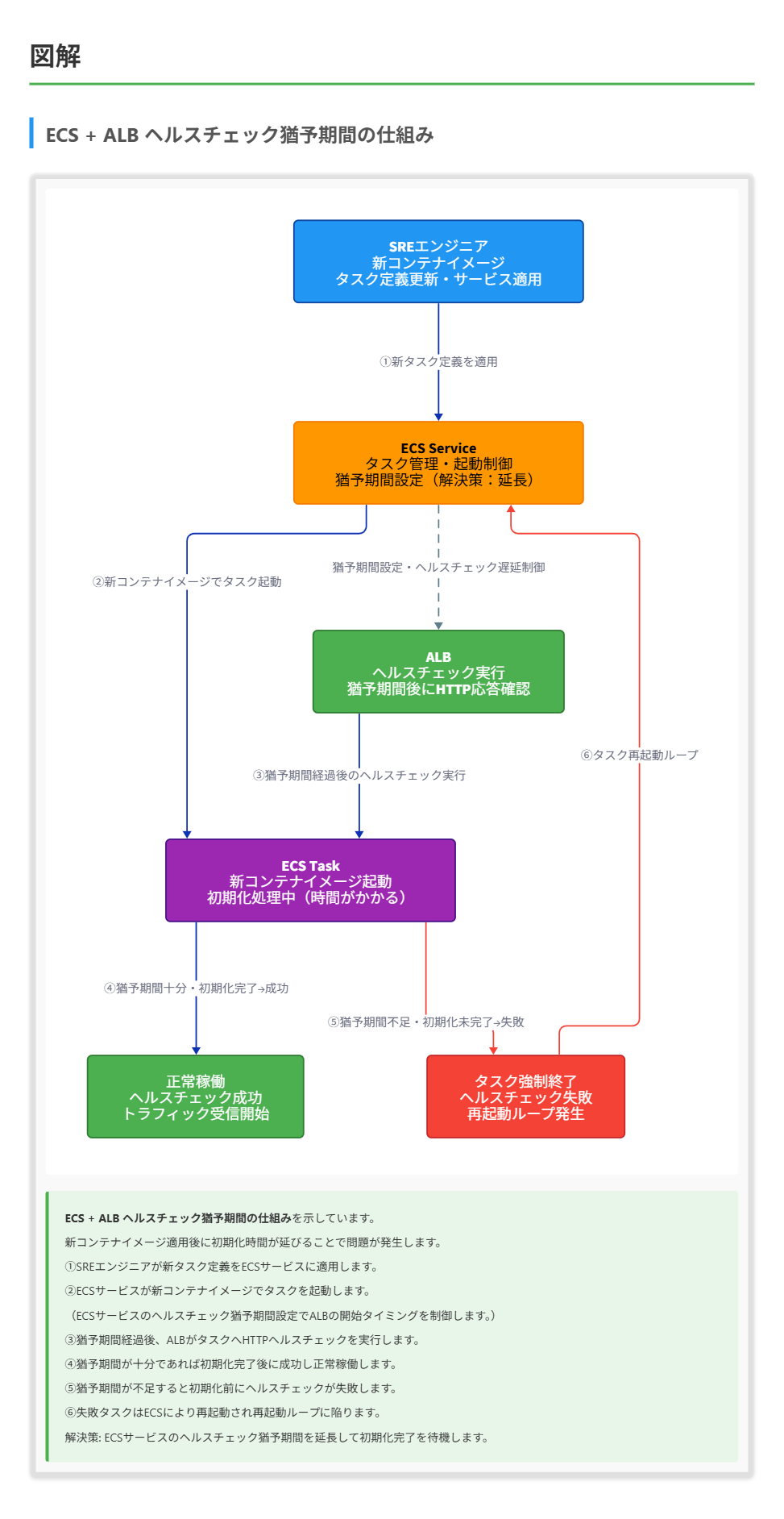
物流企業は、Amazon Elastic Container Service (Amazon ECS)とApplication Load Balancer (ALB)を使用して配送管理APIを運用しています。以前はサービスが安定しており、タスクが効率的に応答していましたが、SREエンジニアが新しいコンテナイメージを使用するようタスク定義を更新し、サービスに適用しました。その結果、サービスがALBのヘルスチェックに失敗し続け、タスクが終了して再起動を繰り返すようになりました。この問題を診断するために、SREエンジニアはどのように対応すべきでしょうか?
選択肢:
A. サービスに関連付けられたセキュリティグループが ALB からのトラフィックを許可していることを確認する。
B. サービスの ALB ヘルスチェックの猶予期間を延長する。
C. サービスの「最低正常率」構成を引き上げる。
D. ALB ヘルスチェックの間隔を短くする。
正解:B
A. サービスに関連付けられたセキュリティグループが ALB からのトラフィックを許可していることを確認する。
不正解 セキュリティグループの設定は、ALBからECSタスクへの接続可否に関わる問題です。もしセキュリティグループが原因であれば、すべてのヘルスチェックが一貫して失敗し、タスクが起動しても接続できないという状態になります。
B. サービスの ALB ヘルスチェックの猶予期間を延長する。
正解 ALBヘルスチェックの猶予期間は、新しいタスクが起動してからヘルスチェックが成功するまでに許容される時間です。問題の説明から、新しいコンテナイメージを使用するようにタスク定義が更新された後に問題が発生したことがわかります。
C. サービスの「最低正常率」構成を引き上げる。
不正解 「最低正常率」はECSサービスのデプロイ設定であり、デプロイ中に維持すべき正常タスクの最小割合を指定します。この値を引き上げると、デプロイ時により多くのタスクが正常である必要がありますが、タスクのヘルスチェック失敗そのものを解決するものではありません。
D. ALB ヘルスチェックの間隔を短くする。
不正解 ヘルスチェックの間隔を短くすると、ヘルスチェックがより頻繁に実行されるようになります。問題の状況では、タスクが初期化に十分な時間を取れていない可能性が高いです。ヘルスチェックの間隔を短くすると、タスクが準備できる前により頻繁にヘルスチェックが実行されることになり、問題をさらに悪化させる可能性があります。
全体的な説明
問われている要件
この問題では、Amazon ECSとALBを使用した配送管理APIにおいて、タスク定義を新しいコンテナイメージに更新した後に発生したサービス障害の診断と解決方法が問われています。具体的には、サービスがALBのヘルスチェックに失敗し続け、タスクが終了して再起動を繰り返すという問題状況において、SREエンジニアとしてどのように対応すべきかを判断する必要があります。
前提知識
Amazon ECSのタスクライフサイクル
Amazon ECSのタスクは、以下のライフサイクルを持ちます:
- PROVISIONING: タスクのリソースをプロビジョニングしている状態
- PENDING: タスクがコンテナインスタンスに配置される待機状態
- RUNNING: タスクが実行中の状態
- DEPROVISIONING: タスクが終了処理中の状態
- STOPPED: タスクが停止した状態
タスクが正常に終了した場合や、ヘルスチェックに失敗した場合など、様々な理由でタスクは停止状態になることがあります。ECSサービスは、設定された必要タスク数を維持するために、停止したタスクを自動的に再起動します。
Application Load Balancer (ALB) のヘルスチェック
ALBは、ターゲットグループに登録されたターゲット(この場合はECSタスク)の健全性を定期的に確認するためにヘルスチェックを行います。ヘルスチェックには以下の重要な設定があります:
- ヘルスチェックのパス: ALBがリクエストを送信するエンドポイント(例:/health)
- 間隔: ヘルスチェックを実行する頻度
- タイムアウト: ヘルスチェックリクエストに対するレスポンスを待つ時間
- 正常しきい値: ターゲットが正常と見なされるまでに必要な連続した成功ヘルスチェックの数
- 異常しきい値: ターゲットが異常と見なされるまでに必要な連続した失敗ヘルスチェックの数
ECSサービスの設定
ECSサービスには、デプロイメントとヘルスチェックに関連する重要な設定があります:
- デプロイメント設定:
- 最小正常率: デプロイ中に常に実行状態を維持する必要があるタスクの割合
- 最大率: 一度に実行できるタスクの最大数(サービスの望ましいタスク数に対する割合)
- ヘルスチェック猶予期間:
- 新しいタスクが起動してから最初のヘルスチェックが実行されるまでの猶予期間
- この期間中、タスクのヘルスステータスがチェックされない、または失敗しても無視される
- これにより、タスクがアプリケーションを完全に初期化し、リクエストに応答できるようになるまでの時間を確保できる
コンテナの初期化時間と起動時間
コンテナイメージが変更されると、以下の要因により初期化時間が変わる可能性があります:
- アプリケーションの初期化処理:
- データベース接続の確立
- キャッシュの準備
- 設定ファイルの読み込み
- 依存サービスとの接続確立
- コンテナイメージのサイズと内容:
- イメージサイズが大きい場合、ダウンロードと展開に時間がかかる
- より多くの依存関係がある場合、初期化に時間がかかる
- システムリソース:
- メモリとCPUの制約が厳しい場合、初期化が遅くなる
新しいコンテナイメージが以前のイメージよりも初期化に時間がかかる場合、既存のヘルスチェック猶予期間が不十分になり、タスクが準備できる前にヘルスチェックが失敗する可能性があります。
ヘルスチェック設定の最適化
ヘルスチェック設定の最適化には、以下の点を考慮する必要があります:
- 猶予期間の適切な設定:
- アプリケーションの実際の起動時間に基づいて設定
- 余裕を持たせる(例:平均起動時間 + 10〜20秒)
- ヘルスチェックエンドポイントの設計:
- 軽量で高速に応答するエンドポイントを使用
- アプリケーションの重要なコンポーネントの健全性を確認する
- ヘルスチェックの間隔とタイムアウト:
- 間隔を長くすると、タスクの起動時間に余裕ができる
- タイムアウトを長くすると、応答時間が遅いタスクでも正常と判断される可能性がある
ヘルスチェックの猶予期間を延長することは、新しいコンテナイメージの初期化時間が長い場合の最も直接的な解決策です。これにより、タスクが完全に起動して応答できるようになるまでの時間を確保できます。
解くための考え方
この問題を解くためには、以下の手順で考えるとよいでしょう:
- 問題の根本原因を特定する:
- 問題が発生したタイミングは「新しいコンテナイメージを使用するようタスク定義を更新し、サービスに適用した後」
- 症状は「サービスがALBのヘルスチェックに失敗し続け、タスクが終了して再起動を繰り返す」
- 可能性のある原因を検討する:
- 新しいコンテナイメージの初期化時間が長い
- コンテナが正しく起動していない
- ヘルスチェックの設定と実際のアプリケーションの状態が一致していない
- ネットワーク接続の問題
- 選択肢を評価する:
- どの選択肢が問題の根本原因に対処しているか
- どの選択肢が症状(タスクの再起動サイクル)を緩和できるか
ここで重要なのは、「タスクが終了して再起動を繰り返す」という症状です。これは、タスクが一時的に起動するものの、ALBのヘルスチェックに合格できず、その結果タスクが不健全と判断されて終了し、新しいタスクが起動するというサイクルを示唆しています。新しいコンテナイメージを使用するように変更した直後に問題が発生したことから、新しいイメージが起動して準備が整うまでの時間が、設定されたヘルスチェックの猶予期間よりも長くなっている可能性が高いです。
問題文:
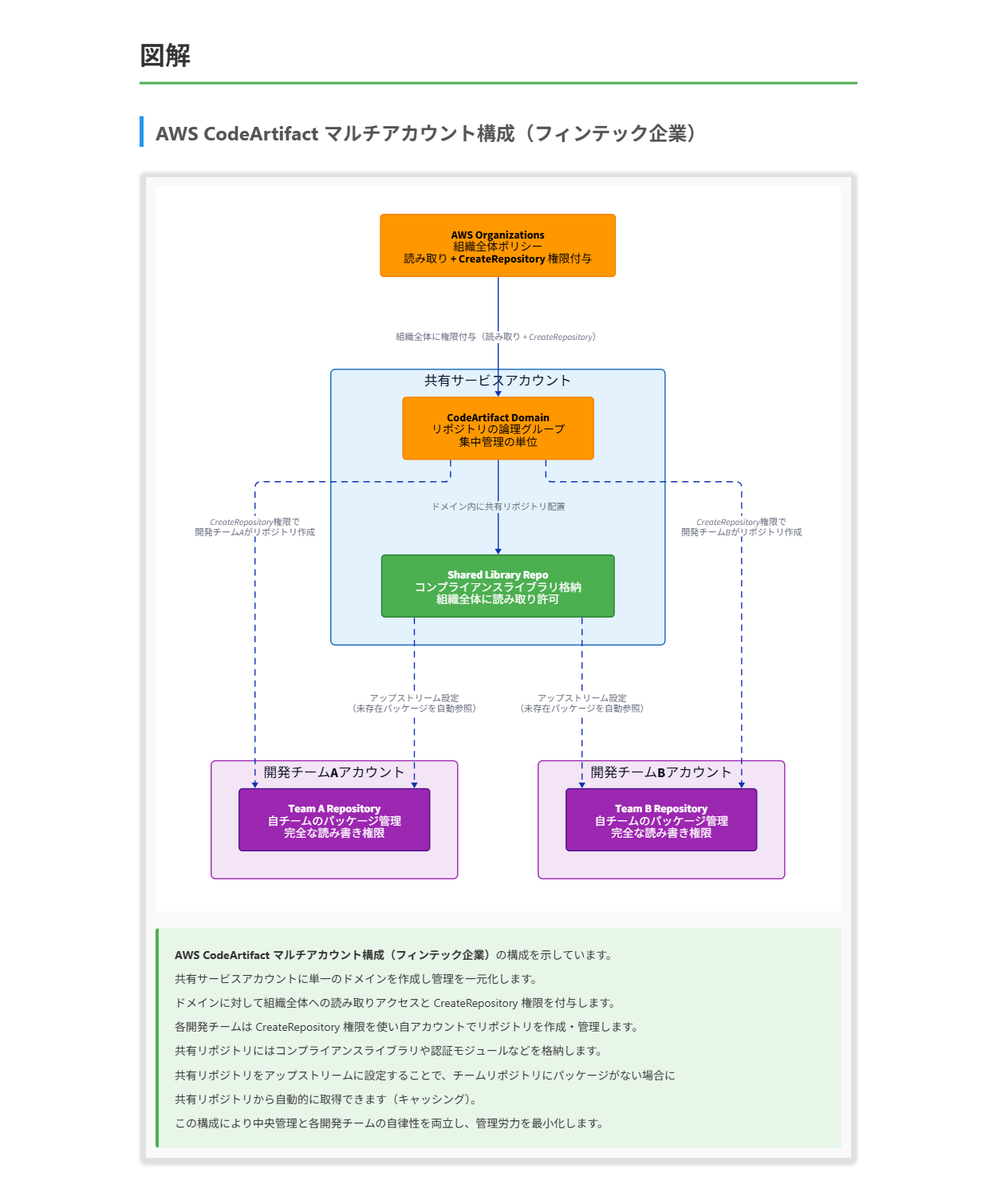
フィンテック企業はAWS Organizationsを利用して複数のAWSアカウントを管理しています。プラットフォームエンジニアはAWS CodeArtifactを導入して金融アプリケーションのパッケージ管理を組織全体でサポートしようとしています。各開発チームには専用のアカウントが割り当てられ、共有サービスアカウントへの制限付きアクセスが設定されています。各チームは自身のパッケージを管理できる十分な権限を持つ必要があり、コンプライアンスライブラリや認証モジュールなどの共有コンポーネントは組織全体でアクセス可能にする必要があります。
この要件を最小限の管理労力で満たすには、どのようなアクションを取るべきでしょうか?(3つ選択してください)
選択肢:
A. 各開発チームのアカウントにドメインを作成し、それぞれのドメイン内で読み取りおよび書き込み権限を付与する。
B. 共有サービスアカウントにドメインを作成し、組織全体の読み取りアクセスと CreateRepository 権限を付与する。
C. 各開発チームのアカウントにリポジトリを作成し、チームにそのリポジトリへの完全な読み取りおよび書き込み権限を付与する。
D. 共有サービスアカウントにリポジトリを作成し、組織全体に読み取りアクセスを付与し、このリポジトリを各開発チームのリポジトリのアップストリームリポジトリとして設定する。
