
運用中のシステムで、Lambdaがエラーになっているのに、CloudWatchアラームが発報されなくて困ったことはありませんか?
私自身、数ヶ月前のある日、通常のシステム運用作業中にたまたまLambdaのエラーログを発見したことがきっかけでした。よく見ると、その関数は異常終了していました。
「おかしい。LambdaのErrorsメトリクスに対してCloudWatchアラームを設定してあるはず。エラーがあれば監視チームにアラートメールが飛ぶはずなのに、なぜ誰も気づかなかったのか?」
かなりの時間をかけてAWSドキュメントを調査した結果、見落としていたLambdaメトリクスの仕様にたどり着きました。同じ問題で悩んでいる人の助けになればと思い、この記事にまとめます。
発生した事象
状況
- Lambda関数でエラーが発生(異常終了)
-
Errorsメトリクスを監視するCloudWatchアラームを設定済み - しきい値超えにもかかわらず、アラートメールが送信されなかった
- 事後にCloudWatchコンソールで確認すると、該当時間帯にErrors=3が記録されていた
Lambdaの実行ログ
START RequestId: a3f291bc-4e17-48c2-9d1a-7b3e85f21c04 09:32:15
[ERROR] WaiterError: Waiter InstanceStatusOk failed: Max attempts exceeded
END RequestId: a3f291bc-4e17-48c2-9d1a-7b3e85f21c04 09:41:47
REPORT RequestId: a3f291bc-4e17-48c2-9d1a-7b3e85f21c04 Duration: 572431.18 ms Billed Duration: 572432 ms Memory Size: 512 MB Max Memory Used: 88 MBポイントは Duration が約572秒(約9分32秒) という点です。関数が呼び出されてからエラーが発生するまでに、約9分半の時間差があります。
原因:LambdaのErrorsメトリクスのタイムスタンプ仕様
CloudWatchアラームが検知しない根本原因
ここが今回の核心です。AWSの公式ドキュメントには以下のように記載されています。
エラーメトリクスのタイムスタンプは、エラーが発生した時点ではなく、関数が呼び出された時間を反映していることに注意してください。
つまり Errors メトリクスのタイムスタンプは、エラーが起きた時刻ではなく、Lambdaが呼び出された時刻になります。多くのエンジニアが「エラーが起きた時刻に記録される」と思い込んでいるため、CloudWatchアラーム 検知しないという問題の見落としにつながります。
今回のタイムラインで整理する
09:32:15 Lambda 呼び出し
↓ ← Errorsメトリクスのタイムスタンプはここ(09:32のバケット)
EC2 の InstanceStatusOk を約9分半ポーリング
↓
09:41:47 WaiterError 発生(エラー)
↓ ← 実際にエラーが起きた時刻アラームの設定が「期間:1分 / データポイント:1/1」の場合、アラームは常に直近1分間のデータのみ評価します。
| 時刻 | メトリクスの状態 | アラームの動き |
|---|---|---|
| 09:32〜09:33 | Errors=3 が記録(呼び出し時刻) | 評価時は値なし |
| 09:41〜09:42 | 値なし(エラー発生時刻付近) | 評価 → 値なし → 発報されない |
エラーが発生する09:41ごろにアラームが評価を行った際、Errors=3 のデータは 09:32のバケットにあり、評価ウィンドウの外に出ていました。結果として、アラームはしきい値超えを検知できませんでした。
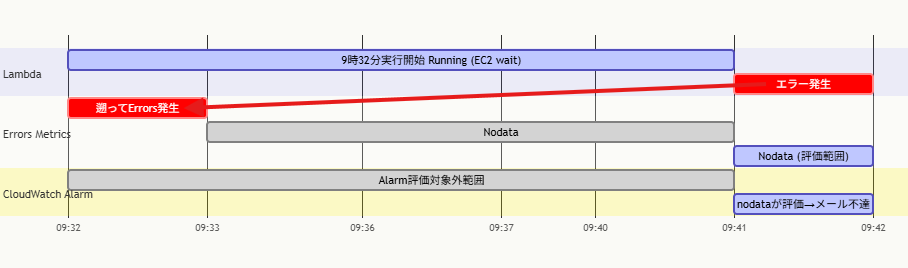
なぜ後からメトリクスを見ると値があるのか
CloudWatchコンソールで「期間:1時間 / 統計:合計」で確認すると、09:32のデータポイントも集計されるためErrors=3が見えます。しかしアラームは1分単位の直近ウィンドウしか評価していないため、「メトリクスはある、でもアラームは鳴らなかった」という一見矛盾した状態が発生します。
根本原因:Lambda側のエラー内容
今回のエラーの正体は WaiterError: Waiter InstanceStatusOk failed: Max attempts exceeded でした。
