AWS DEA無料問題集です。正解と解説を確認する際は右側のボタンを押下してください。
問題集の完全版は以下Udemyにて発売しているためお買い求めください。問題集への質問はUdemyのQA機能もしくはUdemyのメッセージにて承ります。Udemyの問題1から10問抜粋しております。
多くの方にご好評いただき、講師評価 4.5/5.0 を獲得できております。ありがとうございます。

特別価格: 通常2,600円 → 1,500円
講師クーポン適用で42%OFF
講師クーポン【図解付き詳細解説】AWS DEA-C01完全攻略問題集 | 構成図&グラフ解説付き
この資格を活かしたキャリア情報
DEA資格の取得後にどんなキャリアが開けるか、詳しくはこちら:
→ DEA合格者の転職市場価値と求人傾向
AWS資格全体のキャリア活用法:
→ AWS資格は転職・キャリアアップでどう活きる?資格別市場価値と実体験
問題文:
ある医療機器レンタル企業が、病院向けの機器需要をほぼリアルタイムで管理するために、過去の患者受け入れ動向に基づいて需要を予測するMLモデルをトレーニングしています。トレーニング済みモデルを本番のAmazon SageMaker AIエンドポイントに正常にデプロイしましたが、モデルの予測パフォーマンスが時間の経過とともに低下していることに気付きました。企業はパフォーマンス低下を軽減するための長期的かつ自動化されたソリューションを必要としています。この要件を満たすソリューションはどれですか。
選択肢:
A. Amazon SageMaker Debuggerを使用して、モデルパフォーマンスの異常が検出されたときに自動でアラートを送信します。
B. AWS X-Rayを使用して、SageMaker AIエンドポイントのパフォーマンスと受信リクエストを監視し、モデルの再トレーニングに活用します。
C. Amazon SageMaker Ground Truthを使用して高品質なデータセットをキュレーションし、そのデータセットでモデルを再トレーニングします。
D. Amazon SageMaker Clarifyを使用して、モデルおよび特徴量アトリビューションのバイアスを監視し、モデルの再トレーニングに活用します。
正解:D
A. Amazon SageMaker Debuggerを使用して、モデルパフォーマンスの異常が検出されたときに自動でアラートを送信します。
不正解 SageMaker Debuggerはトレーニングジョブ中のデバッグに特化したツールです。トレーニング中の勾配消失、過学習、リソース使用率の異常などをリアルタイムに検出・アラートする機能を提供しますが、本番環境にデプロイされたモデルの推論パフォーマンスの経時的な劣化を監視する機能は持ちません。本番モデルのドリフト検出には適していません。
B. AWS X-Rayを使用して、SageMaker AIエンドポイントのパフォーマンスと受信リクエストを監視し、モデルの再トレーニングに活用します。
不正解 AWS X-Rayはアプリケーションの分散トレーシングサービスです。リクエストのレイテンシ、エラー率、サービス間の呼び出しフローの可視化など、アプリケーションレベルのパフォーマンス監視を行います。しかし、MLモデルの予測品質や特徴量の変化を分析する機能は提供しません。インフラストラクチャのパフォーマンス問題は検出できますが、モデルのドリフトを検出することはできません。
C. Amazon SageMaker Ground Truthを使用して高品質なデータセットをキュレーションし、そのデータセットでモデルを再トレーニングします。
不正解 SageMaker Ground Truthはデータラベリングサービスであり、高品質なトレーニングデータの作成に有用です。しかし、モデルパフォーマンスの低下を自動的に検出する機能は持ちません。また、いつ再トレーニングが必要かを判断する仕組みがないため、長期的かつ自動化されたソリューションとしては不十分です。問題の根本原因であるモデルドリフトの検出には対応していません。
D. Amazon SageMaker Clarifyを使用して、モデルおよび特徴量アトリビューションのバイアスを監視し、モデルの再トレーニングに活用します。
正解 SageMaker Clarifyは本番エンドポイントで特徴量アトリビューションドリフトを継続的に監視する機能を提供します。SHAP値に基づいて特徴量の重要度ランキングをトレーニング時と比較し、正規化割引累積利得(NDCG)スコアで変化を定量化します。 NDCGスコアが0.90を下回ると自動でCloudWatchアラートが発報されるため、モデルの再トレーニングが必要なタイミングを自動的に検知できます。スケジュール実行による継続的な監視が可能であり、長期的な自動化ソリューションとして最適です。
全体的な説明
問われている要件
- 医療機器需要予測モデルが本番環境で時間の経過とともにパフォーマンスが低下している
- パフォーマンス低下を軽減する必要がある
- 長期的かつ自動化されたソリューションを求めている
- 再トレーニングの判断材料となる監視の仕組みが必要である
前提知識
モデルドリフトについて
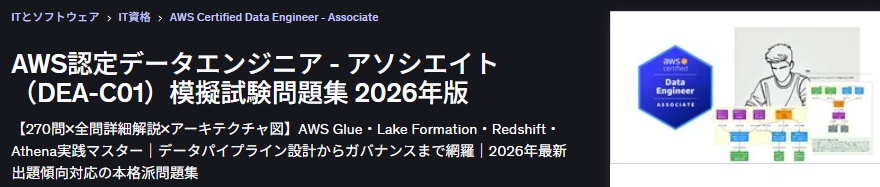
- モデルドリフトとは、本番環境でのデータ分布がトレーニング時と異なることにより、モデルの予測精度が低下する現象である
- 医療機器レンタルの需要予測では、患者の受け入れパターンや季節変動、感染症の流行動向の変化などによりドリフトが発生しやすい
- コンセプトドリフト(入力と出力の関係性の変化)とデータドリフト(入力データの分布の変化)の2種類がある
- ドリフトを早期に検出し、適切なタイミングでモデルを再トレーニングすることが重要である
Amazon SageMaker Clarifyの特徴量アトリビューション監視について
- SageMaker Clarifyは本番エンドポイントの特徴量アトリビューションドリフトを監視する機能を提供する
- SHAP(SHapley Additive exPlanations)値を使用して、各特徴量がモデルの予測にどの程度寄与しているかを測定する
- トレーニング時のベースラインと本番データのSHAP値を比較し、NDCG(正規化割引累積利得)スコアで変化を定量化する
- NDCGスコアが1.0の場合はトレーニング時と完全に一致し、0.90を下回ると自動でアラートが発報される
- ModelExplainabilityMonitorを使用してスケジュール実行(例:1時間ごと)の監視ジョブを設定できる
SageMaker Debuggerの役割について
- Debuggerはトレーニングジョブのデバッグに特化しており、勾配消失・爆発、過学習などの問題を検出する
- トレーニング中のテンソルデータを収集・分析し、問題発生時にアラートやアクションを実行する
- 本番環境にデプロイされたモデルの推論パフォーマンス監視には使用されない
解くための考え方
この問題では、本番環境でデプロイされた需要予測モデルのパフォーマンスが時間の経過とともに低下している状況で、長期的かつ自動化された対策を問われています。
医療機器レンタル企業の需要予測モデルでは、患者の受け入れ動向や地域の医療需要のトレンドが変化するため、トレーニング時のデータと本番データの分布が乖離するモデルドリフトが発生します。 このドリフトを検出するには、特徴量がモデルの予測に与える影響度の変化を監視する必要があります。
SageMaker Clarifyの特徴量アトリビューション監視は、SHAP値を使用して各特徴量の寄与度をトレーニング時と継続的に比較します。寄与度の変化が閾値を超えるとCloudWatchアラートが自動で発報されるため、再トレーニングが必要なタイミングを自動的に検知できます。
SageMaker Debuggerはトレーニングジョブのデバッグツールであり、本番モデルの監視には使えません。 AWS X-Rayはアプリケーションの分散トレーシングツールであり、モデル品質の監視機能を持ちません。 Ground Truthはデータラベリングサービスであり、ドリフト検出の仕組みがありません。
したがって、SageMaker Clarifyによる特徴量アトリビューションドリフトの監視が、長期的かつ自動化されたソリューションとして最適です。
参考資料
- 本番モデルの特徴量アトリビューションドリフト - Amazon SageMaker AI
- 特徴量アトリビューションドリフト監視ジョブのスケジュール設定 - Amazon SageMaker AI
- Amazon SageMaker Clarify とは - Amazon SageMaker AI