E. チーム間で共有パッケージが必要な場合に、他の開発チームのアカウントからの読み取りアクセスを有効にするリソースポリシーを作成する。
F. 他の開発チームのリポジトリをアップストリームリポジトリとして指定する。
正解:B、C、D
A. 各開発チームのアカウントにドメインを作成し、それぞれのドメイン内で読み取りおよび書き込み権限を付与する。
不正解 この方法では各開発チームのアカウントにCodeArtifactドメインを個別に作成することになります。ドメインは管理の単位であり、各ドメインごとに権限設定やポリシー管理が必要になります。組織全体で多数のチームがある場合、ドメインごとの設定と管理が必要になるため管理オーバーヘッドが大きくなります。
B. 共有サービスアカウントにドメインを作成し、組織全体の読み取りアクセスと CreateRepository 権限を付与する。
正解 共有サービスアカウントに単一のCodeArtifactドメインを作成し、組織全体に読み取りアクセスとリポジトリ作成権限を付与する方法は、管理を一元化できます。ドメインはCodeArtifactの最上位のリソースであり、1つのドメインを中央で管理することで設定の一貫性が保たれます。
C. 各開発チームのアカウントにリポジトリを作成し、チームにそのリポジトリへの完全な読み取りおよび書き込み権限を付与する。
正解 この方法では、各開発チームが自身のアカウント内にリポジトリを作成し、そのリポジトリに対する完全な管理権限を持つことができます。これにより、各チームは自分たちのパッケージを独自に管理できる柔軟性が確保されます。
D. 共有サービスアカウントにリポジトリを作成し、組織全体に読み取りアクセスを付与し、このリポジトリを各開発チームのリポジトリのアップストリームリポジトリとして設定する。
正解 この設定では、共有サービスアカウントにコンプライアンスライブラリや認証モジュールなどの共有コンポーネント用リポジトリを作成し、組織全体がそれを読み取れるようにします。
E. チーム間で共有パッケージが必要な場合に、他の開発チームのアカウントからの読み取りアクセスを有効にするリソースポリシーを作成する。
不正解 各チーム間で個別にリソースポリシーを設定して読み取りアクセスを許可する方法は、チーム数が増えるにつれて管理が複雑になります。
F. 他の開発チームのリポジトリをアップストリームリポジトリとして指定する。
不正解 各チームが他チームのリポジトリを直接アップストリームリポジトリとして指定する方法は、依存関係が複雑になる可能性があります。
全体的な説明
問われている要件
この問題では、AWS Organizationsを使用して複数のAWSアカウントを管理するフィンテック企業が、AWS CodeArtifactを使用して金融アプリケーションのパッケージ管理を組織全体でサポートするための最適な方法を問うています。主な要件は以下の通りです:
- 各開発チームには専用のアカウントがあり、共有サービスアカウントへの制限付きアクセスがある
- 各チームは自身のパッケージを管理する十分な権限が必要
- コンプライアンスライブラリや認証モジュールなどの共有コンポーネントは組織全体でアクセス可能にする必要がある
- これらの要件を最小限の管理労力で満たすこと
これらの要件を満たすためには、中央集権的な管理と各チームの自律性のバランスを取る必要があります。
前提知識
AWS CodeArtifact
AWS CodeArtifactは、ソフトウェア開発プロセスで使用されるパッケージ(ライブラリやフレームワークなど)の管理を行うフルマネージドサービスです。主な特徴と概念は以下の通りです:
- ドメイン(Domain):
- CodeArtifactの最上位のリソースで、リポジトリの論理的なグループ
- 1つのAWSアカウントには複数のドメインを作成可能
- ドメイン内のリポジトリは、同じドメイン内の他のリポジトリをアップストリームとして参照可能
- 異なるAWSアカウント間でドメインを共有することも可能
- リポジトリ(Repository):
- パッケージを格納する場所
- 特定のパッケージタイプ(npm、Maven、PyPI、Nugetなど)をサポート
- 1つのドメインには複数のリポジトリを作成可能
- アップストリームリポジトリ(Upstream Repository):
- あるリポジトリが別のリポジトリをアップストリームとして参照することができる仕組み
- リポジトリ内でパッケージが見つからない場合、アップストリームリポジトリが自動的に検索される
- これにより、パッケージの依存関係を効率的に解決できる
- パッケージが見つかると、そのパッケージは自動的にリポジトリにコピーされる(キャッシング)
- パブリックリポジトリ接続:
- CodeArtifactリポジトリからnpmjs.orgやMaven Centralなどのパブリックリポジトリに接続可能
- これにより、パブリックパッケージを安全に利用できる
- リソースポリシー:
- リソース(ドメインやリポジトリ)へのアクセス制御を細かく設定可能
- 組織内の特定のアカウントやIAMプリンシパルにリソースへのアクセスを許可できる
AWS Organizations
AWS Organizationsは、複数のAWSアカウントを一元管理するためのサービスです。主な機能は以下の通りです:
- アカウント管理:
- 複数のAWSアカウントを組織単位(OU)に整理
- アカウントの一元的な作成と管理
- 一元的なポリシー管理:
- サービスコントロールポリシー(SCP)を使用してアカウント間で一貫したポリシーを適用
- タグポリシーやバックアップポリシーの一元管理
- 一括請求:
- 組織内のすべてのアカウントの一括請求
- ボリュームディスカウントの適用
クロスアカウントアクセス
AWSでは、異なるアカウント間でのリソース共有やアクセス許可を設定する方法がいくつかあります:
- IAMロールの引き受け(AssumeRole):
- あるアカウントのIAMエンティティが別のアカウントのIAMロールを引き受ける
- 一時的な認証情報を使用して、別アカウントのリソースにアクセス
- リソースポリシー:
- S3バケットポリシーやCodeArtifactリソースポリシーなど
- リソース側でどのプリンシパル(ユーザー、ロール、アカウント)がアクセスできるかを定義
- AWS Resource Access Manager(RAM):
- 特定のAWSリソースを複数のアカウントと共有するためのサービス
- 共有可能なリソースタイプは限定的
マルチアカウント戦略のベストプラクティス
- 中央集権型管理:
- 共通サービスやツールは中央のアカウントで管理
- 各チームや環境に専用のアカウントを提供
- 最小権限の原則:
- 各アカウントやIAMエンティティには必要最小限の権限のみを付与
- 権限の範囲を制限することでセキュリティリスクを最小化
- 自律性とガバナンスのバランス:
- チームに十分な自律性を与える一方で、組織全体の一貫性やコンプライアンスを確保
- ガードレールを設定しつつ、イノベーションを妨げない
解くための考え方
この問題を解くためには、以下の点を考慮する必要があります:
- 管理の複雑さを最小化:
- 多数のドメインやリポジトリを個別に管理するのではなく、中央で管理する方法を検討
- 権限設定やポリシー管理の回数を減らす方法を考える
- チームの自律性の確保:
- 各チームが自身のパッケージを独自に管理できる権限を確保
- チーム固有の開発サイクルに影響を与えない構成を検討
- 共有コンポーネントへのアクセス:
- 組織全体で共有コンポーネントにアクセスする効率的な方法を検討
- 一貫性のあるバージョン管理と配布を確保
これらの考慮点に基づくと、最適な解決策は以下の組み合わせになります:
- 共有サービスアカウントに1つのドメインを作成し、組織全体に読み取りアクセスとCreateRepository権限を付与する
- 各チームがそのドメイン内に自分たちのリポジトリを作成し、そのリポジトリに対する完全な管理権限を持つ
- 共有コンポーネント用のリポジトリを共有サービスアカウントに作成し、それを各チームのリポジトリのアップストリームリポジトリとして設定する
この組み合わせにより、中央管理と各チームの自律性のバランスを取りながら、最小限の管理労力で要件を満たすことができます。
参考資料
問題文:
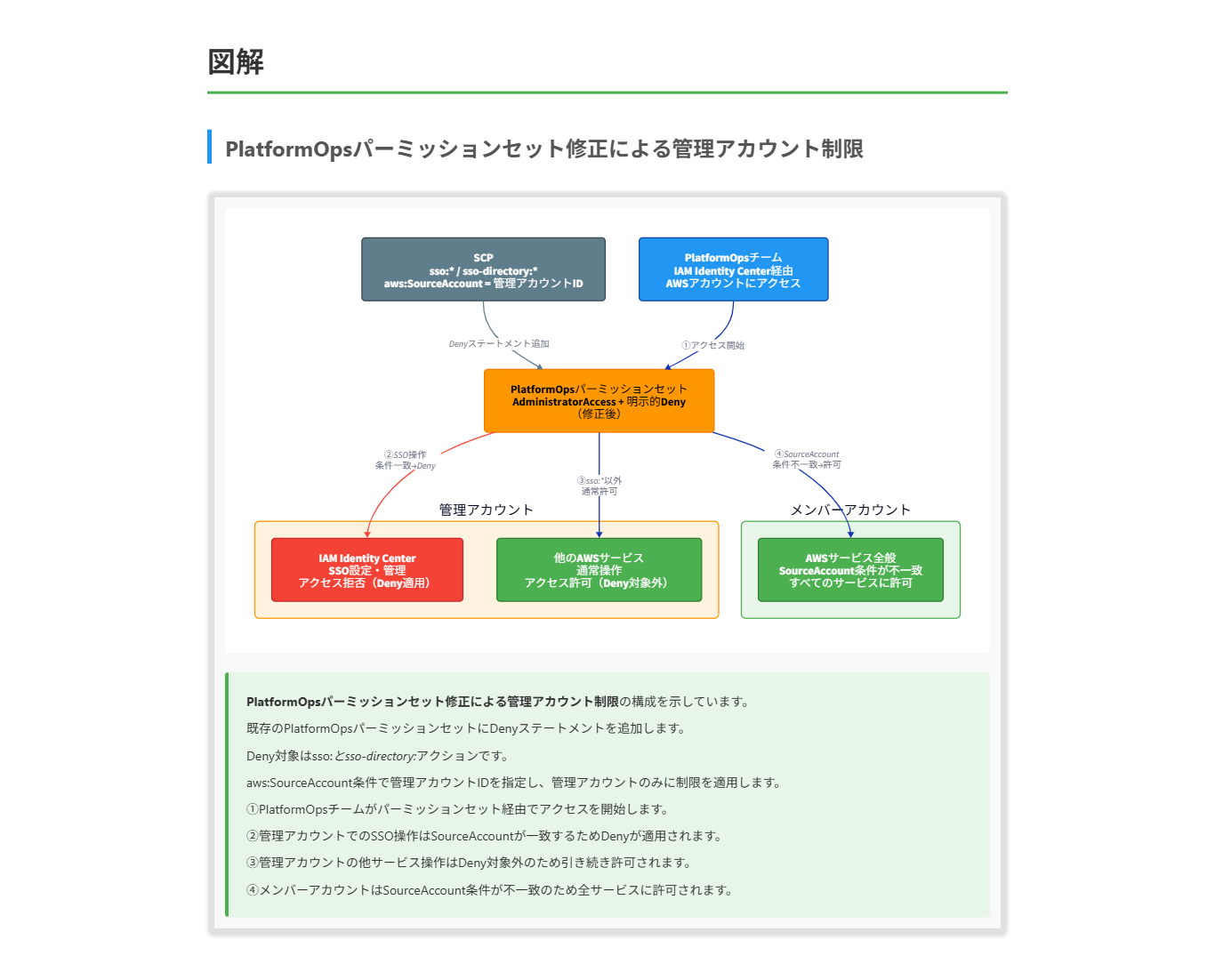
ある医療テクノロジー企業は AWS Organizations を利用しており、ガバナンスチームとプラットフォームチームが共同で管理しています。
両チームは AWS IAM Identity Center を利用してアカウントにアクセスしています。プラットフォームグループには「PlatformOps」という名前のパーミッションセットが関連付けられており、これは AdministratorAccess IAM 管理ポリシーを含んでいます。このパーミッションセットは、組織内のすべてのアカウントに適用されています。
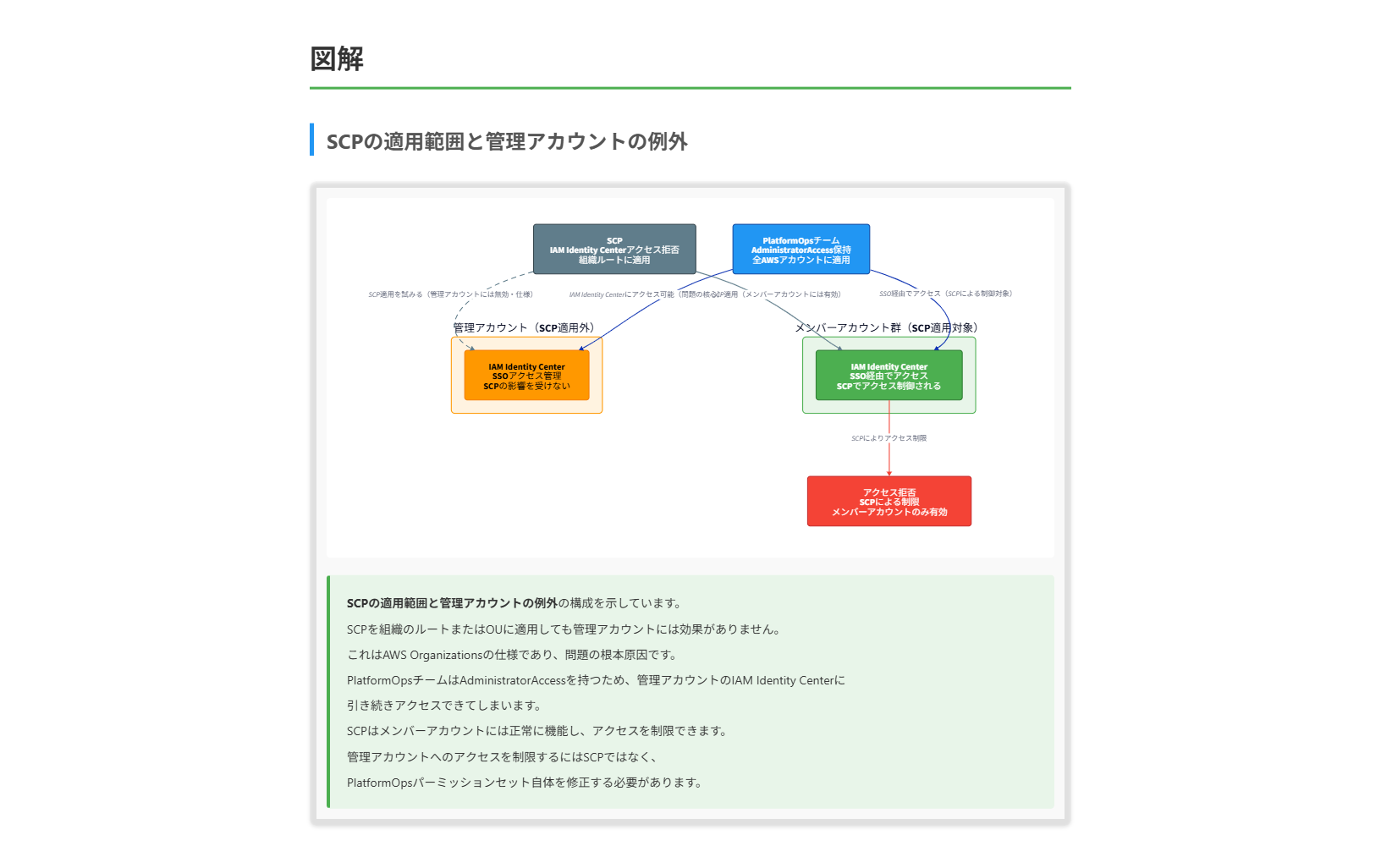
ガバナンスチームは、管理アカウント内でプラットフォームチームが IAM Identity Center にアクセスできないようにするため、組織のルートに SCP を適用しました。しかし、この SCP にもかかわらず、プラットフォームチームは IAM Identity Center にアクセスできています。
この問題を解決するにはどうすればよいでしょうか?
