AWS AIP無料問題集です。正解と解説を確認する際は右側のボタンを押下してください。
問題集の完全版は以下Udemyにて発売しているためお買い求めください。問題集への質問はUdemyのQA機能もしくはUdemyのメッセージにて承ります。Udemyの問題1から10問抜粋しております。
多くの方にご好評いただき、講師評価 4.5/5.0 を獲得できております。ありがとうございます。

特別価格: 通常2,600円 → 1,500円
講師クーポン適用で42%OFF
講師クーポンAWS認定Generative AI Developer – Professional (AIP-C01)模擬試験問題集

この資格を活かしたキャリア情報
AIP資格の取得後にどんなキャリアが開けるか、詳しくはこちら:
→ AIP合格者の転職市場価値と求人傾向
AWS資格全体のキャリア活用法:
→ AWS資格は転職・キャリアアップでどう活きる?資格別市場価値と実体験
問題文:
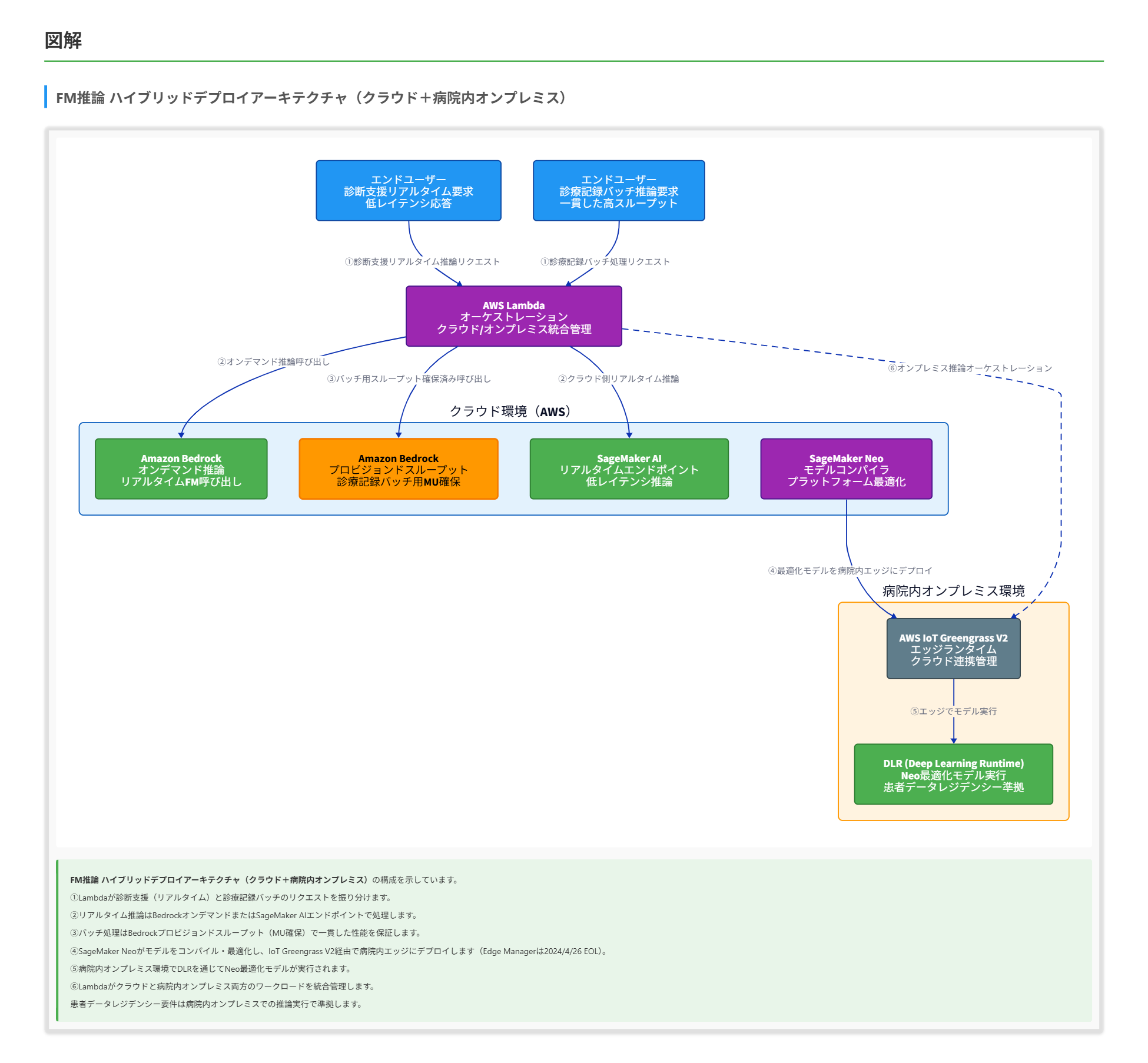
ある医療機器メーカーは、複数のAIワークロードをサポートするために基盤モデル(FM)を使用するソリューションを設計しています。一部のFMは診断支援のためにオンデマンドでリアルタイムに呼び出す必要があります。他のFMは過去の診療記録のバッチ処理のために一貫した高スループットアクセスを必要とします。 このソリューションは、ハイブリッドデプロイパターンをサポートし、患者データのレジデンシーとコンプライアンス要件に準拠するために、クラウドインフラストラクチャと病院内オンプレミスインフラストラクチャの両方でワークロードを実行する必要があります。 これらの要件を満たすステップの組み合わせはどれですか。(2つ選択)
選択肢:
A. AWS Lambdaを使用して、Amazon SageMaker AI非同期エンドポイントでホストされたFMを呼び出すことで、低レイテンシのFM推論をオーケストレーションします。
B. Amazon Bedrockでプロビジョンドスループットを設定して、大量ワークロードに対する一貫したパフォーマンスを確保します。
C. Amazon SageMaker Neoを使用してエッジデプロイをサポートするAmazon SageMaker AIエンドポイントにFMをデプロイします。AWS Lambdaを使用してFMをオーケストレーションし、ハイブリッドデプロイをサポートします。
D. オートスケーリング機能を備えたAmazon Bedrockを使用して、予測困難なトラフィック急増に対応します。
E. Amazon SageMaker JumpStartを使用して、FMをホストおよび呼び出します。
正解:B、C
A. AWS Lambdaを使用して、Amazon SageMaker AI非同期エンドポイントでホストされたFMを呼び出すことで、低レイテンシのFM推論をオーケストレーションします。
不正解 SageMaker AI非同期エンドポイントは、大規模な入力データや処理時間が長いワークロード向けに設計されています。推論結果はAmazon S3に非同期で返されるため、リアルタイムの低レイテンシ推論には適していません。低レイテンシが求められる場合はSageMaker AIリアルタイムエンドポイントを使用する必要があります。
B. Amazon Bedrockでプロビジョンドスループットを設定して、大量ワークロードに対する一貫したパフォーマンスを確保します。
正解 Amazon Bedrockのプロビジョンドスループットは、モデルユニット(MU)を購入することで特定のモデルに対して一定のスループットを確保する機能です。各MUは1分あたりに処理可能な入力トークン数と生成可能な出力トークン数という形でスループットレベルを提供し、バッチ処理のように安定した高スループットが必要なワークロードに対して一貫したパフォーマンスを提供します。なお、MUあたりの具体的なTPM(tokens-per-minute)値はモデルごとに異なり、詳細な値や上限引き上げの申請はAWSアカウントマネージャーへ問い合わせる必要があります。
C. Amazon SageMaker Neoを使用してエッジデプロイをサポートするAmazon SageMaker AIエンドポイントにFMをデプロイします。AWS Lambdaを使用してFMをオーケストレーションし、ハイブリッドデプロイをサポートします。
正解 SageMaker Neoはモデルを一度トレーニングすればクラウドとエッジの両方で実行できる機能を提供します。Neoコンパイラがモデルをターゲットハードウェア向けに最適化したバイナリを生成し、AWS IoT Greengrass V2を介して病院内オンプレミスのエッジデバイスにデプロイできます。Lambdaでオーケストレーションすることで、クラウドとオンプレミスの両環境でのワークロード管理を統合的に実現します。なお、SageMaker Edge Managerは2024年4月26日にEOL(サポート終了)となっており、現行でのエッジ向けモデルデプロイはNeoでコンパイルしたモデルまたはONNX形式のモデルを、AWS IoT Greengrass V2経由でエッジデバイスへ配布・実行する構成が推奨されます。
D. オートスケーリング機能を備えたAmazon Bedrockを使用して、予測困難なトラフィック急増に対応します。
不正解 Amazon Bedrockのオンデマンド推論はAWSが内部的にスケーリングを管理するフルマネージドサービスですが、ユーザーが設定する「オートスケーリング」機能は提供していません。また、この選択肢はクラウドのみの対応であり、病院内オンプレミスインフラストラクチャでのワークロード実行というハイブリッドデプロイ要件を満たしません。
E. Amazon SageMaker JumpStartを使用して、FMをホストおよび呼び出します。
不正解 SageMaker JumpStartは事前トレーニング済みモデルの検索・デプロイを簡易化するサービスですが、エッジデプロイやハイブリッドデプロイをネイティブにサポートする機能を持っていません。モデルのデプロイを容易にする点では有用ですが、病院内オンプレミスインフラストラクチャでのワークロード実行という患者データレジデンシー要件には対応できません。
全体的な説明
問われている要件
- 一部のFMを診断支援のためオンデマンドかつリアルタイムで呼び出す能力
- 過去診療記録のバッチ処理用の一貫した高スループットアクセスの確保
- クラウドと病院内オンプレミスにまたがるハイブリッドデプロイパターンのサポート
- 患者データのレジデンシーとコンプライアンス要件への準拠
前提知識 Amazon Bedrockのプロビジョンドスループットについて
- プロビジョンドスループットは、特定のモデルに対してモデルユニット(MU)を購入することで一定のスループットを確保する機能です。
- 各MUは1分あたりに処理可能な入力トークン数と生成可能な出力トークン数というかたちでスループットレベルを提供します。MUあたりのTPM値はモデルごとに異なり、具体的な値・MU単価・上限引き上げについてはAWSアカウントマネージャーへ問い合わせる必要があります。
- コミットメント期間は「No commitment(なし)」「1か月」「6か月」から選択でき、長期コミットメントほど時間単価が割引されます。ただし一部のモデル(例: Titan Image Generator G1 V1/V2のベースモデル)は「No commitment」での購入に対応しておらず、No commitmentで購入可能なモデルは公式ドキュメントの対応モデル表で確認する必要があります。AWS GovCloud (US-West)ではカスタムモデル+No commitmentのみがサポートされます。
- カスタムモデル(ファインチューニング済みモデル)を本番で使用する場合は、プロビジョンドスループットの購入が必須です。
Amazon SageMaker Neoによるモデル最適化とエッジデプロイについて
- SageMaker Neoは「一度トレーニングすればどこでも実行できる」をコンセプトとした機能です。
- Neoコンパイラは各フレームワーク固有の演算を「framework-agnostic(フレームワーク非依存)な中間表現」に変換した上で最適化を行い、ターゲットハードウェア向けに最適化されたバイナリを生成します(内部的にはApache TVMやTreelite等のオープンソースコンパイラが利用されています)。対応フレームワークにはPyTorch、TensorFlow、MXNet、ONNXなどがあります。
- エッジデプロイはDLR(Deep Learning Runtime)またはAWS IoT Greengrass V2を介して実行でき、ARM、Intel、NVIDIAなど多様なプロセッサアーキテクチャに対応します。
- クラウドインスタンス(Inferentiaを含む)とエッジデバイスの両方へのデプロイをサポートします。
- 旧サービスの SageMaker Edge Manager は 2024年4月26日にEOL となっており、現行の推奨エッジ運用は「SageMaker Neo または ONNX でコンパイル/変換したモデル」を AWS IoT Greengrass V2 で配布・実行する構成です。
SageMaker AIエンドポイントの種類について
- リアルタイムエンドポイントは、数ミリ秒〜数秒の低レイテンシで推論結果を返します。オンデマンドのリアルタイム推論に適しています。
- 非同期エンドポイントは、大規模入力や処理時間が長いワークロード向けで、結果をS3に返します。リアルタイム推論には不適切です。
- バッチ変換はエンドポイントとは異なるジョブベースの大量データ一括処理方式です。
ハイブリッドデプロイとデータレジデンシーについて
- データレジデンシー要件では、特定の地域のデータがその地域内で処理される必要があります。オンプレミスデプロイはこの要件を満たす有効な手段です。
- AWS IoT Greengrassを使用すると、クラウドで管理しながらエッジデバイスでMLモデルを実行できます。
解くための考え方
この問題では、FMの推論ワークロードにおける2つの異なるアクセスパターン(リアルタイムとバッチ)に加え、ハイブリッドデプロイという3つの要件を同時に満たす構成を問われています。 まず、バッチ処理の一貫した高スループットという要件に着目します。Amazon Bedrockのプロビジョンドスループットはモデルユニットを事前に確保することで予測可能な一定のスループットを保証でき、大量のバッチ処理を安定して実行する要件に最適です。 次に、ハイブリッドデプロイとデータレジデンシー要件に着目します。Amazon Bedrockはフルマネージドのクラウドサービスであり、オンプレミスデプロイには対応していません。SageMaker Neoはモデルをコンパイル・最適化し、AWS IoT Greengrass V2を介してエッジデバイスやオンプレミス環境にデプロイできます(SageMaker Edge Managerは2024年4月26日にEOL済のため、現行ではNeo/ONNX + Greengrass V2 の経路を用います)。SageMaker AIのリアルタイムエンドポイントでクラウド側の推論を処理し、Neoでコンパイルされたモデルをオンプレミスに配置することで、ハイブリッドパターンを実現します。 非同期エンドポイントはレスポンスがS3経由で返されるため低レイテンシのリアルタイム推論には不適切です。Bedrockの「オートスケーリング」はユーザー設定可能な機能として提供されておらず、ハイブリッド要件も満たしません。SageMaker JumpStartはモデルの発見とデプロイの簡易化に特化しており、エッジデプロイ機能を持ちません。各サービスの推論エンドポイントタイプの特性と、ハイブリッドアーキテクチャの設計パターンを正確に理解することが求められます。 参考資料
問題文:
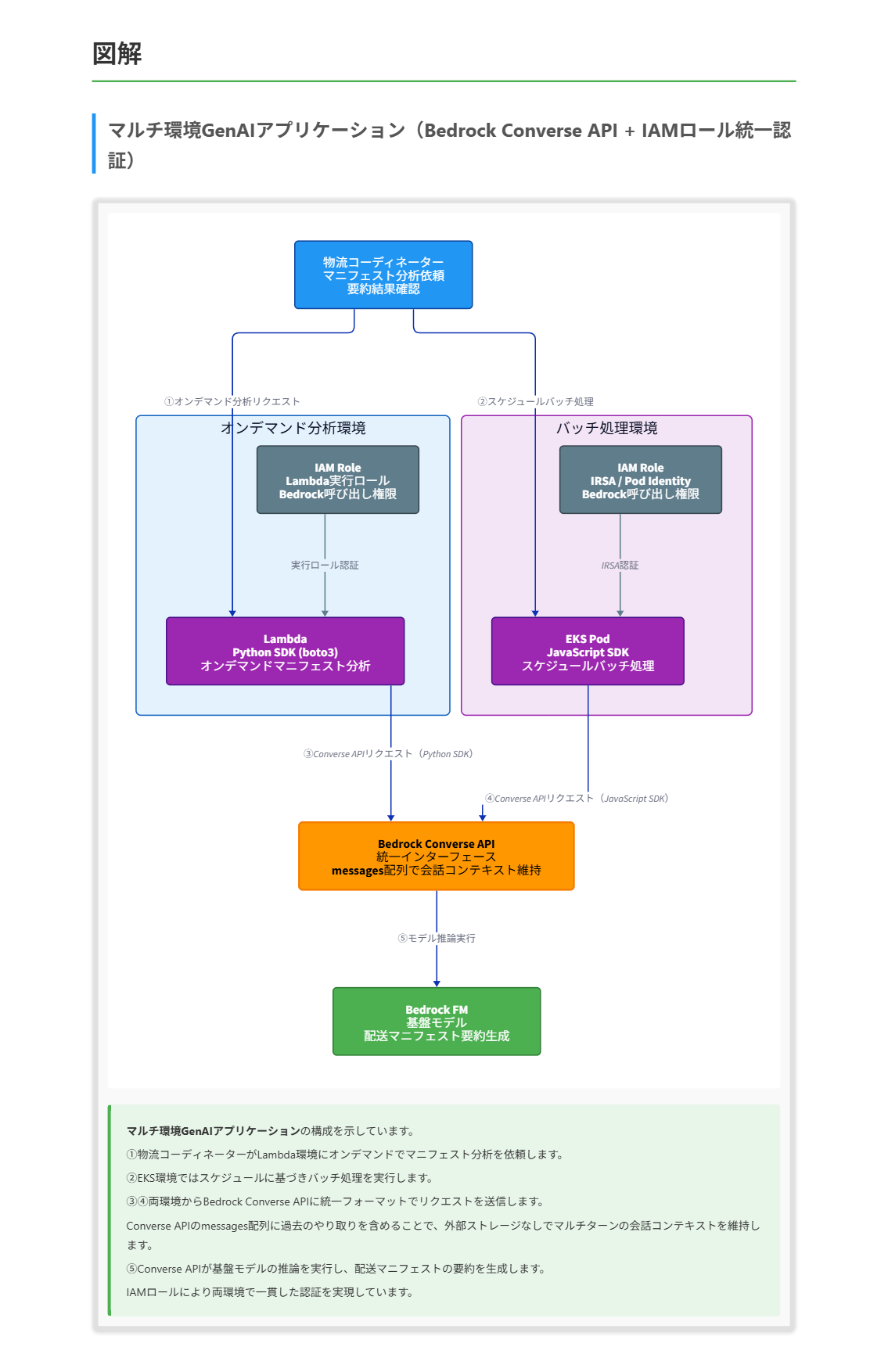
ある物流企業が、配送マニフェストを処理して物流コーディネーターにサマリーを提供するジェネレーティブAI(GenAI)アプリケーションを構築しています。このアプリケーションは2つのコンピューティング環境で実行する必要があります。1つ目の環境では、AWS Lambda関数がPython SDKを使用してオンデマンドでマニフェストを分析します。2つ目の環境では、Amazon EKSコンテナがJavaScript SDKを使用して、スケジュールに基づき複数のマニフェストをバッチ処理します。アプリケーションは、マルチターンのやり取りを通じて会話コンテキストを維持し、環境間で同じ基盤モデル(FM)を使用し、一貫した認証を確保する必要があります。 これらの要件を満たすソリューションはどれですか。
選択肢:
A. Amazon Bedrock InvokeModel APIを各環境で個別の認証方法とともに使用します。会話の状態をAmazon DynamoDBに保存します。各プログラミング言語ごとにカスタムI/Oフォーマットロジックを使用します。
B. Amazon Bedrock Converse APIを両環境で共通の認証メカニズム(IAMロール)とともに直接使用します。会話の状態をAmazon ElastiCacheに保存します。プログラミング言語固有のラッパーをモデルパラメータ用に作成します。
C. 集約型のAmazon API Gateway REST APIエンドポイントを作成し、InvokeModel APIを使用してすべてのモデル操作を処理します。やり取りの履歴を各Lambda関数またはEKSコンテナのアプリケーションプロセスメモリに保存します。環境変数でモデルパラメータを設定します。
D. Amazon Bedrock Converse APIとIAMロールを認証に使用します。リクエストのmessages配列に過去のメッセージを含めて会話コンテキストを維持します。プログラミング言語固有のSDKを使用して一貫したAPIインターフェースを確立します。
正解:D
A. Amazon Bedrock InvokeModel APIを各環境で個別の認証方法とともに使用します。会話の状態をAmazon DynamoDBに保存します。各プログラミング言語ごとにカスタムI/Oフォーマットロジックを使用します。
不正解 InvokeModel APIはモデル固有のリクエスト/レスポンス形式を必要とするため、Python SDKとJavaScript SDKの間で一貫したインターフェースを提供できません。各環境で個別の認証方法を使用する設計は「一貫した認証」という要件に反します。さらに、カスタムI/Oフォーマットロジックを各言語で個別に実装すると、開発・保守の負担が増大し、言語間の動作不整合が発生するリスクがあります。
B. Amazon Bedrock Converse APIを両環境で共通の認証メカニズム(IAMロール)とともに直接使用します。会話の状態をAmazon ElastiCacheに保存します。プログラミング言語固有のラッパーをモデルパラメータ用に作成します。
不正解 Converse APIとIAMロールの組み合わせは適切ですが、ElastiCacheに会話状態を外部保存する設計は不必要な複雑さを追加します。Converse APIはリクエストのmessages配列に過去のメッセージを含めることで会話コンテキストを維持できるため、外部ストレージは必須ではありません。また、言語固有のラッパー作成はConverse APIの統一インターフェースの利点を損なう冗長な設計です。
C. 集約型のAmazon API Gateway REST APIエンドポイントを作成し、InvokeModel APIを使用してすべてのモデル操作を処理します。やり取りの履歴を各Lambda関数またはEKSコンテナのアプリケーションプロセスメモリに保存します。環境変数でモデルパラメータを設定します。
不正解 やり取りの履歴をプロセスメモリに保存する設計は、Lambda関数がステートレスで呼び出しごとにメモリがリセットされるため、マルチターンの会話コンテキストを維持できません。EKSコンテナでもポッドの再起動やスケールイン時にメモリ上のデータは失われます。さらに、集約型API Gatewayエンドポイントは単一障害点となり、InvokeModel APIの言語固有フォーマットの課題も残ります。
D. Amazon Bedrock Converse APIとIAMロールを認証に使用します。リクエストのmessages配列に過去のメッセージを含めて会話コンテキストを維持します。プログラミング言語固有のSDKを使用して一貫したAPIインターフェースを確立します。
正解 Converse APIはモデルに依存しない統一インターフェースを提供し、Python SDKとJavaScript SDKの両方で同じAPI構造を使用できます。messages配列に過去のやり取りを含めるだけでマルチターンの会話コンテキストを維持でき、外部ストレージが不要です。IAMロールによりLambdaとEKSの両環境で一貫した認証を実現し、各言語のAWS SDKがConverse APIの統一フォーマットを自動処理するため、カスタムロジックも不要です。
全体的な説明
問われている要件
- 2つの異なるコンピューティング環境(Lambda/Python、EKS/JavaScript)で動作すること
- マルチターンのやり取りで会話コンテキストを維持すること
- 環境間で同じ基盤モデルを使用すること
- 一貫した認証メカニズムを確保すること
前提知識 Amazon Bedrock Converse APIについて
- Converse APIは、Amazon Bedrockのモデルとメッセージベースの会話を行うための統一APIです。どのモデルに話しかけても同じ書式でリクエストを送れます。
- Converse APIのmessagesフィールドはMessageオブジェクトの配列で、各メッセージにはrole(userまたはassistant)とcontent(テキストや画像など)を含みます。後続のリクエストに過去のメッセージをすべて含めることで、会話コンテキストを維持します。