- Amazon SageMaker Model Monitor - Amazon SageMaker AI
- Amazon SageMaker Debugger - Amazon SageMaker AI
- アトリビューションドリフトを監視するためのパラメータ - Amazon SageMaker AI
- Amazon CloudWatch のメトリクスとアラーム - Amazon SageMaker AI
問題文:
ある医療画像診断企業がMLモデル用のAmazon SageMaker AIパイプラインを構築しています。このパイプラインは分散処理とトレーニングを使用しています。MLエンジニアは、分散ジョブを実行するインスタンス間のネットワーク通信を暗号化する必要があります。MLエンジニアは分散ジョブをプライベートVPCで実行するように構成しました。暗号化の要件を満たすために、MLエンジニアは何をすべきですか。
選択肢:
A. ネットワーク分離を有効にします。
B. セキュリティグループを使用してトラフィック暗号化を構成します。
C. コンテナ間トラフィック暗号化を有効にします。
D. VPCフローログを有効にします。
正解:C
A. ネットワーク分離を有効にします。
不正解 ネットワーク分離(Network Isolation)を有効にすると、トレーニングコンテナはネットワーク呼び出しを一切行えなくなります。これはコンテナがインターネットやVPC内の他のリソースにアクセスすることを防ぐ機能です。分散トレーニングではインスタンス間の通信が必須であるため、ネットワーク分離を有効にすると分散ジョブ自体が正常に動作しなくなります。暗号化とネットワーク分離は異なる概念です。
B. セキュリティグループを使用してトラフィック暗号化を構成します。
不正解 セキュリティグループはVPC内のインスタンスに対するインバウンドおよびアウトバウンドのトラフィックを制御するファイアウォール機能です。セキュリティグループはポートやプロトコル、送信元/宛先に基づいてトラフィックの許可・拒否を行いますが、トラフィックの暗号化機能は提供しません。セキュリティグループはアクセス制御の仕組みであり、データの暗号化とは無関係です。
C. コンテナ間トラフィック暗号化を有効にします。
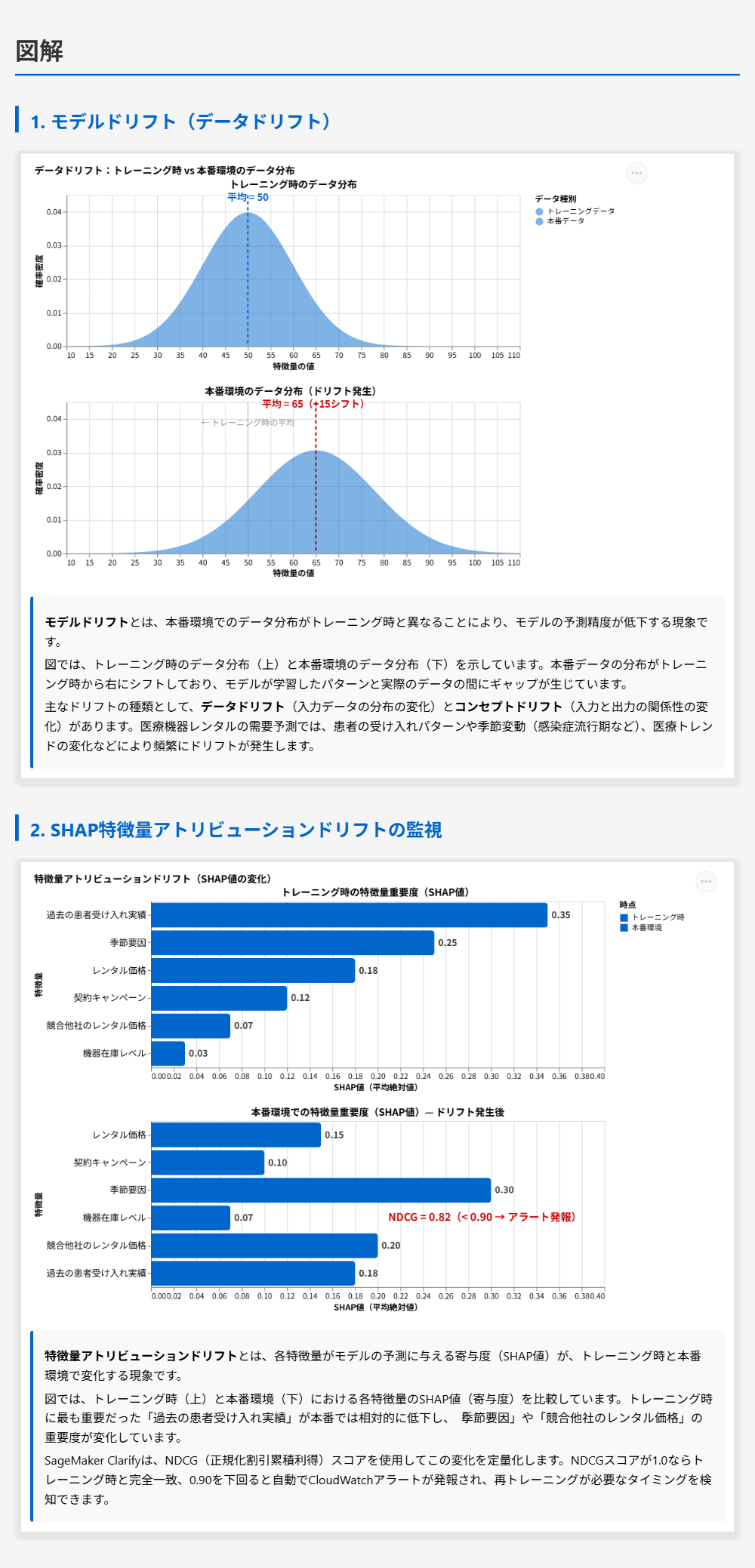
正解 SageMaker AIでは、分散トレーニングジョブにおけるインスタンス間の通信を暗号化するために、コンテナ間トラフィック暗号化(Inter-container Traffic Encryption)機能を提供しています。CreateTrainingJobまたはCreateHyperParameterTuningJob APIでEnableInterContainerTrafficEncryptionパラメータをTrueに設定することで有効化できます。VPCのセキュリティグループにUDPポート500とESPプロトコル50のルールを追加する必要があります。
D. VPCフローログを有効にします。
不正解 VPCフローログは、VPC内のネットワークインターフェイスとの間で送受信されるIPトラフィックに関する情報をキャプチャする機能です。フローログはトラフィックの監視・記録を目的としており、通信の暗号化機能は一切提供しません。ネットワークのトラブルシューティングやセキュリティ監査には有用ですが、暗号化要件を満たすことはできません。
全体的な説明
問われている要件
- SageMaker AIパイプラインで分散処理・トレーニングを実行している
- 分散ジョブを実行するインスタンス間のネットワーク通信を暗号化する必要がある
- 分散ジョブはプライベートVPCで実行するよう構成済み
- 暗号化要件を満たす適切な方法を選択する
前提知識
SageMaker AIのコンテナ間トラフィック暗号化について
- SageMakerは分散トレーニング時、複数のMLコンピューティングインスタンス間でモデルの重みや勾配などの情報を送受信する
- デフォルトでは、分散トレーニングジョブのノード間通信は暗号化されない
- コンテナ間トラフィック暗号化を有効にすると、インスタンス間のすべてのネットワーク通信が暗号化される
- この機能はIPsecトンネルを使用して実装されている
- 暗号化によりトレーニング時間が増加する場合があるが、XGBoost、DeepAR、線形学習器などの組み込みアルゴリズムでは影響が小さい
SageMaker AIのネットワーク分離について
- ネットワーク分離を有効にすると、コンテナはアウトバウンドのネットワーク呼び出しを行えなくなる
- S3やその他のAWSサービスへのアクセスも遮断される
- 分散トレーニングではインスタンス間の通信が必須のため、ネットワーク分離との併用には注意が必要である
VPCセキュリティグループについて
- セキュリティグループはステートフルなファイアウォールとして機能する
- インバウンドルールとアウトバウンドルールにより、許可するトラフィックを制御する
- トラフィックのフィルタリング機能であり、暗号化機能は持たない
- コンテナ間トラフィック暗号化を使用する場合、セキュリティグループにUDPポート500とESPプロトコル50の許可ルールを追加する必要がある
解くための考え方
この問題では、SageMakerの分散ジョブにおけるインスタンス間のネットワーク通信を暗号化する方法を問われています。
まず、分散トレーニングではインスタンス間でモデルの重みや勾配情報などが頻繁にやり取りされます。この通信を暗号化するには、SageMaker AIが提供するコンテナ間トラフィック暗号化機能を使用します。 この機能はAPIのEnableInterContainerTrafficEncryptionパラメータで有効化でき、インスタンス間のすべての通信がIPsecトンネルを通じて暗号化されます。
ネットワーク分離はコンテナのネットワークアクセス自体を遮断する機能であり、分散ジョブに必要なインスタンス間通信も遮断してしまうため不適切です。 セキュリティグループはトラフィックのフィルタリング機能であり暗号化は行いません。VPCフローログはトラフィックの記録機能であり、暗号化とは無関係です。
したがって、コンテナ間トラフィック暗号化を有効にすることが、分散ジョブのインスタンス間通信を暗号化する正しい方法です。
参考資料
- 分散トレーニングジョブ内の ML コンピューティングインスタンス間の通信を保護する
- 転送時のデータの暗号化による保護
- Amazon SageMaker AI トレーニングジョブに Amazon VPC のリソースへのアクセスを許可する
- NetworkConfig – Amazon SageMaker AI API Reference
- CreateTrainingJob – Amazon SageMaker AI API Reference
- Amazon SageMaker AI でのインフラストラクチャセキュリティ
- Amazon SageMaker AI のセキュリティのベストプラクティス
- Amazon VPC とは
問題文:
医療画像診断スタートアップのMLエンジニアが、Amazon S3に蓄積された検査データを分析用に使用、準備、ロードしたいと考えています。MLエンジニアは、データのスキーマを発見し、メタデータを保存するためにETL(抽出、変換、ロード)ジョブを実行する必要があります。最小限の手作業でこれらの要件を満たすソリューションはどれですか。
選択肢:
A. AWS Glueを使用してETLジョブを実行します。ジョブを使用してスキーマを発見し、関連するメタデータをAWS Glue Data Catalogに保存します。
B. Amazon SageMaker Data Wranglerフローを作成してETLジョブを実行します。ジョブを使用してスキーマを発見し、関連するメタデータをS3バケットに保存します。
C. AWS Step Functionsと統合されたAmazon Athenaを使用してETLパイプラインを作成します。パイプラインを使用してETLジョブを実行し、スキーマを発見し、関連するメタデータをS3バケットに保存します。
D. scikit-learnライブラリを含むAmazon EC2インスタンスを起動してETLジョブを実行します。ジョブを使用してスキーマを発見し、関連するメタデータをAmazon Redshiftに保存します。
正解:A
A. AWS Glueを使用してETLジョブを実行します。ジョブを使用してスキーマを発見し、関連するメタデータをAWS Glue Data Catalogに保存します。
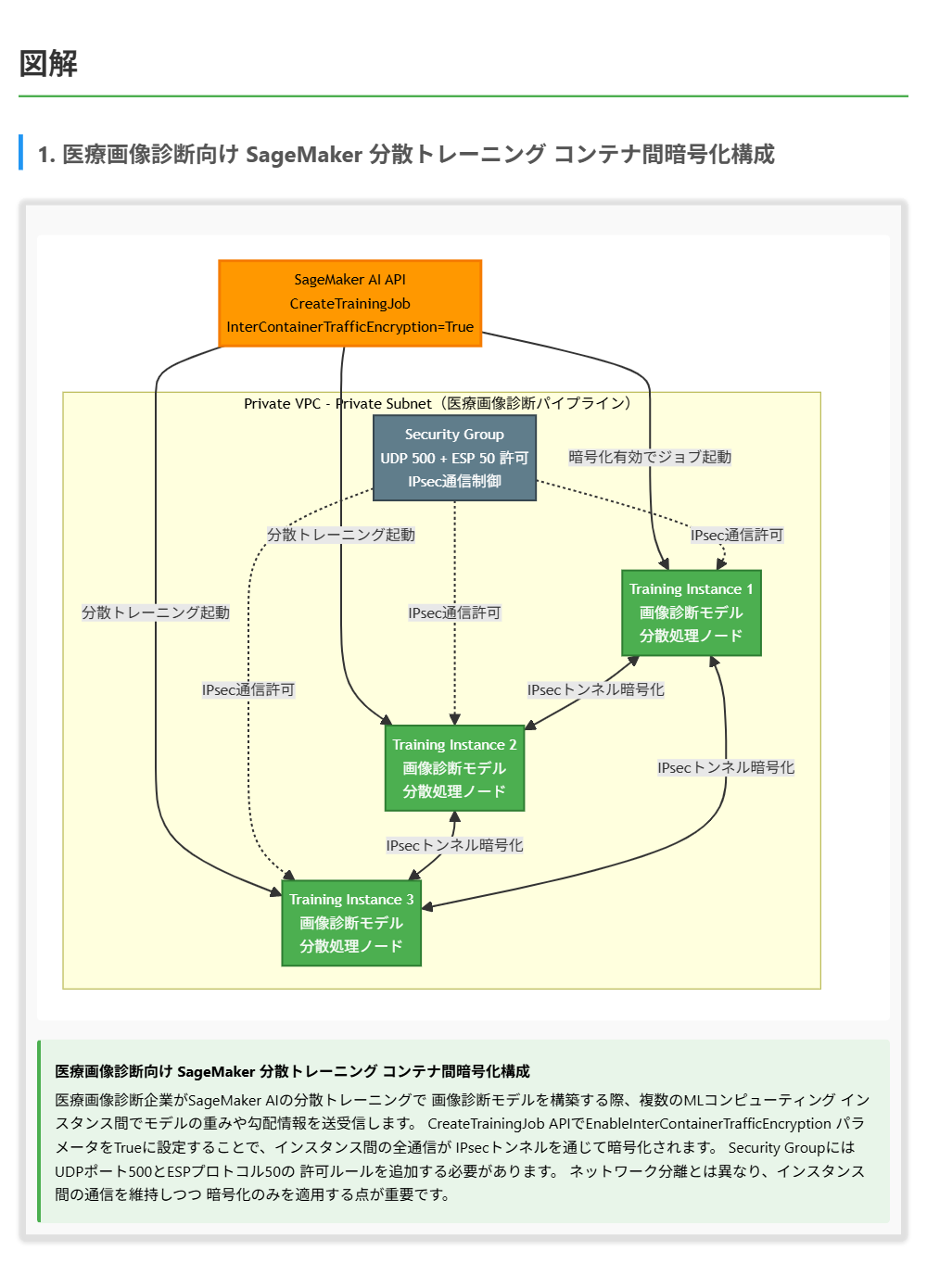