選択肢:
A. 管理アカウント用の新しい組織単位 (OU) を作成し、アカウントをそこに移動する。現在の SCP を削除し、新しい OU に適用する。
B. 管理アカウント内の SCP を修正し、プラットフォームグループのロール ARN を参照する条件を追加して、管理アカウントの AWS ID を含める。
C. IAM Identity Center に新しいパーミッションセットを作成し、一般的なアクセスを許可するが、sso:* および sso-directory:* アクションを明示的に拒否する。このパーミッションセットをプラットフォームグループに管理アカウント内で割り当てる。
D. 現在の PlatformOps パーミッションセットを修正し、sso:* および sso-directory:* アクションを拒否する明示的な条件を追加し、aws:SourceAccount と管理アカウント ID を比較する条件を含める。
正解:D
A. 管理アカウント用の新しい組織単位 (OU) を作成し、アカウントをそこに移動する。現在の SCP を削除し、新しい OU に適用する。
不正解 この方法には根本的な問題があります。サービスコントロールポリシー(SCP)は組織内の管理アカウントには効果がないという特性があります。SCPは管理アカウント以外のメンバーアカウントにのみ影響します。そのため、管理アカウントを新しいOUに移動し、そのOUにSCPを適用したとしても、SCPは管理アカウントには影響せず、プラットフォームチームは引き続きIAM Identity Centerにアクセスできてしまいます。SCPを使用しての管理アカウントへのアクセス制限は不可能です。
B. 管理アカウント内の SCP を修正し、プラットフォームグループのロール ARN を参照する条件を追加して、管理アカウントの AWS ID を含める。
不正解 この方法には根本的な問題があります。サービスコントロールポリシー(SCP)は組織内の管理アカウントには効果がないという特性があります。SCPは管理アカウント以外のメンバーアカウントにのみ影響します。そのため、SCPを修正して条件を追加しても、管理アカウント内でのプラットフォームチームの権限には影響しません。
C. IAM Identity Center に新しいパーミッションセットを作成し、一般的なアクセスを許可するが、sso:* および sso-directory:* アクションを明示的に拒否する。このパーミッションセットをプラットフォームグループに管理アカウント内で割り当てる。
不正解 この方法は、既存のパーミッションセット(AdministratorAccess)と競合する新しいパーミッションセットを作成するため複雑になります。プラットフォームグループにはすでに「PlatformOps」という名前のパーミッションセットが割り当てられており、それにはAdministratorAccessポリシーが含まれています。このパーミッションセットを残したまま新しいパーミッションセットを追加しても、IAMの評価ロジックにより、明示的な拒否がない限り許可が優先されるため、既存のAdministratorAccessポリシーが引き続き有効になる可能性があります。
D. 現在の PlatformOps パーミッションセットを修正し、sso:* および sso-directory:* アクションを拒否する明示的な条件を追加し、aws:SourceAccount と管理アカウント ID を比較する条件を含める。
正解 この方法は、既存のPlatformOpsパーミッションセットを直接修正し、管理アカウントでのIAM Identity Center関連のアクション(sso:およびsso-directory:)を明示的に拒否する条件を追加するアプローチです。aws:SourceAccount条件キーを使用して管理アカウントIDと一致する場合にのみこの制限を適用することで、他のアカウントでの権限には影響を与えずに、管理アカウントでのIAM Identity Centerへのアクセスを制限できます。パーミッションセットの修正は、既存の権限構造を大きく変更せずに目的を達成できます。
全体的な説明
問われている要件
この問題では、AWS Organizationsを利用している医療テクノロジー企業において、プラットフォームチームが管理アカウント内でIAM Identity Centerにアクセスできないようにする方法を問うています。現状、プラットフォームチームには「PlatformOps」という名前のパーミッションセットが割り当てられており、そのパーミッションセットにはAdministratorAccess IAM管理ポリシーが含まれています。ガバナンスチームは組織のルートにSCPを適用してアクセスを制限しようとしましたが、プラットフォームチームは依然としてアクセスできています。問題を解決するための最も効果的な方法を選択する必要があります。
前提知識
AWS Organizations
AWS Organizationsは、複数のAWSアカウントを一元管理するためのサービスで、以下の主要な特性があります:
- 組織構造:
- 管理アカウント:組織の作成と管理を行う最上位のアカウント
- メンバーアカウント:組織に属する他のアカウント
- 組織単位(OU):アカウントを論理的にグループ化する構造
- サービスコントロールポリシー(SCP):
- 組織内のアカウントに対するアクセス許可の上限を設定するポリシー
- IAMユーザーやロールが持つ権限の「ガードレール」として機能
- 重要な制限: SCPは管理アカウントには適用されない
- 一括請求:
- 組織内のすべてのアカウントの使用料を一括で管理
IAM Identity Center (旧AWS SSO)
IAM Identity Centerは、複数のAWSアカウントとアプリケーションへのシングルサインオンアクセスを提供するサービスです:
- パーミッションセット:
- IAM Identity Centerで定義される権限のコレクション
- AWS管理ポリシー(例:AdministratorAccess)をベースにすることができる
- カスタム権限を定義することも可能
- グループと割り当て:
- IDプロバイダー(例:Active Directory)から同期されたユーザーグループ
- グループにパーミッションセットを割り当て、それを特定のAWSアカウントに適用
- アクセス制御:
- パーミッションセットはIAMロールとして各アカウントにプロビジョニングされる
- ユーザーがアカウントにアクセスすると、対応するIAMロールが引き受けられる
IAMポリシーの評価ロジック
IAMポリシーは以下のロジックで評価されます:
- 明示的な拒否:ポリシー内に明示的な拒否(”Effect”: “Deny”)がある場合、そのアクセスは拒否される
- 明示的な許可:明示的な拒否がなく、明示的な許可(”Effect”: “Allow”)がある場合、アクセスは許可される
- 暗黙的な拒否:明示的な許可がない場合、デフォルトでアクセスは拒否される
IAMポリシーの条件キー
IAMポリシーには条件キーを使用して、ポリシーが適用される条件を詳細に指定できます:
- aws:SourceAccount:リクエストの送信元のアカウントIDを指定
- aws:PrincipalOrgID:プリンシパルが属する組織IDを指定
- aws:ResourceAccount:リソースが属するアカウントIDを指定
解くための考え方
この問題を解決するためには、以下の要点を考慮する必要があります:
- SCPの制限を理解する:
- SCPは管理アカウントには適用されないため、管理アカウント内でのアクセス制限には別のアプローチが必要
- プラットフォームチームがIAM Identity Centerにアクセスできている原因はここにある
- パーミッションセットの役割を理解する:
- プラットフォームチームには「PlatformOps」という名前のパーミッションセットが割り当てられている
- このパーミッションセットにはAdministratorAccess IAM管理ポリシーが含まれている
- この広範な権限により、プラットフォームチームは管理アカウント内でIAM Identity Centerにアクセスできる
- 最小特権の原則を適用する:
- プラットフォームチームには必要な権限を維持しつつ、IAM Identity Centerへのアクセスのみを制限する
- 具体的には、sso:*およびsso-directory:*アクションを制限する
- 条件付きアクセス制御を実装する:
- 特定のアカウント(管理アカウント)でのみ制限を適用するために条件キーを使用する
- aws:SourceAccountを使用して、管理アカウントIDと一致する場合にのみ制限を適用する
これらの考慮点を踏まえると、最適なアプローチは既存のPlatformOpsパーミッションセットを修正し、管理アカウントでのIAM Identity Center関連アクションを明示的に拒否することです。これにより、プラットフォームチームは他のリソースやメンバーアカウントへのアクセスを維持しつつ、管理アカウント内でのIAM Identity Centerへのアクセスが制限されます。
パーミッションセットの修正例:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Deny",
"Action": [
"sso:*",
"sso-directory:*"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "管理アカウントID"
}
}
},
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}
]
}このポリシーでは、管理アカウントからのリクエストの場合にのみsso:*およびsso-directory:*アクションを明示的に拒否し、それ以外のすべてのアクションを許可しています。
参考資料
問題文:
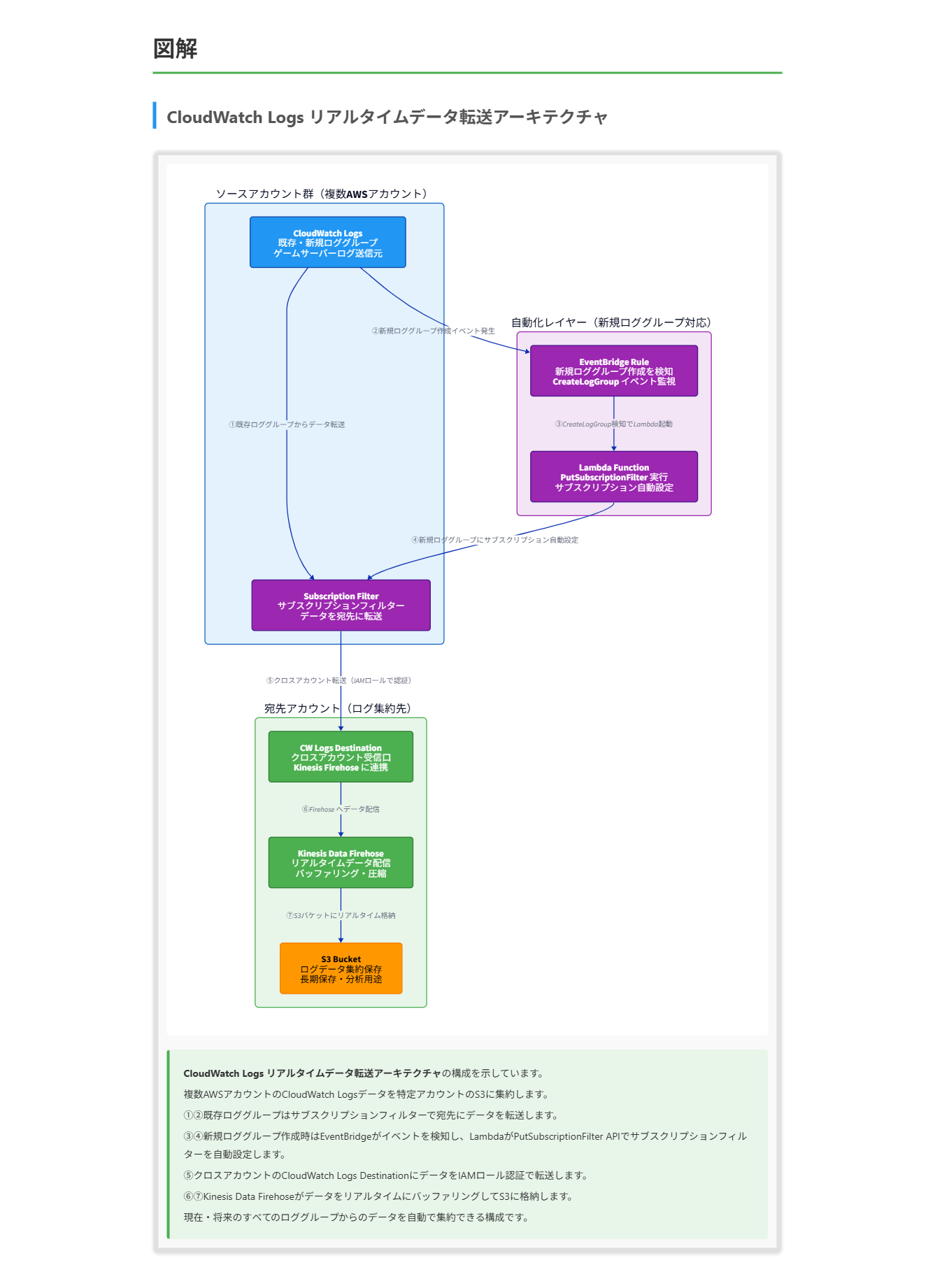
グローバルなオンラインゲームサービスを運営する企業が、AWS Organizations で複数の AWS アカウントを管理しています。セキュリティ監査およびコンプライアンス対応の要件から、すべてのゲームサーバーおよびマイクロサービスが出力する Amazon CloudWatch Logs のデータをリアルタイムに中央ログ集約用の特定の AWS アカウント内の Amazon S3 バケットへ転送するアーキテクチャが必要です。このソリューションは現在稼働中のロググループと今後新たに作成されるロググループの両方をカバーしなければなりません。この要件を満たすアプローチはどれですか?