- InvokeModel APIとは異なり、Converse APIはモデル固有のリクエスト/レスポンス形式を抽象化するため、コードを一度書けば複数のモデルや言語SDKで再利用できます。
AWS SDKのマルチ言語対応について
- AWS SDKはPython(boto3)、JavaScript(@aws-sdk/client-bedrock-runtime)など複数の言語で提供され、Converse APIの統一インターフェースにより、どの言語でも同じパラメータ構造でリクエストを送信できます。
- 各SDK間でConverse APIの入出力フォーマットは共通化されており、言語ごとのカスタムフォーマットロジックは不要です。
IAMロールによるクロス環境認証について
- IAMロールはLambda関数の実行ロールとしてもEKSポッドのサービスアカウント(IRSA)としても使用でき、環境をまたいで統一された認証・認可を提供します。
- Lambda関数には実行ロールが自動で割り当てられ、EKSではIAM Roles for Service Accounts(IRSA)またはEKS Pod Identityにより、ポッド単位でIAMロールを紐づけます。
解くための考え方
この問題では、異なるプログラミング言語・コンピューティング環境で動作するGenAIアプリケーションにおいて、会話コンテキストの維持と一貫性をどう実現するかが問われています。 まず「一貫した認証」という要件から、環境ごとに異なる認証方式を使うInvokeModel APIと個別認証・DynamoDBを組み合わせる選択肢は除外できます。次に「マルチターンの会話コンテキスト維持」について検討します。集約型API Gateway経由でInvokeModelを呼び出しプロセスメモリに状態を保存する選択肢はLambda関数がステートレスであり呼び出し間でメモリを共有しないため、この設計は要件を満たしません。 Converse APIとIAMロールを使用する2つの選択肢はどちらもConverse APIとIAMロールを採用しますが、会話コンテキストの管理方法が異なります。ElastiCacheに状態を外部保存する選択肢は外部ストレージを利用しますが、Converse APIの公式ドキュメントでは「後続のConverseリクエストに会話のすべてのメッセージを含め」ることで会話コンテキストを維持すると明記されています。つまり、messages配列に過去のやり取りを含めるだけで十分であり、外部ストレージは必須ではありません。messages配列に過去のメッセージを含める選択肢はこの標準的なパターンに従い、会話コンテキストを維持します。 さらに、Converse APIを使用しながらも言語固有ラッパーを作成する選択肢はConverse APIが統一インターフェースを提供する目的と矛盾します。SDK固有の実装を活用しつつ統一されたAPIインターフェースを確立するConverse API + IAMロール + messages配列を使用する選択肢は、最もシンプルかつ要件に合致したソリューションです。 参考資料
- Converse API オペレーションを使用して会話を実行する – Amazon Bedrock
- Converse API を使用する場合 – Amazon Bedrock
- Converse API の例 – Amazon Bedrock
- サポートされているモデルとモデルの機能 – Amazon Bedrock
- InvokeModel – Amazon Bedrock API リファレンス
- Amazon Bedrock のセキュリティ – Amazon Bedrock
- Amazon EKS の IAM Roles for Service Accounts
- AWS Lambda 実行ロール – AWS Lambda
- AWS SDK コード例 – Amazon Bedrock
問題文:
あるオンライン教育企業は、Amazon Bedrock を利用して受講生からの質問に対するパーソナライズされたフィードバック応答を生成する学習支援アプリケーションを運用しています。 この企業は、プロンプトの有効性とモデル設定の更新ごとにそれらの品質を評価する品質保証プロセスを確立する必要があります。 このプロセスは、複数のプロンプトテンプレートから生成された応答を自動的に比較し、応答品質の問題を検知し、定量的な指標を提供し、さらに人間のレビュアー(教育コンテンツ担当者)が応答に対してフィードバックを与えられる仕組みを備えていなければなりません。 また、あらかじめ定義された品質しきい値に達しない設定は、本番環境にデプロイされないようにする必要があります。 これらの要件を満たすソリューションはどれですか。
選択肢:
A. AWS Lambda 関数を作成して、サンプルの受講生からの質問を複数の Amazon Bedrock モデル設定に送信し、応答を Amazon S3 に保存します。Amazon QuickSight で応答パターンを可視化し、出力を毎日手動でレビューします。品質しきい値を満たした設定のデプロイには AWS CodePipeline を使用します。
B. AWS Lambda 関数を使用して自動テストフレームワークを構築し、本番トラフィックをサンプリングして更新後のモデルバージョンに重複リクエストを送信します。Amazon Comprehend のセンチメント分析で結果を比較し、センチメントスコアが低下した場合はデプロイをブロックします。
C. Amazon Bedrock の評価ジョブを使用して、カスタムプロンプトデータセットによりモデル出力を比較します。プロンプトテンプレートが変更された際に評価ジョブを実行するように AWS CodePipeline を構成します。CodePipeline は、あらかじめ定義された品質しきい値を超える設定のみをデプロイするように構成します。
D. Amazon CloudWatch アラームを設定して Amazon Bedrock の応答レイテンシとエラー率を監視します。Amazon EventBridge ルールでしきい値超過時にチームへ通知し、AWS Systems Manager で手動承認ワークフローを構成します。
正解:C
A. AWS Lambda 関数を作成して、サンプルの受講生からの質問を複数の Amazon Bedrock モデル設定に送信し、応答を Amazon S3 に保存します。Amazon QuickSight で応答パターンを可視化し、出力を毎日手動でレビューします。品質しきい値を満たした設定のデプロイには AWS CodePipeline を使用します。
不正解 カスタム実装を Lambda・S3・QuickSight で組み合わせる構成は、応答そのものの品質を定量的に採点する機能を持ちません。QuickSight は集計値の可視化に特化したダッシュボードサービスであり、生成テキストの正確性や有害性を直接スコアリングしません。手動レビューは規模が拡大すると遅延と評価ばらつきを生み、しきい値判定の根拠データが不在となるため、要件を満たしません。
B. AWS Lambda 関数を使用して自動テストフレームワークを構築し、本番トラフィックをサンプリングして更新後のモデルバージョンに重複リクエストを送信します。Amazon Comprehend のセンチメント分析で結果を比較し、センチメントスコアが低下した場合はデプロイをブロックします。
不正解 Amazon Comprehend のセンチメント分析は文章の肯定・否定・中立といった感情極性のみを判定する機能で、生成応答の正確性・関連性・ハルシネーション・有害性といった品質観点をカバーしません。本番トラフィックのサンプリングは入力分布が制御不能なため、プロンプトテンプレート間の公平な比較が成立せず、人間レビュアーのフィードバック取り込みの仕組みも欠落しています。
C. Amazon Bedrock の評価ジョブを使用して、カスタムプロンプトデータセットによりモデル出力を比較します。プロンプトテンプレートが変更された際に評価ジョブを実行するように AWS CodePipeline を構成します。CodePipeline は、あらかじめ定義された品質しきい値を超える設定のみをデプロイするように構成します。
正解 Amazon Bedrock の評価ジョブは、自動評価で正確性・堅牢性・有害性などの定量メトリクスを算出し、LLM-as-a-judge では正答性や完全性を採点し、人間評価では Likert 尺度や Thumbs up/down で人間のフィードバックを構造化します。同一のカスタムプロンプトデータセットで複数構成を比較できるため公平な評価が成立し、CodePipeline と連携することでしきい値未達の設定を機械的にブロックできます。
D. Amazon CloudWatch アラームを設定して Amazon Bedrock の応答レイテンシとエラー率を監視します。Amazon EventBridge ルールでしきい値超過時にチームへ通知し、AWS Systems Manager で手動承認ワークフローを構成します。
不正解 CloudWatch のレイテンシ・エラー率監視は運用健全性を示す指標であり、生成応答の意味的な正確性や品質を測定する仕組みではありません。EventBridge による通知や Systems Manager の手動承認は、運用上のインシデント対応には有効ですが、複数プロンプトテンプレートの定量比較・人間レビュアーの構造化フィードバック・自動デプロイゲートを統合する機能を提供しません。
全体的な説明
問われている要件
- 複数のプロンプトテンプレート出力を自動的に比較する仕組みが必要です。
- 応答品質の問題を検出し定量メトリクスで提示できる必要があります。
- 人間のレビュアーが応答に対して構造化フィードバックを与えられる必要があります。
- 品質しきい値未達の設定が本番にデプロイされないゲート機構が必要です。
- 更新ごとに繰り返し実行できる継続的な評価プロセスである必要があります。
前提知識 Amazon Bedrock 評価ジョブについて
- Amazon Bedrock の評価ジョブは、自動評価・LLM-as-a-judge・人間評価の3形態を提供する仕組みです。FM の選定や継続的な品質保証のために設計されています。
- 自動評価では、正確性(Accuracy)、堅牢性(Robustness)、有害性(Toxicity)などのメトリクスをプログラムで計算し、定量スコアを返します。タスクタイプとして質問応答・要約・分類・テキスト生成などが選択できます。
- LLM-as-a-judge では別の LLM を判定者として用い、Correctness や Completeness、Faithfulness(ハルシネーション検出)などの観点でスコアを付与します。判定者がスコアの説明文も生成するため、根拠を伴うレビューが可能です。
- 人間評価では、Likert 5 段階尺度・Thumbs up/down・Preference rank・Choice 比較などの評価方式を選べます。レビュアーは社内ワーカーまたは AWS マネージドチームから構成できます。
- カスタムプロンプトデータセットは Amazon S3 に JSON Lines 形式(.jsonl)で配置し、1ジョブあたり最大 1,000 プロンプトを扱えます。同じデータセットを複数構成に当てて比較できるため、入力ばらつきを排除した公平な比較が成立します。
プロンプトテンプレート評価とモデル更新の品質保証について
- プロンプトテンプレートの差し替えはモデル本体の差し替えと同様に品質影響を持ちます。同一データセットでの A/B 比較が品質回帰を捉える基本手段となります。
- 「ハルシネーション」とは、モデルが事実と異なる内容をもっともらしく生成する現象です。レイテンシやセンチメントでは検出できません。
- 定量メトリクスとして Accuracy・Robustness・Toxicity・Faithfulness・Correctness・Completeness が用いられ、しきい値ベースの自動判定に適合します。
CI/CD パイプラインによるデプロイゲートについて
- AWS CodePipeline は、ソース・ビルド・テスト・デプロイの各ステージを連結する継続的デリバリーサービスです。Lambda アクションや承認アクションを介して任意の AWS API を呼び出せます。
- プロンプトテンプレートまたはモデル設定の変更をトリガーに評価ジョブを起動し、ジョブ結果のスコアを取得して条件分岐させることで、しきい値未達の設定を後段のデプロイステージに進めない構成が組めます。
- 評価ジョブは非同期実行のため、GetEvaluationJob API でステータスをポーリングしてジョブ完了を確認する必要があります。ポーリングの実装方法は主に2つあります。①CodeBuild のビルドステップでポーリングループを実装する方法:スクリプトが Completed または Failed を検出するまでループし、完了後にスコアと閾値を比較して終了コードで CodePipeline の進行を制御します。CodeBuild のビルドタイムアウトは最大 36 時間まで設定可能なため、評価ジョブの所要時間を十分カバーできます。②CodePipeline の Lambda アクションで continuation token を使う方法:Lambda は 15 分の実行制限があるため、ジョブ未完了時にトークンを保存して一度終了し、CodePipeline から再度呼び出された際に続きの確認を行う非同期継続パターンを使います。
他サービスの守備範囲について
- Amazon CloudWatch は応答レイテンシ・エラー率・スループットなどの運用メトリクスを扱います。応答内容の品質判定は守備範囲外です。
- Amazon Comprehend のセンチメント分析は感情極性(POSITIVE/NEGATIVE/NEUTRAL/MIXED)を返す NLP 機能で、生成応答の正確性や関連性とは異なる軸の指標です。
- Amazon QuickSight は BI ダッシュボードであり、テキスト生成品質を採点する機能は持ちません。
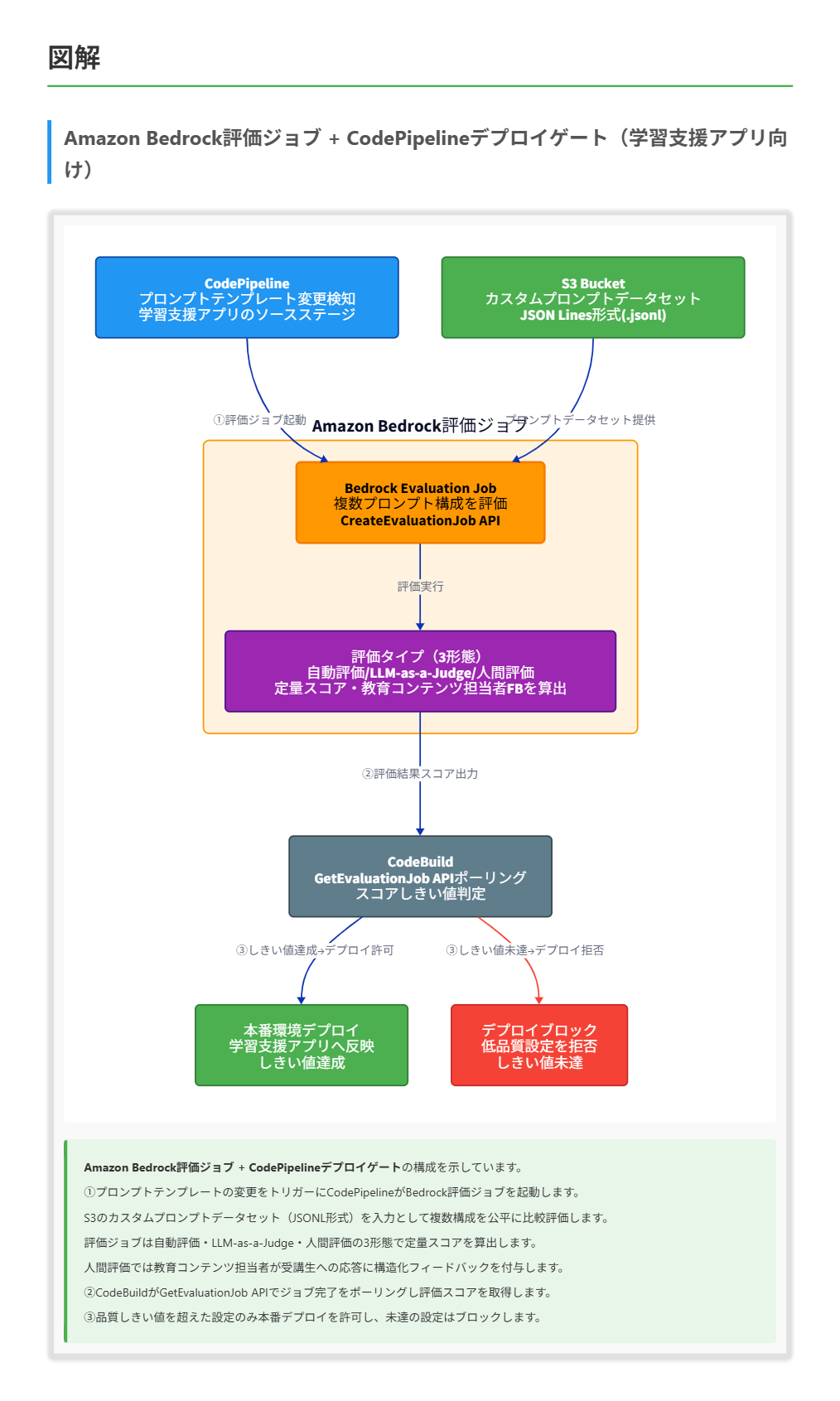
解くための考え方
この問題では、Amazon Bedrock を用いた学習支援アプリの「品質保証プロセス」をどう設計するかが問われています。要件を分解すると、複数プロンプトの自動比較、定量メトリクス、人間レビュアーのフィードバック、しきい値ベースのデプロイゲート、という4つの観点を1つの仕組みに統合する必要があります。 まず重要なのは、要件のうち「応答品質の検出」と「定量メトリクス」を満たすには、生成テキストそのものを採点する仕組みが不可欠であるという点です。レイテンシやエラー率といった運用メトリクスは応答品質の代理指標にはならず、センチメント分析も極性しか測れないため、ハルシネーションや回答の網羅性といった品質劣化を見逃します。 この時点で、運用監視のみで品質を判断する構成や、センチメントだけで合否を決める構成は要件不一致と判断できます。 次に「人間レビュアーのフィードバック」要件です。Amazon Bedrock の人間評価ジョブは、Likert 尺度・Thumbs up/down・Preference rank などの評価 UI と作業ワークフローを提供し、レビュアーの判定結果を構造化された JSON として S3 に出力します。 これは「毎日手動でレビューする」といった非構造的な運用とは本質的に異なり、収集した評価データを後段のしきい値判定に直接利用できる点で優位です。 「複数プロンプトテンプレートの自動比較」と「公平性」を考えるとき、本番トラフィックのサンプリングは入力分布が制御できず、テンプレート間の比較で変数が混在します。一方、Amazon Bedrock の評価ジョブはカスタムプロンプトデータセットを共通入力として複数構成へ適用するため、入力条件を固定した上で出力差分を観測でき、再現性のある比較が可能です。 最後に「デプロイゲート」要件です。Amazon Bedrock 評価ジョブは API(CreateEvaluationJob)と結果出力を備えるため、AWS CodePipeline のステージから評価ジョブを起動し、得られたスコアを条件式に通すことで、しきい値未達の設定を後続ステージへ進めない自動ゲートを構築できます。 これにより、プロンプトテンプレートやモデル設定が変更されるたびに、評価→判定→デプロイの一貫したワークフローが機械的に走り、低品質設定の本番投入を構造的に防げます。 これらの観点を統合すると、評価ジョブと CodePipeline を組み合わせる構成のみが、4つの要件すべてを単一のマネージド基盤で満たすことが導かれます。 参考資料
- Evaluate the performance of Amazon Bedrock resources(公式ドキュメント)
- Amazon Bedrock Evaluations 製品ページ
- Starting an automatic model evaluation job in Amazon Bedrock
- Create a human-based model evaluation job – Amazon Bedrock
- Use prompt datasets for model evaluation in Amazon Bedrock
- Create a prompt dataset for a model evaluation job that uses a model as judge
- Review a human-based model evaluation job in Amazon Bedrock
- CreateEvaluationJob API リファレンス
- GetEvaluationJob API リファレンス
- Monitor Amazon Bedrock job state changes using Amazon EventBridge