正解 AWS Glueはフルマネージドのサーバーレスデータ統合サービスであり、ETLジョブの実行、スキーマの自動発見、メタデータの管理を一貫して行えます。AWS Glueクローラーがデータソースを自動的にスキャンしてスキーマを推論し、AWS Glue Data Catalogにメタデータとして保存します。Data Catalogは一元的なメタデータリポジトリとして機能し、Amazon AthenaやAmazon Redshift Spectrumなど他のAWSサービスからも参照できます。
B. Amazon SageMaker Data Wranglerフローを作成してETLジョブを実行します。ジョブを使用してスキーマを発見し、関連するメタデータをS3バケットに保存します。
不正解 SageMaker Data Wranglerはデータの前処理や特徴量エンジニアリングに特化したツールであり、スキーマの自動発見やメタデータの一元管理を主目的としていません。メタデータをS3バケットに保存する方式では、構造化されたメタデータカタログとして機能せず、他のAWSサービスから容易に参照できません。ETLとメタデータ管理の統合ソリューションとしてはAWS Glueの方が適切です。
C. AWS Step Functionsと統合されたAmazon Athenaを使用してETLパイプラインを作成します。パイプラインを使用してETLジョブを実行し、スキーマを発見し、関連するメタデータをS3バケットに保存します。
不正解 Amazon Athenaは主にS3上のデータに対するインタラクティブなクエリサービスであり、ETLジョブの実行エンジンとしては設計されていません。AthenaとStep Functionsを組み合わせてETLパイプラインを構築することは技術的に可能ですが、スキーマの自動発見やメタデータの管理機能が組み込まれておらず、これらを手動で構築する必要があります。AWS Glueと比較して大幅に手作業が増加します。
D. scikit-learnライブラリを含むAmazon EC2インスタンスを起動してETLジョブを実行します。ジョブを使用してスキーマを発見し、関連するメタデータをAmazon Redshiftに保存します。
不正解 EC2インスタンス上でscikit-learnを使用してETLジョブを実行する方式は、インスタンスのプロビジョニング、セキュリティ設定、スケーリング、メンテナンスなどの運用作業が必要です。scikit-learnは機械学習ライブラリであり、スキーマ発見やETL処理に最適化されたツールではありません。Amazon Redshiftはデータウェアハウスサービスであり、メタデータの保存先として過剰な構成です。
全体的な説明
問われている要件
- Amazon S3のデータを分析用に準備・ロードする必要がある
- ETLジョブを実行してデータのスキーマを自動的に発見する必要がある
- 発見したメタデータを保存する仕組みが必要である
- 最小限の手作業で要件を満たすことが求められている
前提知識
AWS Glueについて
- AWS Glueはフルマネージドのサーバーレスデータ統合サービスであり、ETLジョブの作成・実行を自動化できる
- AWS Glueクローラーはデータソース(S3、RDS、DynamoDBなど)を自動的にスキャンし、スキーマを推論してData Catalogに登録する
- AWS Glue Data Catalogは一元的なメタデータリポジトリであり、テーブル定義、スキーマ情報、パーティション情報などを管理する
- Data CatalogはAmazon Athena、Amazon Redshift Spectrum、Amazon EMRなど多くのAWSサービスと統合されている
Amazon SageMaker Data Wranglerについて
- SageMaker Data Wranglerは機械学習のためのデータ準備に特化したビジュアルツールである
- データのインポート、変換、分析、エクスポートをGUIベースで行える
- 機械学習の特徴量エンジニアリングに強みがあるが、汎用的なETLやメタデータカタログ管理には向いていない
Amazon Athenaについて
- Amazon AthenaはS3上のデータに対して標準SQLでインタラクティブなクエリを実行できるサーバーレスサービスである
- クエリ実行エンジンとして動作し、ETLの実行エンジンとしては最適化されていない
- AWS Glue Data Catalogをメタストアとして使用できる
Amazon Redshiftについて
- Amazon Redshiftはペタバイト規模のデータウェアハウスサービスである
- メタデータの保存先としては過剰な構成であり、クラスターの管理やコストが発生する
解くための考え方
この問題では「ETLジョブの実行」「スキーマの自動発見」「メタデータの保存」の3つの要件を最小限の手作業で実現する方法が問われています。
AWS Glueはこれら3つの要件をすべて単一のサービスで満たすことができます。クローラーがデータソースを自動スキャンしてスキーマを推論し、ETLジョブでデータ変換を行い、発見したメタデータをData Catalogに自動的に保存します。 サーバーレスであるため、インフラストラクチャの管理も不要です。
SageMaker Data Wranglerは機械学習のデータ準備に特化しており、汎用的なスキーマ発見やメタデータカタログの機能を持ちません。 AthenaとStep Functionsの組み合わせは、スキーマ発見やメタデータ管理の仕組みを手動で構築する必要があり、手作業が大幅に増えます。 EC2上でscikit-learnを使用する方式は、インスタンス管理の運用負荷が高く、ETLに最適化されたツールでもありません。
したがって、AWS Glueを使用する方式が最小限の手作業という要件を最も効率的に満たします。
参考資料
問題文:
物流会社のMLエンジニアが、配送需要予測モデル用のAmazon SageMaker AIパイプラインをセットアップしています。このパイプラインは、データドリフトが検出された場合に自動的に再トレーニングジョブを開始する必要があります。この要件を満たすために、MLエンジニアはどのようにパイプラインをセットアップすべきですか。
選択肢:
A. AWS GlueクローラーとAWS Glueの抽出・変換・ロード(ETL)ジョブを使用してデータドリフトを検出します。AWS Glueトリガーを使用して再トレーニングジョブを自動化します。
B. Amazon Managed Service for Apache Flinkを使用してデータドリフトを検出します。AWS Lambda関数を使用して再トレーニングジョブを自動化します。
C. SageMaker Model Monitorを使用してデータドリフトを検出します。AWS Lambda関数を使用して再トレーニングジョブを自動化します。
D. Amazon QuickSightの異常検出を使用してデータドリフトを検出します。AWS Step Functionsワークフローを使用して再トレーニングジョブを自動化します。
正解:C
A. AWS GlueクローラーとAWS Glueの抽出・変換・ロード(ETL)ジョブを使用してデータドリフトを検出します。AWS Glueトリガーを使用して再トレーニングジョブを自動化します。
不正解 AWS Glueはデータカタログの作成やETL処理を行うサービスです。Glueクローラーはデータソースをスキャンしてスキーマを自動検出し、データカタログに登録する機能を持っています。GlueのETLジョブはデータの変換や加工を行います。しかし、AWS Glueにはデータドリフトを検出する機能は組み込まれていません。データドリフトの検出には統計的な比較やモニタリングの仕組みが必要であり、Glueの用途とは異なります。
B. Amazon Managed Service for Apache Flinkを使用してデータドリフトを検出します。AWS Lambda関数を使用して再トレーニングジョブを自動化します。
不正解 Amazon Managed Service for Apache Flinkはリアルタイムストリーム処理サービスで、ストリーミングデータの分析や変換に使用します。カスタムコードを記述すればデータの統計的変化を検出するロジックを構築できますが、データドリフト検出の専用機能は提供されていません。SageMaker Model Monitorのようにベースラインとの統計的比較やドリフト検出レポートの自動生成機能がないため、この用途には過剰な開発工数が必要になります。