選択肢:
A. AWS Organizations の組織バックアップポリシーを作成し、すべてのロググループデータを中央集約用の S3 バケットに保存するよう設定する。S3 バケットポリシーを更新して、組織内のすべてのゲームアカウントがアクセスできるようにする。
B. AWS Backup を使用してバックアッププランを作成し、中央集約用の S3 バケットをリポジトリとして指定する。ゲームサーバーのロググループリソースをプランに割り当て、組織内のすべてのゲームアカウントを対象に含める。
C. AWS Backup を使用して中央集約 S3 バケットを対象とするバックアッププランを作成する。現在稼働中のすべてのロググループをプランにリンクし、組織内のすべてのゲームアカウントを対象に含める。AWS Systems Manager Automation を使用して新しいロググループを関連付け、AWS Config ルールと自動修正を使用して実装する。
D. 中央ログ集約アカウントで CloudWatch Logs の出力先(Destination)を作成し、Amazon Kinesis Data Firehose ストリームを設定してターゲットとして S3 バケットを指定する。現在稼働中のロググループにはサブスクリプションフィルターを設定し、AWS Lambda 関数と Amazon EventBridge ルールを使用して CloudWatch Logs PutSubscriptionFilter API を自動化し、今後作成される新しいロググループを自動的にキャプチャする。
正解:D
A. AWS Organizations の組織バックアップポリシーを作成し、すべてのロググループデータを中央集約用の S3 バケットに保存するよう設定する。S3 バケットポリシーを更新して、組織内のすべてのゲームアカウントがアクセスできるようにする。
不正解 AWS Organizations のバックアップポリシーは主に AWS Backup サービスを制御するためのものであり、CloudWatch Logs データを直接 S3 バケットにリアルタイムに転送する機能はありません。
B. AWS Backup を使用してバックアッププランを作成し、中央集約用の S3 バケットをリポジトリとして指定する。ゲームサーバーのロググループリソースをプランに割り当て、組織内のすべてのゲームアカウントを対象に含める。
不正解 AWS Backup は現在 CloudWatch Logs をネイティブにサポートしていないため、このアプローチは技術的に実装できません。AWS Backup は主に EC2 インスタンス、RDS データベース、DynamoDB テーブル、EFS ファイルシステムなどのリソースのバックアップを管理するためのサービスであり、CloudWatch Logs リソースは直接のバックアップ対象として設定できません。また、AWS Backup は定期的なスナップショットによるバックアップを行うサービスであり、リアルタイムデータ転送という要件も満たせません。
C. AWS Backup を使用して中央集約 S3 バケットを対象とするバックアッププランを作成する。現在稼働中のすべてのロググループをプランにリンクし、組織内のすべてのゲームアカウントを対象に含める。AWS Systems Manager Automation を使用して新しいロググループを関連付け、AWS Config ルールと自動修正を使用して実装する。
不正解 AWS Backup は CloudWatch Logs をネイティブにサポートしていません。また、AWS Backup と Systems Manager を組み合わせたアプローチは複雑であり、リアルタイムのログデータ転送には不適切です。この方法では新しいロググループの処理に手動設定が必要になる可能性が高いです。
D. 中央ログ集約アカウントで CloudWatch Logs の出力先(Destination)を作成し、Amazon Kinesis Data Firehose ストリームを設定してターゲットとして S3 バケットを指定する。現在稼働中のロググループにはサブスクリプションフィルターを設定し、AWS Lambda 関数と Amazon EventBridge ルールを使用して CloudWatch Logs PutSubscriptionFilter API を自動化し、今後作成される新しいロググループを自動的にキャプチャする。
正解 このアプローチはゲームサービスの CloudWatch Logs データをリアルタイムで特定の S3 バケットに転送するという要件を満たしています。主要コンポーネントは以下の通りです:
全体的な説明
問われている要件
この問題では、AWS Organizations に複数のアカウントを持つゲーム企業が、以下の要件を満たすソリューションを求めています:
- CloudWatch Logs のデータをリアルタイムに特定の AWS アカウント内の S3 バケットに転送する
- 現在のロググループと将来作成されるロググループの両方を対象にする
つまり、複数アカウントにわたるすべての CloudWatch Logs データを集約し、リアルタイムで特定のアカウントの S3 バケットに保存する必要があります。また、新しいロググループが作成された場合にも、自動的にこのデータ転送設定が適用される必要があります。
前提知識
CloudWatch Logs
Amazon CloudWatch Logsは、ログデータを保存、監視、アクセスするためのAWSサービスです。主な機能と概念は以下の通りです:
- ロググループ:
- ログストリームの論理的なグループ
- アプリケーション、サービス、環境ごとに作成されることが多い
- 保持期間、アクセス制御などの設定はロググループレベルで適用される
- ログストリーム:
- 同じソースからのイベントシーケンス
- 例えば、1つのアプリケーションインスタンスからのログなど
- サブスクリプションフィルター:
- ロググループからリアルタイムでデータを他のAWSサービスに転送するための仕組み
- サポートされる宛先には、Lambda、Kinesis Data Streams、Kinesis Data Firehose、別のアカウントのCloudWatch Logs宛先などがある
- クロスアカウントデータ共有:
- CloudWatch Logs宛先(Destination)を使用して、あるアカウントのログデータを別のアカウントに送信することができる
- 宛先アカウントではIAMロールを使用してアクセス制御を設定できる
Amazon Kinesis Data Firehose
Amazon Kinesis Data Firehoseは、ストリーミングデータを目的の宛先にリアルタイムで配信するためのフルマネージドサービスです:
- 主な特徴:
- データの変換、バッチ処理、圧縮をサポート
- 宛先には、S3、Redshift、Elasticsearch、Splunkなどがある
- バッファリング、リトライなどの機能を提供
- CloudWatch Logsとの統合:
- サブスクリプションフィルターとCloudWatch Logs宛先を通じて、CloudWatch LogsからFirehoseにデータを直接送信可能
- データをS3に保存する前に処理または変換することができる
AWS Lambda
AWS Lambdaは、サーバーレスでコードを実行するサービスで、イベント駆動のアプリケーションを構築するのに適しています:
- 主な特徴:
- サーバー管理不要でコードを実行
- さまざまなイベントソースからトリガー可能
- AWSのサービスと連携して自動化タスクを実行
- CloudWatch Logsとの統合:
- CloudWatch Logsからイベントを受け取り処理することができる
- PutSubscriptionFilter APIを呼び出して、サブスクリプションフィルターを動的に設定できる
Amazon EventBridge
Amazon EventBridgeは、イベント駆動型アーキテクチャを構築するためのサーバーレスイベントバスサービスです:
- 主な特徴:
- イベントパターンに基づいてルールを定義
- イベントが発生したときに特定のアクションをトリガー
- 複数のAWSサービスとの統合
- CloudWatch Logsとの統合:
- ロググループの作成など、CloudWatch Logsのイベントを検出可能
- 検出したイベントに基づいて、Lambda関数などのターゲットを起動できる
AWS Organizations
AWS Organizationsは、複数のAWSアカウントを一元管理するためのサービスです:
- 主な特徴:
- 複数のAWSアカウントを組織単位にグループ化
- 一元的なポリシー管理を提供
- アカウント間のリソース共有をサポート
- リソース共有:
- 特定のS3バケットに対するアクセス許可を組織内の複数アカウントに付与可能
- IAMロールとリソースポリシーを使用して、クロスアカウントアクセスを設定
解くための考え方
この問題を解決するためには、以下の要素を考慮する必要があります:
- リアルタイムデータ転送:
- CloudWatch Logsデータをリアルタイムで転送する方法を選択する
- データの遅延を最小限に抑える必要がある
- クロスアカウント設定:
- 複数アカウントからのデータを単一のアカウントに集約する方法を設計する
- 適切なアクセス制御を確保する
- 自動化と将来のロググループ対応:
- 新しいロググループが作成されたときに自動的に設定を適用する方法を検討する
- 継続的なメンテナンスを最小限に抑える
これらの要素を考慮した上で、以下のソリューションが最適であると判断できます:
- CloudWatch Logs宛先の設定:
- 特定のアカウントにCloudWatch Logs宛先を作成
- 宛先をKinesis Data Firehoseストリームに設定
- Kinesis Data Firehoseの設定:
- FirehoseストリームのターゲットをS3バケットに設定
- 適切なバッファリング、圧縮、パーティション設定を行う
- サブスクリプションフィルターの設定:
- 既存のロググループにサブスクリプションフィルターを設定
- フィルターを通じてデータをCloudWatch Logs宛先に送信
- 自動化の実装:
- EventBridgeルールを設定して新しいロググループの作成を検出
- Lambda関数を使用して新しいロググループにサブスクリプションフィルターを自動的に適用
このアプローチは、現在と将来のロググループからのデータをリアルタイムで指定のS3バケットに転送するという要件を満たします。
参考資料
問題文:
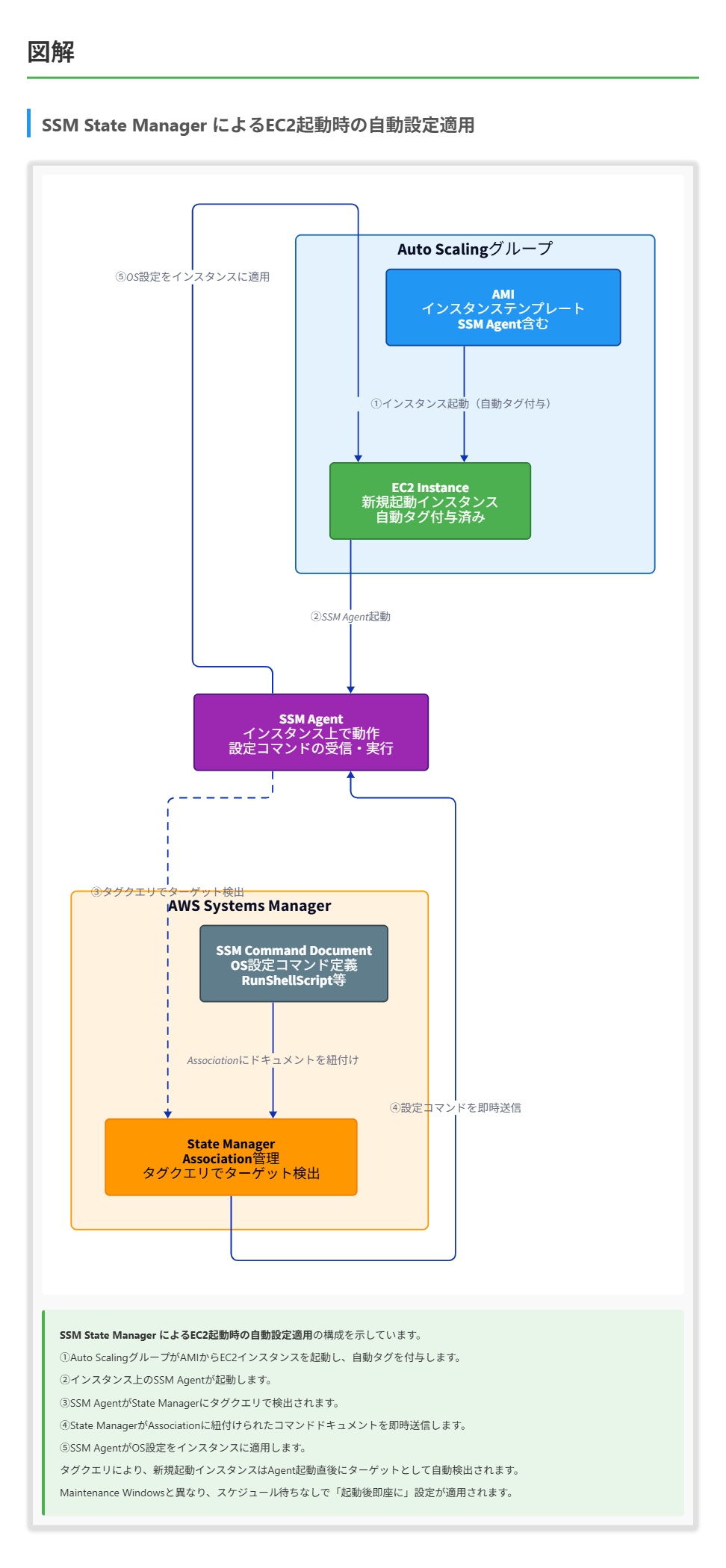
ある自動車部品メーカーは、工場の生産ライン管理システムをAmazon EC2 Auto Scalingグループで運用しています。このグループは、AWS Systems Manager Agentがプリインストールされた社内承認済みのAMIからEC2インスタンスを起動します。Auto Scalingグループによって起動されたインスタンスには、管理用のタグが自動的に付与されます。
社内のセキュリティポリシーに従い、これらのEC2インスタンスが規定されたオペレーティングシステムのセキュリティ設定をインスタンス起動直後に確実に満たす必要があります。
この要件を効率的に満たすためには、どのアプローチが適切でしょうか?
選択肢:
A. インスタンスのOS設定内容を定義したSystems Manager Run Commandドキュメントを用意し、インスタンスが社内セキュリティポリシーに準拠していない場合にRun Commandを実行するよう、Systems Manager Complianceを構成する。
B. OS設定を定義したSystems Managerコマンドドキュメントに関連付けられたState Manager関連付けを作成し、Auto Scalingグループが付与するタグをターゲットクエリとして使用することで、起動直後のインスタンスに即時設定を適用する。
C. 必要なOS設定を適用するSystems Manager Run Commandドキュメントを作成し、Auto Scalingグループのタグと一致するインスタンスをターゲットとして、Systems Manager Maintenance Windowsで毎日実行するようスケジュールする。
D. Systems Manager Patch Managerでセキュリティパッチのベースラインを定義し、Auto Scalingグループと同一のタグを使用してパッチグループを設定する。そのグループをベースラインに関連付け、Systems Manager Run Commandを使用してパッチ適用を実行する。
正解:B
A. インスタンスのOS設定内容を定義したSystems Manager Run Commandドキュメントを用意し、インスタンスが社内セキュリティポリシーに準拠していない場合にRun Commandを実行するよう、Systems Manager Complianceを構成する。
不正解 このアプローチには複数の問題があります。Systems Manager Complianceは主にインスタンスのパッチ適用状況やアソシエーションコンプライアンスを評価するためのものであり、自動的に構成を適用するツールではありません。コンプライアンスの評価は通常、インスタンスが一定期間稼働した後に行われるため、「起動後に即座に」という要件を満たせません。
B. OS設定を定義したSystems Managerコマンドドキュメントに関連付けられたState Manager関連付けを作成し、Auto Scalingグループが付与するタグをターゲットクエリとして使用することで、起動直後のインスタンスに即時設定を適用する。
正解 Systems Manager State Managerは、EC2インスタンスの設定を定義し維持するための最適なツールです。関連付け(Association)を作成し、Auto Scalingグループによって自動的に付与されるタグをターゲットとして使用することで、新しく起動されたインスタンスを即座に識別し、必要な構成を適用できます。
C. 必要なOS設定を適用するSystems Manager Run Commandドキュメントを作成し、Auto Scalingグループのタグと一致するインスタンスをターゲットとして、Systems Manager Maintenance Windowsで毎日実行するようスケジュールする。
不正解 Maintenance Windowsは、定期的なメンテナンス作業をスケジュールするためのものであり、インスタンス起動後に即座に構成を適用するという要件には適していません。毎日のスケジュールでは、新しく起動されたインスタンスが次のメンテナンスウィンドウまで最大24時間待機する可能性があります。この間、インスタンスは必要な構成を満たしていない状態で稼働することになり、「起動後に即座に」という要件を満たせません。また、Maintenance Windowsは特定の時間帯に実行されるため、Auto Scalingによって起動時間がばらつくインスタンスに対しては効率的ではありません。
D. Systems Manager Patch Managerでセキュリティパッチのベースラインを定義し、Auto Scalingグループと同一のタグを使用してパッチグループを設定する。そのグループをベースラインに関連付け、Systems Manager Run Commandを使用してパッチ適用を実行する。