- Amazon Bedrock model evaluation is now generally available(AWS Blog)
- AWS CodePipeline 製品ページ
- Invoke an AWS Lambda function in a pipeline in CodePipeline(continuation token パターン)
問題文:
ある医療機関グループは、複数のコンテンツソースから自動的に職員研修教材を生成するシステムを必要としています。コンテンツソースには、ドキュメントファイル(PDFファイル、Word文書)とマルチメディアファイル(手術手技の録画動画)が含まれます。このシステムは、1日あたり10,000件以上のコンテンツソースを処理する必要があり、ピーク時には500件の同時アップロードに対応する必要があります。また、ドキュメントファイルとマルチメディアファイルからキーとなる概念を抽出し、文脈的に正確な要約を作成しなければなりません。生成された研修教材は、バージョン管理機能を備えたリアルタイムでの共同編集をサポートする必要があります。 これらの要件を満たすソリューションはどれですか。
選択肢:
A. Amazon Bedrock Data Automation(BDA)とAWS Lambda関数を使用してドキュメントファイルの処理をオーケストレーションします。すべてのマルチメディアコンテンツの処理にAmazon Bedrock Knowledge Basesを使用します。レプリケーションを設定したAmazon DocumentDBにコンテンツを保存します。Amazon SNSトピックのサブスクリプションを使用して共同作業を行います。Amazon Bedrock Agentsを使用して変更を追跡します。
B. Amazon Bedrock Data Automation(BDA)とAWS Lambda関数を使用して、コンテンツファイルのバッチを処理します。Amazon Bedrockで基盤モデル(FM)をファインチューニングして、すべてのコンテンツタイプのドキュメントを分類します。Amazon ElastiCache(Redis OSS)にクラスターモードとシャーディングを使用して、処理済みデータを保存します。バージョン管理にはAmazon Bedrockのプロンプト管理機能を使用します。
C. Amazon Bedrock Data Automation(BDA)と基盤モデル(FM)を使用してドキュメントファイルを処理します。BDAをAmazon TextractのPDF抽出機能、およびAmazon Transcribeのマルチメディアファイル機能と統合します。バージョニングを有効にしたAmazon S3に処理済みコンテンツを保存します。メタデータはAmazon DynamoDBに保存します。AWS AppSyncのGraphQLサブスクリプションとDynamoDBを使用してリアルタイムで共同作業を行います。
D. Amazon Bedrock Data Automation(BDA)とAmazon SageMaker AIエンドポイントを使用して、コンテンツの抽出と要約モデルをホストします。Amazon Bedrock Guardrailsを使用して、すべてのファイルタイプからコンテンツを抽出します。Amazon Neptuneを使用して、ドキュメントファイルを時系列分析用に保存します。リアルタイムメッセージングにはAmazon Bedrock Chatを使用して共同作業を行います。
正解:C
A. Amazon Bedrock Data Automation(BDA)とAWS Lambda関数を使用してドキュメントファイルの処理をオーケストレーションします。すべてのマルチメディアコンテンツの処理にAmazon Bedrock Knowledge Basesを使用します。レプリケーションを設定したAmazon DocumentDBにコンテンツを保存します。Amazon SNSトピックのサブスクリプションを使用して共同作業を行います。Amazon Bedrock Agentsを使用して変更を追跡します。
不正解 Amazon Bedrock Knowledge Basesは検索拡張生成(RAG)のために知識ソースをベクトル化して保持するサービスであり、マルチメディアの中核処理基盤として位置付けるとアーキテクチャが冗長になります。Amazon SNSはトピック・サブスクリプション型のメッセージング基盤で、WebSocketで継続接続する双方向のリアルタイム共同編集には適合しません。Amazon Bedrock Agentsは基盤モデルへの推論呼び出しと外部ツール連携をオーケストレーションする機能であり、ドキュメントの版管理機能は備えていません。
B. Amazon Bedrock Data Automation(BDA)とAWS Lambda関数を使用して、コンテンツファイルのバッチを処理します。Amazon Bedrockで基盤モデル(FM)をファインチューニングして、すべてのコンテンツタイプのドキュメントを分類します。Amazon ElastiCache(Redis OSS)にクラスターモードとシャーディングを使用して、処理済みデータを保存します。バージョン管理にはAmazon Bedrockのプロンプト管理機能を使用します。
不正解 Amazon ElastiCache(Redis OSS)はインメモリキャッシュであり、高スループットの低レイテンシ参照を目的としたデータストアです。永続的な研修教材の主たる保存先には適さず、容量超過時にはキーが追い出されるリスクを伴います。Amazon Bedrockのプロンプト管理機能はプロンプトテンプレートの版管理を行う機能であり、生成された研修教材自体のバージョン管理用途には対応しません。コンテンツ分類のためだけに基盤モデルをファインチューニングするのも過剰です。
C. Amazon Bedrock Data Automation(BDA)と基盤モデル(FM)を使用してドキュメントファイルを処理します。BDAをAmazon TextractのPDF抽出機能、およびAmazon Transcribeのマルチメディアファイル機能と統合します。バージョニングを有効にしたAmazon S3に処理済みコンテンツを保存します。メタデータはAmazon DynamoDBに保存します。AWS AppSyncのGraphQLサブスクリプションとDynamoDBを使用してリアルタイムで共同作業を行います。
正解 Amazon Bedrock Data Automationはドキュメント、画像、音声、動画といった非構造化マルチモーダルコンテンツから構造化インサイトを自動生成するサービスで、PDFやDOCXに加え動画も扱えます。Amazon Transcribeで音声・動画文字起こしを補強し、Amazon S3のバージョニングで成果物の世代管理を実現できます。AWS AppSyncのGraphQLサブスクリプションはWebSocketで変更をプッシュするためリアルタイム共同編集に適合し、DynamoDBはピーク時の同時アクセスにスケールします。
D. Amazon Bedrock Data Automation(BDA)とAmazon SageMaker AIエンドポイントを使用して、コンテンツの抽出と要約モデルをホストします。Amazon Bedrock Guardrailsを使用して、すべてのファイルタイプからコンテンツを抽出します。Amazon Neptuneを使用して、ドキュメントファイルを時系列分析用に保存します。リアルタイムメッセージングにはAmazon Bedrock Chatを使用して共同作業を行います。
不正解 Amazon Bedrock Guardrailsは入出力に対する有害コンテンツのフィルタリングや個人情報の遮断を行うガードレール機能であり、ファイルからのコンテンツ抽出機能は提供していません。Amazon Neptuneはノードとエッジで関係性を表現するグラフデータベースであり、時系列分析やドキュメント保存の用途には合致しません。「Amazon Bedrock Chat」というリアルタイムメッセージング向けのサービスは存在せず、共同編集の実装基盤として成立しません。
全体的な説明
問われている要件
- PDF・Word・録画動画という複数モダリティを統一的に処理できること
- 1日1万件以上、ピーク時500並列のアップロードに耐えるスケーラビリティ
- ドキュメントとマルチメディアの両方からキー概念抽出と文脈正確な要約生成ができること
- 生成された研修教材のバージョン管理機能を備えること
- WebSocketなどによるリアルタイム共同編集を実現できること
前提知識 Amazon Bedrock Data Automation(BDA)について
- BDAはドキュメント、画像、音声、動画といった非構造化マルチモーダルコンテンツから構造化されたインサイト(テキスト、要約、シーンサマリー、文字起こし等)を自動生成するマネージドサービスです。
- 標準出力(Standard Output)はファイルを送るだけで既定のインサイトを返し、カスタム出力(Custom Output)はブループリントで抽出項目を定義できます。
- ドキュメントは PDF、TIFF、JPEG、PNG、DOCX をサポートし、スプリッター有効時は1ファイル最大3,000ページまで処理できます。動画は H.264/H.265/AV1/MPEG-4 などをサポートし、MP4/M4V/MOV はビデオまたはオーディオとしてルーティング可能です。
Amazon Textract と Amazon Transcribe について
- Amazon TextractはOCRと帳票・表抽出に特化したサービスで、構造化フィールドの取り出しに強みを持ちます。
- Amazon Transcribeは音声・動画から自動音声認識(ASR)でテキストを生成するサービスで、話者分離やタイムスタンプ付き文字起こしに対応します。
- BDAは内部で同等の機能を持ちますが、専用ジョブ単体で扱いたい場合や既存パイプラインへの統合では別サービスとしての利用も有効です。
Amazon S3 のバージョニングについて
- S3のバージョニングはバケット単位で有効化する機能で、上書き・削除のたびに固有のバージョンIDを付けてオブジェクトを保持します。誤削除は「削除マーカー」が現行版になるだけで、過去版から復元できます。
- 一度有効化したバージョニングは無効化はできず、停止のみ可能です。世代ごとに課金されるため、ライフサイクルルールで古い世代をアーカイブまたは削除する運用が一般的です。
- 研修教材ファイルそのもののバージョン管理用途として、追加の実装なしで利用できる強力な基盤になります。
AWS AppSync の GraphQLサブスクリプションについて
- AWS AppSyncはマネージド型のGraphQL APIサービスで、Query(取得)、Mutation(更新)、Subscription(購読)の3種のオペレーションを提供します。Subscriptionは pure WebSocket で確立され、Mutationが発生するとサーバが購読中のクライアントに変更内容をプッシュします。
- データソースとして Amazon DynamoDB、AWS Lambda、Aurora、OpenSearch、HTTP エンドポイント等を直接接続でき、リゾルバーで GraphQL 操作を各データソースの操作にマッピングします。
- グループチャット、スコア更新、共同編集のように「複数ユーザーへの即時反映」が必要なユースケースに最適です。
Amazon DynamoDB と他のストレージ系サービスについて
- DynamoDBはサーバーレスなNoSQLデータベースで、オンデマンドキャパシティ/オートスケーリングにより同時アクセスのスパイクへ自動追従します。メタデータインデックスや状態管理に向きます。
- Amazon DocumentDBは MongoDB API 互換のドキュメントDBで、JSON文書のクエリ用途。Amazon Neptuneはグラフ用、Amazon ElastiCache(Redis)はインメモリキャッシュ用と、サービスごとに役割が分かれており、用途を取り違えるとコスト・性能・耐久性のいずれかが劣化します。
不正解選択肢のサービスについて
- Amazon Bedrock Guardrailsは入出力フィルタ、PII遮断、トピック禁止などの安全制御を行う機能で、抽出処理は行いません。
- Amazon Bedrock Agentsは基盤モデルとAPI連携をオーケストレーションする機能で、ドキュメントのバージョン管理は提供しません。
- Bedrockのプロンプト管理(Prompt management)はプロンプトテンプレートの管理機能であり、生成成果物の版管理用途とは別物です。
- Amazon SNSはpub/sub型メッセージングであり、リアルタイム共同編集の継続接続型UIには直接適合しません。
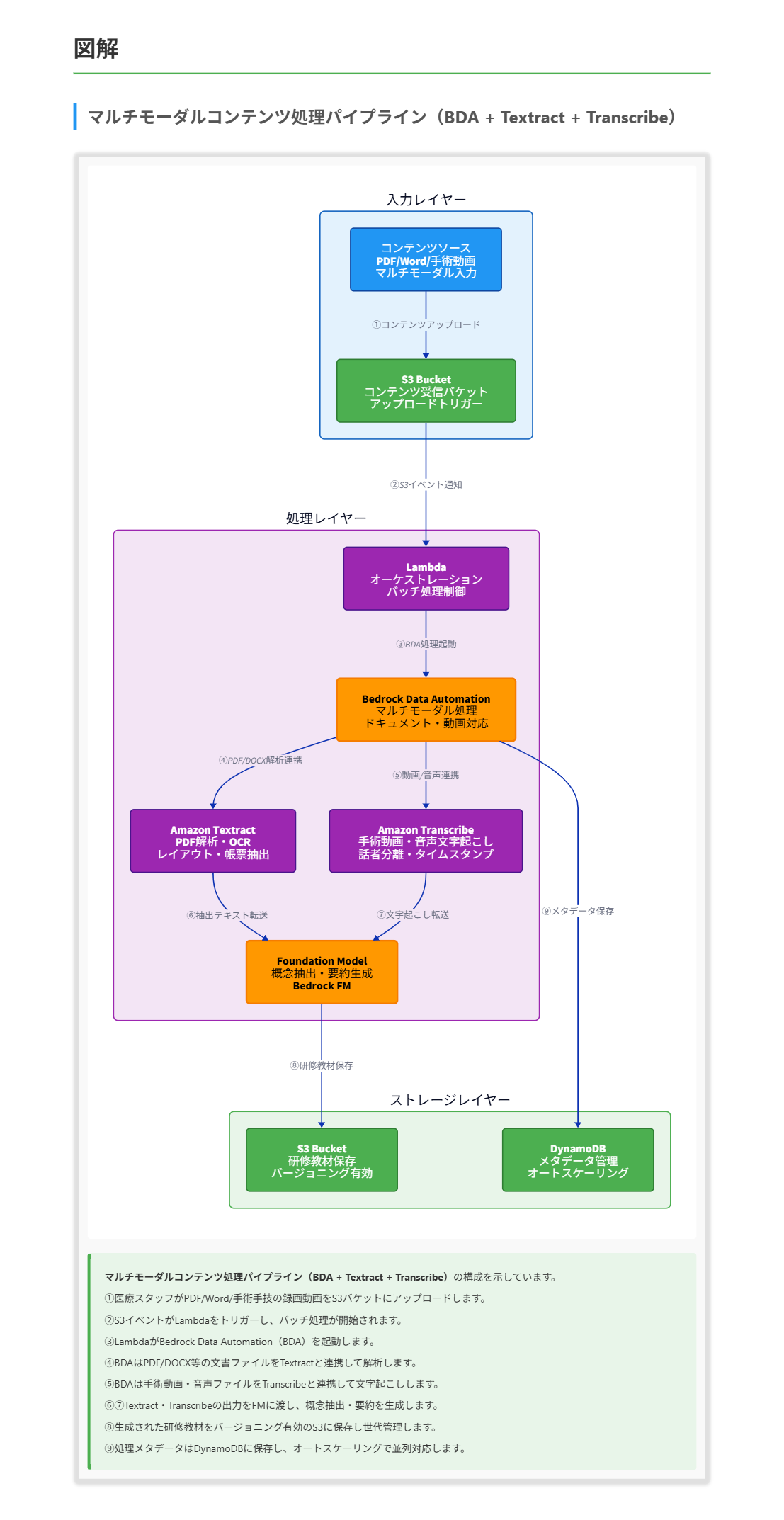
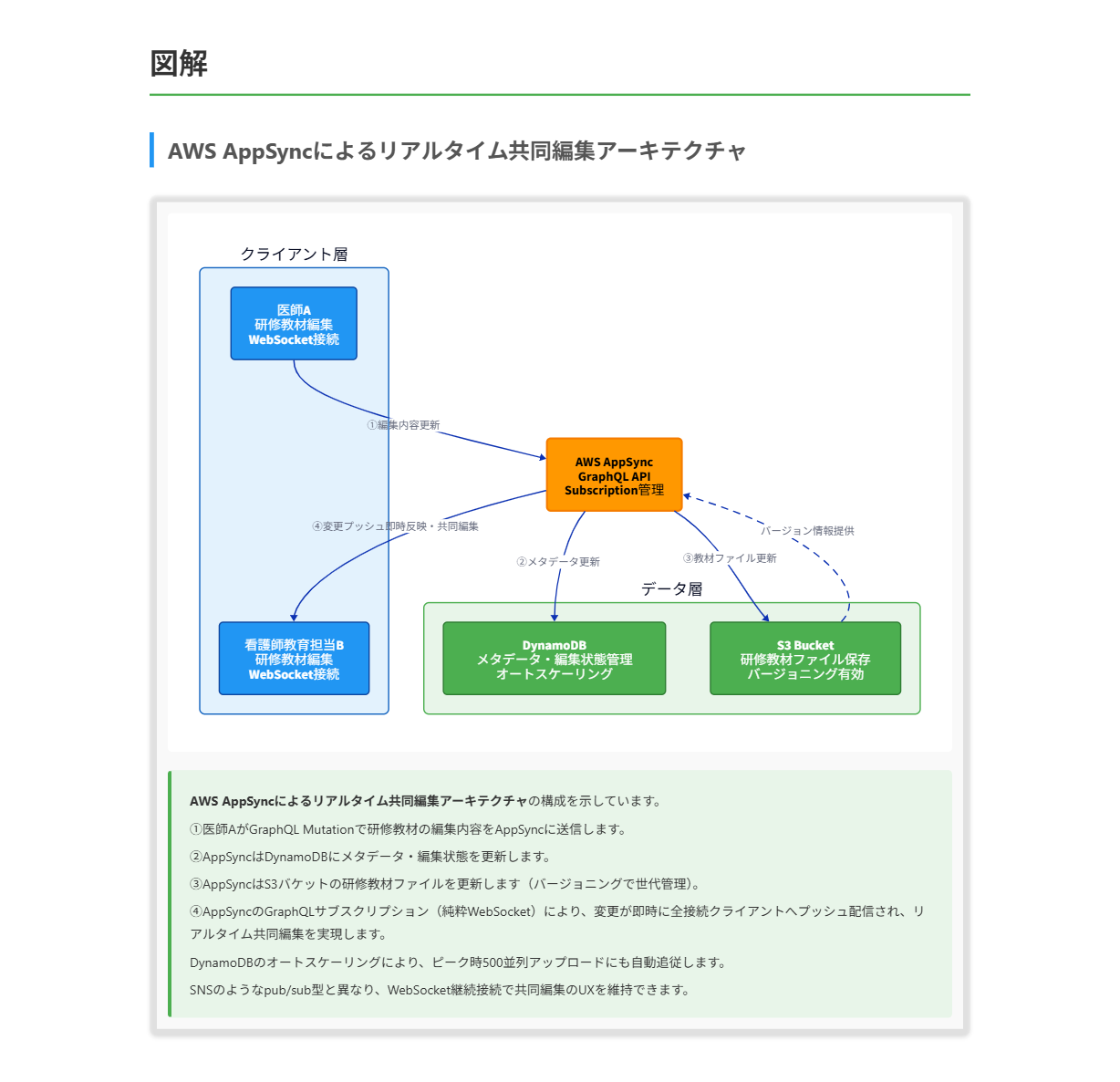
解くための考え方
この問題は、ドキュメントとマルチメディアという異種コンテンツを統一的に処理しつつ、保存・バージョン管理・リアルタイム共同編集まで一気通貫で実装できるアーキテクチャを選ぶ問題です。 最初に注目すべきは「PDF・Word・動画から概念抽出と要約」という要件です。BDAはPDF・DOCX(Word)・動画を直接処理でき、文書系ファイルからのテキスト・テーブル抽出、動画からのシーン要約と文字起こしをマネージドで提供します。 これにAmazon TextractやAmazon Transcribeを補助的に組み合わせれば、PDFのレイアウト解析や音声認識の精度・運用要件にも応えられます。 次に「バージョン管理」を満たす保存先を考えます。 S3バージョニングはバケット単位で有効化するだけで、上書き・削除のたびに自動で世代を保持し、過去版を復元可能です。 研修教材という大きなデータを安価に長期保存しつつ、ライフサイクルポリシーで世代コストを抑えられる点が効きます。 これに対して、インメモリキャッシュは永続ストレージとして耐久性に欠け、プロンプト管理機能はテンプレート管理であり生成成果物の版管理は守備範囲外です。 最後に「リアルタイム共同編集」です。 ここで決め手になるのがAWS AppSyncのGraphQLサブスクリプションで、pure WebSocketによりMutationを起点に変更を即時にプッシュ配信できます。 DynamoDBをデータソースに据えれば、ピーク時500並列のアップロードに伴うメタデータ更新も自動スケーリングで吸収できます。 pub/sub型のSNSはトピック配信向きで、ユーザーセッションを維持する共同編集には設計が合いません。 Bedrock Agentsはタスクオーケストレーション、Bedrock Guardrailsは安全性フィルタ、Neptuneはグラフ、ElastiCacheはキャッシュと、それぞれ用途が固定されており、要件に対する直接の解にはなりません。 これらを総合すると、BDAをコア処理としてS3バージョニング・DynamoDB・AppSyncを組み合わせた構成がもっとも整合的です。 参考資料
- Amazon Bedrock Data Automation ユーザーガイド
- Bedrock Data Automation の前提条件とファイル制限
- Amazon Bedrock Data Automation now supports DOC/DOCX and H.265 files
- Amazon Bedrock Data Automation supports additional formats for video
- Amazon Transcribe ドキュメント
- Amazon Textract ドキュメント
- Amazon S3 バージョニングの概要
- AWS AppSync GraphQL サブスクリプション
- AWS AppSync の概要ページ
- Amazon DynamoDB オートスケーリング
- Amazon Bedrock Guardrails 概要
- Amazon Bedrock Knowledge Bases マルチモーダル対応
問題文:
あるオンラインゲーム会社が、Amazon SageMaker AI 上で動作するコンテナ化された大規模言語モデル(LLM)を使用するゲーム内サポートチャットボットを開発しています。アーキテクチャは、Amazon API Gateway の REST API がプレイヤーからのリクエストを AWS Lambda 関数へルーティングし、その Lambda 関数が LLM をホストする SageMaker AI のリアルタイムエンドポイントを呼び出す構成です。 プレイヤーから応答時間にばらつきがあるとの報告が寄せられています。分析によると、最初のトークンが返ってくるのを 2 秒間待った時点でチャットを離脱するケースが多発しています。同社は、対話的なリクエストに対する p95 レイテンシを 800 ms 未満に抑えるソリューションを求めています。 この要件を満たすソリューションの組み合わせはどれですか。(2 つ選択)
選択肢:
A. SageMaker AI エンドポイントに、より大型の GPU インスタンスタイプを選択します。
B. コンテナ起動時にモデルをプリロードします。
C. 最初のリクエストが来たタイミングでモデルの重みを遅延ロードします。
D. 最小インスタンス数を 0 より大きく設定し、レスポンスストリーミングを有効化します。
E. 動的バッチング(dynamic batching)を実装し、複数のプレイヤーのリクエストを 1 回の推論パスにまとめて処理します。
正解:B、D
A. SageMaker AI エンドポイントに、より大型の GPU インスタンスタイプを選択します。