C. SageMaker Model Monitorを使用してデータドリフトを検出します。AWS Lambda関数を使用して再トレーニングジョブを自動化します。
正解 SageMaker Model Monitorは、デプロイされたMLモデルのデータ品質を継続的にモニタリングするサービスです。ベースラインのデータ統計量と現在の推論データを比較し、データドリフト(入力データの分布変化)を自動的に検出します。ドリフトが検出されるとAmazon CloudWatch Eventsに通知が送信されるため、この通知をトリガーとしてAWS Lambda関数を呼び出し、SageMakerの再トレーニングジョブを自動的に開始できます。
D. Amazon QuickSightの異常検出を使用してデータドリフトを検出します。AWS Step Functionsワークフローを使用して再トレーニングジョブを自動化します。
不正解 Amazon QuickSightはビジネスインテリジェンス(BI)サービスで、ダッシュボードの作成やデータの可視化を行います。QuickSightにはML Insightsによる異常検出機能がありますが、これはビジネスメトリクスの異常を検出するためのものであり、MLモデルのデータドリフトを検出するための機能ではありません。SageMakerのMLパイプラインと統合してデータドリフトを検出する仕組みは提供されていません。
全体的な説明
問われている要件
- SageMaker AIパイプラインでMLモデルを運用している
- データドリフトを自動的に検出する仕組みが必要
- データドリフト検出時に再トレーニングジョブを自動的に開始する必要がある
- 適切なAWSサービスの組み合わせを選択する
前提知識
データドリフトについて
- データドリフトとは、モデルのトレーニングに使用したデータの分布と、本番環境で受け取る推論データの分布が時間とともに変化する現象のこと
- 例えば、ローン審査モデルをトレーニングした時点では申請者の平均年収が500万円だったが、経済状況の変化により現在は400万円に低下したような場合がデータドリフトに該当する
- データドリフトが発生するとモデルの予測精度が低下するため、検出と再トレーニングが重要になる
SageMaker Model Monitorについて
- デプロイされたモデルのデータ品質、モデル品質、バイアス、特徴量の帰属性を継続的にモニタリングするサービス
- ベースラインの統計量(平均値、標準偏差、データ型など)を自動的に計算し、推論データと比較する
- データドリフトを検出するとCloudWatch Eventsに通知を発行する
- スケジュール実行(例:1時間ごと)で定期的にモニタリングジョブを実行できる
AWS Lambda関数について
- サーバーレスのコンピューティングサービスで、イベント駆動型の処理を実行する
- CloudWatch Events、Amazon EventBridge、S3イベントなど様々なトリガーで起動できる
- SageMaker APIを呼び出してトレーニングジョブやパイプラインの実行を開始できる
- 実行時間は最大15分まで対応している
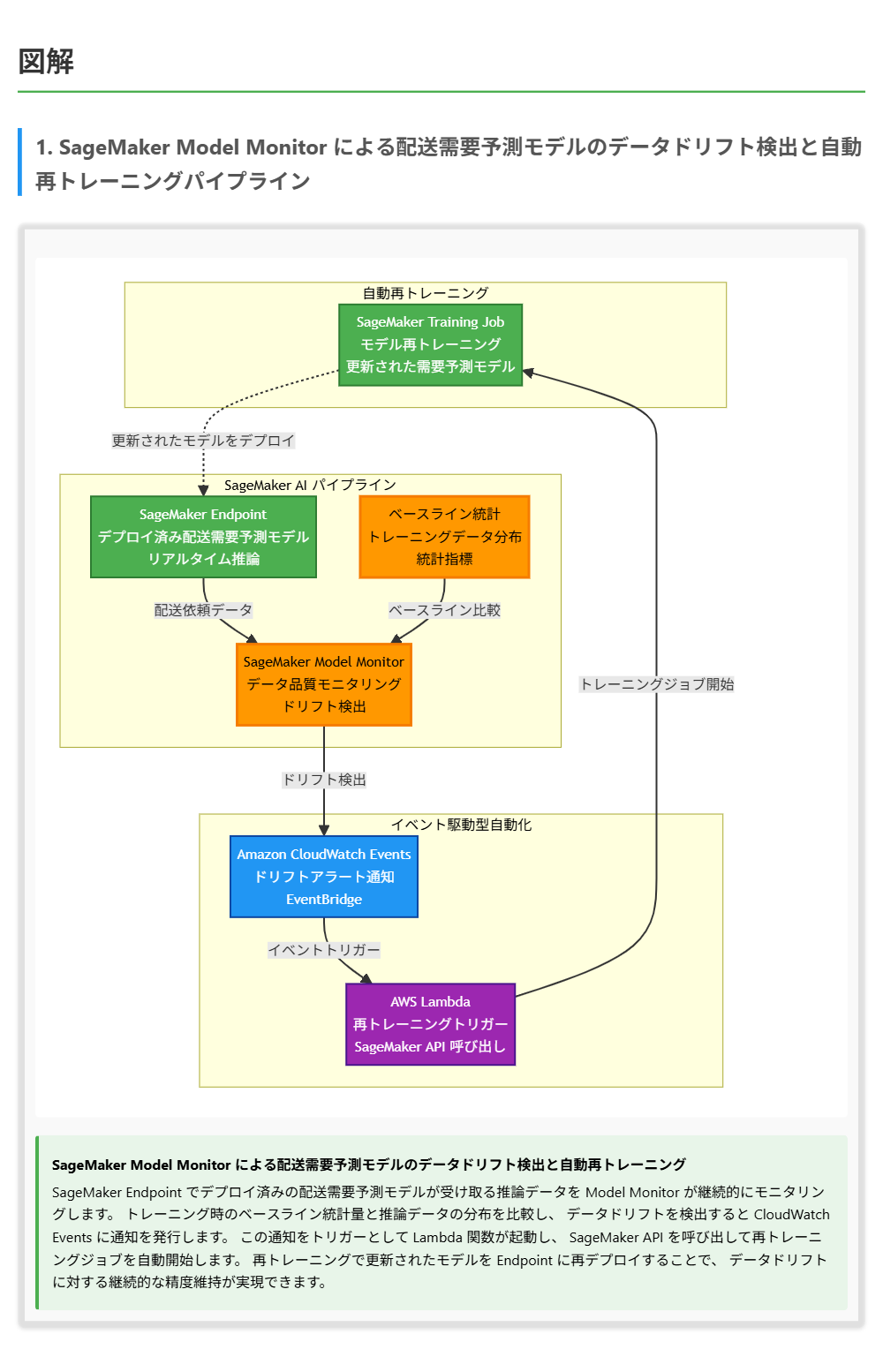
解くための考え方
この問題では、SageMakerパイプラインにおけるデータドリフトの検出と自動再トレーニングの仕組みを構築する方法を問われています。
データドリフトの検出には、トレーニング時のデータ分布と現在の推論データの分布を統計的に比較する機能が必要です。SageMaker Model Monitorはまさにこの目的のために設計されたサービスで、ベースラインの統計量を自動計算し、推論データとの差異を継続的にモニタリングします。
再トレーニングの自動化については、Model Monitorがデータドリフトを検出するとCloudWatch Eventsに通知を発行するため、この通知をトリガーとしてLambda関数を呼び出すことができます。 Lambda関数内でSageMaker APIを使用してトレーニングジョブやパイプラインの実行を開始すれば、データドリフト検出から再トレーニングまでの一連の流れを自動化できます。
AWS Glueはデータカタログ・ETL用、Apache Flinkはストリーム処理用、QuickSightはBI・可視化用のサービスであり、いずれもデータドリフト検出の専用機能を持っていません。 したがって、SageMaker Model MonitorとLambda関数の組み合わせが正解です。
参考資料
問題文:
あるオンライン学習プラットフォーム企業が、Amazon SageMaker AIを使用して、eラーニングサイト向けの新しい教材レコメンデーションモデルをデプロイしています。モデルはすべての受講者のサイト内インタラクションのデータを入力として使用する必要があります。トラフィックは1日を通して変動します。企業はモデルの推論エンドポイントを作成する必要があります。これらの要件を最もコスト効率よく満たす推論エンドポイントのタイプはどれですか。
選択肢:
A. バッチ変換推論エンドポイント
B. 非同期推論エンドポイント
C. リアルタイム推論エンドポイント
D. サーバーレス推論エンドポイント
正解:D
A. バッチ変換推論エンドポイント
不正解 バッチ変換は、大量のデータセットに対してオフラインで一括推論を実行する方式です。eラーニングサイトの受講者インタラクションに基づくリアルタイムの教材レコメンデーションには、受講者がサイトを閲覧している間に即座に推論結果を返す必要があります。バッチ変換はリクエストごとのオンライン推論に対応しておらず、サイトでのリアルタイムなレコメンデーション要件を満たすことができません。
B. 非同期推論エンドポイント
不正解 非同期推論エンドポイントは、大きなペイロードサイズや長い処理時間を必要とするリクエストに適した方式です。リクエストをキューに入れて非同期で処理するため、レスポンスの即時性が求められるeラーニングサイトのレコメンデーションには適していません。また、非同期推論はインスタンスを常時稼働させる構成が基本であり、トラフィックの変動が大きい場合のコスト効率はサーバーレス推論に劣ります。
C. リアルタイム推論エンドポイント
不正解 リアルタイム推論エンドポイントは常時稼働するインスタンスを使用してリアルタイムの推論を提供します。リアルタイムのレコメンデーション要件は満たせますが、インスタンスはトラフィックがない時間帯でも稼働し続けるため、トラフィックが変動する場合にはコスト効率が低くなります。インスタンスの利用時間に対して課金されるため、アイドル時間分のコストが無駄になります。
D. サーバーレス推論エンドポイント
正解 サーバーレス推論エンドポイントは、トラフィックに応じて自動的にコンピューティングリソースをスケールアップ・スケールダウンし、トラフィックがないときはゼロにスケールダウンします。利用した推論リクエストの処理時間に対してのみ課金される従量課金モデルであるため、1日を通してトラフィックが変動するワークロードにおいて最もコスト効率が高くなります。eラーニングサイトのレコメンデーションのようなリアルタイム推論にも対応しています。
全体的な説明
問われている要件
- eラーニングサイト向けの教材レコメンデーションモデルをデプロイする必要がある
- すべての受講者のサイト内インタラクションのデータを入力として使用する
- トラフィックは1日を通して変動する
- 最もコスト効率の良い推論エンドポイントを選択する
前提知識
SageMakerサーバーレス推論エンドポイントについて
- トラフィックに応じてコンピューティングリソースを自動的にスケーリングし、ゼロまでスケールダウンできる
- 推論リクエストの処理時間に基づく従量課金モデルで、アイドル時間には課金されない
- コールドスタート(数秒程度のレイテンシ)が発生する場合があるが、Provisioned Concurrencyを設定することで軽減できる
- スパイク的なトラフィックパターンや予測不能なトラフィック量のワークロードに適している
SageMakerリアルタイム推論エンドポイントについて
- 常時稼働するインスタンスを使用して、低レイテンシのリアルタイム推論を提供する
- Auto Scalingを構成できるが、ゼロインスタンスまでのスケールダウンはできない(最低1台のインスタンスが常時稼働する)
- インスタンスの稼働時間に対して課金されるため、トラフィックが少ない時間帯でもコストが発生する
バッチ変換と非同期推論について
- バッチ変換はS3に保存されたデータセットに対してオフラインで一括推論を実行する方式であり、リアルタイムの推論リクエストには対応していない