不正解 Patch Managerは、セキュリティパッチやソフトウェア更新プログラムの適用を管理するためのツールであり、オペレーティングシステムの構成管理を主な目的としていません。パッチベースラインは、どのパッチを適用するかを定義するもので、オペレーティングシステムの設定には直接関係ありません。また、パッチ適用作業は通常、インスタンス起動直後ではなく、スケジュールに従って実行されるため、「起動後に即座に」という要件を満たせません。さらに、パッチ適用はシステム設定とは別の作業であり、この方法では必要なオペレーティングシステム設定を確実に適用できません。
全体的な説明
問われている要件
この問題では、Amazon EC2 Auto Scalingグループから起動されるインスタンスが、起動後に即座に適切なオペレーティングシステムの設定を満たす必要があります。重要なポイントは以下の通りです:
- EC2インスタンスはAuto Scalingグループによって作成される
- インスタンスには既にSystems Manager Agent(SSM Agent)がインストールされている
- インスタンスには自動的にタグが付与される
- 必要な構成を「起動後に即座に」適用する必要がある
これらの要件を踏まえて、起動されたインスタンスに効率的に設定を適用する方法を選択する必要があります。
前提知識
AWS Systems Manager (SSM)
AWS Systems Managerは、AWSリソースの管理を自動化するためのサービスです。主要なコンポーネントは以下の通りです:
- SSM Agent:
- EC2インスタンスにインストールされるソフトウェア
- Systems Managerサービスとインスタンス間の通信を可能にする
- コマンドの実行、パッチ適用、インベントリ収集などの機能を提供
- State Manager:
- インスタンスの設定を定義し、維持するためのサービス
- 関連付け(Association)を通じて、インスタンスに対する設定を適用
- インスタンスが起動するとすぐに適用される(SSM Agentが動作開始すれば)
- スケジュールに基づいて定期的に適用することも可能
- Run Command:
- インスタンスでコマンドをリモートで実行するサービス
- オンデマンドで実行される
- コマンドドキュメントを使用してタスクを定義
- Maintenance Windows:
- 定期的なメンテナンス作業をスケジュールするためのサービス
- 特定の時間帯にタスクを実行
- Patch Manager:
- パッチの適用を管理するためのサービス
- パッチベースラインを使用して適用するパッチを定義
- Compliance:
- パッチ適用状況やアソシエーションコンプライアンスを評価するサービス
- 設定の適用自体は行わない
EC2インスタンスのタグ付けとターゲティング
AWSリソースに対するタグ付けは、リソースの識別や整理に役立ちます。Systems Managerでは、タグを使用してターゲットインスタンスを指定できます:
- タグクエリ:
- 特定のタグキーと値に基づいてインスタンスを動的に選択
- 例:tag:Environment=Production
- Auto Scalingグループとタグ:
- Auto Scalingグループは、起動するインスタンスに自動的にタグを付与できる
- これらのタグを使用して、Systems Manager操作のターゲットを指定できる
解くための考え方
この問題の要件を満たすためには、以下の点を考慮する必要があります:
- 即時性:
- インスタンス起動後すぐに設定を適用する必要がある
- 定期的なスケジュールではなく、イベント駆動型のアプローチが望ましい
- 自動化:
- 手動介入なしで設定を適用できる
- Auto Scalingによって動的に変化するインスタンス群を対象にできる
- 一貫性:
- すべてのインスタンスに同じ設定が確実に適用される
- 設定のドリフトを防止する
これらの要件を満たすベストプラクティスは、Systems Manager State Managerを使用することです。State Managerの関連付けは、インスタンスの起動時に自動的に適用され、定義された状態を維持します。タグを使用してターゲットを指定することで、Auto Scalingグループによって起動される新しいインスタンスも自動的に対象になります。
State Managerを使用した具体的な実装手順は以下の通りです:
- システム設定を定義するコマンドドキュメント(例:AWS-RunPowerShellScriptやAWS-RunShellScript)を作成または選択
- State Manager関連付けを作成し、以下を設定:
- 作成したコマンドドキュメントを指定
- Auto Scalingグループが付与するタグを使用してターゲットを指定(例:tag:AutoScalingGroupName=my-asg)
- 関連付けの適用頻度を設定(この場合は「即時」実行が望ましい)
- 関連付けを有効化
この方法により、新しく起動されたインスタンスは、SSM Agentが動作を開始するとすぐに必要な設定が適用されます。また、State Managerは定期的に設定の状態を確認し、必要に応じて再適用するため、設定のドリフトも防止できます。
参考資料
問題文:
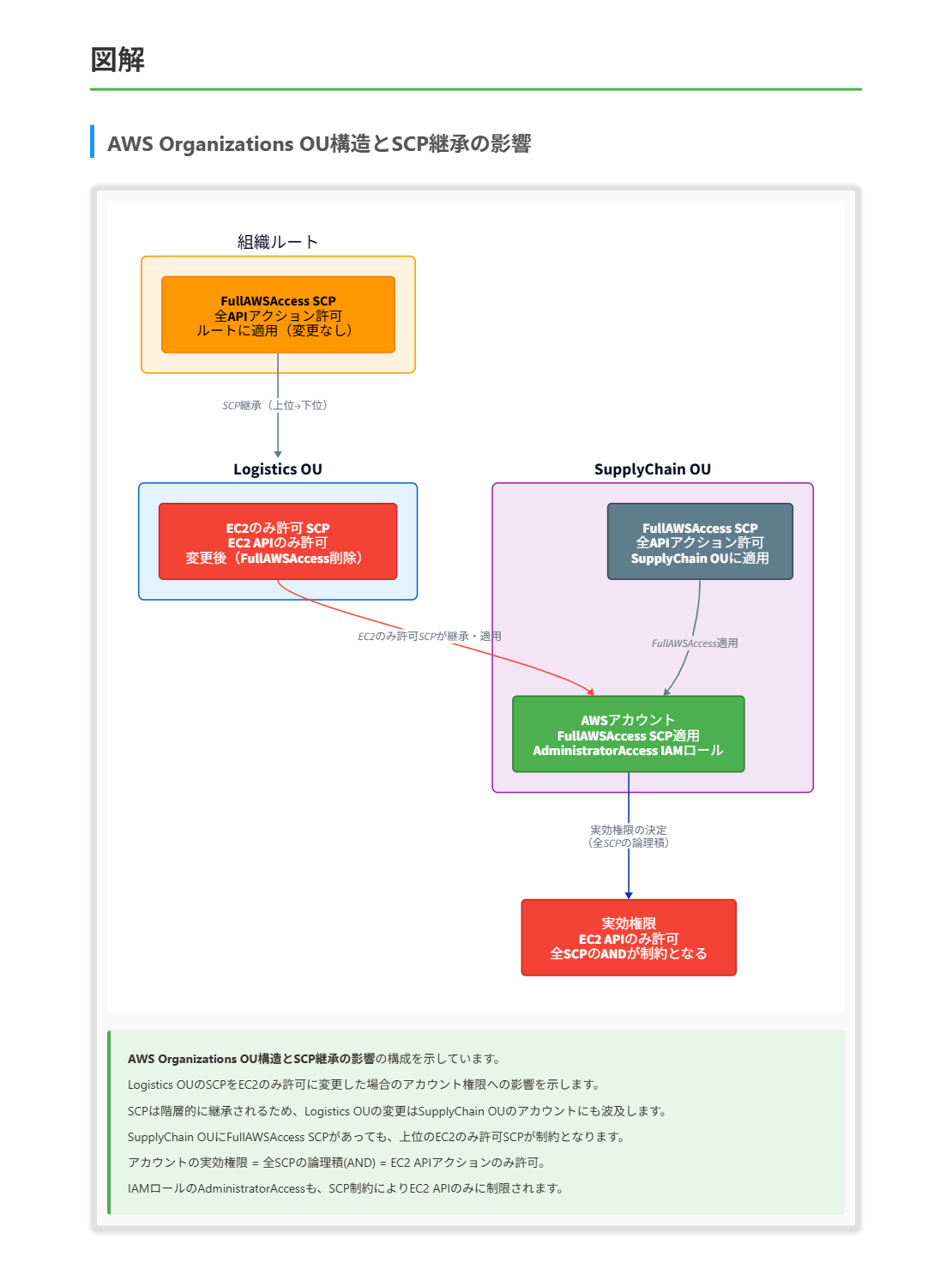
ある大手物流企業はAWS Organizationsを使用してAWSアカウントを管理しています。組織のルートには「Logistics」というOUがあり、その下に「SupplyChain」という子OUがあります。
デフォルトのService Control Policy(SCP)である「FullAWSAccess」は、ルート、Logistics OU、およびSupplyChain OUに適用されています。SupplyChain OUには複数のAWSアカウントが含まれており、それぞれのアカウントにはAdministratorAccess管理ポリシーを持つシステム管理者IAMロールが設定されています。各アカウントにはFullAWSAccess SCPも適用されています。クラウドエンジニアはLogistics OUからFullAWSAccess SCPを削除し、Amazon EC2 APIアクションのみを許可するSCPに置き換えようとしています。
この変更がシステム管理者IAMロールの権限にどのような影響を与えるかを選択してください。
選択肢:
A. すべてのAPIアクションが許可される。
B. EC2 APIアクションのみが許可され、それ以外のAPIはすべて拒否される。
C. すべてのリソースに対するすべてのAPIアクションへのアクセスが禁止される。
D. EC2 APIアクションは拒否され、それ以外のAPIはすべて許可される。
正解:B
A. すべてのAPIアクションが許可される。
不正解 Service Control Policy(SCP)はAWS Organizationsの機能であり、組織内のアカウントで利用可能な最大権限を制限します。SCPは「許可リスト」として機能し、明示的に許可されていないアクションは実行できません。Logistics OUからFullAWSAccess SCPを削除し、EC2 APIアクションのみを許可するSCPに置き換えた場合、Logistics OU下の全アカウント(つまりSupplyChain OUのアカウントも含む)で利用可能な最大権限はEC2 APIアクションのみになります。
B. EC2 APIアクションのみが許可され、それ以外のAPIはすべて拒否される。
正解 Service Control Policy(SCP)はアカウントで実行可能な最大権限セットを定義します。SCPがEC2 APIアクションのみを許可する場合、IAMポリシー(この場合はAdministratorAccess)がより広範な権限を付与していても、実際に使用できる権限はSCPとIAMポリシーの共通部分に制限されます。
C. すべてのリソースに対するすべてのAPIアクションへのアクセスが禁止される。
不正解 SCPをEC2 APIアクションのみを許可するものに変更しても、EC2 APIアクションへのアクセスは引き続き許可されます。SCPは「許可リスト」として機能するため、明示的に許可されたAPIアクション(この場合はEC2 API)は引き続き使用可能です。したがって、すべてのAPIアクションが禁止されるわけではなく、EC2 APIアクションは引き続き許可されます。
D. EC2 APIアクションは拒否され、それ以外のAPIはすべて許可される。
不正解 この解釈は完全に逆です。SCPはアカウントで実行可能な最大権限を定義します。Logistics OUのSCPをEC2 APIアクションのみを許可するものに変更した場合、EC2 APIアクションは明示的に許可され、その他のAPIアクションは暗黙的に拒否されます。SCPは「許可リスト」であり、明示的に許可されていないものはすべて拒否されるため、EC2以外のAPIアクションがすべて許可されるという結論は誤りです。
全体的な説明
問われている要件
この問題では、AWS Organizations内のService Control Policy(SCP)の変更が、組織内のアカウントに設定されているIAMロールの権限にどのような影響を与えるかを理解する必要があります。具体的には、Logistics OUからFullAWSAccess SCPを削除し、Amazon EC2 APIアクションのみを許可するSCPに置き換えた場合に、SupplyChain OUのアカウントに設定されているシステム管理者IAMロール(AdministratorAccess管理ポリシーを持つ)の権限がどうなるかを問われています。
前提知識
AWS Organizations とサービスコントロールポリシー(SCP)
AWS Organizationsは、複数のAWSアカウントを一元管理するためのサービスで、サービスコントロールポリシー(SCP)を使用して組織内のアカウントの権限を一括制御できます。
- 組織構造:
- 組織ルート: 組織の最上位コンテナ
- 組織単位(OU): アカウントの論理的なグループ。階層構造を形成できる
- アカウント: 個々のAWSアカウント
- SCP(Service Control Policy)の特性:
- SCPは組織内のアカウントで利用可能な最大権限を制限するポリシー
- SCPは「許可リスト」であり、明示的に許可されていないアクションは拒否される
- SCPは階層構造で適用され、上位レベルでの制限は下位レベルに継承される
- アカウントで実行できるアクションは、そのアカウントに適用されるすべてのSCPの論理的な積(AND)
- デフォルトではFullAWSAccessポリシーが適用され、すべてのアクションを許可
- SCPはIAMポリシーをオーバーライドするのではなく、制限する
- フルAWSアクセスSCP:
json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}
]
}- EC2 APIのみを許可するSCP(例):
json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "ec2:*",
"Resource": "*"
}
]
}IAMポリシーとSCPの関係
IAMポリシーとSCPは連携して動作し、最終的な権限を決定します:
- 権限の評価モデル:
- 明示的な拒否が優先される
- アクションが許可されるためには、適用されるすべてのポリシータイプで許可されなければならない
- SCPとIAMポリシーの論理的な積(AND)が最終的な有効権限
- AdministratorAccess IAM管理ポリシー:
json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}
]
}- SCPとIAMポリシーの相互作用:
- SCPは「ガードレール」として機能し、IAMで付与できる最大権限を制限
- IAMポリシーで許可されているアクションでも、SCPで許可されていなければ拒否される
- 最終的な権限 = SCPで許可されている権限 ∩ IAMポリシーで許可されている権限
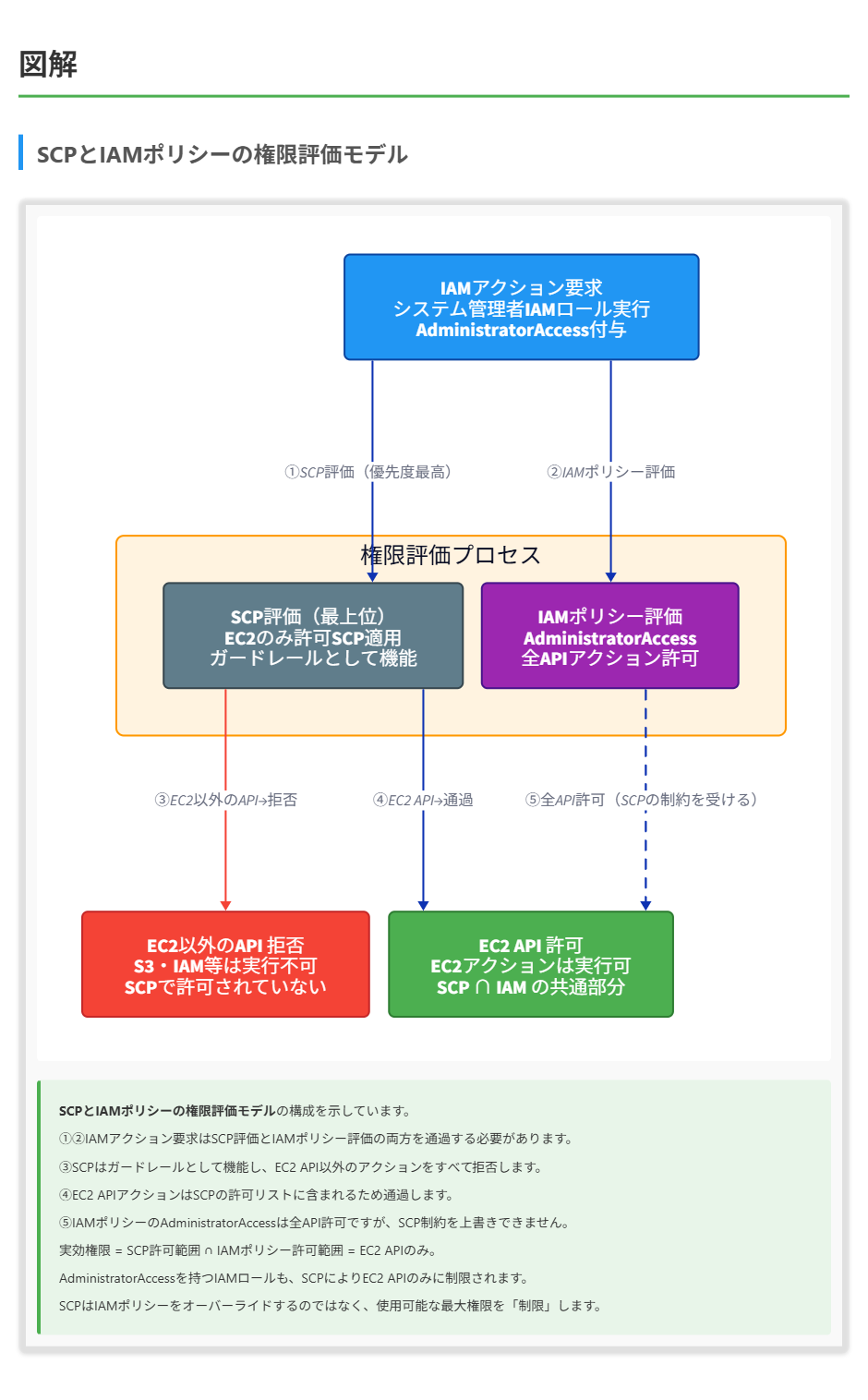
解くための考え方
この問題を解決するには、SCPとIAMポリシーがどのように相互作用するかを理解し、以下のポイントを考慮する必要があります:
- 組織構造の理解:
- 組織ルートLogistics OU (FullAWSAccess SCPが適用されている)SupplyChain OU (FullAWSAccess SCPが適用されている)複数のAWSアカウント (各アカウントにFullAWSAccess SCPが適用され、システム管理者IAMロールにAdministratorAccessポリシーが設定されている)
- SCPの変更の影響:
- Logistics OUからFullAWSAccess SCPを削除し、EC2 APIアクションのみを許可するSCPに置き換える
- この変更はLogistics OUのすべての子OU(SupplyChain OU)とアカウントに影響する
- 有効な権限の計算:
- 初期状態:SCPから: すべてのアクション許可 (FullAWSAccess)
- IAMから: すべてのアクション許可 (AdministratorAccess)
- 有効権限: すべてのアクション許可
- 変更後:
- SCPから: EC2 APIアクションのみ許可
- IAMから: すべてのアクション許可 (AdministratorAccess)
- 有効権限: EC2 APIアクションのみ許可
従って、Logistics OUのSCPを変更した後、システム管理者IAMロールはEC2 APIアクションのみを実行でき、他のすべてのAPIアクションは拒否されることになります。これは、SCPが「許可リスト」として機能し、IAMポリシーで許可されている権限のうち、SCPでも許可されている権限のみが有効になるためです。
SCPの階層的な適用を考慮すると、Logistics OUに適用されるSCPの制限は、その下のSupplyChain OUとそのアカウントすべてに継承されます。したがって、Logistics OUのSCPがEC2 APIアクションのみを許可する場合、SupplyChain OUのアカウントのシステム管理者IAMロールは、AdministratorAccessポリシーが付与されていても、EC2 APIアクションのみを実行できます。
参考資料
問題文:
医療データ分析企業において、クラウドアーキテクトがAWS Organizationsを使用して、複数のAWSアカウントを研究部門OU、臨床部門OU、管理部門OUなど異なるOUに分けて管理しています。IAMポリシーやAmazon S3ポリシーなどを含むすべてのリソースはAWS CloudFormationを通じてデプロイされています。テンプレートとコードはCodeCommitリポジトリに保存されています。
最近、研究部門のデータアナリストが、患者統計データを格納する特定のS3バケットにアクセスできないという問題を報告しました。このS3バケットには現在バケットポリシーが設定されています。
このアクセスの問題を解決するにはどうするべきでしょうか?