不正解 GPU インスタンスを大型化してもトークン生成速度が上がるかどうかはモデルの並列性とメモリ要件に依存し、最初のトークン到達までの遅延の主因であるコールドスタートやストリーミング未対応の問題は解消されません。インスタンスがゼロから起動する場合は数十秒単位の起動時間が支配的になり、計算資源の増強だけでは p95 800 ms の目標達成には不十分です。
B. コンテナ起動時にモデルをプリロードします。
正解 コンテナ起動時にモデルの重みを GPU メモリへロードし切る設計にすることで、エンドポイントが InService 状態になった時点で即座に推論を開始できます。LLM では数十 GB の重み読み込みと初期化が大きなボトルネックとなるため、ヘルスチェック前にロードを完了させておけば初回リクエストでのロード待ちが排除され、最初のトークン到達までの時間を大きく短縮できます。
C. 最初のリクエストが来たタイミングでモデルの重みを遅延ロードします。
不正解 重みを初回リクエスト時に読み込む方式では、最初の呼び出しでダウンロードと初期化が完了するまで応答を返せません。LLM の場合は数十 GB のアーティファクトを扱うため、最初のトークン生成までに数十秒のペナルティが発生します。スケールアウトで新インスタンスが追加されるたびに同じ遅延が再発するため、p95 800 ms 未満は達成不能です。
D. 最小インスタンス数を 0 より大きく設定し、レスポンスストリーミングを有効化します。
正解 MinInstanceCount を 0 より大きくすることでエンドポイントを常時暖機状態に保ち、scale-to-zero に伴うコールドスタートを回避できます。加えて InvokeEndpointWithResponseStream API によるレスポンスストリーミングは、HTTP/1.1 chunked encoding で生成済みトークンを逐次送信するため、time-to-first-byte が劇的に改善し、最初のトークンを待つ離脱問題を直接解消します。
E. 動的バッチング(dynamic batching)を実装し、複数のプレイヤーのリクエストを 1 回の推論パスにまとめて処理します。
不正解 動的バッチングはサーバが一定時間(既定 max_batch_delay は 100 ms)リクエストを蓄積し、まとめて 1 パスで処理することで GPU 使用率とスループットを高める手法です。本質的にバッチ集約のための待機時間が個々のリクエストに加算されるため、スループットとレイテンシはトレードオフの関係になり、対話型用途では p95 レイテンシを悪化させます。
全体的な説明
問われている要件
- SageMaker AI のリアルタイムエンドポイントで動作する LLM チャットの応答性を改善することが目的です。
- 症状は「最初のトークンが届くまでの 2 秒間で離脱が多発」であり、time-to-first-token が支配要因です。
- p95 レイテンシ 800 ms 未満という対話型ワークロードの SLO を達成する必要があります。
- スループット最適化ではなく、ユーザー知覚レイテンシの短縮を優先する設計判断が求められます。
- 2 つの施策を組み合わせて、コールドスタート要因と知覚レイテンシ要因の両方を同時に潰す必要があります。
前提知識 SageMaker AI リアルタイムエンドポイントのレイテンシ構造について
- リアルタイムエンドポイントのレイテンシは、SageMaker のオーバーヘッドレイテンシと、コンテナ内のモデルレイテンシ、クライアント間のネットワークレイテンシに分解されます。CloudWatch では ModelLatency と OverheadLatency としてそれぞれ観測可能です。
- スケールイン後の最初のリクエストではコールドスタート(インスタンス起動とコンテナ初期化、モデル重みのロード)が発生し、LLM では数十秒〜数分の待ちとなります。
- ManagedInstanceScaling の MinInstanceCount を 0 より大きく設定するとエンドポイントは常に最低 N 台が稼働し、コールドスタートを回避できます。逆に 0 にすると idle 時のコスト削減と引き換えに初回応答の遅延が発生します。
LLM 推論の time-to-first-token と response streaming について
- LLM はトークンを 1 つずつ生成するため、レスポンス全体の生成完了を待つと数秒〜数十秒の遅延を伴います。これが「first token を待つ離脱」の原因です。
- SageMaker のリアルタイム推論は InvokeEndpointWithResponseStream API でレスポンスストリーミングをサポートし、HTTP/1.1 chunked encoding で生成済みトークンを逐次クライアントへ送信します。Hugging Face TGI では Server-Sent Events、LMI でも同等のトークンストリーミングが利用可能です。
- ストリーミングはチャットボットなど対話的 UX で「最初の数文字が表示されるまでの体感時間」を劇的に短縮します。
コンテナ起動とモデルロード戦略について
- LLM コンテナの起動シーケンスは、コンテナイメージのプル、コンテナ起動、モデル重みのダウンロード、テンソルパラレル等の初期化、ヘルスチェック合格、の順で進みます。
- モデルプリロードは、ヘルスチェック前に重みをメモリへ完全に展開する戦略で、初回リクエストでロード待ちが発生しないようにします。これに対し遅延ロード(lazy loading)は初回呼び出し時にロードを開始するため、最初のリクエストの応答時間が極端に悪化します。
- 補助的な高速化策として、Container Caching によるイメージプル時間短縮や Fast Model Loader による S3 から GPU への直接ストリームロードがあります。
バッチング戦略とレイテンシ/スループットのトレードオフについて
- 動的バッチングはサーバ側で短時間リクエストを蓄積して 1 パスで処理する方式で、GPU 利用率とスループットを大きく改善する一方、待機時間がレイテンシに加算されます。バッチサイズ 4〜8 で実用的なレイテンシを保てるとされ、64〜128 まで上げるとスループット最大化と引き換えにレイテンシが悪化します。
- 連続バッチング(continuous batching)や PagedAttention は、バッチ内で完了したリクエストの席を新規リクエストへ即座に割り当てるため、純粋な動的バッチングよりレイテンシ/スループットの両立に優れます。
- 対話的低レイテンシ要件では、バッチング由来の待機時間そのものを削るより、コールドスタート除去とストリーミング採用の方が効果的です。
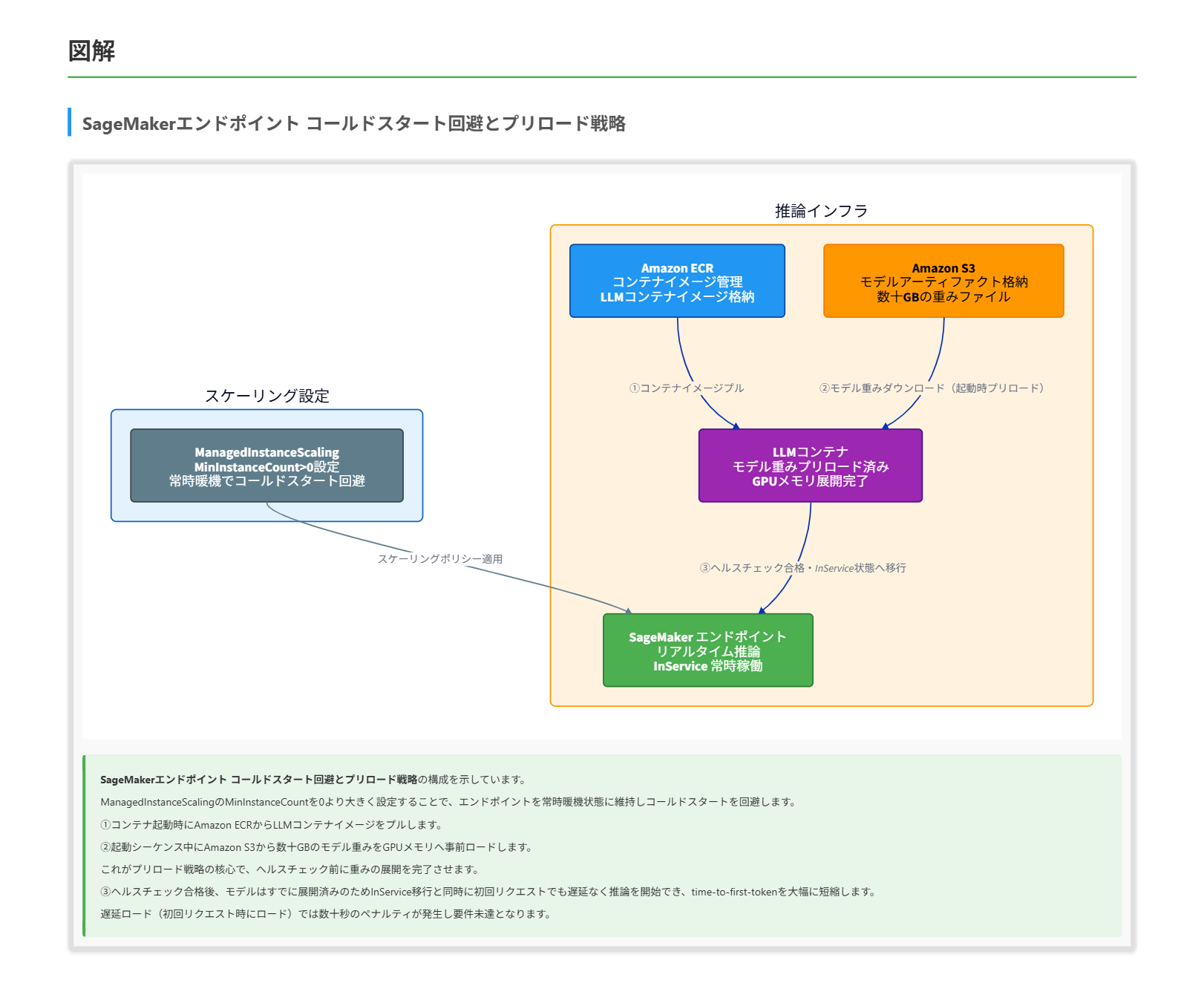
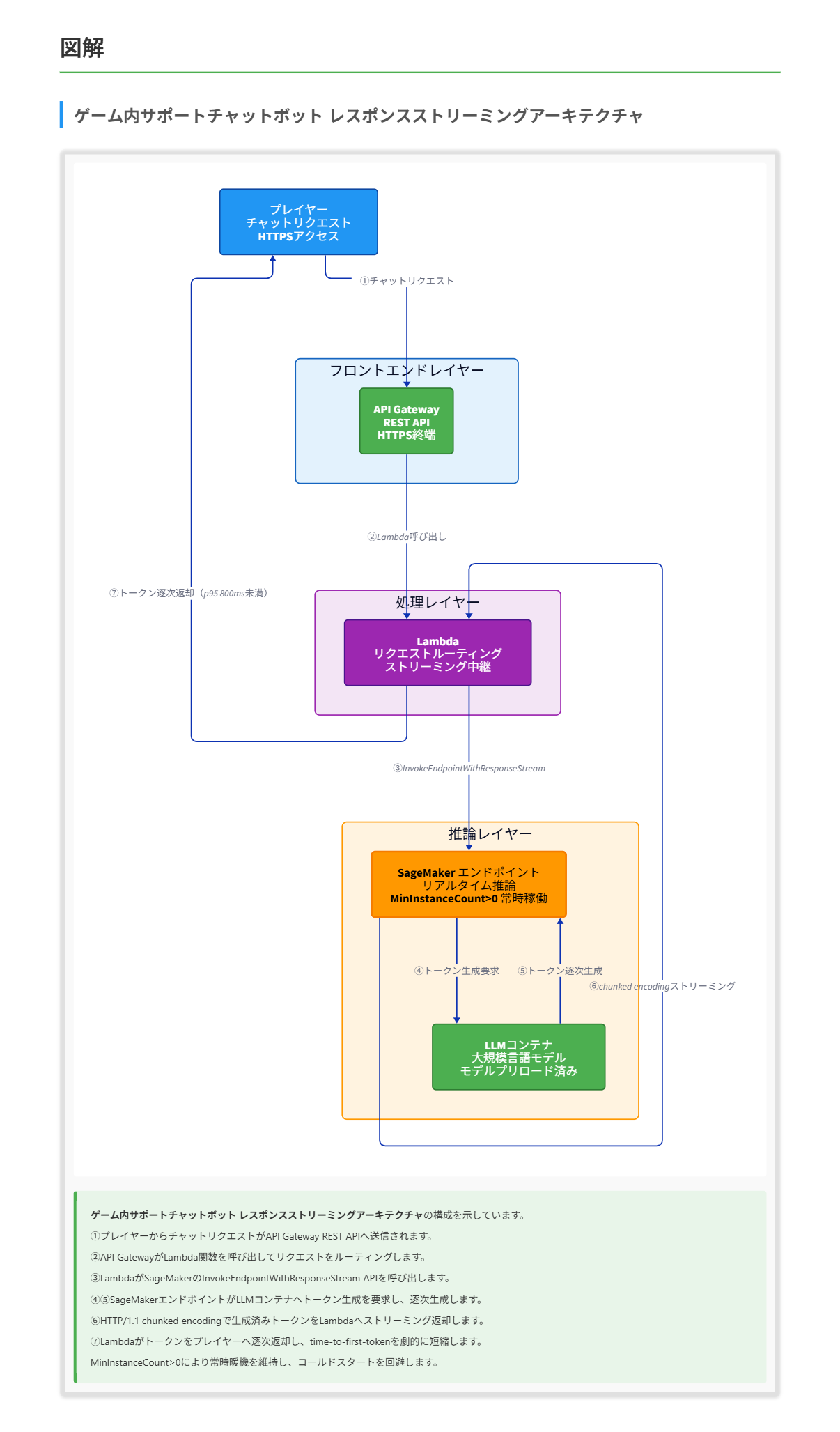
解くための考え方
問題の症状は「最初のトークンを 2 秒待ったところで離脱」と非常に具体的で、ボトルネックが「first token に到達するまでの時間」にあることを示しています。 レスポンス全体の生成時間ではなく、エンドポイントが応答を開始するまでの時間が問題の核心であるため、解決策は「応答開始タイミングを早める」方向に絞り込めます。 応答開始の遅さを生み出す要因は大きく 2 つあります。 1 つはインフラ起動時の遅延、すなわちエンドポイントがアイドルから起動するときのコールドスタートと、コンテナ初回起動時のモデルロードです。 もう 1 つはアプリケーションレベルの設計、すなわちレスポンス生成完了を待ってから一括返却するか、生成中のトークンを逐次返すかという違いです。 最初の要因に対しては、モデル重みをコンテナ起動シーケンスの中で先に読み込んでしまう「プリロード」が直接的な対策になります。 これにより InService 状態に到達した瞬間から推論を即座に開始できるため、初回呼び出しのロード待ちが消えます。 2 つ目の要因に対しては、最小インスタンス数を 0 より大きく設定して常時稼働を確保しつつ、レスポンスストリーミングを有効化して先頭トークンが生成された瞬間にクライアントへ送り始めるという二段構えが必要です。 最小インスタンス数の確保はコールドスタート発生確率そのものを下げ、ストリーミングは知覚レイテンシを根本から短縮します。 両者は相補的で、片方だけでは 800 ms p95 を安定して達成しづらい構造です。 逆に動的バッチングはバッチ集約のための待機時間を加算し対話型 SLO を悪化させ、GPU の大型化はコールドスタートやストリーミング未対応という根本要因に効きません。 遅延ロードは初回応答を意図的に遅らせる設計で、要件と正反対の方向に働きます。 よって、コールドスタートを除去するモデルプリロードと、常時暖機+ストリーミングの組み合わせが、p95 800 ms 達成への最短ルートになります。 参考資料
- Amazon SageMaker AI でのリアルタイム推論 – Amazon SageMaker AI
- Elevating the generative AI experience: Introducing streaming support in Amazon SageMaker hosting – AWS Machine Learning Blog
- Inference Llama 2 models with real-time response streaming using Amazon SageMaker – AWS Machine Learning Blog
- Stream large language model responses in Amazon SageMaker JumpStart – AWS Machine Learning Blog
- SageMaker AI モデルの自動スケーリング – Amazon SageMaker AI
- Unlock cost savings with the new scale down to zero feature in SageMaker Inference – AWS Machine Learning Blog
- Introducing Fast Model Loader in SageMaker Inference: Accelerate autoscaling for your Large Language Models (LLMs) – part 1 – AWS Machine Learning Blog
- Supercharge your auto scaling for generative AI inference – Introducing Container Caching in SageMaker Inference – AWS Machine Learning Blog
- Improve performance of Falcon models with Amazon SageMaker – AWS Machine Learning Blog
- Best practices for load testing Amazon SageMaker real-time inference endpoints – AWS Machine Learning Blog
問題文:
ある金融サービス会社が Amazon Bedrock を利用して生成 AI(GenAI)システムを構築しています。このシステムは多様なソースからデータを処理し、エンドツーエンドのデータ系統(データリネージ)を維持する必要があります。さらに、リアルタイムでの個人を特定できる情報(PII)フィルタリングと、コンプライアンスを自動的に報告するための監査証跡も備える必要があります。 これらの要件を満たすソリューションはどれですか。
選択肢:
A. Amazon DataZone を使用してすべてのデータソースを登録しエンドツーエンドのデータ系統を追跡します。Amazon Bedrock Guardrails の PII フィルターを使用します。AWS CloudTrail のロギングを Amazon Bedrock の全 API 呼び出しに対して有効化し、Amazon S3 と統合します。Amazon Macie で保存データをスキャンして機微情報を検出し、AWS Security Hub に集約してコンプライアンスレポートを生成します。
B. AWS Config を使用してデータソースの設定と変更を追跡します。AWS WAF とカスタムルールを使用して、Amazon Bedrock がデータを処理する前にアプリケーション層で PII をフィルタリングします。Amazon EventBridge を構成して監査イベントを取得し Amazon S3 にルーティングします。Amazon Comprehend Medical と AWS Lambda のスケジュール実行関数を使用して、保存された出力をコンプライアンス違反について分析します。
C. AWS DataSync を使用してデータソースを複製しデータ系統を追跡します。Amazon Macie を構成して Amazon Bedrock の出力をスキャンし機微情報を検出します。AWS Systems Manager Session Manager を使用してユーザー操作をログに記録します。Amazon Textract と AWS Step Functions ワークフローをデプロイして、生成されたレポートから PII を識別して編集します。
D. Amazon Athena を構成してデータソースをクエリし、データ系統を分析および報告します。Amazon CloudWatch のカスタムメトリクスを使用して Amazon Bedrock 応答内の PII 露出を監視し、AWS X-Ray のトレーシングを構築して監査証跡を生成します。Amazon Rekognition Custom Labels モデルを使用して、Amazon Bedrock が処理するデータ内の機微情報を検出します。
正解:A
A. Amazon DataZone を使用してすべてのデータソースを登録しエンドツーエンドのデータ系統を追跡します。Amazon Bedrock Guardrails の PII フィルターを使用します。AWS CloudTrail のロギングを Amazon Bedrock の全 API 呼び出しに対して有効化し、Amazon S3 と統合します。Amazon Macie で保存データをスキャンして機微情報を検出し、AWS Security Hub に集約してコンプライアンスレポートを生成します。
正解 Amazon DataZone はデータソースの登録からデータ消費までのエンドツーエンドのデータ系統を OpenLineage 互換形式で追跡・可視化し、コンプライアンスおよびデータガバナンスにおける出所の透明性を確保します。Amazon Bedrock Guardrails の機微情報フィルターは入力プロンプトとモデル応答中の PII を機械学習でリアルタイムに検出し、ブロックまたはマスクします。CloudTrail は Bedrock の全 API 呼び出しを S3 に継続配信し、Macie は S3 内の PII を機械学習で検出して Security Hub に通知することで、4 つの要件すべてを満たします。
B. AWS Config を使用してデータソースの設定と変更を追跡します。AWS WAF とカスタムルールを使用して、Amazon Bedrock がデータを処理する前にアプリケーション層で PII をフィルタリングします。Amazon EventBridge を構成して監査イベントを取得し Amazon S3 にルーティングします。Amazon Comprehend Medical と AWS Lambda のスケジュール実行関数を使用して、保存された出力をコンプライアンス違反について分析します。
不正解 AWS Config は AWS リソースの構成変更を追跡するサービスであり、データの流れや変換履歴を示すデータ系統の追跡用途ではありません。AWS WAF は SQL インジェクションや XSS など Web アプリケーションへの攻撃を防ぐためのファイアウォールであり、PII の検出・マスキング機能は備えていません。さらに、Comprehend Medical をスケジュール実行で適用する方式はバッチ処理となり、要件であるリアルタイム PII フィルタリングを満たせません。
C. AWS DataSync を使用してデータソースを複製しデータ系統を追跡します。Amazon Macie を構成して Amazon Bedrock の出力をスキャンし機微情報を検出します。AWS Systems Manager Session Manager を使用してユーザー操作をログに記録します。Amazon Textract と AWS Step Functions ワークフローをデプロイして、生成されたレポートから PII を識別して編集します。
不正解 AWS DataSync はオンプレミスや別ストレージ間でファイルを高速転送するためのデータ移行サービスであり、データ変換の履歴やソースから宛先への流れを記録する系統管理機能はありません。Systems Manager Session Manager は EC2 インスタンスへのシェルアクセスを管理する仕組みで、生成 AI アプリケーションの利用者操作をログ化する用途には合致しません。Textract と Step Functions による編集はワークフロー駆動のバッチ処理であり、リアルタイムでの PII フィルタリングは実現できません。
D. Amazon Athena を構成してデータソースをクエリし、データ系統を分析および報告します。Amazon CloudWatch のカスタムメトリクスを使用して Amazon Bedrock 応答内の PII 露出を監視し、AWS X-Ray のトレーシングを構築して監査証跡を生成します。Amazon Rekognition Custom Labels モデルを使用して、Amazon Bedrock が処理するデータ内の機微情報を検出します。