- 非同期推論はリクエストをキューに入れて非同期に処理する方式で、大きなペイロード(最大1GB)や長い処理時間のワークロードに適している
- 非同期推論はゼロインスタンスへのスケールダウンが可能だが、レスポンスが即時ではないためリアルタイムのサイト内インタラクションには不向きである
解くための考え方
この問題では、eラーニングサイトのレコメンデーションモデルの推論エンドポイントについて、トラフィックが変動する状況で最もコスト効率の良いタイプを選ぶ必要があります。
まず、eラーニングサイトのレコメンデーションは受講者がサイトを閲覧している間にリアルタイムで結果を返す必要があるため、バッチ変換は除外されます。 非同期推論もレスポンスが即時ではないため、サイトのリアルタイムインタラクションには適していません。
リアルタイム推論とサーバーレス推論はどちらもリアルタイムの推論要件を満たせます。 しかし、リアルタイム推論エンドポイントは最低1台のインスタンスが常時稼働するため、トラフィックが少ない時間帯でもコストが発生します。
一方、サーバーレス推論エンドポイントはトラフィックがないときにゼロまでスケールダウンし、推論リクエストの処理時間に対してのみ課金されます。 1日を通してトラフィックが変動するという要件において、サーバーレス推論が最もコスト効率の高い選択肢です。
参考資料
問題文:
あるゲーム開発会社がAWSアカウントAのAmazon S3バケットにプレイヤーの行動ログデータを保存しています。企業はこのデータを使用して、AWSアカウントBのAmazon SageMaker AIでMLモデルをトレーニングする必要があります。トレーニングには10日間かかります。企業はトレーニングでプライベートIPアドレスのみを使用する必要があります。また、トレーニングのメタデータがAWSと共有されないようにする必要があります。これらの要件を満たすソリューションはどれですか。
選択肢:
A. アカウントAとアカウントBの間にVPCピアリングを設定します。AWSにメールで連絡し、メタデータ収集のオプトアウトを依頼します。
B. S3バケット用のVPCエンドポイントを設定します。トレーニングジョブでSageMaker AIのOPT_OUT_TRACKING環境変数を1に設定します。
C. アカウントAのS3バケットに割り当てたセキュリティグループポリシーを構成し、アカウントBからのアクセスのみを許可します。AIサービスのオプトアウトポリシーを作成します。
D. S3バケットに保存されたオブジェクトに対して有効期限付きの署名付きURLを生成します。署名付きURLを使用してデータにアクセスします。トレーニングジョブでSageMaker AIのOPT_OUT_TRACKING環境変数を1に設定します。
正解:B
A. アカウントAとアカウントBの間にVPCピアリングを設定します。AWSにメールで連絡し、メタデータ収集のオプトアウトを依頼します。
不正解 VPCピアリングはVPC間のプライベート通信を可能にしますが、S3はVPC外のサービスであるため、VPCピアリングだけではS3へのプライベートIPアドレスでのアクセスを実現できません。S3にプライベートにアクセスするにはVPCエンドポイントが必要です。また、メタデータ収集のオプトアウトはAWSにメールで連絡する方法ではなく、トレーニングジョブの環境変数OPT_OUT_TRACKINGを1に設定することで実現します。
B. S3バケット用のVPCエンドポイントを設定します。トレーニングジョブでSageMaker AIのOPT_OUT_TRACKING環境変数を1に設定します。
正解 VPCエンドポイント(ゲートウェイ型)を使用すると、インターネットを経由せずにプライベートIPアドレスのみでS3にアクセスできます。これによりトレーニングデータの転送がAWSのプライベートネットワーク内で完結します。 また、OPT_OUT_TRACKING環境変数を1に設定することで、SageMaker AIがトレーニングジョブのメタデータ(使用ライブラリの統計情報やエラー情報など)を収集することを無効化できます。この設定はトレーニングジョブごとに行う必要があります。
C. アカウントAのS3バケットに割り当てたセキュリティグループポリシーを構成し、アカウントBからのアクセスのみを許可します。AIサービスのオプトアウトポリシーを作成します。
不正解 セキュリティグループはEC2インスタンスやENIなどのVPCリソースに割り当てるものであり、S3バケットに直接割り当てることはできません。S3のアクセス制御にはバケットポリシーやIAMポリシーを使用します。また、セキュリティグループはトラフィックのフィルタリングを行う機能であり、プライベートIPアドレスのみでのアクセスを保証するものではありません。AIサービスのオプトアウトポリシーはAWS Organizations向けの機能であり、SageMaker AIのトレーニングメタデータの収集停止には対応していません。
D. S3バケットに保存されたオブジェクトに対して有効期限付きの署名付きURLを生成します。署名付きURLを使用してデータにアクセスします。トレーニングジョブでSageMaker AIのOPT_OUT_TRACKING環境変数を1に設定します。
不正解 署名付きURL(Presigned URL)はHTTPSを使用してS3オブジェクトにアクセスする方法ですが、パブリックなインターネット経由でアクセスするため、プライベートIPアドレスのみを使用するという要件を満たしません。OPT_OUT_TRACKING環境変数の設定はメタデータ収集のオプトアウトとして正しいですが、プライベートIPアドレスの要件を満たせないため、全体としては不適切なソリューションです。
全体的な説明
問われている要件
- アカウントAのS3バケットからアカウントBのSageMaker AIにデータを転送してトレーニングする
- トレーニングではプライベートIPアドレスのみを使用する
- トレーニングのメタデータがAWSと共有されないようにする
- 10日間のトレーニング期間に対応するソリューションを選択する
前提知識
Amazon S3のVPCエンドポイントについて
- S3用のVPCエンドポイント(ゲートウェイ型)を使用すると、VPC内のリソースからインターネットを経由せずにS3にアクセスできる
- ゲートウェイ型エンドポイントはVPCのルートテーブルにルートを追加することで機能し、追加料金は発生しない
- エンドポイントポリシーを使用して、アクセスを特定のS3バケットやアクションに制限できる
- SageMaker AIのトレーニングジョブをVPC内で実行する場合、VPCエンドポイントを設定することでS3へのプライベートアクセスが可能になる
SageMaker AIのOPT_OUT_TRACKING環境変数について
- SageMaker AIはデフォルトでトレーニングジョブのメタデータ(使用ライブラリの統計情報やエラー情報)を収集する
- トレーニングデータ、トレーニングスクリプト、ログ、モデルの内容自体は収集されない
- OPT_OUT_TRACKING環境変数を1に設定することで、個々のトレーニングジョブのメタデータ収集を無効化できる
- この設定はトレーニングジョブごとに行う必要があり、グローバルな永続設定は存在しない
- SageMakerコンソールからジョブを作成する場合、メタデータ収集はデフォルトで無効になっている
VPCピアリングとS3アクセスについて
- VPCピアリングは2つのVPC間のプライベート通信を可能にする機能である
- S3はVPC外のリージョナルサービスであるため、VPCピアリングだけではS3へのプライベートアクセスを実現できない
- S3にプライベートにアクセスするには、VPCエンドポイントの設定が必要である
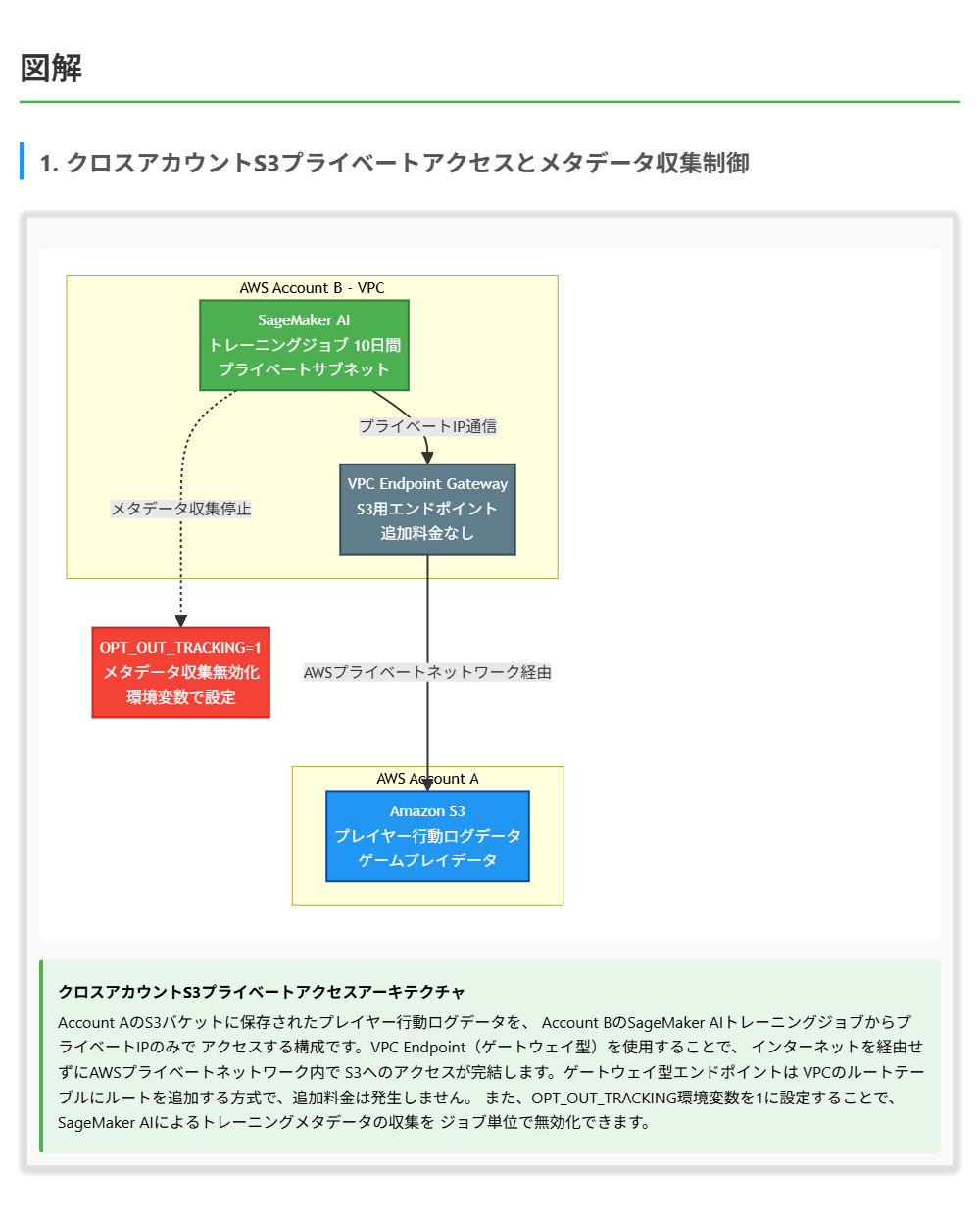
解くための考え方
この問題では「プライベートIPアドレスのみの使用」と「メタデータのAWSとの共有禁止」という2つの要件を同時に満たすソリューションを選ぶ必要があります。
まず、プライベートIPアドレスの要件について考えます。S3はVPC外のAWSマネージドサービスであるため、通常はパブリックエンドポイント経由でアクセスします。プライベートIPアドレスのみでS3にアクセスするには、VPCエンドポイント(ゲートウェイ型)を設定する必要があります。 VPCピアリングはVPC間の通信には有効ですが、S3へのプライベートアクセスには対応しません。署名付きURLはパブリックインターネット経由のアクセスとなるため、プライベートIPの要件を満たしません。
次に、メタデータ共有の禁止について考えます。SageMaker AIのトレーニングメタデータ収集を停止するには、OPT_OUT_TRACKING環境変数を1に設定します。AWSにメールで連絡する方法は正式な手段ではありません。