選択肢:
A. S3バケットポリシーを更新する。S3の「パブリックアクセスブロック」オプションを無効にする。S3バケットポリシーにaws:SourceAccount条件を追加し、該当するデータアナリストのAWSアカウントIDを含める。
B. データアナリストのアクセスを制限しているIAM権限境界がないか確認する。制限がある場合は調整する。影響を受けている研究部門アカウントにAWS Configレコーダーを実装し、アクセス問題を引き起こしている設定ミスを修正する。解決策をCodeCommitリポジトリにコミットし、CloudFormationを使用してデプロイする。
C. 研究部門OUでIAMリソースへの変更を防止するSCPを実装する。S3ポリシーにaws:SourceAccount条件を追加し、該当するデータアナリストのAWSアカウントIDを含める。解決策をCodeCommitリポジトリにコミットし、CloudFormationを使用してデプロイする。
D. S3バケットへのデータアナリストからのアクセスを拒否しているSCPが存在しないことを確認する。IAMポリシーの権限境界がアクセスを妨げていないことを確認する。必要に応じてSCPやIAMポリシーの権限境界を調整し、CodeCommitリポジトリに変更をコミットして、CloudFormationを使用してデプロイする。
正解:D
A. S3バケットポリシーを更新する。S3の「パブリックアクセスブロック」オプションを無効にする。S3バケットポリシーにaws:SourceAccount条件を追加し、該当するデータアナリストのAWSアカウントIDを含める。
不正解 このアプローチには複数の問題があります。まず、「パブリックアクセスブロック」を無効にすることはセキュリティ上のリスクを大きく高めます。パブリックアクセスブロックはS3バケットを意図しない公開アクセスから保護する機能であり、データアナリストのアクセス問題とは関係がありません。
B. データアナリストのアクセスを制限しているIAM権限境界がないか確認する。制限がある場合は調整する。影響を受けている研究部門アカウントにAWS Configレコーダーを実装し、アクセス問題を引き起こしている設定ミスを修正する。解決策をCodeCommitリポジトリにコミットし、CloudFormationを使用してデプロイする。
不正解 この方法はIAM権限境界の確認など一部適切な要素を含んでいますが、不完全です。IAM権限境界はユーザーやロールに設定できる最大権限を制限するため、データアナリストのアクセス問題の原因となる可能性は確かにあります。しかし、AWS Configレコーダーの実装は、設定ミスを検出するのに役立つ可能性がありますが、即時の問題解決策ではありません。AWS Configは主に設定変更を記録し、コンプライアンスをモニタリングするためのものであり、アクセス問題の根本原因を特定するためのツールではありません。また、OUレベルで適用されている可能性のあるSCPを確認する点が欠けています。CodeCommitとCloudFormationを使用した変更のデプロイは適切ですが、問題の根本原因に対処していない可能性があります。
C. 研究部門OUでIAMリソースへの変更を防止するSCPを実装する。S3ポリシーにaws:SourceAccount条件を追加し、該当するデータアナリストのAWSアカウントIDを含める。解決策をCodeCommitリポジトリにコミットし、CloudFormationを使用してデプロイする。
不正解 この方法はアクセス問題を解決するのではなく、むしろ複雑にする可能性があります。研究部門OUでIAMリソースへの変更を防止するSCPを実装することは、既存のアクセス問題とは無関係であり、むしろデータアナリストが自分のIAM権限を管理する能力をさらに制限することになります。また、S3ポリシーにaws:SourceAccount条件を追加することは有効かもしれませんが、それだけでは問題の根本原因に対処していない可能性があります。問題は既存のSCPやIAM権限境界など、より上位の制約にある可能性が高いですが、この解決策ではそれらの確認が行われていません。CodeCommitとCloudFormationを使用したデプロイのアプローチは正しいですが、適切な解決策をデプロイしていないため不正解です。
D. S3バケットへのデータアナリストからのアクセスを拒否しているSCPが存在しないことを確認する。IAMポリシーの権限境界がアクセスを妨げていないことを確認する。必要に応じてSCPやIAMポリシーの権限境界を調整し、CodeCommitリポジトリに変更をコミットして、CloudFormationを使用してデプロイする。
正解 この方法は、S3アクセス問題の最も可能性の高い根本原因に対処しています。AWS Organizationsの構造内では、SCPはOU内のすべてのアカウントに影響を与え、IAMポリシーよりも上位の制約として機能します。
全体的な説明
問われている要件
この問題では、AWS Organizations内で複数のAWSアカウントを管理しており、データアナリストが特定のS3バケットにアクセスできないという問題を解決する方法を問われています。主なポイントは以下の通りです:
- AWS Organizationsの構造内で、複数のAWSアカウントが異なるOUに分けて管理されている
- すべてのリソース(IAMポリシーやS3ポリシーを含む)はCloudFormationを通じてデプロイされている
- テンプレートとコードはCodeCommitリポジトリに保存されている
- 問題のS3バケットには既にバケットポリシーが設定されている
- 一部のデータアナリストがこのS3バケットにアクセスできない
この状況を踏まえて、アクセス問題を解決するための最も適切なアプローチを選択する必要があります。
前提知識
AWS Organizationsの構造とポリシー階層
AWS Organizationsは、複数のAWSアカウントを一元管理するためのサービスです。主要な概念と構造は以下の通りです:
- 組織構造:
- 組織のルート:組織の最上位コンテナ
- 組織単位(OU):アカウントの論理的なグループ。階層構造を形成できる
- アカウント:個々のAWSアカウント
- サービスコントロールポリシー(SCP):
- AWS Organizationsの機能で、組織内のアカウントで利用可能な最大権限を制限する
- OU単位で適用され、その下のすべてのアカウントに影響する
- IAMポリシーよりも優先される(SCPで拒否されるとIAMで許可されていても拒否される)
- 「許可リスト」または「拒否リスト」として機能する
- アクセス制御階層:
- SCPはアカウントの最大権限を制限する最上位の制約
- IAM権限境界はユーザーやロールに設定できる最大権限を制限
- IAMポリシー(アイデンティティベースまたはリソースベース)が実際のアクセス許可を決定
- リソースポリシー(S3バケットポリシーなど)も権限を制御
IAM権限境界
IAM権限境界は、IAMエンティティ(ユーザーまたはロール)に設定できる最大権限を定義するポリシーです:
- 機能:
- アイデンティティに付与できる最大権限を制限する
- 権限境界自体はアクセス権を付与しない
- アイデンティティベースのポリシーと権限境界の共通部分が実際の権限となる
- 評価ロジック:
- アイデンティティにアクションの実行を許可するには、アイデンティティポリシーと権限境界の両方でそのアクションが許可されている必要がある
- 権限境界で明示的に許可されていないアクションは、アイデンティティポリシーで許可されていても実行できない
S3バケットポリシーとアクセス制御
S3バケットポリシーは、特定のS3バケットに対するアクセスを制御するリソースベースのポリシーです:
- 機能:
- バケットレベルでのアクセス制御を定義
- プリンシパル(ユーザー、ロール、アカウント)ごとに異なるアクセス権限を設定可能
- クロスアカウントアクセスを許可する手段として使用可能
- パブリックアクセスブロック:
- バケットレベルまたはアカウントレベルで設定可能
- 意図しないパブリックアクセスを防ぐためのセキュリティ機能
- 開発者の正規アクセスには通常影響しない
- 条件キー:
- aws:SourceAccount:リクエストの送信元のアカウントを指定
- aws:PrincipalOrgID:プリンシパルが属する組織を指定
- aws:PrincipalTag:プリンシパルに付けられたタグに基づいてアクセスを制御
インフラストラクチャのコード化(IaC)
AWSリソースをコードとして管理するプラクティスは、一貫性と再現性を確保するために重要です:
- AWS CloudFormation:
- AWSリソースをテンプレート(YAMLまたはJSON)として定義
- スタックを通じてリソースを一括デプロイおよび管理
- 変更の追跡と一貫したデプロイを可能にする
- AWS CodeCommit:
- マネージドのGitリポジトリサービス
- インフラストラクチャコードのバージョン管理とコラボレーションを可能にする
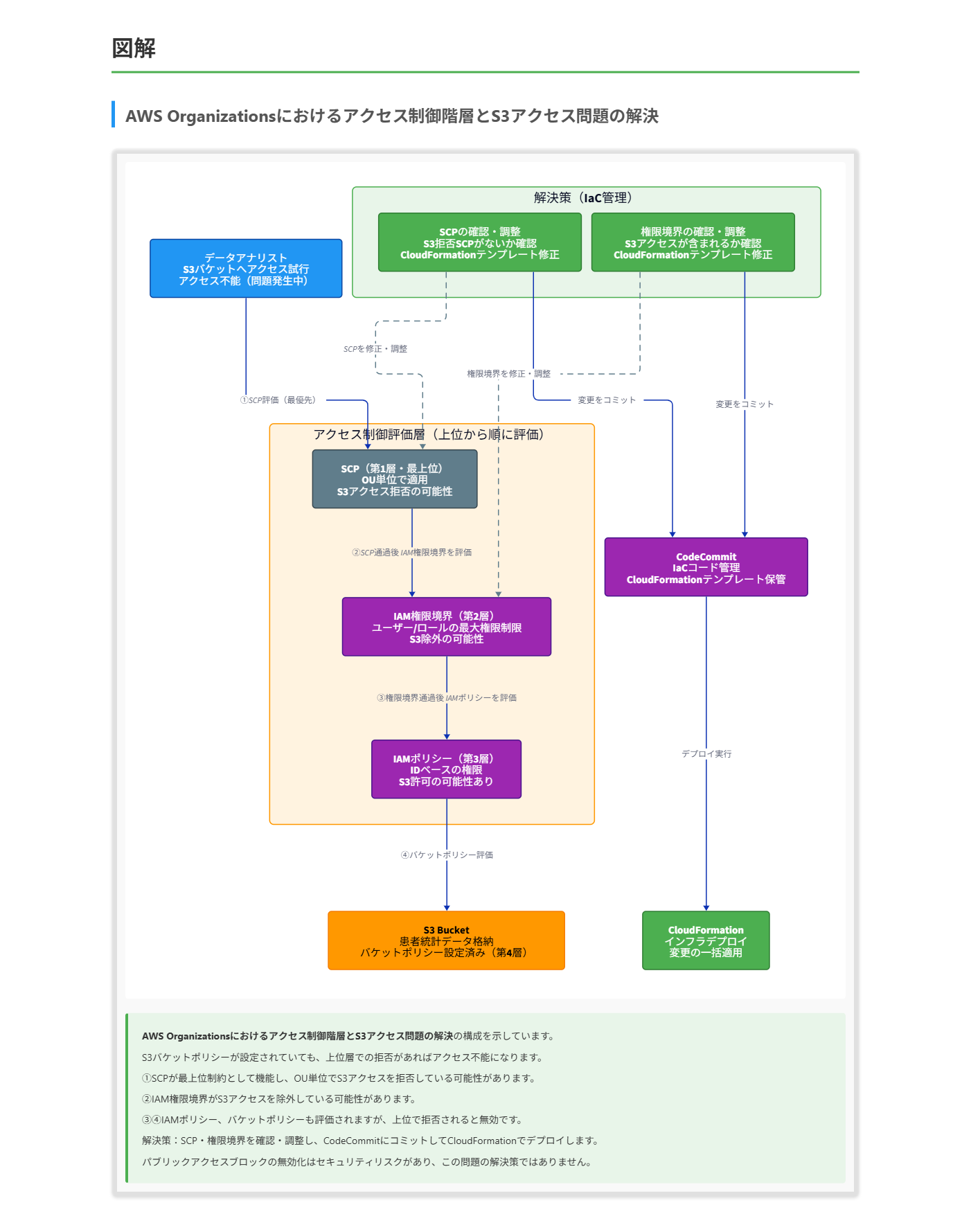
解くための考え方
この問題を解決するためには、以下の点を考慮する必要があります:
- アクセス制御階層の理解:
- AWS Organizationsのアクセス制御は階層的である
- 最上位から順に:SCP → IAM権限境界 → IAMポリシー → リソースポリシー
- 上位レベルで拒否されると、下位レベルでの許可は無効になる
- 問題の根本原因の特定:
- S3バケットポリシーは設定されていることが既に分かっている
- アクセス問題の原因は、より上位の制約(SCPやIAM権限境界)にある可能性が高い
- OUレベルでのSCPの設定が開発者のアクセスを妨げている可能性がある
- IAM権限境界が開発者の権限を制限している可能性もある
- 変更管理の一貫性:
- すべてのリソースはCloudFormationを通じてデプロイされている
- テンプレートとコードはCodeCommitリポジトリに保存されている
- 解決策も同じ管理方法に従う必要がある
これらの点を考慮すると、最も適切なアプローチは以下のステップを含むものになります:
- S3バケットへのアクセスを拒否しているSCPが存在しないか確認する
- IAMポリシーの権限境界がアクセスを妨げていないか確認する
- 必要に応じてSCPやIAM権限境界を調整する
- 変更をCodeCommitリポジトリにコミットし、CloudFormationを使用してデプロイする
参考資料
問題文:
製造会社は、スマートファクトリーから収集された品質検査データを複数の連続ステージで分析するカスタマイズされたパイプラインを運用しています。このパイプラインはAmazon EC2インスタンス上でAuto Scalingグループ内で動作しています。各ステージは画像解析や統計的品質評価を含む計算負荷が高い処理であり、5分以内に完了します。
現在、いずれかのステージが失敗するとパイプライン全体が最初のステージから再処理を開始します。このシステムを改善し、失敗したステージのみを再処理して全体の品質検査効率を向上させるには、どのソリューションが最適ですか?