不正解 Amazon Athena は S3 上のデータに対してアドホックな SQL クエリを実行するサービスであり、データの変換履歴や依存関係を自動的に追跡する系統管理の機能は備えていません。AWS X-Ray は分散トレーシングでアプリケーションのリクエストフローやレイテンシを可視化するもので、コンプライアンス目的の監査証跡として CloudTrail の代替にはなりません。Rekognition Custom Labels は画像内のオブジェクト検出に特化しており、テキスト中の PII 検出には適合しません。
全体的な説明
問われている要件
- 多様なソースから取り込まれるデータについて、エンドツーエンドのデータ系統を維持できること
- 入力および出力に対してリアルタイムで PII をフィルタリングできること
- すべての処理が監査可能となるよう監査証跡を取得できること
- コンプライアンス報告を自動化できる仕組みを備えていること
- 金融業界の規制要件(GLBA、PCI DSS など)に整合する構成であること
前提知識 Amazon Bedrock Guardrails について
- Amazon Bedrock Guardrails は基盤モデルの入力プロンプトと応答に対して安全制御を適用する仕組みで、機微情報フィルター、コンテンツフィルター、トピック拒否、コンテキスト整合性チェックなどを提供します。
- 機微情報フィルターは氏名、住所、電話番号、SSN、クレジットカード番号など定義済み PII カテゴリを機械学習で検出し、BLOCK でブロック、ANONYMIZE でマスキングが可能です。
- カスタム正規表現も登録でき、医療業界固有の患者 ID 形式などにも対応できます。フィルター適用は推論実行時にリアルタイムで行われます。
Amazon DataZone について
- Amazon DataZone はデータの検索・共有・ガバナンスを一元管理するデータカタログサービスで、データソースの登録から消費までのエンドツーエンドのデータ系統(データリネージ)を OpenLineage 互換形式で追跡・可視化します。
- AWS Glue や Amazon Redshift などのデータソースを登録すると、データソース実行時にリネージイベントが自動的にキャプチャされます。また API を通じてカスタムのリネージイベントを送信することも可能です。
- コンプライアンスや監査の観点で「どのデータがどこから来てどう変換されたか」という出所の透明性を確保でき、HIPAA 等の規制要件への対応基盤として機能します。
- なお AWS Glue Data Catalog 単体はスキーマや場所などのメタデータリポジトリであり、エンドツーエンドのデータリネージの追跡・可視化には DataZone との統合が必要です。
AWS CloudTrail と Amazon Bedrock の統合について
- AWS CloudTrail は AWS アカウント内のユーザー、ロール、サービスによる操作を記録するサービスで、API 呼び出しごとに誰がいつ何をしたかを残せます。
- Amazon Bedrock のすべての API 呼び出し(InvokeModel、Converse、Agents 関連の操作など)はイベントとして記録され、証跡を作成すれば S3 へ継続的に配信されます。
- 監査証跡としてのデータが SOC、PCI、HIPAA などの規制への準拠を示す根拠資料として活用でき、コンプライアンス自動報告の基盤となります。
Amazon Macie について
- Amazon Macie は機械学習とパターンマッチングを用いて S3 上の機微情報を発見・分類するデータセキュリティサービスです。マネージドデータ識別子で氏名、住所、SSN、医療情報など多様な PII を検出できます。
- 自動検出ジョブと対象を絞ったジョブの両方が利用でき、HIPAA、GDPR、PCI DSS など規制対応のための継続的な監査が可能です。
- 検出結果は Amazon EventBridge と AWS Security Hub に送信でき、コンプライアンスレポートの自動生成や自動修復ワークフローと組み合わせて運用を自動化できます。
コンプライアンス可視化と自動報告について
- AWS Security Hub は Macie、GuardDuty、CloudTrail などの検出結果を一元集約し、CIS AWS Foundations Benchmark や PCI DSS、HIPAA などの標準フレームワークへの準拠状況を自動的に評価・レポートするセキュリティ管理サービスです。コンプライアンス報告の自動化には Security Hub の活用が適切です。
- CloudWatch Logs と CloudWatch ダッシュボードは Macie や CloudTrail の出力を集約して時系列で監視・可視化する用途に有効です。Security Hub と組み合わせることで、可視化と自動コンプライアンス評価の両方をカバーできます。
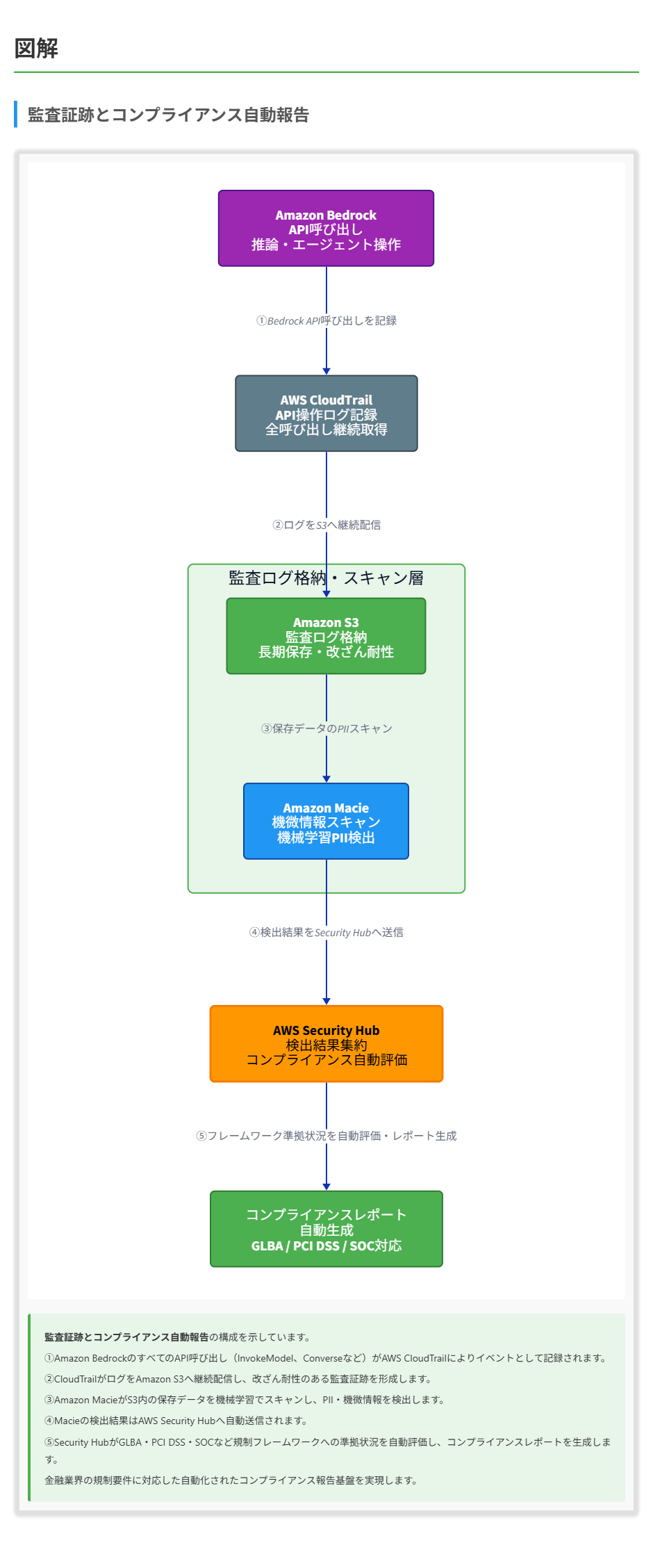
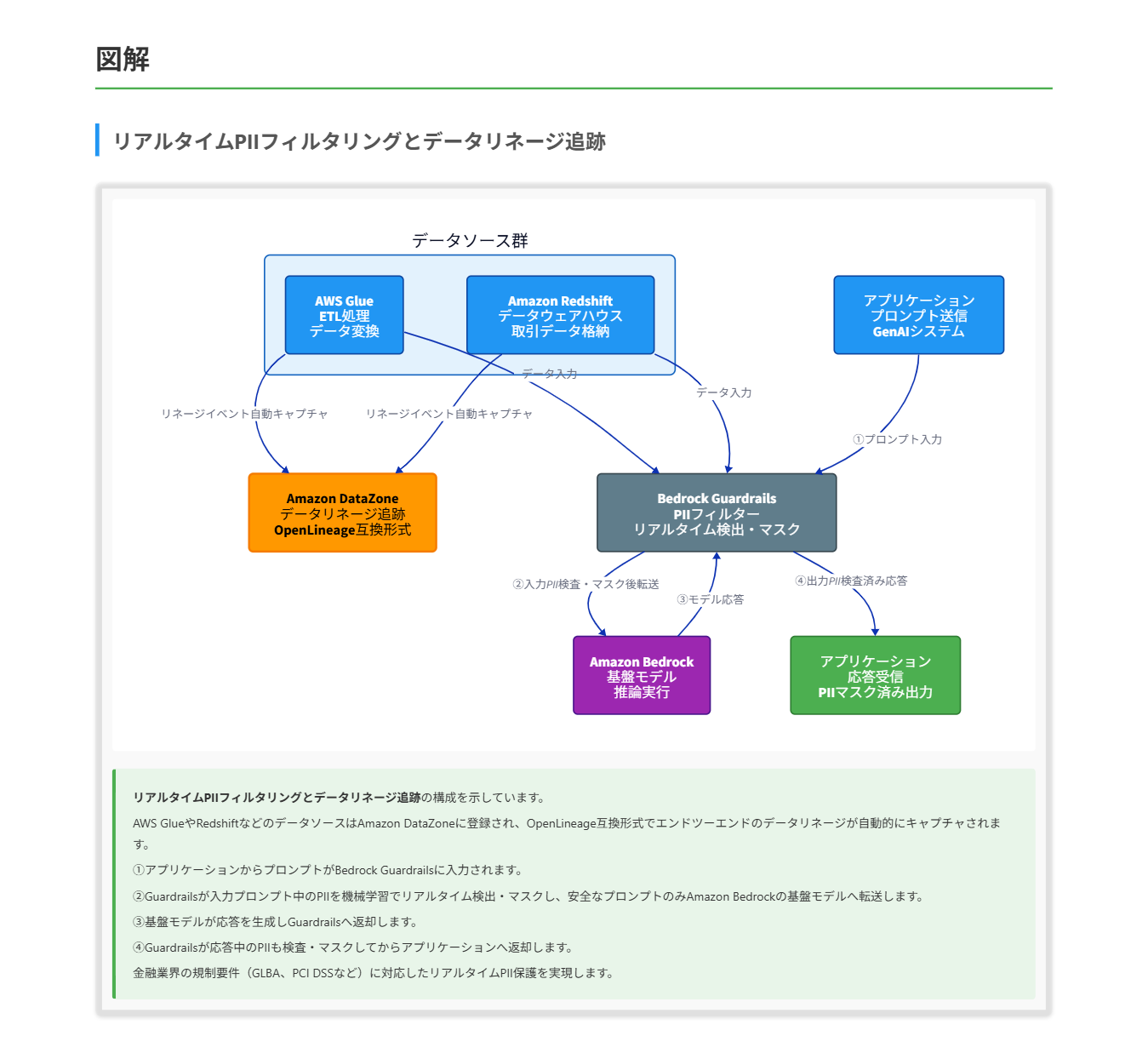
解くための考え方
この問題では「データ系統の維持」「リアルタイム PII フィルタリング」「監査証跡」「コンプライアンス自動報告」という 4 つの要件を同時に満たすアーキテクチャを選ぶ必要があります。 医療業界という背景から HIPAA への対応が求められ、各要件を専用のマネージドサービスでカバーする発想が出題の核となります。 データ系統の追跡には、ソースから消費までのデータの流れを記録・可視化できる専用サービスが必要となります。 AWS Glue Data Catalog はスキーマや場所といったメタデータを管理するリポジトリですが、エンドツーエンドのデータリネージの追跡・可視化には対応していません。OpenLineage 互換のリネージイベントをキャプチャし可視化できる Amazon DataZone が要件に合致します。 単純な複製サービスやクエリサービス、構成変更追跡サービスは「変換の履歴を含めた流れ」を体系的に管理する目的には設計されておらず、要件を満たしません。 リアルタイムの PII フィルタリングについては、生成 AI の推論経路に直接組み込めるガードレール機構が最適です。 Bedrock の機能としてプロンプトと応答の両方に対し推論時に PII を検出・マスク・ブロックできる仕組みが用意されているため、これを利用すればモデル呼び出し前後でレイテンシを最小化しつつ確実な制御が可能になります。 Web 層のファイアウォールやバッチ実行型の自然言語処理サービス、画像認識モデルでは推論経路上のリアルタイム保護にはなりません。 監査証跡については、API 呼び出しを誰がいつ実行したかを改ざん耐性のある形で記録する必要があります。 AWS の標準的な監査基盤として API 操作を網羅的に記録し S3 に永続化できるサービスを選ぶのが正解パターンです。 分散トレーシングはパフォーマンス分析向けであり、ガバナンス用途の監査証跡としては機能要件が異なります。 最後にコンプライアンス自動報告については、保存データに対する継続的な機微情報スキャンと結果の集約を組み合わせる必要があります。 S3 を対象に機械学習で PII を検出し Security Hub に通知できる仕組みを使い、標準フレームワークへの準拠状況を自動評価することで、人手を介さずに監査向けレポートを生成できます。 これら 4 つの要件を専用サービスで分担し、Bedrock の Guardrails、Amazon DataZone、CloudTrail、Macie、Security Hub を組み合わせる構成が、医療コンプライアンスの観点でも整合性の高い解答となります。 参考資料
- Amazon Bedrock Guardrails – 機微情報フィルター
- Amazon Bedrock Guardrails の概要
- CloudTrail を使用した Amazon Bedrock API 呼び出しの監視
- Amazon DataZone のデータリネージ
- Amazon DataZone の概要
- Amazon Macie – 機微データの検出
- Amazon Macie とは何か
- AWS Security Hub の概要
- Amazon Bedrock のセキュリティとコンプライアンス
- AWS CloudTrail サービス概要
- Amazon Bedrock Data Automation と Guardrails による PII の検出と編集
問題文:
ある医療グループが、Amazon Bedrock のファウンデーションモデル(FM)を利用する生成 AI(GenAI)診療支援アプリケーションを構築しています。このアプリケーションは、認証に Microsoft Entra ID を使用する必要があります。すべての FM API 呼び出しはプライベートなネットワーク経路を通る必要があります。アプリケーションへのアクセスは、診療科ごとに特定のモデルファミリーに限定する必要があります。さらに、モデル相互作用の包括的な監査証跡も必要です。 これらの要件を満たすソリューションはどれですか。
選択肢:
A. Entra ID と IAM の間で OpenID Connect(OIDC)フェデレーションを設定します。属性ベースアクセスコントロール(ABAC)を使用して診療科属性を特定モデルへのアクセス権限にマッピングします。SCP ポリシーを適用して診療科ごとに Amazon Bedrock の FM ファミリーへのアクセスを制限します。Microsoft Entra ID の組み込みログ機能を使用してモデル相互作用の監査証跡を維持します。
B. IAM に SAML アイデンティティプロバイダー(IdP)を作成して Microsoft Entra ID で認証します。IAM のアクセス許可境界を使用して診療科ロールのアクセスを特定のモデルファミリーに限定します。VPC ルーティングを設定したパブリックな Amazon Bedrock API エンドポイントでプライベート接続性を維持します。CloudTrail と Amazon S3 のライフサイクルルールを組み合わせて、モデル相互作用の監査ログを管理します。
C. Microsoft Entra ID と AWS Identity and Access Management の間で SAML フェデレーションを設定します。必要な ModelId のみを許可する診療科固有の IAM ロールを作成します。Amazon Bedrock ランタイムサービス用の AWS PrivateLink インターフェイス VPC エンドポイントを作成します。AWS CloudTrail を有効にして Amazon Bedrock の API 呼び出しをキャプチャします。Amazon Bedrock のモデル呼び出しログを設定して、詳細なモデル相互作用を記録します。
D. IAM に IdP 接続を作成して Microsoft Entra ID で認証します。診療科ごとの権限セットで特定モデルファミリーへのアクセスを制御します。プライベートサブネットに AWS Lambda 関数をデプロイし、NAT ゲートウェイ経由で Amazon Bedrock のパブリックエンドポイントへ送信します。CloudWatch Logs を有効にしてモデル相互作用をキャプチャします。
正解:C
A. Entra ID と IAM の間で OpenID Connect(OIDC)フェデレーションを設定します。属性ベースアクセスコントロール(ABAC)を使用して診療科属性を特定モデルへのアクセス権限にマッピングします。SCP ポリシーを適用して診療科ごとに Amazon Bedrock の FM ファミリーへのアクセスを制限します。Microsoft Entra ID の組み込みログ機能を使用してモデル相互作用の監査証跡を維持します。
不正解 Entra ID 側のサインインログは AWS で実行される InvokeModel などの API 呼び出しを記録できないため、Bedrock の監査証跡として機能しません。AWS 側の操作監査には CloudTrail が必須となります。さらに本構成にはプライベートネットワーク経路の設計が含まれておらず、API 呼び出しがインターネット経由となる点でも要件を満たしません。
B. IAM に SAML アイデンティティプロバイダー(IdP)を作成して Microsoft Entra ID で認証します。IAM のアクセス許可境界を使用して診療科ロールのアクセスを特定のモデルファミリーに限定します。VPC ルーティングを設定したパブリックな Amazon Bedrock API エンドポイントでプライベート接続性を維持します。CloudTrail と Amazon S3 のライフサイクルルールを組み合わせて、モデル相互作用の監査ログを管理します。
不正解 パブリックな Bedrock API エンドポイントへの通信はインターネットゲートウェイを経由するため、ルートテーブルを工夫してもトラフィックは公衆網に出ます。プライベートネットワーク経路を成立させるには PrivateLink によるインターフェイス VPC エンドポイントが必須であり、本選択肢の構成ではこの要件を満たせません。
C. Microsoft Entra ID と AWS Identity and Access Management の間で SAML フェデレーションを設定します。必要な ModelId のみを許可する診療科固有の IAM ロールを作成します。Amazon Bedrock ランタイムサービス用の AWS PrivateLink インターフェイス VPC エンドポイントを作成します。AWS CloudTrail を有効にして Amazon Bedrock の API 呼び出しをキャプチャします。Amazon Bedrock のモデル呼び出しログを設定して、詳細なモデル相互作用を記録します。
正解 SAML 2.0 フェデレーションは Entra ID を企業 IdP として AWS に統合する標準的な方式で、IAM ロールのリソース条件に Bedrock モデル ARN を指定することで診療科ごとの細粒度制御が可能です。bedrock-runtime のインターフェイス VPC エンドポイントにより API 通信は AWS バックボーン内に閉じます。CloudTrail で API 呼び出しを、モデル呼び出しログでプロンプトと応答本文を記録できます。
D. IAM に IdP 接続を作成して Microsoft Entra ID で認証します。診療科ごとの権限セットで特定モデルファミリーへのアクセスを制御します。プライベートサブネットに AWS Lambda 関数をデプロイし、NAT ゲートウェイ経由で Amazon Bedrock のパブリックエンドポイントへ送信します。CloudWatch Logs を有効にしてモデル相互作用をキャプチャします。
不正解 NAT ゲートウェイは送信元 IP を変換してインターネットゲートウェイへ流すため、通信経路はプライベートではなくパブリックネットワークを経由することになり要件を満たせません。また CloudWatch Logs 単独では誰がいつどの API を呼び出したかという呼び出し主体や認証コンテキストを記録できず、包括的な監査証跡として不十分です。
全体的な説明
問われている要件
- Microsoft Entra ID を企業 IdP とする外部認証統合の実装方式
- Bedrock の API トラフィックが公衆インターネットを経由しないネットワーク設計
- 診療科ごとに利用可能な FM ファミリーを限定するアクセス制御方式
- API 呼び出しと実際のプロンプト・応答の双方を記録する監査基盤
前提知識 AWS と外部 IdP のフェデレーション統合について
- Microsoft Entra ID は SAML 2.0 アサーションを発行する企業向け IdP として広く採用されており、AWS とは IAM SAML プロバイダーまたは IAM Identity Center を通じて連携できます。
- IAM SAML フェデレーションでは、AssumeRoleWithSAML API を介して一時クレデンシャルが発行され、長期アクセスキーを排除した安全な認証が成立します。
- SAML アサーションに含まれる属性(部門名、グループ ID 等)を IAM ロールの信頼ポリシーで評価し、ロールマッピングや ABAC に活用できます。
Amazon Bedrock のプライベートネットワーク接続について
- Bedrock は AWS PrivateLink ベースのインターフェイス VPC エンドポイントをサポートしており、サービス名は制御プレーン用 com.amazonaws.region.bedrock とランタイム用 com.amazonaws.region.bedrock-runtime の2系統が存在します。
- Private DNS を有効にすると、デフォルトのリージョナル DNS 名(bedrock-runtime.region.amazonaws.com 等)が VPC 内では VPC エンドポイントの IP に解決され、アプリケーションコードを変更せずプライベート経路化できます。
- NAT ゲートウェイを介した送信通信はパブリックエンドポイント経由でインターネットを通るため、プライベート要件を満たさない構成になります。生成 AI でいうトークン(モデルが処理する文字や単語の最小単位、英文の1単語が約1〜3トークンに相当)のやり取りも公衆網に出ることになります。
Bedrock のきめ細かいアクセス制御について
- IAM ポリシーの Resource 要素に foundation-model ARN(例: arn:aws:bedrock:region::foundation-model/anthropic.claude-3-sonnet-…)を指定することで、ロールごとに呼び出せるモデルを限定できます。