# 該当コード(抜粋)
waiter = ec2_client.get_waiter('instance_status_ok')
waiter.wait(InstanceIds=[instance_id])boto3 の InstanceStatusOk ウェイターはデフォルトで 40回 × 15秒間隔 = 最大10分 ポーリングします。対象のEC2インスタンスが期待どおりの状態にならなかったため、上限近くまで待ち続けてからエラーになりました。
この「呼び出しからエラー発生まで約9分半」という処理時間が、CloudWatchアラームの評価期間(1分)を大幅に上回っていたことが、Lambda エラー 検知されない直接的な要因です。
対策
対策① CloudWatchアラームの評価期間を延ばす(最重要)
Lambda関数のタイムアウト設定時間を基準に、アラームの評価期間を設定するのがポイントです。
ルール:アラームの評価期間 ≥ Lambdaのタイムアウト時間
| 設定項目 | 変更前 | 変更後(例) |
|---|---|---|
| 期間(Period) | 1分 | 10分 |
| データポイント数(Datapoints to Alarm) | 1/1 | 1/10 |
| しきい値 | 1以上 | 1以上(変更なし) |
CloudWatch コンソールでの設定例:
期間: 600秒(10分)
統計: 合計(Sum)
しきい値タイプ: 静的
条件: 1 以上
評価期間: 10対策② boto3ウェイターの待機時間を短縮する
ウェイターの最大待機時間を短くすることで、エラー発生までの時間を予測しやすくなります。
import boto3
waiter = ec2_client.get_waiter('instance_status_ok')
waiter.wait(
InstanceIds=[instance_id],
WaiterConfig={
'Delay': 15, # ポーリング間隔(秒)
'MaxAttempts': 10 # 最大試行回数 → 最大2分30秒
}
)待機時間を短くすることで、アラームの評価期間とのズレも小さくなります。
対策③ Lambdaのタイムアウト設定を見直す
処理時間が長い関数は、Lambda関数のタイムアウト値も明示的に設定し、タイムアウト時間 ≒ アラームの評価期間になるよう合わせることを意識しましょう。これにより「呼び出し〜エラーまでの最大時間」が予測しやすくなります。
まとめ
| 項目 | 内容 |
|---|---|
| 原因 |
Errorsメトリクスのタイムスタンプ=呼び出し時刻(エラー発生時刻ではない) |
| 発生条件 | 呼び出しからエラー発生までの時間 > アラームの評価期間 |
| 対策① | アラームの評価期間をLambdaタイムアウト以上に設定する |
| 対策② | boto3ウェイターのMaxAttemptsを小さくして待機時間を短縮する |
| 対策③ | Lambdaタイムアウト設定を明示し、アラーム期間と合わせる |
CloudWatchのアラーム設定では「評価期間を短くするほど検知が速くなる」と思いがちですが、Lambda Errorsメトリクスに関しては処理時間が長いほど評価期間も長く設定する必要があるという、直感に反する設計が求められます。
今回の私のケースは数ヶ月後にたまたま発覚しましたが、これはシステムの信頼性に関わる重大な見落としです。CloudWatchアラーム 設定 が完了していても、Lambda関数の実行時間とアラームの評価期間のバランスを必ず確認するようにしましょう。
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。
参考リンク
- 呼び出しメトリクス | Lambda 関数のメトリクスのタイプ – AWS Lambda
- Amazon CloudWatch アラームの作成 – Amazon CloudWatch
- Waiters – boto3 documentation

システムエンジニア
AWSを中心としたクラウド案件に携わっています。
IoTシステムのバックエンド開発、Datadogを用いた監視開発など経験があります。
IT資格マニアでいろいろ取得しています。
AWS認定:SAP, DOP, SAA, DVA, SOA, CLF
Azure認定:AZ-104, AZ-300
ITIL Foundation
Oracle Master Bronze (DBA)
Oracle Master Silver (SQL)
Oracle Java Silver SE
■略歴
理系の大学院を卒業
IT企業に就職
AWSのシステム導入のプロジェクトを担当