選択肢:
A. 検査レコードをAmazon S3に書き込むウェブサービスを開発する。Amazon S3イベント通知を設定して、メッセージをAmazon SNSトピックに送信する。新しいレコードをスキャンして処理を開始するためのEC2インスタンスをデプロイし、中間結果を次のステージのためにAmazon S3に保存する。
B. 品質検査ロジックをコンテナ環境で動作するように変更し、AWS Fargateを使用してこれらのコンテナを管理する。ステージの進行に合わせてコンテナが自動的に呼び出されるように設定する。
C. Amazon Kinesisデータストリームを使用して品質検査レコードを送信するウェブサービスを実装する。AWS Lambda関数を使用して処理を分割する。
D. AWS Step Functionsを利用するウェブサービスを実装し、品質検査処理をStep FunctionsとAWS Lambda関数で管理されるタスクに分割する。
正解:D
A. 検査レコードをAmazon S3に書き込むウェブサービスを開発する。Amazon S3イベント通知を設定して、メッセージをAmazon SNSトピックに送信する。新しいレコードをスキャンして処理を開始するためのEC2インスタンスをデプロイし、中間結果を次のステージのためにAmazon S3に保存する。
不正解 この手順はステージ間のデータを保存するためにAmazon S3を使用し、S3イベント通知とSNSトピックを介して処理を進めるものです。しかし、この方法には複数の欠点があります。まず、各ステージの状態管理を明示的に実装する必要があり、失敗したステージのみを再処理する仕組みを自前で構築しなければなりません。
B. 品質検査ロジックをコンテナ環境で動作するように変更し、AWS Fargateを使用してこれらのコンテナを管理する。ステージの進行に合わせてコンテナが自動的に呼び出されるように設定する。
不正解 この手順は、品質検査パイプラインをコンテナ化してAWS Fargateで実行することを提案しています。コンテナ化によりデプロイの一貫性は向上しますが、この方法にもいくつかの課題があります。
C. Amazon Kinesisデータストリームを使用して品質検査レコードを送信するウェブサービスを実装する。AWS Lambda関数を使用して処理を分割する。
不正解 Amazon Kinesisデータストリームは連続的なデータ処理に適していますが、この方法にはいくつかの制限があります。Kinesisはストリーミングデータの処理に優れていますが、複数のステージを持つワークフローの管理や、失敗したステージのみを再処理するという要件には対応していません。
D. AWS Step Functionsを利用するウェブサービスを実装し、品質検査処理をStep FunctionsとAWS Lambda関数で管理されるタスクに分割する。
正解 AWS Step Functionsは、まさにこのような複数ステージのワークフロー管理に最適なサービスです。各検査ステージを個別のステート(状態)として定義でき、それぞれのステートはAWS Lambda関数によって実行できます。Step Functionsの主な利点は以下の通りです:
全体的な説明
問われている要件
この問題では、複数の連続ステージで品質検査データを処理するパイプラインの改善策を求められています。現状の課題と要件は以下の通りです:
- パイプラインはEC2インスタンス上のAuto Scalingグループで動作している
- 処理は複数の連続ステージで構成され、各ステージは計算負荷が高い
- 各ステージは5分以内に完了する
- 現在は、あるステージが失敗すると全体が最初から再処理される
- 改善目標:失敗したステージのみを再処理できるようにして効率を高める
この問題の本質は、複数ステージのワークフローを管理し、特定のステージが失敗した場合に、そのステージだけを再処理できる仕組みを構築することです。
前提知識
ワークフロー管理の考え方
複数のステージを持つデータ処理ワークフローを効率的に管理するには、以下の要素を考慮する必要があります:
- 状態管理: 各ステージの実行状態(未実行、実行中、成功、失敗)を追跡する仕組み
- エラーハンドリング: ステージの失敗を検出し、適切に対応する仕組み
- 再処理: 特定のステージだけを再実行できる仕組み
- データの受け渡し: ステージ間でデータを効率的に受け渡す仕組み
- スケーラビリティ: 処理量の増加に対応できる柔軟性
AWS Step Functions
AWS Step Functionsは、ワークフローを視覚的に構築し管理できるサービスです:
- ステートマシン: JSON形式で定義されるワークフロー
- ステート(状態): ワークフローの各ステップ。Task、Choice、Parallel、Mapなど様々なタイプがある
- タスク: 実際の処理を行うステート。Lambda関数、ECSタスク、他のAWSサービスなどを呼び出せる
- 入出力処理: JSONデータを入力として受け取り、処理結果をJSONデータとして次のステートに渡せる
- エラーハンドリング: Retry(再試行)やCatch(エラー捕捉)などの機能が組み込まれている
- 実行履歴: ワークフローの実行状況や結果をログとして保存
AWS Lambda
AWS Lambdaは、サーバーレスでコードを実行できるコンピューティングサービスです:
- イベント駆動: 様々なイベントをトリガーにして関数を実行できる
- スケーラビリティ: 需要に応じて自動的にスケールする
- 短時間実行: 現在は最大15分間の実行が可能
- ステートレス: 基本的にステートレスだが、外部サービスと連携して状態を管理できる
- リソース効率: 実行時間に応じた課金で、アイドル時間のコストがない
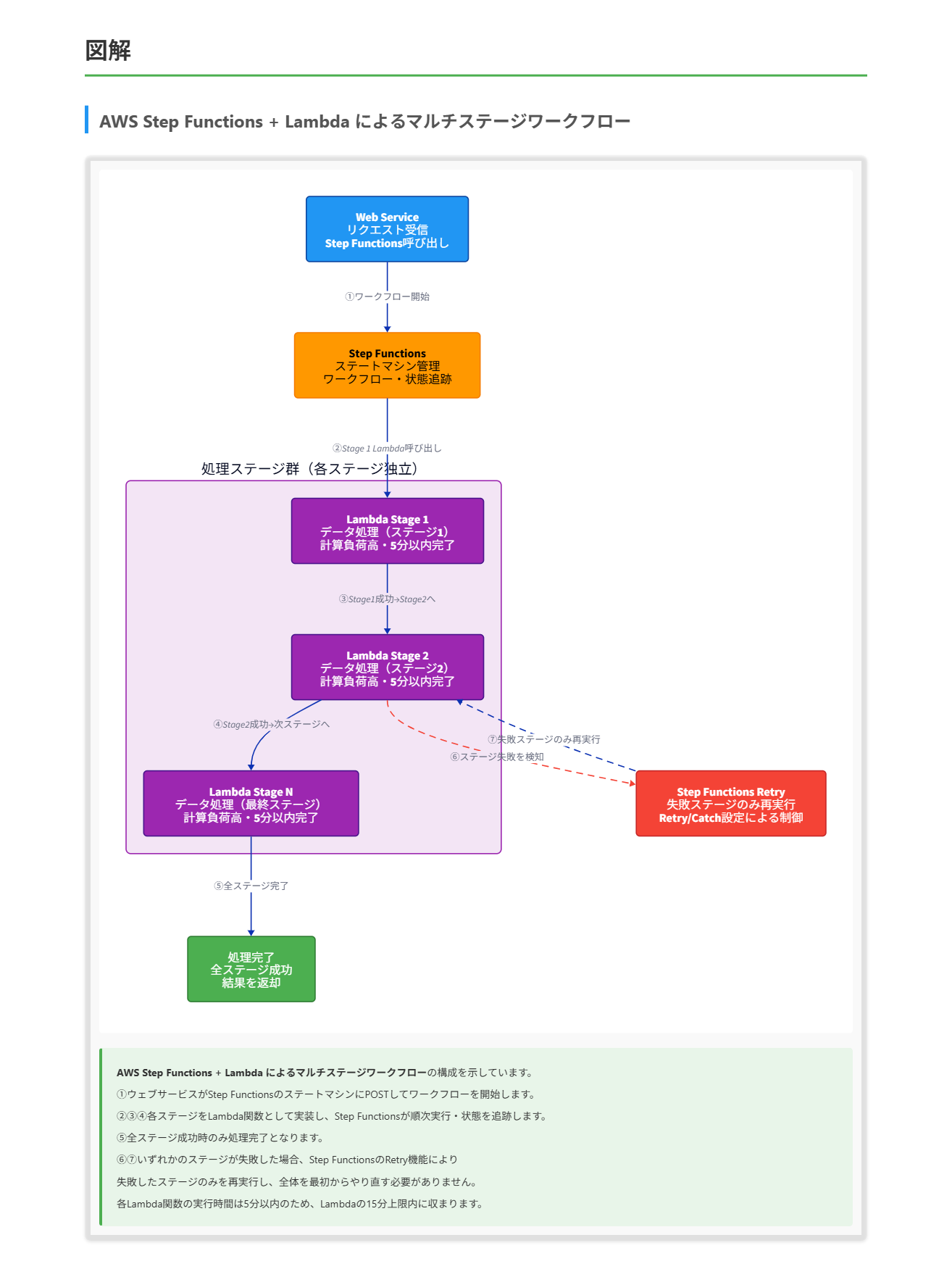
解くための考え方
この問題を解決するための最適な手順を考えるには、以下の観点で各選択肢を評価します:
- ワークフロー管理機能: ステージ間の依存関係や制御フローを適切に管理できるか
- 状態管理: 各ステージの実行状態を追跡できるか
- エラーハンドリング: ステージの失敗を検出し、適切に対応できるか
- 再処理能力: 失敗したステージのみを再実行できるか
- リソース効率: 必要なときだけリソースを使用する効率的な実行が可能か
- 開発・運用の複雑性: 実装や運用にかかる労力はどの程度か
これらの観点から各選択肢を分析すると:
- S3 + SNS + EC2の組み合わせ:ステージの状態管理やエラーハンドリング、再処理の仕組みを自前で実装する必要があり、複雑性が高い
- コンテナ化 + Fargate:ワークフロー管理の機能が不足しており、状態管理やエラーハンドリングも自前で実装する必要がある
- Kinesis + Lambda:ストリーム処理には適しているが、特定ステージの再処理という要件に直接対応していない
- Step Functions + Lambda:ワークフロー管理、状態追跡、エラーハンドリング、再処理の機能が組み込まれており、サーバーレスで効率的
AWS Step FunctionsとLambdaの組み合わせは、以下のような実装が可能です:
- 各処理ステージを個別のLambda関数として実装
- Step Functionsのステートマシンで、各ステージの順序や依存関係を定義
- ステージ間のデータはStep Functionsの入出力メカニズムを使用して受け渡し
- エラーハンドリングにStep FunctionsのRetry機能を使用し、失敗したステージのみを再試行
- 必要に応じてFall back(代替処理)やエラー通知を実装
この手順により、失敗したステージのみを再処理するという要件を効率的に満たすことができます。
参考資料
問題文:
ある医療情報SaaS企業は、複数の病院・クリニック向けに電子カルテ管理システムをコンテナベースで提供しています。外部セキュリティ監査の指摘を受け、本番環境で稼働するコンテナイメージのセキュリティ対策を強化することになりました。
CI/CDワークフローにおいて、オペレーティングシステムおよびプログラミング言語のパッケージに対する脆弱性スキャンを組み込むことが求められています。このワークフローではAWS CodePipelineが使用され、AWS CodeBuild、AWS CodeDeployのステップを含み、Amazon ECRリポジトリを使用しています。
DevOpsエンジニアは、CRITICALおよびHIGHの脆弱性が存在しないイメージのみがデプロイされるように、CI/CDワークフローにイメージスキャンプロセスを統合する必要があります。
この要件を満たすために必要なアクションは何ですか?(2つ選択してください)
選択肢:
A. Amazon ECRの基本スキャンを有効化する。
B. Amazon ECRの拡張スキャンを有効化する。
C. CI/CDワークフロー内でCRITICALまたはHIGHの脆弱性を持つイメージに対してRejectedステータスを設定するようにAmazon ECRを構成する。
D. イメージスキャンの完了時にAWS Lambda関数をトリガーするAmazon EventBridgeルールを設定する。このLambda関数はAmazon Inspectorのスキャン結果を評価し、CI/CDワークフローにApprovedまたはRejectedステータスを送信する。
E. スキャン後にAWS Lambda関数をトリガーするAmazon EventBridgeルールを設定する。このLambda関数はClairスキャンの結果を評価し、CI/CDワークフローにApprovedまたはRejectedステータスを送信する。
正解:B、D
A. Amazon ECRの基本スキャンを有効化する。
不正解 Amazon ECRの基本スキャンにはAWS新しいバージョンが提供されており、これはAmazonのネイティブスキャンテクノロジーを使用しています。この新しい基本スキャンは、一般的なオペレーティングシステム全体での脆弱性検出を改善していますが、主にオペレーティングシステムパッケージの脆弱性スキャンに焦点を当てています。
B. Amazon ECRの拡張スキャンを有効化する。
正解 Amazon ECRの拡張スキャンは、Amazon Inspectorを使用して実行されます。この機能は、オペレーティングシステムのパッケージだけでなく、さまざまなプログラミング言語のパッケージ(Java、Python、JavaScript、Goなど)における脆弱性もスキャンできます。拡張スキャンを使用することで、コンテナイメージに含まれる幅広い脆弱性を検出可能となり、CRITICALおよびHIGHの脆弱性を特定できるようになります。拡張スキャンは、Common Vulnerability Scoring System(CVSS)スコアに基づいて脆弱性の重大度を評価し、詳細な結果を提供します。これにより、オペレーティングシステムとプログラミング言語のパッケージ両方を対象とした包括的な脆弱性検出という要件を満たすことができます。
C. CI/CDワークフロー内でCRITICALまたはHIGHの脆弱性を持つイメージに対してRejectedステータスを設定するようにAmazon ECRを構成する。
不正解 Amazon ECR自体にはイメージに対して「Rejected」というステータスを明示的に設定する機能は存在しません。ECRはイメージの脆弱性をスキャンし、その結果を報告することはできますが、スキャン結果に基づいてイメージにステータスを割り当てる機能はネイティブには提供していません。
D. イメージスキャンの完了時にAWS Lambda関数をトリガーするAmazon EventBridgeルールを設定する。このLambda関数はAmazon Inspectorのスキャン結果を評価し、CI/CDワークフローにApprovedまたはRejectedステータスを送信する。
正解 この選択肢は、スキャン結果の自動評価と、それに基づいたCI/CDワークフローの制御を実現するための適切な方法を示しています。Amazon ECR(特に拡張スキャン)でイメージがスキャンされると、スキャン完了イベントがAmazon EventBridgeに送信されます。EventBridgeルールを設定することで、このイベントをトリガーにLambda関数を実行できます。Lambda関数はAmazon Inspectorのスキャン結果を取得し、CRITICALまたはHIGHの脆弱性が存在するかどうかを評価します。その評価結果に基づいて、CI/CDワークフロー(AWS CodePipeline)に「Approved」または「Rejected」のステータスを送信することができます。CodePipelineにはApproval(承認)ステージを設定できるため、Lambda関数からの評価結果に基づいて、パイプラインの進行を制御することが可能です。これにより、CRITICALまたはHIGHの脆弱性が存在するイメージのデプロイを防止できます。
E. スキャン後にAWS Lambda関数をトリガーするAmazon EventBridgeルールを設定する。このLambda関数はClairスキャンの結果を評価し、CI/CDワークフローにApprovedまたはRejectedステータスを送信する。
不正解 Clairは以前のAmazon ECRの旧基本スキャンで使用されていたオープンソースの脆弱性スキャンツールであり、現在の新しい基本スキャンではAmazonのネイティブスキャンテクノロジーに置き換えられています。旧基本スキャンはプログラミング言語のパッケージに対する脆弱性検出が限定的であり、問題の要件を完全に満たしません。
全体的な説明
問われている要件
この問題では、CI/CDワークフローにコンテナイメージのセキュリティスキャンを統合し、CRITICALおよびHIGHの脆弱性が存在するイメージがプロダクション環境にデプロイされないようにする方法を問われています。具体的な要件は以下の通りです:
- オペレーティングシステムおよびプログラミング言語のパッケージに対する脆弱性スキャンを行う
- AWS CodePipeline、CodeBuild、CodeDeployを使用したCI/CDワークフローに統合する
- Amazon ECRリポジトリを使用している
- CRITICALおよびHIGHの脆弱性が存在しないイメージのみをデプロイ可能にする
これらの要件を満たすためには、適切なイメージスキャンソリューションの選択と、スキャン結果に基づいてCI/CDワークフローを制御する仕組みが必要です。
前提知識
Amazon ECRのイメージスキャン
Amazon ECRは、主に2種類のイメージスキャンオプションを提供しています:
- 基本スキャン:
- 以前の基本スキャン(旧スキャン)はClairに基づいていましたが、新しいバージョンではAmazonのネイティブスキャンテクノロジーを使用
- 一般的なオペレーティングシステム全体での脆弱性検出を改善
- 主にオペレーティングシステムのパッケージレベルでの脆弱性をスキャン
- プログラミング言語のパッケージに対する包括的な検出は限定的
- 追加費用なしで利用可能
- 拡張スキャン:
- Amazon Inspectorを使用して実行
- オペレーティングシステムパッケージだけでなく、プログラミング言語のパッケージ(Java、Python、JavaScript、Goなど)も包括的にスキャン