- 診療科単位の制御では、診療科ごとの IAM ロールに必要な ModelId のみを許可するポリシーを付与する設計が直接的かつ管理しやすい方式です。
- VPC エンドポイントポリシーを併用すると、エンドポイント経由のアクセスにもネットワーク層で同等の制限を強制できます。
Bedrock の監査・ロギングについて
- CloudTrail は Bedrock のすべての API 呼び出し(InvokeModel、Converse 等を含む)を自動的にイベントとして記録し、いつ・誰が・どの IP から・どのリソースへ・どのアクションを実行したかという呼び出し主体の監査トレイルを残します。
- モデル呼び出しログ(Model Invocation Logging)は CloudTrail とは別の追加機能で、デフォルトでは無効です。有効化するとプロンプト本文、応答本文、トークン数、メタデータを CloudWatch Logs または S3 に出力できます。生成 AI における幻覚(ハルシネーション、モデルが事実に基づかない内容をもっともらしく生成する現象)の検証には、この応答本文ログが不可欠です。
- 完全な監査証跡には、CloudTrail(API 呼び出しの記録)とモデル呼び出しログ(プロンプト・応答内容の記録)の両方を組み合わせる構成が標準的です。
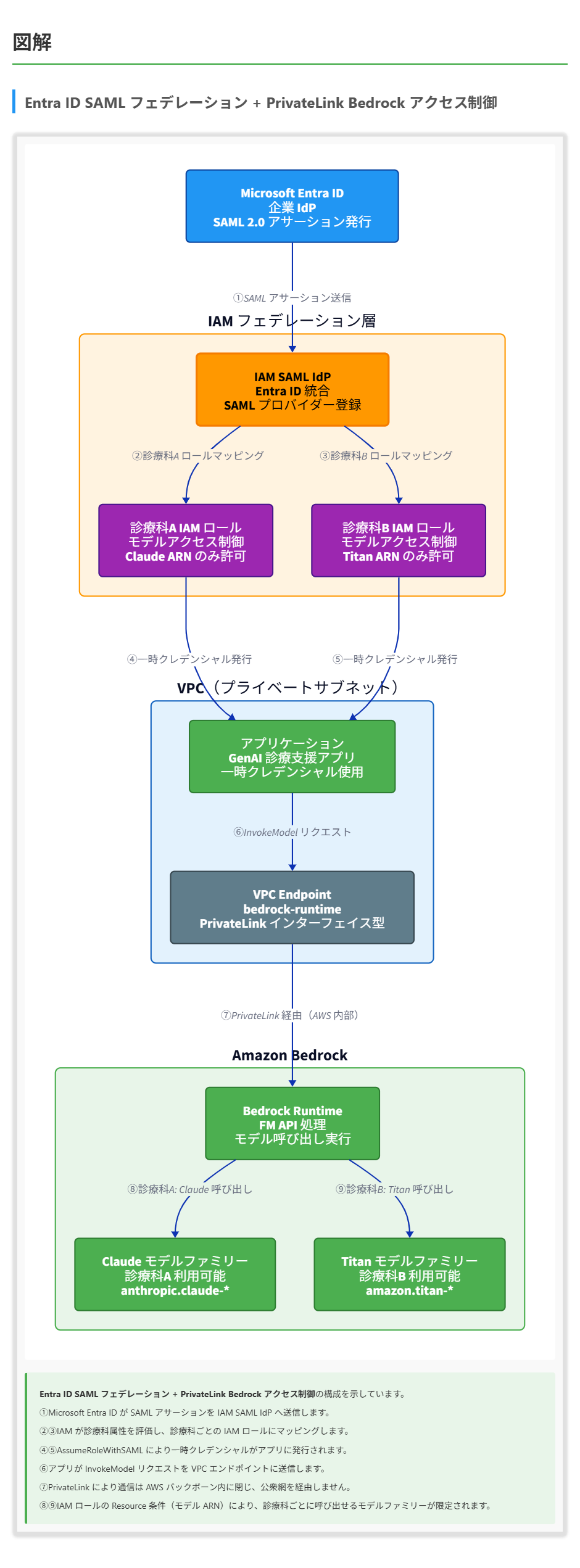
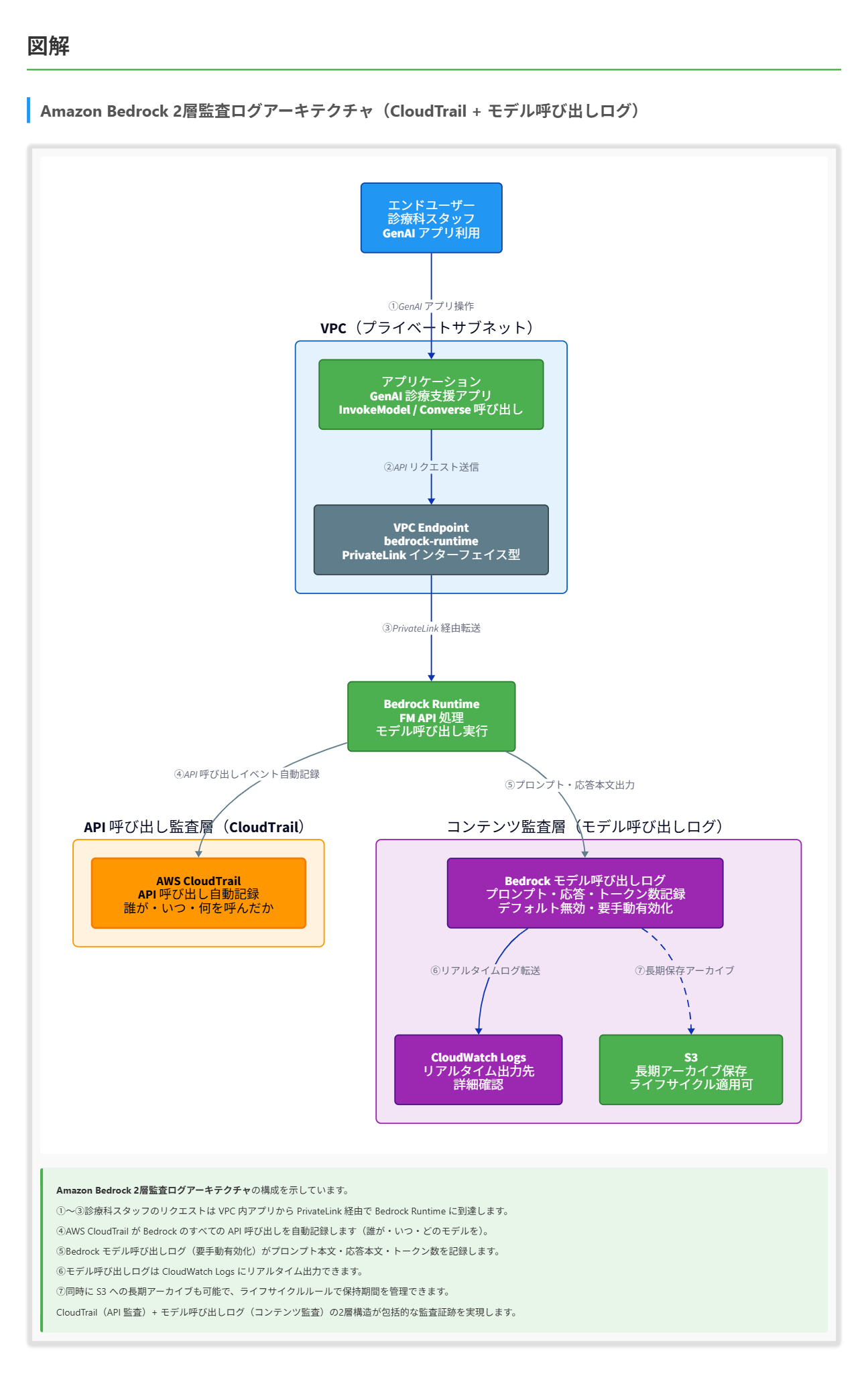
解くための考え方
問題文には4つの独立した要件が並んでおり、それぞれを満たすサービス・機能の組み合わせを順に検証していくことが解法の基本となります。 まず認証の要件では、Entra ID という外部 IdP との連携方式が問われています。Entra ID は SAML 2.0 を標準サポートしており、AWS 側では IAM の SAML IdP として登録するか IAM Identity Center で外部 IdP として設定する2通りの方式が一般的です。OIDC も技術的には選択肢に入りますが、Entra ID と AWS の統合における第一選択肢ではありません。 次にプライベートネットワーク要件は最も誤解されやすいポイントです。 「VPC 内に Lambda を置けばプライベート」と考えがちですが、Lambda が NAT ゲートウェイ経由でパブリックエンドポイントに到達する構成では、トラフィックは結局インターネットゲートウェイを通って公衆網に出ます。 Bedrock 通信を真にプライベート経路に閉じる唯一の方式は、PrivateLink を使ったインターフェイス VPC エンドポイント(特に bedrock-runtime エンドポイント)の作成であり、これがあるかないかが選択肢の正誤を分ける決定打になります。 診療科ごとのモデル制限については、IAM ポリシーの Resource 要素に Bedrock のモデル ARN を指定する方式が最も直接的です。 SCP は AWS Organizations のアカウント横断ガードレールであり、単一アカウント内の診療科単位制御には粒度がミスマッチします。 最後に監査証跡では、API 呼び出しの監査(誰がいつ何を呼んだか)を担う CloudTrail と、プロンプト・応答本文を記録するモデル呼び出しログの2層構造が「包括的」という要件に対応します。 CloudWatch Logs 単独や Entra ID 側のログだけでは、AWS 上の API 操作を体系的に追跡できないため要件を満たしません。 これら4つの観点で各選択肢を採点していくと、SAML 統合・モデル ARN ベースの IAM ロール・PrivateLink インターフェイスエンドポイント・CloudTrail とモデル呼び出しログを組み合わせた構成だけがすべての要件に対して整合的に応答していることが見えてきます。 参考資料
- Use interface VPC endpoints (AWS PrivateLink) to create a private connection between your VPC and Amazon Bedrock
- Protect your data using Amazon VPC and AWS PrivateLink – Amazon Bedrock
- Monitor Amazon Bedrock API calls using AWS CloudTrail
- Monitor model invocation using CloudWatch Logs and Amazon S3 – Amazon Bedrock
- Identity providers and federation – AWS Identity and Access Management
- Configure SAML and SCIM with Microsoft Entra ID and IAM Identity Center
- Use AWS PrivateLink to set up private access to Amazon Bedrock | AWS Machine Learning Blog
- Endpoints supported by Amazon Bedrock
- Monitoring Generative AI applications using Amazon Bedrock and Amazon CloudWatch integration | AWS Cloud Operations Blog
- Identity-based policy examples for Amazon Bedrock
問題文:
ある製薬企業が、社内向けの週次臨床文献レポートを自動生成する生成AIシステムを構築しています。開発チームは、最新の臨床論文や治験データを収集・検索する文献調査エージェント、その結果を要約する要約エージェント、最終的なレポートを成形するレポート作成エージェントの3つの専門エージェントで構成されるマルチエージェントシステムを設計しています。各エージェントの中間成果物を次のエージェントへ引き渡し、最終的に1つのレポートに集約する必要があります。チームは、エージェントの推論ループ・ツール呼び出し・エージェント間のコンテキスト引き渡しをゼロから自前実装することなく、AWSエコシステムのフレームワーク組み込み機能で賄いたいと考えています。カスタムオーケストレーションコードの量を最小化することが最優先事項です。これらの要件をすべて満たすソリューションはどれですか。
選択肢:
A. AWS Step FunctionsのParallelステートまたはMapステートを使って3つのAWS Lambda関数を呼び出し、それぞれがAmazon Bedrockのファンデーションモデルを利用して文献調査・要約・レポート作成を担当します。ステートマシンの入出力変換機能で各ステージの結果を次のLambdaへ受け渡し、最終ステップで成果物を統合します。エラー時はStep Functionsの組み込みリトライポリシーを適用し、処理の信頼性を確保します。
B. 文献調査・要約・レポート作成の各エージェントをAmazon ECSコンテナとして独立してデプロイします。Amazon SQSキューを介したメッセージングでエージェント間を疎結合に接続し、各コンテナが処理結果をキューへ送信して次のエージェントへ引き継ぎます。エージェント間のルーティング・コンテキスト管理・エラー処理のロジックは各コンテナ内に独自実装し、各エージェントの動作を細粒度で制御します。
C. 3つのAWS Lambda関数をAmazon SQSキューで直列に結線します。各LambdaはAmazon Bedrockを呼び出してそれぞれの専門タスクを実行し、処理結果をシリアライズして次のキューへ送信します。エージェントの状態管理・コンテキストの引き継ぎ・タイムアウト時のリトライロジックを各Lambda関数内に実装し、全体の処理フローを制御します。
D. Strands Agents SDKを採用し、文献調査・要約・レポート作成それぞれの専門エージェントを定義します。SDKが提供するWorkflowパターンで3エージェントをパイプライン状に結線し、前のエージェントの出力が自動的に次のエージェントのコンテキストとして引き渡されるよう構成します。各エージェントのバックエンドにはAmazon Bedrockのファンデーションモデルを設定し、SDKのツールエコシステム経由で外部データソースへアクセスします。
正解:D
A. AWS Step FunctionsのParallelステートまたはMapステートを使って3つのAWS Lambda関数を呼び出し、それぞれがAmazon Bedrockのファンデーションモデルを利用して文献調査・要約・レポート作成を担当します。ステートマシンの入出力変換機能で各ステージの結果を次のLambdaへ受け渡し、最終ステップで成果物を統合します。エラー時はStep Functionsの組み込みリトライポリシーを適用し、処理の信頼性を確保します。
不正解 AWS Step FunctionsはLLMエージェント専用のフレームワークではなく、サーバーレスワークフロー制御サービスです。モデルが主導するエージェントループ・自律的なツール選択・エージェント間のメモリ管理を組み込みで提供しておらず、これらの機能はすべてLambda内に別途実装する必要があります。カスタムコードの最小化という要件を満たせません。
B. 文献調査・要約・レポート作成の各エージェントをAmazon ECSコンテナとして独立してデプロイします。Amazon SQSキューを介したメッセージングでエージェント間を疎結合に接続し、各コンテナが処理結果をキューへ送信して次のエージェントへ引き継ぎます。エージェント間のルーティング・コンテキスト管理・エラー処理のロジックは各コンテナ内に独自実装し、各エージェントの動作を細粒度で制御します。
不正解 Amazon ECSとAmazon SQSによる疎結合構成は、エージェント動作の完全な制御が可能な反面、推論ループ・コンテキスト管理・エラーリカバリのロジックをすべてコンテナ内に独自実装する必要があります。制御の自由度が高い分だけカスタムコード量が増大するため、実装負荷の最小化という要件とはトレードオフの関係にあります。
C. 3つのAWS Lambda関数をAmazon SQSキューで直列に結線します。各LambdaはAmazon Bedrockを呼び出してそれぞれの専門タスクを実行し、処理結果をシリアライズして次のキューへ送信します。エージェントの状態管理・コンテキストの引き継ぎ・タイムアウト時のリトライロジックを各Lambda関数内に実装し、全体の処理フローを制御します。
不正解 AWS LambdaとAmazon SQSの組み合わせは、エージェントフレームワークを一切使用しない自前オーケストレーション構成です。推論ループ・ツール選択・エージェント間のコンテキスト管理・リトライをすべてチームがゼロから実装する必要があり、専用フレームワークが提供するエージェント協調機能は得られません。実装負荷が最も大きくなります。
D. Strands Agents SDKを採用し、文献調査・要約・レポート作成それぞれの専門エージェントを定義します。SDKが提供するWorkflowパターンで3エージェントをパイプライン状に結線し、前のエージェントの出力が自動的に次のエージェントのコンテキストとして引き渡されるよう構成します。各エージェントのバックエンドにはAmazon Bedrockのファンデーションモデルを設定し、SDKのツールエコシステム経由で外部データソースへアクセスします。
正解 Strands AgentsはAWSがApache 2.0ライセンスのもとでオープンソース公開したSDKで、モデルファーストアプローチで自律エージェントを構築するために設計されています。Swarm・Graph・Workflowという組み込みのマルチエージェント協調パターンを備え、エージェントループ・ツール呼び出し・コンテキスト引き渡しを自前実装せずに構成できます。Amazon BedrockのファンデーションモデルおよびAWSの各種サービスとシームレスに統合して動作します。
全体的な説明
問われている要件
- 文献調査・要約・レポート作成の3つの専門エージェントが協調して動作するマルチエージェント構成であること
- 各エージェントの中間成果物が次のエージェントへ自動的に引き渡されること
- エージェントの推論ループ・ツール呼び出しをフレームワーク組み込み機能で賄えること
- AWSエコシステムのサービス(Amazon Bedrockなど)と統合できること
- カスタムオーケストレーションコードの量を最小化できること
前提知識 マルチエージェントシステムについて
- マルチエージェントシステムとは、複数のAIエージェントがそれぞれ異なる役割を持ち、連携して1つの目標を達成する仕組みです。工場の生産ラインに例えると、各工程に担当者(エージェント)がいて、前工程の成果物を受け取り次工程へ渡すイメージです。
- エージェント間のコンテキスト引き渡しとは、前のエージェントが生成したテキストや構造化データを、次のエージェントが処理できる形式で受け渡すことを指します。フレームワークが自動管理しない場合は、シリアライズ・デシリアライズのロジックを開発者が自前実装する必要があります。
- 推論ループとは、エージェントがツールを呼び出してその結果を受け取り、さらに次のアクションを判断するサイクルです。このサイクルをフレームワークが内包しているかどうかが、実装コスト削減の鍵となります。
Strands Agents SDKについて
- Strands AgentsはAWSがApache 2.0ライセンスのもとでオープンソース公開したSDKで、モデルファーストアプローチで自律エージェントを構築するために設計されています。マネージドサービスではなくSDKであるため、デプロイ基盤(AWS LambdaやAmazon ECSなど)の選択は開発チームが行います。
- 組み込みのマルチエージェント協調パターンとして、Swarm(分散型)・Graph(有向グラフ型)・Workflow(逐次パイプライン型)の3種類を提供します。今回のユースケースのような逐次パイプライン(文献調査→要約→レポート作成)にはWorkflowパターンが適しています。
- Amazon BedrockのファンデーションモデルをバックエンドとしてAnthropicのClaude・Amazon Novaなど複数の選択肢から使用でき、AWS LambdaやAmazon ECSなどのAWSコンピューティングサービス上にそのままデプロイできる設計になっています。
- ツールエコシステムを通じて外部APIやデータソースへのアクセスを提供しており、どのツールをいつ呼び出すかの判断もフレームワーク内部で処理されます。
AWS Step Functionsのエージェント用途における特性について
- AWS Step Functionsはサーバーレスワークフローオーケストレーションサービスであり、ステート間の遷移・並列実行・エラーハンドリングを宣言的に定義できます。ただし、LLMが主導するエージェントループ(ツール選択→実行→結果評価→次のアクション決定)を組み込みで提供していません。
- Step FunctionsでAIエージェントを構築する場合、各ステートに対応するLambda関数の内部に推論ループ・ツール選択ロジック・エージェント間のコンテキスト管理を個別実装する必要があります。これはカスタムオーケストレーションコードの最小化という要件と相反します。
エージェントオーケストレーションのアーキテクチャパターンについて
- Amazon ECSコンテナやAWS Lambda関数として各エージェントを独立デプロイし、Amazon SQSでメッセージングする構成は、エージェントの動作を細粒度で制御できる反面、ルーティング・コンテキスト管理・エラー処理のロジックをすべてコンテナまたは関数内に独自実装する必要があります。制御の自由度が高い分だけカスタムコード量が最大になるため、実装負荷の最小化という要件とはトレードオフの関係にあります。
- エージェントフレームワークを採用する目的は、エージェントオーケストレーション・ツール統合・メモリ管理・ワークフロー定義といった複雑な処理をフレームワーク側に委ねることで、開発チームが本来のビジネスロジックだけに集中できるようにする点にあります。フレームワークを使わない場合はこれらをすべてゼロから実装することになり、コードの量と保守コストの両方が増大します。
- Amazon Bedrock Multi-Agent Collaborationはスーパーバイザー/コラボレーター階層モデルによるマネージドなマルチエージェント機能であり、Strands Agents SDKとは別の仕組みです。Strands AgentsはSDKとして独自のデプロイ基盤上で動作します。
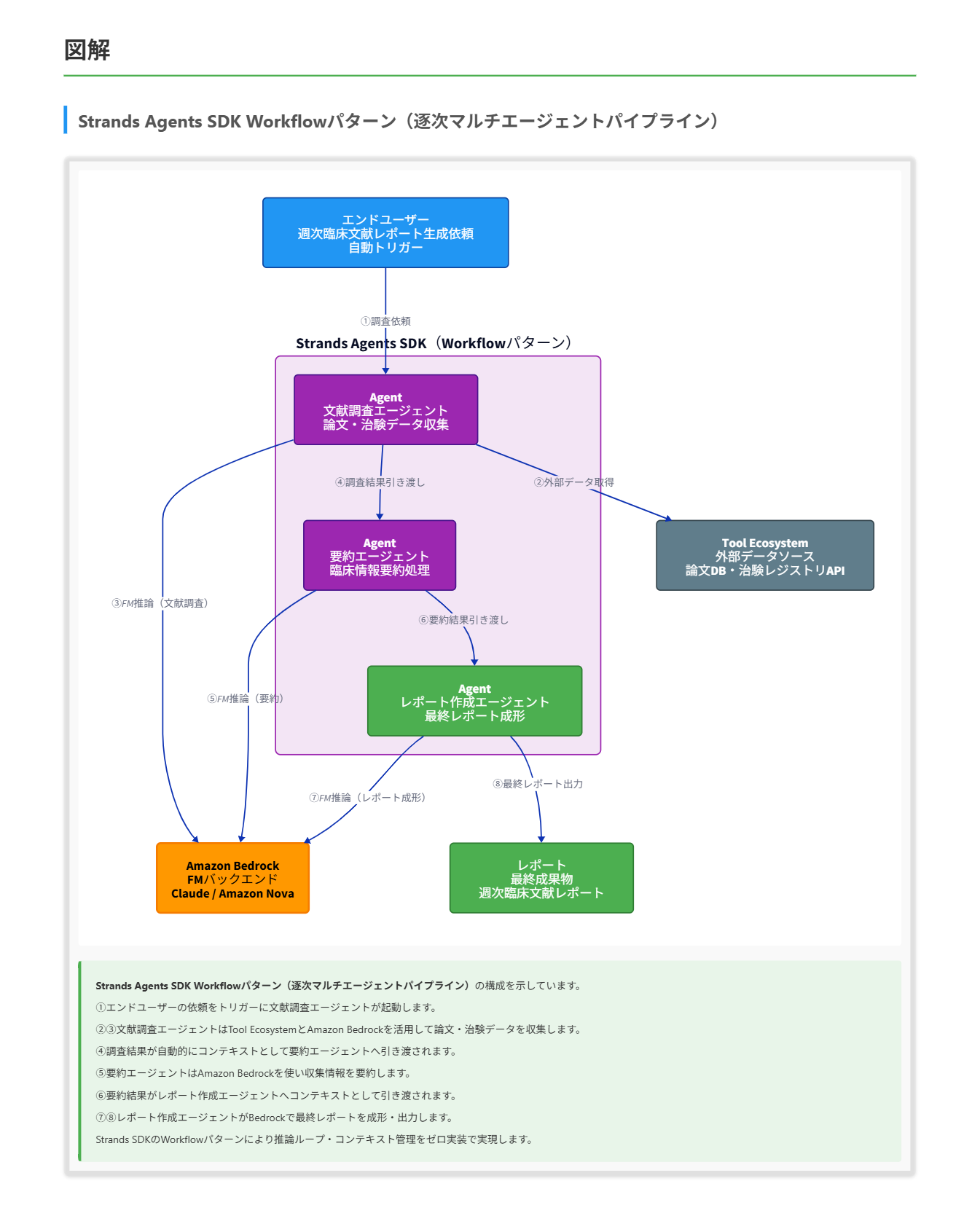
解くための考え方
この問題を解くには、まず問題文の核心となる要件を正確に読み取ることが重要です。要件の本質は「推論ループ・ツール呼び出し・エージェント間コンテキスト引き渡しをゼロから自前実装しない」かつ「カスタムオーケストレーションコードの量を最小化する」という2点です。 各選択肢をこの基準で評価します。まずStep Functions+Lambda構成はワークフロー制御を宣言的に記述できますが、LLMエージェントループそのものはLambda内に実装する必要があります。Step FunctionsはLLMエージェント専用フレームワークではなく、モデル主導のツール選択やエージェント間メモリ管理を提供しないため、要件を満たしません。 次にECSコンテナ+SQSキューによる疎結合構成は、エージェントの独立性と制御の自由度を最大化できますが、その分だけルーティング・コンテキスト管理・エラー処理をすべてコンテナ内に独自実装する必要があります。Lambda+SQS直列構成も同様に、推論ループからリトライロジックまでをゼロから実装する純粋な自前オーケストレーションであり、フレームワークの恩恵を一切受けられません。 Strands Agents SDKを採用した構成だけが、Swarm・Graph・Workflowという組み込みの協調パターンによってエージェント間の連携を最小限のコードで実現できます。エージェントループ・ツール選択・コンテキスト引き渡しをSDK内部で処理するため、開発チームはビジネスロジック(何を調査し・どう要約し・どんなレポートを生成するか)の実装に専念できます。 なお、Strands AgentsはSDKであってマネージドサービスではないため、実際のデプロイ基盤(Lambda、ECS等)は別途選択する必要がありますが、この点は本問の評価軸には含まれていません。 参考資料