両方の要件を満たすのは、VPCエンドポイントの設定とOPT_OUT_TRACKING環境変数の設定を組み合わせたソリューションです。
参考資料
問題文:
ある物流会社が、複数のデータソースからAmazon SageMaker Data Wranglerにデータを取り込み、配送需要予測モデルの構築に利用しようとしています。データソースはAmazon S3、Amazon Redshift、Snowflakeです。取り込んだデータはソースシステムの最新の変更と常に同期されている必要があります。これらの要件を満たすソリューションはどれですか。
選択肢:
A. ダイレクト接続を使用してデータソースからData Wranglerにデータをインポートします。
B. カタログ接続を使用してデータソースからData Wranglerにデータをインポートします。
C. AWS Glueを使用してデータソースからデータを抽出します。AWS Glueを使用してデータをData Wranglerに直接インポートします。
D. AWS Lambdaを使用してデータソースからデータを抽出します。Lambdaを使用してデータをData Wranglerに直接インポートします。
正解:B
A. ダイレクト接続を使用してデータソースからData Wranglerにデータをインポートします。
不正解 ダイレクト接続はData Wranglerからデータソースに直接接続してデータをインポートする方法です。ダイレクト接続ではデータのスナップショットがインポート時点で取得されますが、ソースシステムの変更との自動同期機能は提供されません。データが更新されるたびに手動で再インポートする必要があり、常に最新のデータと同期されているという要件を満たせません。
B. カタログ接続を使用してデータソースからData Wranglerにデータをインポートします。
正解 カタログ接続(Cataloged Connection)はAWS Glueデータカタログを介してデータソースに接続する方法です。Glueデータカタログがデータソースのメタデータとスキーマ情報を一元管理し、データソースの変更を追跡します。 カタログ接続を使用すると、Data Wranglerはデータカタログを通じて常にソースシステムの最新のデータにアクセスでき、スキーマの変更やデータの更新が自動的に反映されます。S3、Redshift、Snowflakeのすべてに対応しています。
C. AWS Glueを使用してデータソースからデータを抽出します。AWS Glueを使用してデータをData Wranglerに直接インポートします。
不正解 AWS GlueはETL(抽出・変換・ロード)サービスとしてデータの抽出と変換に使用できますが、GlueからData Wranglerに直接データをインポートする機能は提供されていません。Data Wranglerへのデータインポートは、Data Wranglerのインポート機能を通じて行う必要があります。Glueのクローラーやジョブでデータを前処理してS3に出力し、そこからData Wranglerに取り込む間接的なワークフローは可能ですが、直接インポートは不可能です。
D. AWS Lambdaを使用してデータソースからデータを抽出します。Lambdaを使用してデータをData Wranglerに直接インポートします。
不正解 AWS Lambdaはサーバーレスのコンピューティングサービスであり、コードを実行してデータの抽出処理を行うことは可能です。しかし、LambdaからData Wranglerに直接データをインポートするAPIや統合機能は存在しません。Lambdaは最大実行時間が15分という制約もあり、大量データの抽出と転送にも適していません。Data Wranglerへのデータ取り込みはData Wrangler自身のインポート機能を使用する必要があります。
全体的な説明
問われている要件
- Amazon S3、Amazon Redshift、Snowflakeの3つのデータソースからデータを取り込む
- SageMaker Data Wranglerにデータをインポートする
- 取り込んだデータはソースシステムの最新の変更と常に同期されている必要がある
- 複数の異なるデータソースに対応する統一的なソリューションが求められている
前提知識
SageMaker Data Wranglerのデータインポート方法について
- Data Wranglerはダイレクト接続とカタログ接続の2つのインポート方法を提供する
- ダイレクト接続はデータソースへの直接的な接続であり、接続時点のデータスナップショットを取得する
- カタログ接続はAWS Glueデータカタログを介した接続であり、データカタログがソースのメタデータを管理する
- Data Wranglerは最大1,000列のデータセットをインポートできる
カタログ接続の特徴について
- カタログ接続ではAWS Glueデータカタログがデータソースのスキーマ情報やメタデータを一元管理する
- Glueデータカタログはスケジュール実行やオンデマンド実行で最新のメタデータを自動更新できる
- カタログ接続を使用すると、SQLクエリでデータカタログ、データベース、テーブルを指定してデータにアクセスする
- S3、Redshift、Snowflakeなどの複数のデータソースをGlueデータカタログで統一的に管理できる
AWS Glueデータカタログについて
- AWS Glueデータカタログはデータレイクやデータウェアハウスのメタデータを一元管理するリポジトリである
- クローラーを使用してデータソースのスキーマを自動検出し、カタログテーブルとして登録できる
- クローラーのスケジュール実行により、データソースの変更を定期的に検出して反映する
- Athena、Redshift Spectrum、EMRなど他のAWSサービスからも参照可能な統一メタデータストアとして機能する
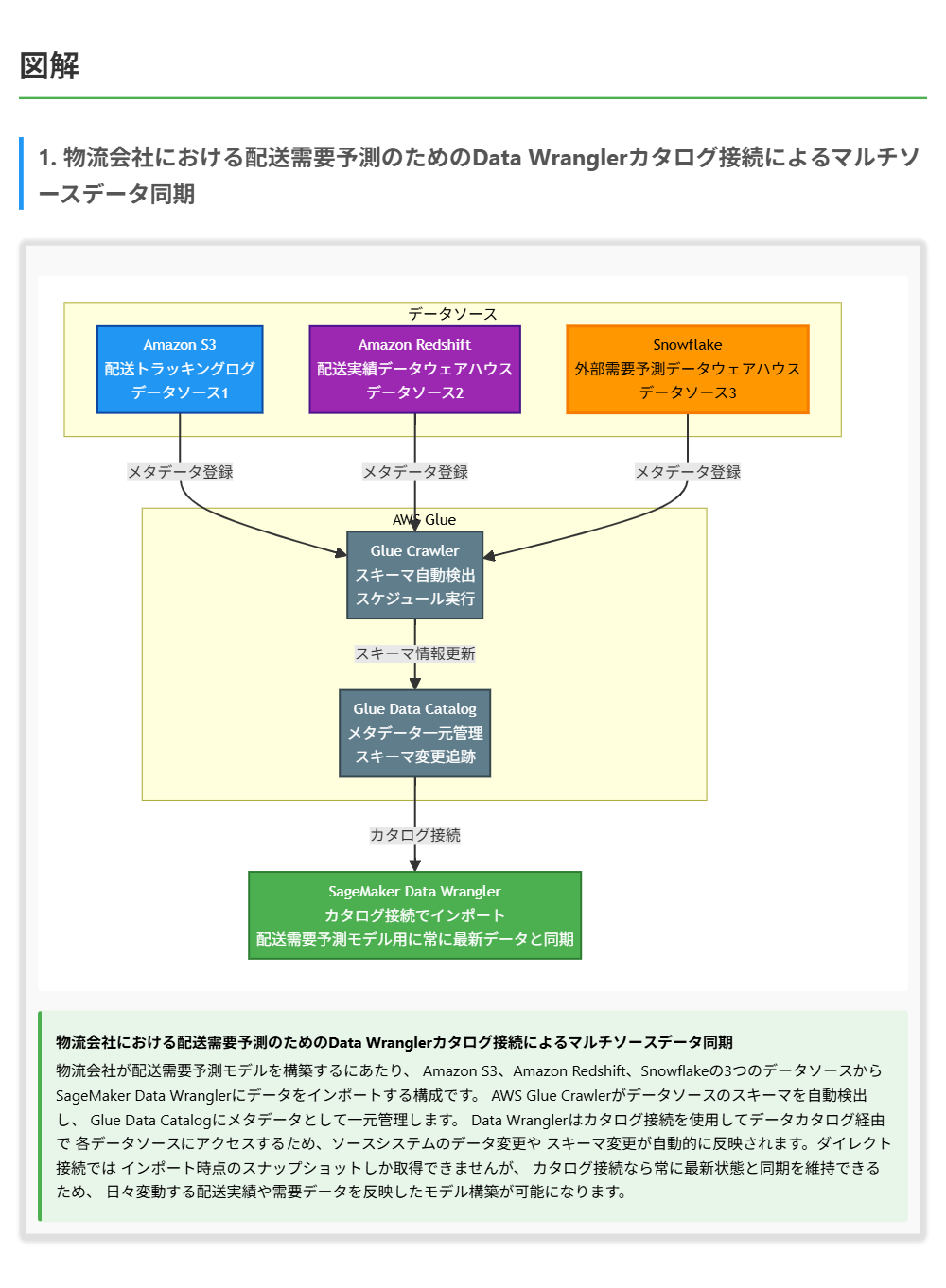
解くための考え方
この問題では、複数のデータソースからData Wranglerにデータを取り込む際に、ソースシステムの最新変更との同期を維持する方法を問われています。
重要なのは「常に最新の変更と同期」という要件です。ダイレクト接続ではインポート時点のデータを取得するだけであり、ソースの変更を自動的に追跡する仕組みがありません。 一方、カタログ接続はAWS Glueデータカタログを介してデータソースに接続するため、データカタログがソースのメタデータやスキーマの変更を追跡・管理します。これにより、Data Wranglerからデータにアクセスする際に常にソースの最新状態が反映されます。
AWS GlueやLambdaからData Wranglerに「直接インポートする」という方法は技術的に提供されていません。Data Wranglerへのデータ取り込みはData Wrangler自身のインポート機能を使う必要があります。
したがって、カタログ接続を使用してデータソースからData Wranglerにデータをインポートすることが、ソースシステムとの同期を維持しながら複数のデータソースに対応できる正しいソリューションです。
参考資料
問題文:
ある物流企業がAmazon SageMaker AIで新しい配送需要予測モデルをトレーニングするためにデータを準備しています。このデータはMLトレーニングに使用されたことがありません。データには重複が含まれており、一部の値が欠損しています。企業はデータ品質を向上させ、データ内の統計的バイアスを検出する必要があります。これらの要件を満たすソリューションはどれですか。
選択肢:
A. SageMaker Clarifyを使用してデータ品質ルールを作成します。SageMaker Model Monitorを使用してバイアスを検出します。
B. SageMaker Data Wranglerを使用してデータ品質ルールを作成します。SageMaker Clarifyを使用してバイアスを検出します。
C. SageMaker Debuggerを使用してデータ品質ルールを作成します。SageMaker Model Monitorを使用してバイアスを検出します。
D. SageMaker Model Monitorを使用してデータ品質ルールを作成します。SageMaker Clarifyを使用してバイアスを検出します。
正解:B
A. SageMaker Clarifyを使用してデータ品質ルールを作成します。SageMaker Model Monitorを使用してバイアスを検出します。