- AWS Security Hubと統合可能
- CVE(共通脆弱性識別子)情報と詳細な修復ガイダンスを提供
- CVSSスコアに基づいた重大度評価(CRITICAL、HIGH、MEDIUM、LOW)
- Amazon Inspector利用料金が適用
スキャンは、手動で開始するか、プッシュ時に自動的に実行するように設定できます。スキャン結果はAmazon ECRコンソールで確認でき、APIを通じて取得することも可能です。
AWS EventBridgeとLambda
AWS EventBridgeは、イベント駆動型アーキテクチャを実現するためのサービスです:
- イベントバス:アプリケーションやAWSサービスからのイベントを受信
- ルール:特定のイベントパターンに一致した場合にアクションを実行
- ターゲット:ルールに一致した場合に呼び出されるリソース(Lambda関数など)
AWS Lambda関数は、Amazon ECRのスキャン結果を評価し、必要なアクションを実行するために使用できます:
- イベント駆動:EventBridgeからのイベントをトリガーに実行
- スキャン結果の取得:ECR APIを使用してスキャン結果を取得
- 結果の評価:CRITICALやHIGHの脆弱性が存在するかを評価
- アクションの実行:評価結果に基づいてCodePipelineに承認/拒否を送信
AWS CodePipelineの承認アクション
AWS CodePipelineには、パイプラインの進行を制御するための承認アクションが組み込まれています:
- 手動承認:ユーザーがコンソールやCLIを通じて承認/拒否を行う
- 自動承認:Lambda関数などから承認/拒否のステータスを送信
- 承認ステータス:Approved(承認)またはRejected(拒否)
Lambda関数からCodePipelineの承認アクションにステータスを送信するには、AWS SDKのput-approval-result APIを使用します。
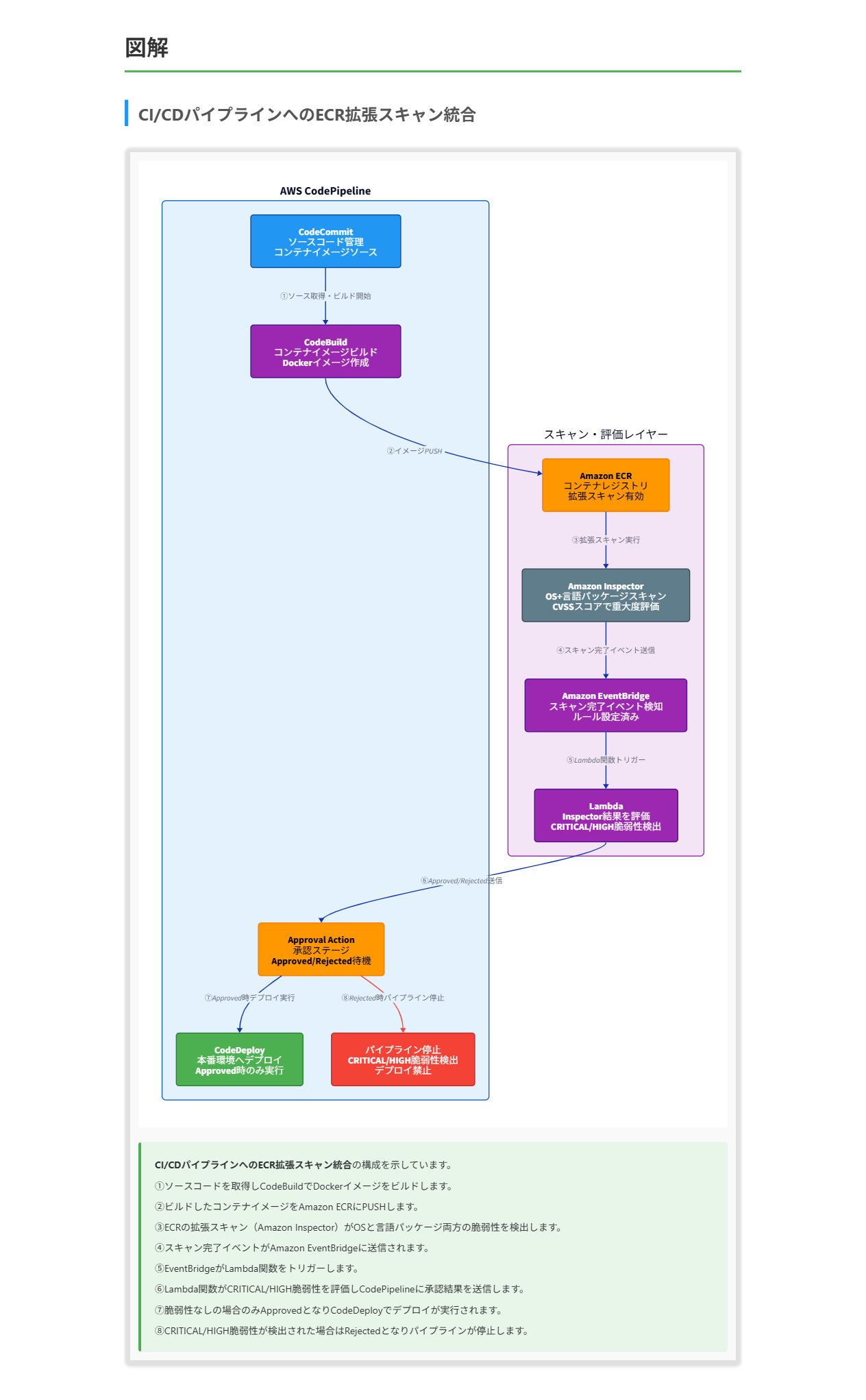
解くための考え方
この問題を解決するための最適なアプローチを選択するには、以下の点を考慮する必要があります:
- 脆弱性スキャンの範囲:
- オペレーティングシステムパッケージだけでなく、プログラミング言語のパッケージもスキャンする必要がある
- 新しい基本スキャンはオペレーティングシステムの脆弱性検出が改善されたが、プログラミング言語パッケージの包括的なスキャンは限定的
- 拡張スキャンは両方をカバーしており、より包括的なセキュリティ分析を提供する
- 自動化と統合:
- スキャン結果を自動的に評価し、CI/CDワークフローに統合する仕組みが必要
- EventBridgeとLambdaを組み合わせることで、スキャン完了をトリガーに自動評価が可能
- CodePipelineの承認アクションと連携して、パイプラインの進行を制御できる
- コストと機能のバランス:
- 基本スキャンは追加費用なしで利用可能だが、機能は限定的
- 拡張スキャンはAmazon Inspector利用料金が発生するが、より包括的な検出能力を提供
これらの考慮点から、最適な解決策は以下の組み合わせになります:
- Amazon ECRの拡張スキャンを実装する:
- オペレーティングシステムとプログラミング言語のパッケージ両方の脆弱性をスキャン
- CVSSスコアに基づいた重大度評価で、CRITICALやHIGHの脆弱性を特定
- イメージスキャンの完了時にAWS Lambda関数をトリガーするAmazon EventBridgeルールを設定する。このLambda関数はAmazon Inspectorの結果を評価し、CI/CDワークフローにApprovedまたはRejectedステータスを送信する:
- スキャン完了を自動的に検知し、結果を評価
- 評価結果に基づいてCodePipelineの進行を制御
- CRITICALまたはHIGHの脆弱性が存在する場合、パイプラインを停止
これにより、問題の要件を満たすセキュアなCI/CDワークフローが実現できます。
参考資料
問題文:
あるオンライン小売企業は、ECプラットフォームの新機能のリリース期間を短縮することを目指しており、AWS CodeBuildとAWS CodeDeployを使用してアプリケーションの構築とリリースを行っています。各マイクロサービスは、個別のAWS CodePipelineを使用してリリースされます。
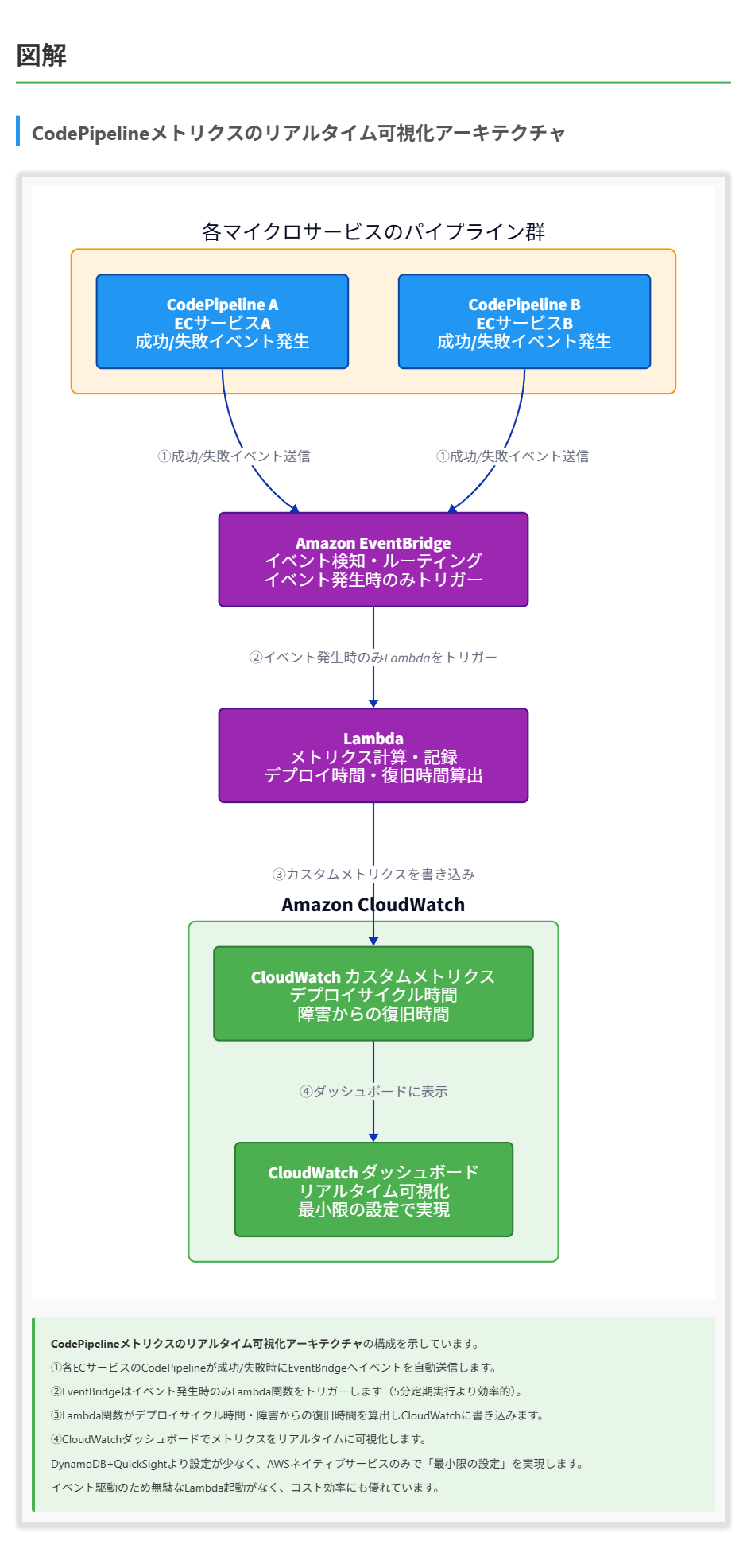
企業は、平均的なデプロイサイクル時間と障害からの復旧時間に関するリアルタイム可視化ダッシュボードを求めています。
最小限の設定でこの可視化を提供するソリューションはどれですか?
選択肢:
A. 成功および失敗したパイプライン実行の統計を収集するAmazon CloudWatchカスタムメトリクスを作成するAWS Lambda関数を設計する。Amazon EventBridgeルールを設定して、5分間隔でLambda関数をトリガーする。これらのメトリクスを使用してCloudWatchダッシュボードを構築する。
B. 成功および失敗したパイプライン実行の詳細を記録するAmazon CloudWatchカスタムメトリクスを作成するAWS Lambda関数を設計する。Amazon EventBridgeルールを設定して、各パイプラインの成功または失敗イベントの発生時にLambda関数をトリガーする。これらのメトリクスを使用してCloudWatchダッシュボードを構築する。
C. 成功および失敗した実行の詳細をAmazon DynamoDBに保存するAWS Lambda関数を開発する。Amazon EventBridgeルールを設定して、各パイプラインの成功または失敗イベントの発生時にLambda関数をトリガーする。Amazon QuickSightを使用してDynamoDBのデータからダッシュボードを作成する。
D. 成功および失敗した実行の詳細をAmazon DynamoDBに保存するAWS Lambda関数を開発する。Amazon EventBridgeルールを設定して、5分間隔でLambda関数をトリガーする。DynamoDBのデータを使用してAmazon QuickSightでダッシュボードを作成する。
正解:B
A. 成功および失敗したパイプライン実行の統計を収集するAmazon CloudWatchカスタムメトリクスを作成するAWS Lambda関数を設計する。Amazon EventBridgeルールを設定して、5分間隔でLambda関数をトリガーする。これらのメトリクスを使用してCloudWatchダッシュボードを構築する。
不正解 この手順では、Lambda関数を定期的(5分ごと)に実行して、パイプラインの実行状況を監視します。しかし、この方法にはいくつかの問題があります。まず、パイプライン実行が発生していない時間帯でもLambda関数が実行され続けるため、不要なリソース消費とコストが発生します。また、5分間隔で実行する場合、実際のパイプライン実行とメトリクス収集の間に最大5分のずれが生じる可能性があり、リアルタイム性が損なわれます。パイプラインの実行時間が短い場合、5分以内に完了した実行を正確に測定できない可能性もあります。
B. 成功および失敗したパイプライン実行の詳細を記録するAmazon CloudWatchカスタムメトリクスを作成するAWS Lambda関数を設計する。Amazon EventBridgeルールを設定して、各パイプラインの成功または失敗イベントの発生時にLambda関数をトリガーする。これらのメトリクスを使用してCloudWatchダッシュボードを構築する。
正解 この手順は、最小限の設定でパイプラインのパフォーマンス指標を可視化するのに最適です。パイプラインの実行が成功または失敗した時点でイベントが発生し、それをトリガーにLambda関数が実行されます。これにより、パイプラインの実行に関連するイベント発生時のみLambda関数が起動するため、リソース効率が高くなります。
C. 成功および失敗した実行の詳細をAmazon DynamoDBに保存するAWS Lambda関数を開発する。Amazon EventBridgeルールを設定して、各パイプラインの成功または失敗イベントの発生時にLambda関数をトリガーする。Amazon QuickSightを使用してDynamoDBのデータからダッシュボードを作成する。
不正解 この方法は、パイプラインの実行成功や失敗時にイベントベースでLambda関数をトリガーする点は効率的ですが、全体としては複雑さが増しています。DynamoDBを使用してデータを保存し、QuickSightを使用してダッシュボードを作成する手順は、より高度なデータ分析や可視化が必要な場合には適していますが、「最小限の設定」という要件には合致しません。DynamoDBテーブルの設計、プロビジョニング、QuickSightのセットアップと接続設定など、追加の作業が必要になります。また、QuickSightはサブスクリプションベースのサービスであり、追加のコストが発生します。基本的なパイプラインの実行時間や復旧時間の可視化であれば、CloudWatchのネイティブな機能だけで十分対応できるため、この複雑な手順は必要以上のオーバーヘッドを生じさせます。
D. 成功および失敗した実行の詳細をAmazon DynamoDBに保存するAWS Lambda関数を開発する。Amazon EventBridgeルールを設定して、5分間隔でLambda関数をトリガーする。DynamoDBのデータを使用してAmazon QuickSightでダッシュボードを作成する。
不正解 5分ごとにLambda関数を実行する方法は、パイプライン実行がない時間でも不要な処理が発生し、リアルタイム性も低下します。また、DynamoDBとQuickSightを使用する複雑なアーキテクチャは、「最小限の設定」という要件に反します。さらに、この組み合わせでは、5分ごとに実行されるLambda関数がDynamoDBからデータを取得し分析する必要があり、データ処理の負荷が増大する可能性があります。
全体的な説明
問われている要件
この問題では、AWS CodePipeline、CodeBuild、CodeDeployを使用している企業が、以下の指標を可視化するダッシュボードを求めています:
- 平均的なデプロイサイクル時間(コードがビルドされてからデプロイが完了するまでの時間)
- 障害からの復旧時間(デプロイ失敗から正常なデプロイまでの時間)
重要なのは、この可視化ソリューションが「最小限の設定」で実現できることです。つまり、シンプルかつ効率的で、管理オーバーヘッドが少ないソリューションが求められています。
前提知識
AWS DevOpsサービス
AWS CodePipeline、CodeBuild、CodeDeployは、アプリケーションのビルド、テスト、デプロイを自動化するためのAWSのCI/CDサービスです:
- AWS CodePipeline:
- ソフトウェアリリースのワークフローを自動化するサービス
- 各パイプラインは、ソース、ビルド、デプロイなどの複数のステージで構成される
- パイプラインの実行状態は「成功」「失敗」などのイベントとして通知される
- AWS CodeBuild:
- フルマネージドのビルドサービス
- ソースコードのコンパイル、テストの実行、パッケージの生成などを行う
- AWS CodeDeploy:
- アプリケーションのデプロイを自動化するサービス
- EC2インスタンス、Lambda関数、ECSサービスなどにデプロイ可能
AWS モニタリングサービス
AWS提供するモニタリングとダッシュボード作成のためのサービスには以下があります:
- Amazon CloudWatch:
- AWSリソースとアプリケーションのモニタリングサービス
- メトリクスの収集、ログの保存、アラームの設定、ダッシュボードの作成が可能
- カスタムメトリクスの作成に対応し、独自の測定データを記録できる
- ネイティブなダッシュボード機能を持ち、グラフやウィジェットを配置可能
- Amazon EventBridge:
- サーバーレスのイベントバスサービス
- AWSサービスからのイベントを検出し、指定したターゲット(Lambda関数など)にルーティング
- スケジュールベース(時間間隔)またはイベントベース(特定のイベント発生時)のルール設定が可能
- Amazon DynamoDB:
- フルマネージドのNoSQLデータベースサービス
- スケーラブルな高性能データストレージを提供
- 時系列データなど、様々な形式のデータを保存可能
- Amazon QuickSight:
- ビジネスインテリジェンスとデータ可視化サービス
- 様々なデータソースからデータを取得し、インタラクティブなダッシュボードを作成可能
- 高度な分析機能を提供するが、追加のセットアップとコストが必要
解くための考え方
この問題を解決するための最適な手順を選択するには、以下の観点で評価する必要があります:
- 設定の最小化:
- 最小限のサービスと設定で要件を満たせるか
- 管理オーバーヘッドは少ないか
- データ収集の効率性:
- 必要なデータを効率的に収集できるか
- 無駄な処理やリソース消費はないか
- 可視化の適切性:
- 求められる指標(デプロイサイクル時間、復旧時間)を適切に可視化できるか
- リアルタイム性は確保されているか
- コスト効率:
- 不要なサービスやリソース消費を避けられているか
- スケーリングしても効率的か
これらの観点から各選択肢を分析すると:
- 5分ごとのLambda実行 + CloudWatchダッシュボード:パイプライン実行がない時間も無駄にLambda関数が実行される
- リアルタイム性に欠ける
- 設定は比較的シンプルだが、リソース効率が悪い
イベントベースのLambda実行 + CloudWatchダッシュボード:
- 必要な時だけLambda関数が実行され、リソース効率が良い
- リアルタイムにデータが収集される
- AWS標準サービスのみで実現でき、設定が最小限
イベントベースのLambda実行 + DynamoDB + QuickSight:
- 必要な時だけLambda関数が実行される点は良い
- しかし、DynamoDBとQuickSightは追加の設定とコストが必要
- 高度な分析には適しているが、基本的な指標の表示には過剰
5分ごとのLambda実行 + DynamoDB + QuickSight:
- 無駄なLambda実行とリアルタイム性の欠如
- 追加の設定とコストが必要
- 最も効率が悪く、複雑な手順
以上の分析から、「イベントベースのLambda実行 + CloudWatchダッシュボード」が最も要件に合致していることがわかります。この手順では、CodePipelineの成功/失敗イベントをトリガーにLambda関数が実行され、その中でパイプラインの実行時間や復旧時間をCloudWatchカスタムメトリクスとして記録します。これらのメトリクスはCloudWatchダッシュボードで視覚化され、最小限の設定で要件を満たすことができます。
参考資料
スポンサーリンク
以下スポンサーリンクです。
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。