- Strands Agents — AWS Prescriptive Guidance(エージェントAIフレームワーク)
- Frameworks(エージェントAIフレームワーク一覧)— AWS Prescriptive Guidance
- Introducing Strands Agents, an Open Source AI Agents SDK — AWS Open Source Blog
- Guidance for Multi-Agent Orchestration on AWS
- Amazon Bedrock Agentsでのマルチエージェントコラボレーション — Amazon Bedrock ユーザーガイド
- Parallelワークフローステート — AWS Step Functions 開発者ガイド
- Amazon Bedrockのエージェントとは — Amazon Bedrock ユーザーガイド
- AWS Step Functionsとは — AWS Step Functions 開発者ガイド
問題文:
ある物流会社が、Strands Agents SDK を用いて配送業務自動化エージェントを構築しています。このエージェントは、外部の REST API を呼び出して配送追跡データを取得するツールと、Amazon DynamoDB に荷主情報を書き込むツールという、2 種類のカスタムツールを持っています。両ツールは将来的に独立してスケールできるよう、エージェントのオーケストレーションループとは別の実行環境で動作させる計画です。また、受け取ったリクエストのパラメータが不正な場合は、後続の処理を一切実行せず、呼び出し元のエージェントに明確なエラー情報を返す必要があります。開発チームは、最もシンプルで公式に推奨される設計に沿って実装したいと考えています。これらの要件を満たすソリューションはどれですか。
選択肢:
A. Amazon Bedrock Agents のアクショングループとして各ツールを定義します。OpenAPI スキーマにより REST API の呼び出しパラメータを記述し、DynamoDB への書き込みは Lambda 関数にバインドします。パラメータの検証は Amazon Bedrock Agents のオーケストレーションの前処理ステップで行い、不正な入力があった場合はエージェントにエラーレスポンスを返すよう設定します。エージェントとツールの実行環境は Bedrock のマネージド基盤によって自動的に分離されます。
B. AWS Step Functions のステートマシンを中心に据え、REST API 呼び出しタスクと DynamoDB 書き込みタスクを個別のステートとして定義します。各ステートの入力に JSONPath による条件分岐を設定し、パラメータが不正な場合は Fail ステートに遷移させてエラー情報を返します。Strands Agents SDK はユーザーとの会話インターフェースのみに使用し、ツール実行の制御はすべて Step Functions に委ねます。
C. REST API 呼び出しと DynamoDB 書き込みのそれぞれについて、Python 関数に @tool デコレータを付与してカスタムツールとして定義します。各ツール関数の先頭でリクエストパラメータを検証し、不正な値が含まれていた場合は例外またはエラー情報を返して後続処理を実行しないようにします。ツールの実行環境はエージェントのオーケストレーションループとは分離した AWS Lambda 上に配置し、エージェントはツールへの呼び出しを API 経由で行うアーキテクチャを採用します。
D. 各ツールの入力パラメータを JSON Schema ファイルとして個別に記述し、Strands Agents SDK のツール定義設定に読み込ませます。JSON Schema のバリデーション仕様に従って不正なパラメータを自動的に拒否する設定を SDK レベルで有効化し、エラー時は SDK のフレームワークが自動的に呼び出し元にエラーを返却するよう構成します。ツールの実行は Lambda で行い、JSON Schema の定義ファイルのみを管理することでコード量を最小化します。
正解:C
A. Amazon Bedrock Agents のアクショングループとして各ツールを定義します。OpenAPI スキーマにより REST API の呼び出しパラメータを記述し、DynamoDB への書き込みは Lambda 関数にバインドします。パラメータの検証は Amazon Bedrock Agents のオーケストレーションの前処理ステップで行い、不正な入力があった場合はエージェントにエラーレスポンスを返すよう設定します。エージェントとツールの実行環境は Bedrock のマネージド基盤によって自動的に分離されます。
不正解 Amazon Bedrock Agents は、アクショングループ・OpenAPI スキーマ・Lambda を組み合わせた Amazon Bedrock 固有のマネージドエージェントサービスです。Strands Agents SDK はオープンソースの Python フレームワークであり、Bedrock Agents が提供する前処理ステップ・オーケストレーションステップ・後処理ステップといったマネージド機構とは製品レイヤーが根本的に異なります。Strands SDK でエージェントを構築しているにもかかわらず、Bedrock Agents のアクショングループを主体に据えることは、フレームワークの設計目的に反します。
B. AWS Step Functions のステートマシンを中心に据え、REST API 呼び出しタスクと DynamoDB 書き込みタスクを個別のステートとして定義します。各ステートの入力に JSONPath による条件分岐を設定し、パラメータが不正な場合は Fail ステートに遷移させてエラー情報を返します。Strands Agents SDK はユーザーとの会話インターフェースのみに使用し、ツール実行の制御はすべて Step Functions に委ねます。
不正解 AWS Step Functions は分散アプリケーションのワークフローをオーケストレーションするサービスであり、Strands エージェントを上位ビジネスワークフローの一ステップとして組み込む用途には適しています。しかし、モデルが自律的にツールを選択・実行するという Strands Agents SDK のモデル駆動型エージェントループを、Step Functions のステートマシンで置き換えることはできません。Step Functions は事前に定義されたステート遷移ロジックに基づいて動作するため、LLM の推論結果によって動的にツール呼び出しを決定する Strands のループ構造と設計目的が根本的に異なります。
C. REST API 呼び出しと DynamoDB 書き込みのそれぞれについて、Python 関数に @tool デコレータを付与してカスタムツールとして定義します。各ツール関数の先頭でリクエストパラメータを検証し、不正な値が含まれていた場合は例外またはエラー情報を返して後続処理を実行しないようにします。ツールの実行環境はエージェントのオーケストレーションループとは分離した AWS Lambda 上に配置し、エージェントはツールへの呼び出しを API 経由で行うアーキテクチャを採用します。
正解 Strands Agents SDK では、Python 関数に @tool デコレータを付与することがカスタムツールを定義する中核パターンです。ツール実行をエージェントのオーケストレーションループとは別の実行環境(Lambda・EC2・Fargate など)に分離するアーキテクチャは、セキュリティと信頼性を高める方法として明示されています。パラメータ検証とエラー返却はツール関数の実装側の責務であり、SDK がフレームワーク機能として自動検証を提供する専用設定は存在しません。ツール関数の先頭で検証ロジックを実行し、不正な場合は例外を送出することで、後続処理を一切行わずに呼び出し元のエージェントにエラー情報を返せます。
D. 各ツールの入力パラメータを JSON Schema ファイルとして個別に記述し、Strands Agents SDK のツール定義設定に読み込ませます。JSON Schema のバリデーション仕様に従って不正なパラメータを自動的に拒否する設定を SDK レベルで有効化し、エラー時は SDK のフレームワークが自動的に呼び出し元にエラーを返却するよう構成します。ツールの実行は Lambda で行い、JSON Schema の定義ファイルのみを管理することでコード量を最小化します。
不正解 Strands Agents SDK のカスタムツール定義の主要パターンは、@tool デコレータを付与した Python 関数による実装です。JSON Schema ファイルのみでツールを定義する方式は、Strands SDK が公式に推奨する開発者向けの主要パターンではありません。また、SDK がフレームワーク機能としてパラメータ検証を自動実行する専用の設定ポイントを提供しているという事実はなく、検証ロジックはツール実装関数の内部に組み込む責務です。なお、Amazon Bedrock Agents 側では OpenAPI スキーマや関数詳細スキーマを使ってアクション定義を行う仕組みが存在しますが、これは Strands Agents SDK とは別製品の構成要素です。
全体的な説明
問われている要件
- Strands Agents SDK において最もシンプルかつ公式に推奨されるカスタムツール定義パターンを選択できるか。
- エージェントのオーケストレーションループとツールの実行環境を分離するための正しいアーキテクチャを理解しているか。
- パラメータ検証とエラー返却の責務がどこ(SDK か、ツール実装か)にあるかを正しく把握しているか。
- Amazon Bedrock Agents(マネージドサービス)と Strands Agents SDK(OSS フレームワーク)が製品レイヤーとして異なることを区別できるか。
- AWS Step Functions の適切な用途(上位ワークフローへの組み込み)と、エージェントループの代替として使えないことを理解しているか。
前提知識 Strands Agents SDK のアーキテクチャについて
- Strands Agents SDK は AWS がリリースしたオープンソースの Python フレームワークで、モデル駆動型のエージェントループを中核としています。エージェントは「モデル・ツール・プロンプト」の 3 要素で構成されます。
- カスタムツールの定義には、Python 関数に @tool デコレータを付与する方法が主要パターンです。デコレータを付与するだけで、関数のシグネチャと docstring から自動的にツールの説明が生成され、エージェントのモデルがそのツールを選択・呼び出せるようになります。
- エージェントループは、モデルがプロンプトとツール一覧を受け取り、自律的にツールを選択・実行して結果をモデルに戻すというサイクルを繰り返します。このループは Step Functions などのワークフローエンジンとは構造が異なり、モデルの推論が各ステップの制御を担います。
- ツール実行環境をエージェントのオーケストレーションループとは別の実行環境(Lambda・EC2・Fargate など)に分離することは、セキュリティと信頼性を高める方法として明示されています。
パラメータ検証とエラーハンドリングの実装について
- Strands Agents SDK には、ツールへの入力パラメータをフレームワーク側で自動検証する専用の設定ポイントは存在しません。検証ロジックはツール関数の実装の中に組み込むのが開発者の責務です。
- ツール関数の先頭でパラメータを検証し、不正な場合に例外を送出またはエラー情報を返すことで、後続処理を実行せずに呼び出し元のエージェントへエラーを伝えることができます。エンタープライズ向けの実装では、入力のサニタイズ・カスタム検証・堅牢な例外処理をアプリケーション層の実践として行うことが推奨されています。
Amazon Bedrock Agents(マネージドエージェントサービス)との違いについて
- Amazon Bedrock Agents は、Amazon Bedrock プラットフォーム上で提供されるマネージドエージェントサービスです。アクショングループ・OpenAPI スキーマ・Lambda 関数を組み合わせてエージェントを構成し、前処理・オーケストレーション・後処理という 3 段階のマネージドなエージェントシーケンスで動作します。
- Strands Agents SDK は OSS の Python フレームワークであり、Bedrock Agents のオーケストレーション基盤とは製品レイヤーが異なります。Strands を使用するエージェントでは、Bedrock Agents のアクショングループは使用しません。
- ただし、Strands エージェントが Amazon Bedrock 上のモデルを使用することは可能であり、「Bedrockのモデルを使うこと」と「Bedrock Agentsのサービスを使うこと」は別の概念として区別する必要があります。
AWS Step Functions の適切な用途について
- AWS Step Functions は、分散アプリケーションのビジネスワークフローを視覚的・宣言的に定義・実行するサービスです。ステートマシンにより複数のタスクを順次・並列・条件分岐させて制御できます。
- Strands エージェント全体を Step Functions のワークフローの一ステップとして組み込むこと(例:「エージェントを呼び出すステート」を定義する)は適切なユースケースです。しかし、Step Functions のステートマシンが Strands SDK のモデル駆動型エージェントループそのものを代替することはできません。
AWS Lambda でのツール実行環境分離について
- Lambda は、コードをサーバーレスで実行できるコンピューティングサービスです。スケーリングが自動化されており、エージェントのオーケストレーションループとツールの実行環境を分離するのに適しています。
- Strands ツールを Lambda 上に配置することで、エージェントのオーケストレーションロジックとツール実装を独立してスケール・デプロイできます。Lambda の実行時間制限(デフォルト 3 秒、最大 15 分)やコールドスタートの影響を考慮し、適切なタイムアウト設定と再試行ロジックをエージェント側に設けることができます。
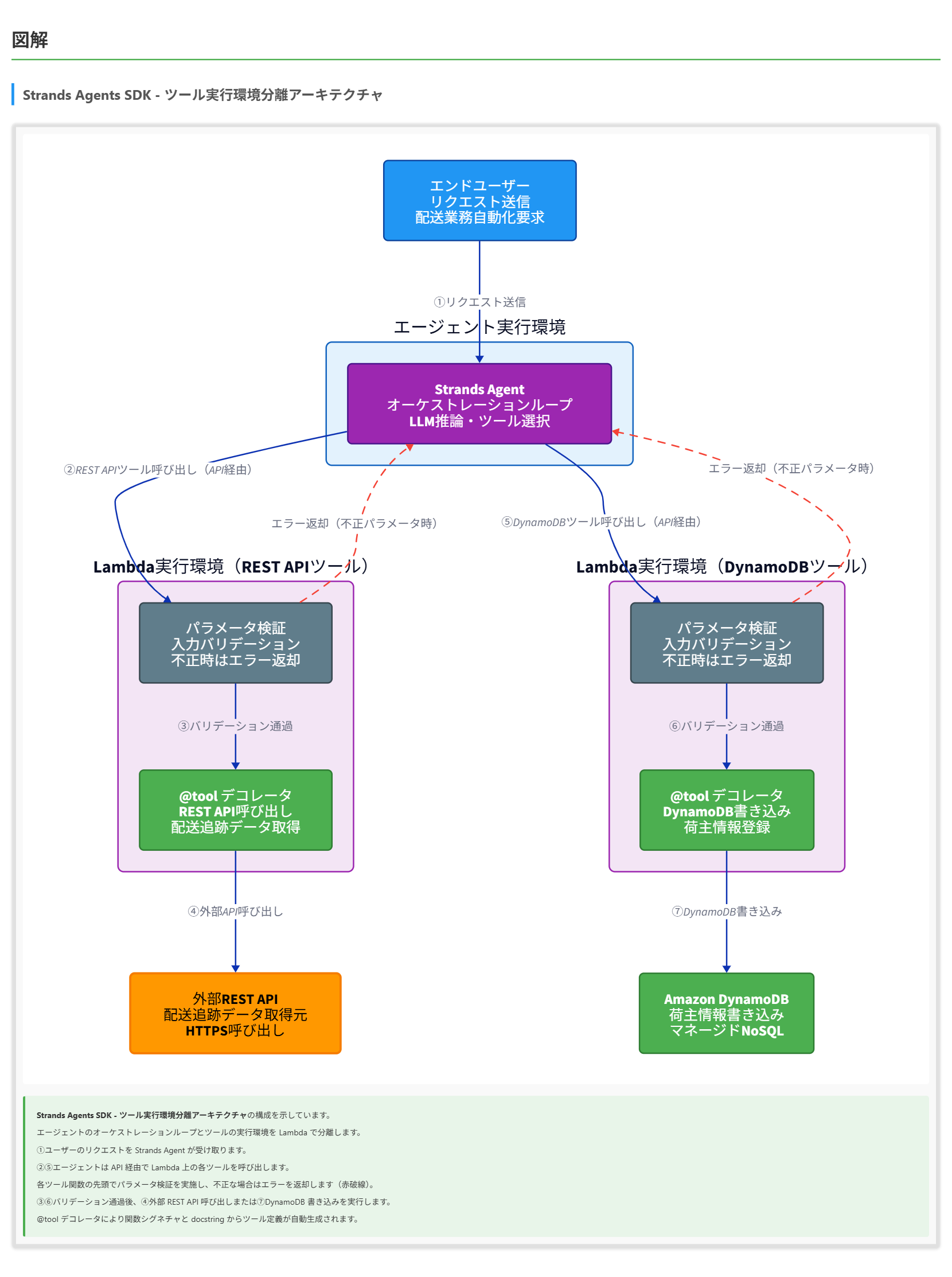
解くための考え方
この問題の核心は、「Strands Agents SDK という特定のフレームワークを使う前提で、最もシンプルかつ公式に推奨される設計を選べるか」という判断力を問う点にあります。 まず問題文の要件を整理します。要件は大きく3つです。①カスタムツール定義の方法(REST API 呼び出しと DynamoDB 書き込みのツール化)、②ツールの実行環境をエージェントのオーケストレーションループから分離すること、③不正なパラメータを受け取った場合に後続処理を実行せずエラーを返すことです。 最初の絞り込みポイントは「製品の選択が適切か」です。問題文は Strands Agents SDK を使うと明示しています。Strands SDK はオープンソースの Python フレームワークであり、Amazon Bedrock Agents はまったく別のサービスです。Strands でエージェントを構築しているにもかかわらず、Bedrock Agents のアクショングループを主体にする設計は、フレームワークの用途に合致しません。この時点で、Bedrock Agents を中心とした選択肢を除外できます。 次の絞り込みポイントは「Step Functions はエージェントループの代替として使えるか」です。Step Functions は事前定義されたステート遷移で動作するワークフローエンジンです。Strands のモデル駆動型エージェントループは、LLM が推論しながら動的にツールを選択・実行するため、事前定義ステートとは設計思想が根本的に異なります。Step Functions に会話インターフェース以外の制御を委ねることは、Strands SDK のモデル駆動型の仕組みを無効化してしまいます。 残る選択肢の判断では「SDK によるパラメータ自動検証の設定が存在するか」が論点になります。Strands Agents SDK には、フレームワークレベルでパラメータ検証を自動実行する専用の設定ポイントは存在しません。JSON Schema ファイルだけを管理してSDK側が自動検証するという設計はStrands SDKの実際の仕様に存在しないため、そのような設計を前提にした選択肢は誤りです。 正解の設計では、@tool デコレータを付与した Python 関数がカスタムツール定義の主要パターンであること、ツール関数内部でパラメータ検証と例外処理を実装することが開発者の責務であること、そしてツールを Lambda 上に配置してオーケストレーションループと実行環境を分離するアーキテクチャが公式に示されていることが、それぞれ対応します。これら3つの要件がすべて正しく設計されている選択肢が正解です。 参考資料