不正解 SageMaker Clarifyはバイアス検出と説明可能性に特化したサービスであり、重複や欠損値の処理といったデータ品質ルールの作成機能は提供していません。SageMaker Model Monitorはデプロイ済みモデルの品質を本番環境で継続的に監視するサービスであり、トレーニング前のデータに対するバイアス検出ツールではありません。各サービスの役割が入れ替わっているため、この組み合わせは要件を満たしません。
B. SageMaker Data Wranglerを使用してデータ品質ルールを作成します。SageMaker Clarifyを使用してバイアスを検出します。
正解 SageMaker Data Wranglerはデータ準備に特化したサービスであり、重複の削除、欠損値の処理、異常値の検出などのデータ品質検証機能を提供しています。自動的にデータ品質レポートを生成し、問題点を可視化できます。SageMaker Clarifyはトレーニング前のデータにおける統計的バイアスを検出する機能を備えており、クラスの不均衡や特定の属性に対する偏りを特定できます。この2つのサービスの組み合わせが要件に最も適しています。
C. SageMaker Debuggerを使用してデータ品質ルールを作成します。SageMaker Model Monitorを使用してバイアスを検出します。
不正解 SageMaker Debuggerはモデルのトレーニングプロセスをデバッグするためのツールであり、勾配消失やオーバーフィッティングなどのトレーニング上の問題を検出します。トレーニング前のデータ品質ルールの作成には使用できません。SageMaker Model Monitorは本番環境にデプロイされたモデルの継続的な監視を行うサービスであり、トレーニング前のデータに対するバイアス検出には適していません。
D. SageMaker Model Monitorを使用してデータ品質ルールを作成します。SageMaker Clarifyを使用してバイアスを検出します。
不正解 SageMaker Model Monitorはデプロイ済みのモデルエンドポイントに送信されるデータの品質を監視するサービスです。本番環境でのデータドリフトや品質劣化を検出する機能を提供しますが、トレーニング前のデータ準備段階での品質ルール作成や、重複・欠損値の処理には使用できません。バイアス検出にSageMaker Clarifyを使用する点は正しいですが、データ品質の部分が要件を満たしていません。
全体的な説明
問われている要件
- 新しい配送需要予測モデルのトレーニング用データを準備する
- データには重複と欠損値が存在する
- データ品質を向上させる必要がある
- データ内の統計的バイアスを検出する必要がある
- トレーニング前の段階で上記を実施する
前提知識
SageMaker Data Wranglerについて
- データの準備と前処理に特化したビジュアルツールである
- データのインポート、変換、分析、エクスポートを一つのインターフェイスで実行できる
- データ品質とインサイトレポートを自動生成し、欠損値、重複行、データ型の問題を検出する
- 300以上の組み込み変換機能を提供し、重複の削除、欠損値の補完、特徴量エンジニアリングなどを行える
- 外れ値、クラスの不均衡、データリークなどの異常も検出できる
SageMaker Clarifyについて
- バイアス検出とモデルの説明可能性に特化したサービスである
- トレーニング前バイアス(Pre-training Bias)とトレーニング後バイアス(Post-training Bias)の両方を検出できる
- クラスの不均衡(CI)、ラベルの不均衡(DPL)など複数のバイアスメトリクスを提供する
- SHAP値を用いた特徴量の重要度分析や部分依存プロットによるモデル説明機能も備える
- 本番環境でのバイアスドリフトの監視にも対応する
SageMaker Model Monitorについて
- デプロイ済みモデルのエンドポイントを継続的に監視するサービスである
- データ品質監視、モデル品質監視、バイアスドリフト監視、特徴量属性ドリフト監視の4種類を提供する
- 本番環境で入力データの分布変化(データドリフト)やモデル精度の劣化を検出する
- トレーニング前のデータ準備には使用しない
SageMaker Debuggerについて
- モデルのトレーニングプロセスをリアルタイムで監視・デバッグするツールである
- 勾配消失、勾配爆発、オーバーフィッティングなどのトレーニング上の問題を検出する
- システムリソースの使用率(CPU、GPU、メモリ)も監視できる
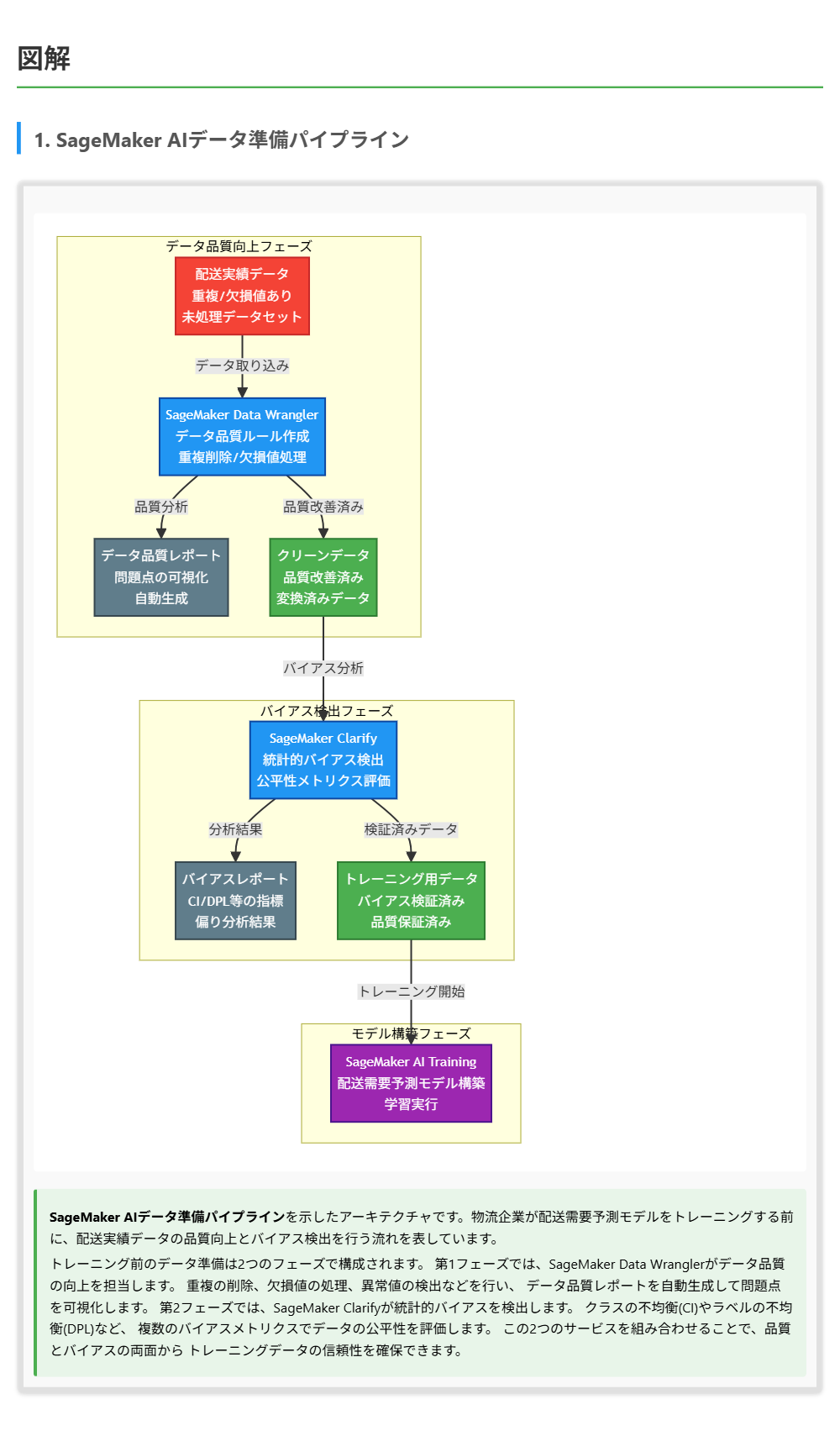
解くための考え方
この問題では「データ品質の向上」と「統計的バイアスの検出」という2つの要件を満たすサービスの組み合わせを選択する必要があります。
データ品質の向上について考えると、問題文にはデータに重複と欠損値があると記載されています。これらを処理してデータ品質を改善するには、データ準備に特化したツールが必要です。 SageMaker Data Wranglerはまさにこの目的のために設計されており、データ品質レポートの自動生成、重複の検出と削除、欠損値の処理などの機能を提供しています。
統計的バイアスの検出については、SageMaker Clarifyがトレーニング前のデータにおけるバイアスを検出する機能を備えています。特定の属性に対する偏りやクラスの不均衡など、公平性に関わる問題を複数のメトリクスで評価できます。
SageMaker Model Monitorは本番環境のモデル監視に特化しており、トレーニング前のデータ準備には適していません。 SageMaker Debuggerはトレーニングプロセスのデバッグに特化しており、データ品質の管理には使用できません。
したがって、Data Wranglerでデータ品質を向上させ、Clarifyでバイアスを検出するという組み合わせが最適です。
参考資料
問題文:
ある総合病院がMLモデルを使用して患者があるがんに罹患しているかどうかをスクリーニング検査で予測しています。この病院はできるだけ多くのがん患者を発見する必要があります。この要件を満たすためにモデルを評価するにはどの評価メトリクスを使用すべきですか。
選択肢:
A. F1スコア
B. ROC曲線下面積(AUC)
C. 適合率
D. 再現率
正解:D
A. F1スコア
不正解 F1スコアは適合率と再現率の調和平均であり、両者のバランスを取る指標です。適合率と再現率の両方を考慮するため、どちらか一方に偏った最適化には向いていません。今回の要件は「できるだけ多くのがん患者を発見する」ことであり、がんの見逃しを最小化することが最優先です。F1スコアでは再現率の最大化に焦点を当てた評価ができません。
B. ROC曲線下面積(AUC)
不正解 AUCはモデルの全体的な分類性能を評価する指標で、すべての閾値における真陽性率と偽陽性率のトレードオフを総合的に示します。AUCはモデル間の性能比較に有用ですが、特定の閾値での検出性能を直接測定するものではありません。「できるだけ多くのがん患者を発見する」という具体的な要件に対しては、がんの検出率を直接評価できる指標が適切です。
C. 適合率
不正解 適合率(Precision)は、モデルががんと予測した患者のうち実際にがんだった割合を示す指標です。適合率が高いということは誤検知(健康な患者をがんと判定すること)が少ないことを意味します。しかし、適合率を重視すると見逃し(実際のがん患者を検出できないこと)が増える傾向があります。今回の要件はがんの見逃しを最小化することであり、適合率ではこの目標を評価できません。
D. 再現率
正解 再現率(Recall)は、実際にがんに罹患している患者のうちモデルが正しくがんと予測できた割合を示す指標です。計算式はTP÷(TP+FN)であり、偽陰性(見逃し)を最小化することに焦点を当てています。「できるだけ多くのがん患者を発見する」という要件は、がんの見逃しを最小限に抑えることを意味するため、再現率が最も適切な評価メトリクスです。
全体的な説明
問われている要件
- MLモデルでがんの罹患を予測している
- できるだけ多くのがん患者を発見する必要がある
- この目標に適した評価メトリクスを選択する
- がんの見逃しを最小化することが最優先事項である
前提知識
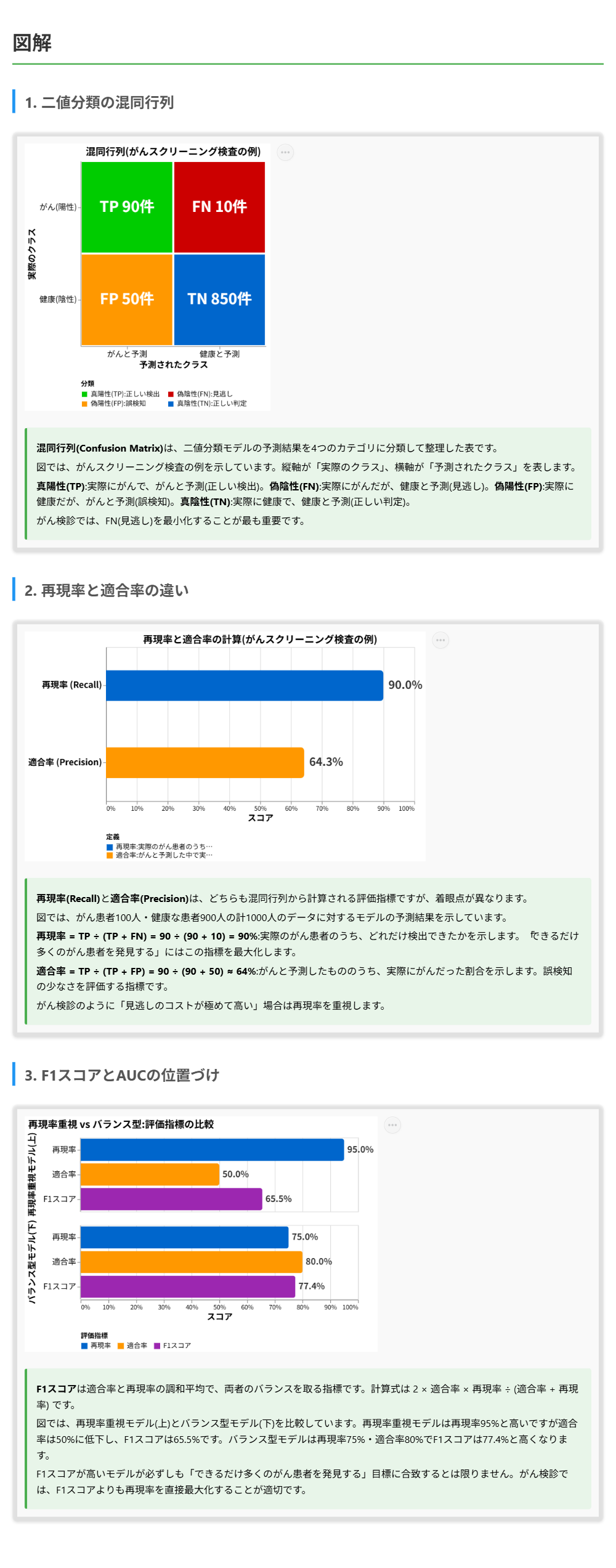
二値分類の混同行列について
- 二値分類モデルの予測結果は、真陽性(TP)、偽陽性(FP)、真陰性(TN)、偽陰性(FN)の4つに分類される
- 真陽性は実際にがんで、がんと予測した件数、偽陰性は実際にがんだが健康と予測した(見逃した)件数を表す