- Introducing Strands Agents, an Open Source AI Agents SDK(AWS Open Source Blog)
- Strands Agents SDK: A technical deep dive into agent architectures and observability(AWS 機械学習ブログ)
- Strands Agents(AWS Prescriptive Guidance)
- How Amazon Bedrock Agents works(Amazon Bedrock ユーザーガイド)
- What is Step Functions?(AWS Step Functions ドキュメント)
- AWS Lambda(製品概要)
- Amazon DynamoDB(製品概要)
- Strands Agents ツール概要(Strands 公式ドキュメント)
問題文:
ある物流企業が、荷主向けの問い合わせ対応AIエージェントを本番環境で運用しています。エージェントは複数のバックエンドツールを呼び出してユーザーの依頼を処理しており、今後の改善サイクルを回すために品質の定量評価を継続的に実施したいと考えています。必要なのは、エージェントがユーザーの依頼をエンドツーエンドで達成できているかどうか(ゴール達成率)と、各ステップで適切なツールを選択できているかどうか(ツール選択の妥当性)を、本番トラフィックに対してリアルタイムにスコア化する仕組みです。呼び出し回数やレイテンシといった運用指標はすでに別途監視されており、今回の目的はそれらでは測れないセマンティックな品質の継続的把握に絞られます。開発チームは追加のML基盤を自前で構築・維持する余力がなく、フルマネージドな形で評価パイプラインを稼働させたいと考えています。これらの要件をすべて満たすソリューションはどれですか。
選択肢:
A. Amazon SageMaker Clarifyを中心とした評価基盤を構築します。エージェントのセッションログをAmazon S3に集約し、Clarifyの説明可能性分析ジョブを定期的に起動してツール選択の傾向を特徴量帰属として可視化します。ゴール達成の判定はAmazon SageMaker Experimentsでカスタム指標として記録し、Amazon QuickSightのダッシュボードから確認できる体制を整えます。
B. Amazon BedrockのCreateEvaluationJob APIを活用した評価ジョブを定期実行します。applicationTypeをモデル評価として設定し、自動評価設定のmodel-as-judgeによってエージェントのセッションログをスコア化します。ジョブはAmazon EventBridgeスケジューラで一定間隔に起動し、結果をAmazon S3に保存してAmazon Athenaでクエリできる体制を整えます。ゴール達成率とツール選択精度はカスタムメトリクスとして評価プロンプトに定義します。
C. Amazon Bedrock Agentsが発行するAmazon CloudWatchのランタイムメトリクスを中心に評価ダッシュボードを構築します。InvocationCount・TotalTime・InputTokenCount・ClientErrorsなどの主要指標をAmazon CloudWatchダッシュボードに集約し、呼び出し成功率やエラー率からエージェントの健全性をトラッキングします。しきい値超過時はAmazon SNSで通知を発報し、問題の兆候を早期に把握できる体制を整えます。
D. Amazon Bedrock AgentCore Evaluationsのオンライン評価を設定します。本番のライブトラフィックに対してエージェントのトレースをサンプリングし、組み込み評価子を指定することでゴール達成率とツール選択精度を継続的にスコア化します。評価結果はAmazon CloudWatchのダッシュボードに自動集約され、スコアの低下をアラートで検知できる体制を整えます。
正解:D
A. Amazon SageMaker Clarifyを中心とした評価基盤を構築します。エージェントのセッションログをAmazon S3に集約し、Clarifyの説明可能性分析ジョブを定期的に起動してツール選択の傾向を特徴量帰属として可視化します。ゴール達成の判定はAmazon SageMaker Experimentsでカスタム指標として記録し、Amazon QuickSightのダッシュボードから確認できる体制を整えます。
不正解 Amazon SageMaker ClarifyはSHAPアルゴリズムによる特徴量帰属やバイアス検出など、機械学習モデルの予測に対する説明可能性の分析を主目的とするサービスです。会話エージェントがマルチステップのタスクを達成できたかどうかのセマンティックな評価や、文脈に照らしたツール選択の妥当性を定量スコアとして算出する機能は設計に含まれておらず、本問の評価要件を満たすことができません。
B. Amazon BedrockのCreateEvaluationJob APIを活用した評価ジョブを定期実行します。applicationTypeをモデル評価として設定し、自動評価設定のmodel-as-judgeによってエージェントのセッションログをスコア化します。ジョブはAmazon EventBridgeスケジューラで一定間隔に起動し、結果をAmazon S3に保存してAmazon Athenaでクエリできる体制を整えます。ゴール達成率とツール選択精度はカスタムメトリクスとして評価プロンプトに定義します。
不正解 `CreateEvaluationJob` APIの`applicationType`は`ModelEvaluation`(モデル評価)と`RagEvaluation`(ナレッジベース評価)の2値のみに限定されており、エージェントのエンドツーエンドトレースを評価対象とする種別は存在しません。同APIはプロンプトデータセット上の応答品質を測定する枠組みであるため、マルチステップのツール呼び出し履歴をセマンティックにスコア化する要件を満たせません。EventBridgeによるバッチ実行では本番トラフィックへのリアルタイム評価も実現できません。
C. Amazon Bedrock Agentsが発行するAmazon CloudWatchのランタイムメトリクスを中心に評価ダッシュボードを構築します。InvocationCount・TotalTime・InputTokenCount・ClientErrorsなどの主要指標をAmazon CloudWatchダッシュボードに集約し、呼び出し成功率やエラー率からエージェントの健全性をトラッキングします。しきい値超過時はAmazon SNSで通知を発報し、問題の兆候を早期に把握できる体制を整えます。
不正解 Amazon Bedrock AgentsがAWS/Bedrock/Agents名前空間で発行するCloudWatchメトリクスは、呼び出し数・処理時間・トークン数・エラー率といったランタイム運用指標に限定されています。これらはシステムの稼働状況を把握するための可観測性指標であり、エージェントがユーザーのゴールを達成できたかどうか、また文脈に照らして適切なツールを選択したかどうかといったセマンティックな品質の定量評価は、これらのメトリクスには含まれていません。
D. Amazon Bedrock AgentCore Evaluationsのオンライン評価を設定します。本番のライブトラフィックに対してエージェントのトレースをサンプリングし、組み込み評価子を指定することでゴール達成率とツール選択精度を継続的にスコア化します。評価結果はAmazon CloudWatchのダッシュボードに自動集約され、スコアの低下をアラートで検知できる体制を整えます。
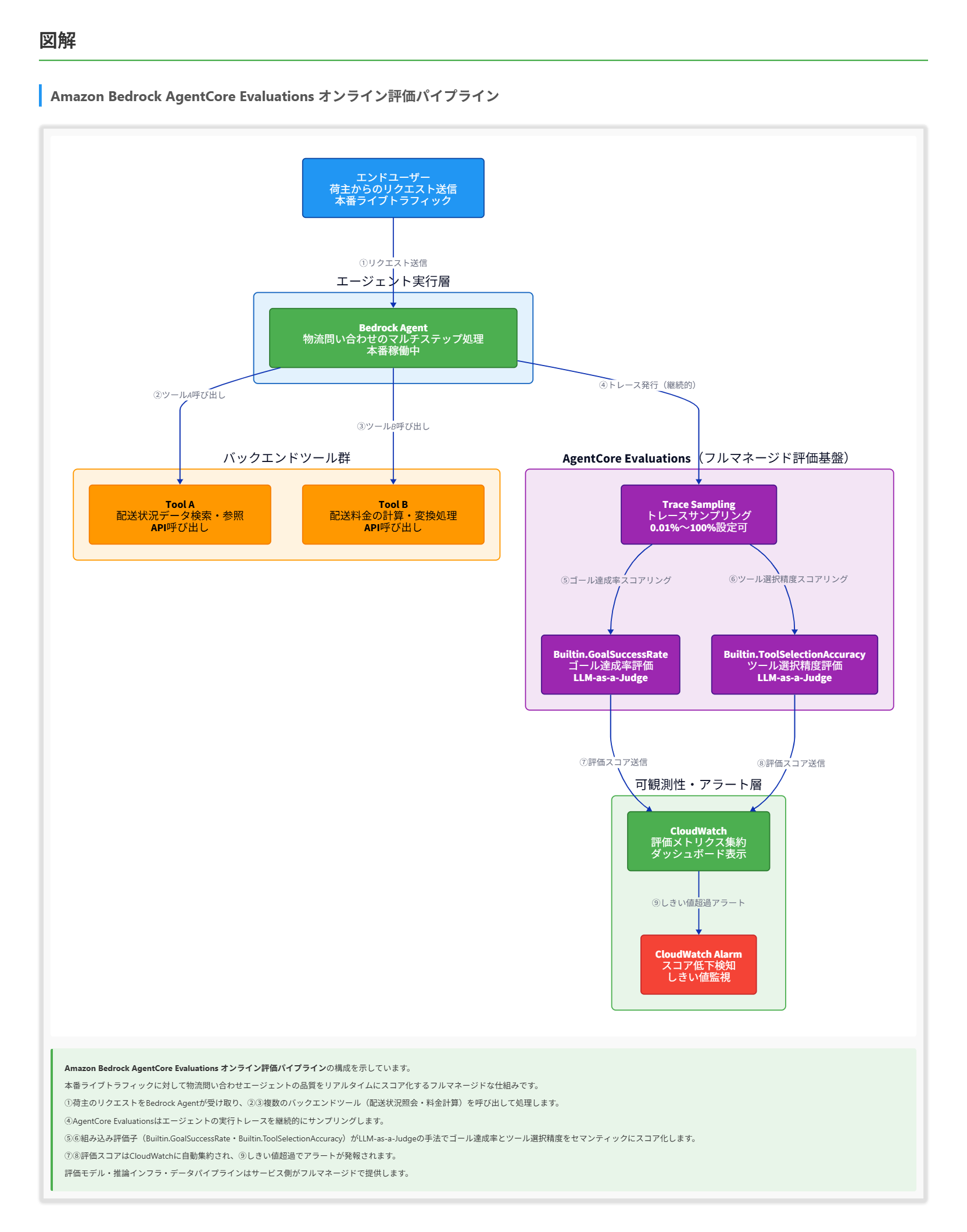
正解 Amazon Bedrock AgentCore Evaluationsはエージェントの品質評価に特化したフルマネージドサービスです。オンライン評価機能により本番のライブトラフィックからトレースを継続的にサンプリング・スコア化でき、組み込み評価子`Builtin.GoalSuccessRate`(ゴール達成率)と`Builtin.ToolSelectionAccuracy`(ツール選択精度)でセマンティックな品質を定量化します。評価基盤はサービスがフルマネージドで提供するため独自ML基盤の構築は不要で、結果はAgentCore ObservabilityおよびAmazon CloudWatchと統合されます。
全体的な説明
問われている要件
- 本番ライブトラフィックに対するリアルタイムかつ継続的な評価(バッチ処理による事後評価ではないこと)
- ゴール達成率:エージェントがユーザーの依頼をエンドツーエンドで達成できているかどうかの定量測定
- ツール選択の妥当性:各ステップで文脈に合った適切なツールが呼び出されているかのセマンティックな評価
- 呼び出し回数・レイテンシ等の運用指標では代替できないセマンティック品質の継続的定量把握
- フルマネージドな評価基盤(追加のML基盤を自前で構築・維持する必要がないこと)
前提知識
Amazon Bedrock AgentCore Evaluationsについて
- AIエージェントのパフォーマンス評価に特化したフルマネージドサービスで、2026年3月31日に一般提供(GA)となりました。評価モデルの管理・推論基盤・データパイプラインはすべてサービス側が担うため、利用者が独自のML基盤を構築する必要はありません。
- 評価の核となるのは「評価子(Evaluator)」と呼ばれるコンポーネントです。評価子はエージェントのトレース(実行過程の記録)を入力として受け取り、LLM-as-a-Judgeの手法でセマンティックなスコアを算出します。トレースとは、エージェントがどのツールをどの順序で呼び出し、最終的にどのような回答を返したかを記録した一連のデータです。LLM-as-a-Judgeとは、採点する側も大規模言語モデルであるという評価手法で、人間が採点するような「文脈を考慮した意味的な正しさ」をモデルに判定させる方式です。
- 組み込み評価子(Built-in Evaluator)として13種類が提供されており、ゴール達成率を測るBuiltin.GoalSuccessRateとツール選択精度を測るBuiltin.ToolSelectionAccuracyはその中に含まれます。いずれも追加の設定なしで即座に利用できます。
- 評価結果はAgentCore ObservabilityおよびAmazon CloudWatchと統合されており、メトリクスの一元監視・アラート設定が可能です。
オンライン評価とオンデマンド評価の違いについて
- Amazon Bedrock AgentCore Evaluationsはオンライン評価とオンデマンド評価の2種類の評価モードを提供しています。
- オンライン評価は稼働中のエージェントのライブトラフィックを継続的に監視するモードです。評価対象とするセッションのサンプリング割合(0.01%〜100%)を設定すると、指定した評価子が自動的にトレースをスコア化し続けます。本番環境での継続的な品質監視に適しており、本問の要件と直接対応します。
- オンデマンド評価は特定のセッションIDやトレースIDを指定して任意のタイミングで実行するモードです。CI/CDパイプラインへの組み込みや、変更前後の性能比較(回帰テスト)に活用できます。
- 両モードは同じ評価子・スコアリング基盤を共有しているため、CI/CDでテストした品質基準をそのまま本番監視に引き継ぐことができます。
Amazon Bedrockモデル評価(**`**CreateEvaluationJob**`**)との違いについて
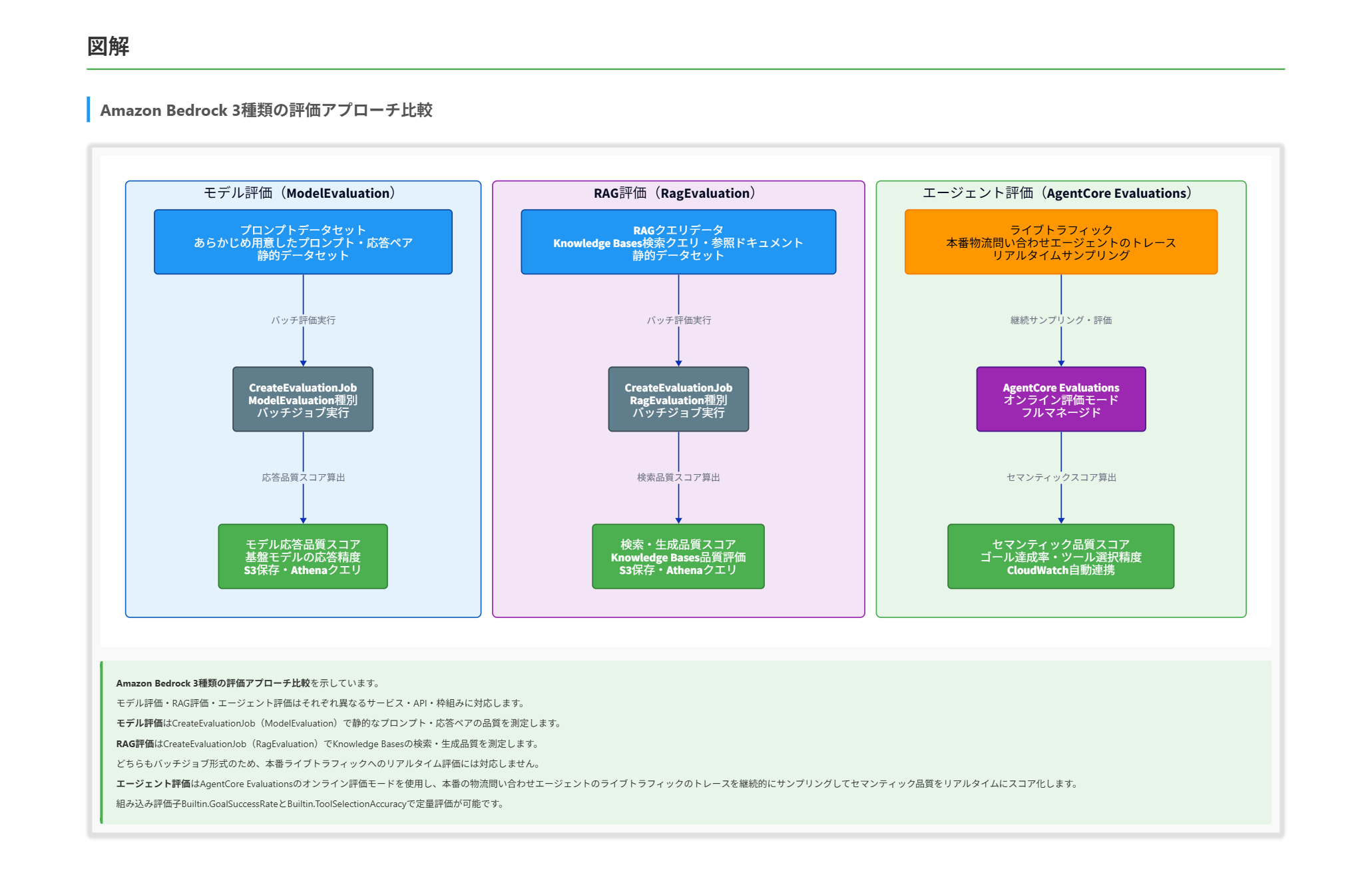
- CreateEvaluationJob APIはAmazon Bedrockが提供するモデル評価・RAG評価の枠組みです。applicationTypeパラメータの有効値はModelEvaluation(基盤モデルの応答品質評価)とRagEvaluation(Knowledge Basesの検索・生成品質評価)の2種類のみであり、エージェントのエンドツーエンドトレースを対象とする評価種別は仕様上存在しません。
- このAPIはあらかじめ用意したプロンプトデータセットに対してモデルが返した応答をスコア化する枠組みであり、エージェントが複数ステップにわたってどのツールをどの順序で呼び出したかというトレースベースの動的評価とは設計上の対象範囲が異なります。
- ジョブ形式のバッチ処理であるため、本番ライブトラフィックへの継続的なリアルタイム評価という要件とも整合しません。
Amazon CloudWatch Bedrockエージェントメトリクスについて
- Amazon Bedrock AgentsはAWS/Bedrock/Agents名前空間のメトリクスをCloudWatchに発行します。主なメトリクスとしてInvocationCount(呼び出し数)・TotalTime(処理時間)・InputTokenCount(入力トークン数)・ClientErrors(クライアントエラー数)などがあります。
- これらは「システムが正常に動いているか」を把握するための運用可観測性指標です。エージェントの回答内容がユーザーの意図を達成しているか、あるいは呼び出されたツールが文脈的に適切だったかというセマンティックな評価は、これらのメトリクスには含まれていません。
- 問題文で「呼び出し回数やレイテンシは別途監視済みであり、セマンティックな品質の把握が目的」と明示されているため、CloudWatchランタイムメトリクスが今回の要件を満たさないことを読み取ることができます。
Amazon SageMaker Clarifyについて
- Amazon SageMaker ClarifyはSHAPアルゴリズムを用いた特徴量帰属(どの入力特徴がモデルの予測にどれだけ影響したかの分析)と、学習データ・推論結果のバイアス検出を主目的とするサービスです。特徴量帰属とは「融資審査モデルが否決した理由として収入が最も影響していた」といった分析を数値で示すものです。
- 会話エージェントのゴール達成率やツール選択の妥当性をセマンティックに評価する機能はClarifyの設計に含まれておらず、エージェント評価の文脈で使用することは想定されていません。
解くための考え方
この問題では、5つの要件すべてを同時に満たすサービスを特定する必要があります。まず各要件を整理し、それぞれに対応できるかどうかという軸で選択肢を検証する方針が有効です。 最初に「セマンティックな品質評価が可能か」という軸で絞り込みます。セマンティックとは「意味的に正しいか」ということです。たとえば「エージェントがユーザーの質問に答えるために正しいツールを選んだか」という評価は、ツールが呼び出されたという事実(運用指標)ではなく、「そのツールが文脈的に適切だったか」という意味的な判断を必要とします。CloudWatchランタイムメトリクスは呼び出し回数やエラー数を記録するシステム指標であり、この意味的な判断を行う機能を持ちません。SageMaker ClarifyはMLモデルの特徴量帰属分析ツールであり、会話エージェントのセマンティック評価はそもそも設計対象外です。この時点でCloudWatchメトリクス中心の構成とSageMaker Clarify中心の構成は除外できます。 次に「エージェントのトレースを対象とした評価か」という軸で検証します。CreateEvaluationJob APIはapplicationTypeがModelEvaluationまたはRagEvaluationに限定されており、APIの仕様上エージェントのエンドツーエンドトレースを評価対象とする種別が存在しません。このAPIはプロンプトと応答のペアをデータセットとして評価する枠組みであり、エージェントが複数のバックエンドツールをどのように選択・実行したかという動的なトレースの評価には対応していません。さらに、バッチジョブをEventBridgeで定期実行する構成はリアルタイムの継続評価という要件と整合しません。 最後に残る選択肢であるAmazon Bedrock AgentCore Evaluationsを検証します。このサービスのオンライン評価モードは本番ライブトラフィックからトレースを継続的にサンプリング・スコア化します。組み込み評価子Builtin.GoalSuccessRateはゴール達成率を、Builtin.ToolSelectionAccuracyはツール選択精度をLLM-as-a-Judgeで定量化します。評価基盤(評価モデル・推論インフラ・データパイプライン)はサービス側がフルマネージドで提供するため、独自のML基盤を構築・維持する必要はありません。評価結果はCloudWatchと統合されているため、アラート設定も可能です。5つの要件すべてに合致することが確認できます。 静的なプロンプト・応答ペアの品質を測る「モデル評価」、検索・生成品質を測る「RAG評価」、マルチステップのトレースに基づくセマンティック品質を測る「エージェント評価」は、それぞれ異なるサービス・API・枠組みに対応することを押さえておく必要があります。 参考資料
- Amazon Bedrock AgentCore Evaluations の概要
- AgentCore Evaluations の仕組み
- オンライン評価の作成
- 組み込み評価子の概要
- Amazon Bedrock AgentCore Evaluations の一般提供開始
- Amazon Bedrock AgentCore Evaluations によるAIエージェント評価(AWSブログ)
- CreateEvaluationJob API リファレンス
- Amazon Bedrock Agents の CloudWatch メトリクス
- Amazon SageMaker Clarify によるモデル説明可能性
スポンサーリンク
以下スポンサーリンクです。
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。