- がん検診においては、偽陰性(見逃し)を減らすことが特に重要である
再現率(Recall)について
- 再現率はTP÷(TP+FN)で計算され、実際の陽性クラスのうち正しく検出できた割合を示す
- 例えば、100人のがん患者のうち95人を検出できれば再現率は95%となる
- 再現率が高いほど見逃しが少ないことを意味し、不正検知や疾病診断など見逃しのコストが非常に高い場面で重視される
- 身近な例では、空港のセキュリティ検査は再現率を重視している。危険物の持ち込みを1件でも見逃すと大事故になるため、誤検知で無害な荷物を再検査するコストを許容してでも見逃しを最小化する
適合率(Precision)について
- 適合率はTP÷(TP+FP)で計算され、陽性と予測した件数のうち実際に陽性だった割合を示す
- 適合率が高いほど誤検知が少ないことを意味する
- スパムフィルタなど誤検知のコストが高い場面で重視される。重要なメールをスパムと誤判定すると業務に支障が出るためである
F1スコアとAUCについて
- F1スコアは適合率と再現率の調和平均であり、2×適合率×再現率÷(適合率+再現率)で計算される
- 適合率と再現率のバランスを取りたい場合に使用する
- AUCはROC曲線の下の面積で、モデルの全体的な分類性能を0から1の範囲で評価する指標である
- AUCは閾値に依存しないモデル全体の性能評価に使用される
解くための考え方
この問題では、がん患者をできるだけ多く発見するために適切な評価メトリクスを問われています。
「できるだけ多くのがん患者を発見する」とは、実際のがん患者の中から漏れなくすべてを検出することを意味します。例えば、病院で100人のがん患者がいた場合、そのうち何人を正しく検出できたかという割合を最大化したいということです。 この「実際の陽性サンプルに対する検出率」を直接測定するのが再現率(Recall)です。
再現率の計算式はTP÷(TP+FN)です。TPは正しくがんと判定した数、FNは見逃したがん患者の数です。再現率を最大化するということは、FN(見逃し)をゼロに近づけることを意味します。
適合率は「がんと予測した中で本当にがんだった割合」を測る指標です。適合率を重視すると、確実にがんと判断できるものだけを検出するようになり、結果としてがん患者の見逃しが増えます。 F1スコアは適合率と再現率のバランスを取る指標であり、一方を犠牲にして他方を最大化するような場面には適していません。 AUCはモデルの全体的な性能を示す指標であり、「できるだけ多くのがん患者を発見する」という具体的な要件に焦点を当てた評価には向いていません。
がん検診では、1人の見逃しが患者の生命に関わる重大な結果につながるため、再現率を最重視することが適切です。
参考資料
問題文:
MLエンジニアが物流会社でAmazon SageMaker AIを使用して配送遅延予測モデルをトレーニングしました。MLエンジニアは、モデルが過学習しており、トレーニングデータに不要な特徴量が含まれていることを確認しました。MLエンジニアは過学習を軽減し、不要な特徴量の影響を低減する必要があります。この要件を満たすソリューションはどれですか。
選択肢:
A. トレーニングの反復回数を増やします。モデルを再トレーニングします。
B. トレーニングデータにL1正則化を適用します。モデルを再トレーニングします。
C. トレーニングの反復回数を減らします。モデルを再トレーニングします。
D. SageMaker Debuggerを使用して実行中のモデルにL1正則化を適用します。
正解:B
A. トレーニングの反復回数を増やします。モデルを再トレーニングします。
不正解 トレーニングの反復回数(エポック数)を増やすと、モデルはトレーニングデータのパターンをさらに深く学習します。過学習はモデルがトレーニングデータに過度に適合している状態であるため、反復回数を増やすと過学習がさらに悪化します。また、反復回数の増加は不要な特徴量の影響を低減する機能を持ちません。過学習を軽減するには、モデルの複雑さを制限する正則化手法や特徴量選択が必要です。
B. トレーニングデータにL1正則化を適用します。モデルを再トレーニングします。
正解 L1正則化(Lasso正則化)は、損失関数にモデルの重みの絶対値の合計をペナルティとして加えることで、不要な特徴量の重みを正確にゼロに縮小します。これにより自動的に特徴量選択が行われ、モデルの複雑さが低減されます。 例えば、配送遅延を予測するモデルで「配送伝票番号の下1桁」のような無関係な特徴量があった場合、L1正則化はその特徴量の重みをゼロにして無視します。SageMaker AIの組み込みアルゴリズム(Linear Learnerなど)ではハイパーパラメータとしてL1正則化を設定できます。
C. トレーニングの反復回数を減らします。モデルを再トレーニングします。
不正解 トレーニングの反復回数を減らすこと(早期停止に近い手法)は、過学習の軽減に一定の効果があります。しかし、反復回数を減らすだけでは不要な特徴量の影響を低減することはできません。モデルは依然として不要な特徴量を使用して学習するため、特徴量選択の問題は解決されません。問題の要件は過学習の軽減と不要な特徴量の影響低減の両方を求めています。
D. SageMaker Debuggerを使用して実行中のモデルにL1正則化を適用します。
不正解 SageMaker Debuggerはトレーニングジョブの監視とデバッグのためのツールです。テンソルの値やリソース使用率などのメトリクスを収集・分析し、トレーニングの問題(勾配消失、過学習の兆候など)を検出する機能を提供します。しかし、Debuggerはあくまで監視・診断ツールであり、L1正則化のようなモデルのトレーニングパラメータを変更する機能は持ちません。正則化はトレーニングの設定段階で適用する必要があります。
全体的な説明
問われている要件
- モデルが過学習しており、トレーニングデータに不要な特徴量が含まれている
- 過学習を軽減する必要がある
- 不要な特徴量の影響を低減する必要がある
- 上記の両方の要件を同時に満たすソリューションを選択する
前提知識
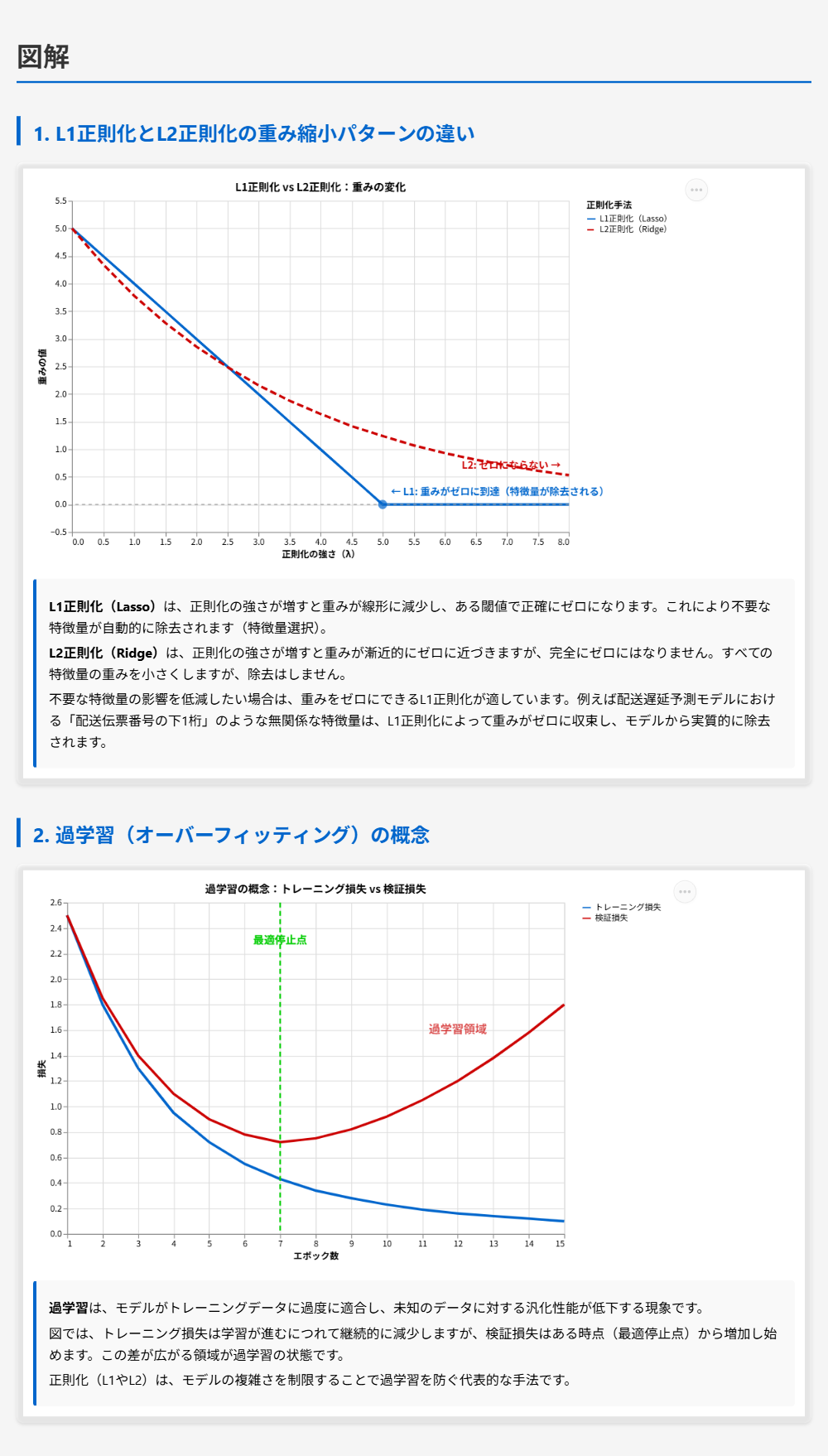
L1正則化(Lasso)とL2正則化(Ridge)の違いについて
- L1正則化は損失関数に重みの絶対値の合計(L1ノルム)をペナルティとして加える手法である
- L1正則化は不要な特徴量の重みを正確にゼロに縮小するため、自動的な特徴量選択として機能する
- L2正則化は重みの二乗の合計(L2ノルム)をペナルティとして加える手法で、重みを小さくするが完全にゼロにはしない
- 不要な特徴量の除去が必要な場合はL1正則化が適している
過学習(オーバーフィッティング)について
- 過学習はモデルがトレーニングデータに過度に適合し、未知のデータに対する汎化性能が低下する現象である
- 対策にはデータ量の増加、正則化、ドロップアウト、早期停止、特徴量選択などがある
- 正則化はモデルの複雑さを制限することで過学習を防ぐ手法である
SageMaker Debuggerについて
- SageMaker Debuggerはトレーニングジョブのリアルタイム監視ツールである
- テンソル値、リソース使用率、モデルパラメータの変化などを追跡できる
- ルールベースの検出により、勾配消失やオーバーフィッティングの兆候を自動検知する
- 監視と診断が目的であり、モデルのトレーニングパラメータの変更機能は提供しない
解くための考え方
この問題では「過学習の軽減」と「不要な特徴量の影響低減」という2つの要件を同時に満たす手法が求められています。
L1正則化(Lasso正則化)は、損失関数にペナルティ項を加えることでモデルの複雑さを制限し、過学習を防ぎます。さらにL1正則化の特徴として、不要な特徴量の重みを正確にゼロに収束させるため、実質的な特徴量選択が自動で行われます。 これは買い物に例えると、予算制限(ペナルティ)をかけることで本当に必要なもの(重要な特徴量)だけにお金を使い、不要なもの(不要な特徴量)にはお金を一切使わないようにする仕組みです。
トレーニングの反復回数を増やすと過学習が悪化し、減らすと早期停止的な効果はありますが特徴量選択はできません。 SageMaker Debuggerはトレーニングの監視ツールであり、正則化を適用する機能はありません。
したがって、L1正則化を適用してモデルを再トレーニングすることが、過学習の軽減と不要な特徴量の影響低減を同時に実現する正しいソリューションです。
参考資料
スポンサーリンク
以下スポンサーリンクです。
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。