当ブログにはPRを含みます。
AWS の認定資格 Machine Learning Engineer Associate (MLA-C01)という資格に合格したため試験概要や勉強方法について紹介します。
※MLA-C01はAIF(AI Practitioner)の上位試験です。AIF(AI Practitioner)については以下の記事をご参考ください。
- AWSのAI/ML系サービスはほぼ未経験
- しいて言うならcodewhispererを少し触ったことがある程度
- IT企業でAWSプロジェクトマネジメント経験あり
- ただしプロジェクトではAIサービスを使っていない
- SAAを取得しており、AI以外の基本的なAWSの知識はあった
筆者は約1ヶ月(2時間×30日)学習し、820点で合格することができました。試験範囲が重複している個所もあったのでAIF(AI Practitioner)と一緒に受験しました。SAAを取得していてもSageMakerなどのAI関連サービスはしっかり勉強しました。
「MLAの機械学習用語やAWS構成イメージが湧かない」
そんな悩みを解決する問題集
本問題集の特徴:
✓ 解説にAWSアーキテクチャ図を掲載
✓ 機械学習の概念を図解で説明
✓ AWS・機械学習の両方を初心者向けに解説
✓ 公式ドキュメントへの参照リンク付き
Udemy評価4.4の講師が作成
講師クーポン【図解付き詳細解説】AWS MLA-C01完全攻略問題集 | 構成図&グラフ解説付き

Machine Learning Engineer Associate(MLA)の概要
Machine Learning Engineer Associate(MLA)は中級レベルのAWS認定資格です。
| 資格名 | AWS Certified Machine Learning Engineer Associate |
| 試験時間 | 130分 |
| 出題形式 | 選択問題、並び替え |
| 言語 | 英語、日本語、韓国語、中国語 (簡体字) |
| 問題数 | 65問 |
| 合格ライン | 720点/1000点 |
| 試験日 | 随時 |
| 試験場所 |
全国のピアソンテストセンター または 試験監督付きオンライン受験 |
| 受験料 | 20,000 円 |
| 受験要件 | なし |
Machine Learning Engineer Associate(MLA)出題範囲、サービス
MLAではデータの取り込みや変換、MLモデルの開発とチューニング、CI/CDパイプラインの構築、セキュリティやコストの最適化、モデルのモニタリングと保守に関するスキルが問われます。特にAWSのSageMakerや関連サービスについて多く出題されます。
試験範囲は以下となっています。※詳細な試験範囲は公式試験ガイドをご覧ください。
- 第 1 分野: 機械学習 (ML) のためのデータ準備 (採点対象コンテンツの 28%)
- 第 2 分野: ML モデルの開発 (採点対象コンテンツの 26%)
- 第 3 分野: ML ワークフローのデプロイとオーケストレーション (採点対象コンテンツの 22%)
- 第 4 分野: ML ソリューションのモニタリング、保守、セキュリティ (採点対象コンテンツの 24%)
出題される主なAWSサービスは以下の通りです。特にSageMakerについては深く理解しておきましょう。
- 分析: Athena, Kinesis, Glue, Redshift
- コンピューティング: EC2, Lambda, Batch
- コンテナ: ECR, ECS, EKS
- データベース: DynamoDB, RDS, ElastiCache
- 機械学習: SageMaker, Rekognition, Polly, Translate, Textract
- その他: S3, CloudFormation, CloudWatch
難易度(例題付き)
MLAはAssociate(中級)レベルにしては難しいと感じました。普段馴染みのないサービスが出題されるうえに、学習教材が少なかったためです。SAAやSAPを取得していても対策が必要だと思います。
- 1年以上のAmazon SageMakerなどAWSサービスを利用したMLエンジニアリング経験を推奨
試験問題はSAAなどの一般的なAWS知識で解ける問題と機械学習に精通していないと解けない問題の2種類があるように感じました。以下、Machine Learning Engineer Associate(MLA)のサンプル問題です。正解を確認する場合▼を押下してください。
ある企業は、ML モデルの作成を ML スタートアップ企業に委託したいと考えています。同社は、現在 Amazon S3 に保存されているトレーニング データをスタートアップ企業に提供することを計画しています。スタートアップ企業はすでに、AWS アカウント内で Amazon S3 をストレージ ソリューションとして使用しています。データへのアクセスは、プログラムと AWS マネジメント コンソールの両方から行う必要があります。
これらの要件を満たすソリューションはどれでしょうか?
A. ML スタートアップの AWS アカウントにリソースベースのバケットポリシーを作成します。
B. 会社の AWS アカウントにロールを作成します。ML スタートアップの AWS アカウントからこのIAM ロールを引き受けます。
C. 会社のアカウントに AWS Organizations を設定し、組織内の既存の組織単位(OU)にML スタートアップのアカウントを追加します。
D. 会社の AWS アカウントにACL を作成します。
正解:B
解説:S3へのアクセス許可を与えたIAMポリシーをアタッチしたIAMロールを作成して信頼関係を設定してクロスアカウントを実現できます。
ある会社では、本番環境で ML モデルを管理しています。モデルのパフォーマンスに影響を与えずに、モデルの品質を向上させる必要があります。さらに、追加のデータを使用してモデルを再トレーニングしたいと考えています。
最も少ない開発労力でこれらの要件を満たすソリューションはどれでしょうか?
A. Amazon QuickSight を使用してモデルの予測を行います。予測結果に基づいてモデルを再トレーニングします。
B. Amazon SageMaker モデルレジストリを使用して新しいデータを収集します。新しいデータを再トレーニングに使用します。
C. Amazon SageMaker Experiments を使用して新しいデータを収集します。新しいデータを使用してモデルを再トレーニングします。
D. Amazon SageMaker Model Monitor を使用します。エンドポイントでデータキャプチャを有効にし、そのデータをモデルの再トレーニングに使用します。
正解:D
Amazon SageMaker Model Monitor を使用します。エンドポイントでデータキャプチャを有効にし、そのデータをモデルの再トレーニングに使用します。
解説:Amazon SageMaker Model Monitor は、デプロイされた ML モデルを監視し、リアルタイムでのデータキャプチャを行い、そのデータを使用してモデルのパフォーマンスを監視および評価します。さらに、モデルの予測に使用された入力データを保存して、新しいデータでモデルを再トレーニングすることができます。これにより、モデルの品質を維持しながら、追加データを活用して効率的に再トレーニングを行うことが可能です。
他の選択肢について:
- A: Amazon QuickSight はデータの可視化ツールであり、モデルの予測には向いていますが、再トレーニングのプロセスをサポートするものではありません。
- B: SageMaker モデルレジストリはモデルのバージョン管理を行いますが、データ収集や再トレーニングには直接関与しません。
- C: SageMaker Experiments は実験の追跡と管理を行うためのツールであり、データ収集そのものを担うものではありません。
AWS AI/ML系3資格(AIF MLA MLS)の比較
MLA(Machine Learning Engineer Associate)とAIF(AI Practitioner)の登場によりAI/ML系のAWS認定は3資格となりました。それぞれの違いが以下AWS公式ブログに書かれていたので要約して紹介します。AI/ML系資格の松竹梅という感じで紹介されていました。
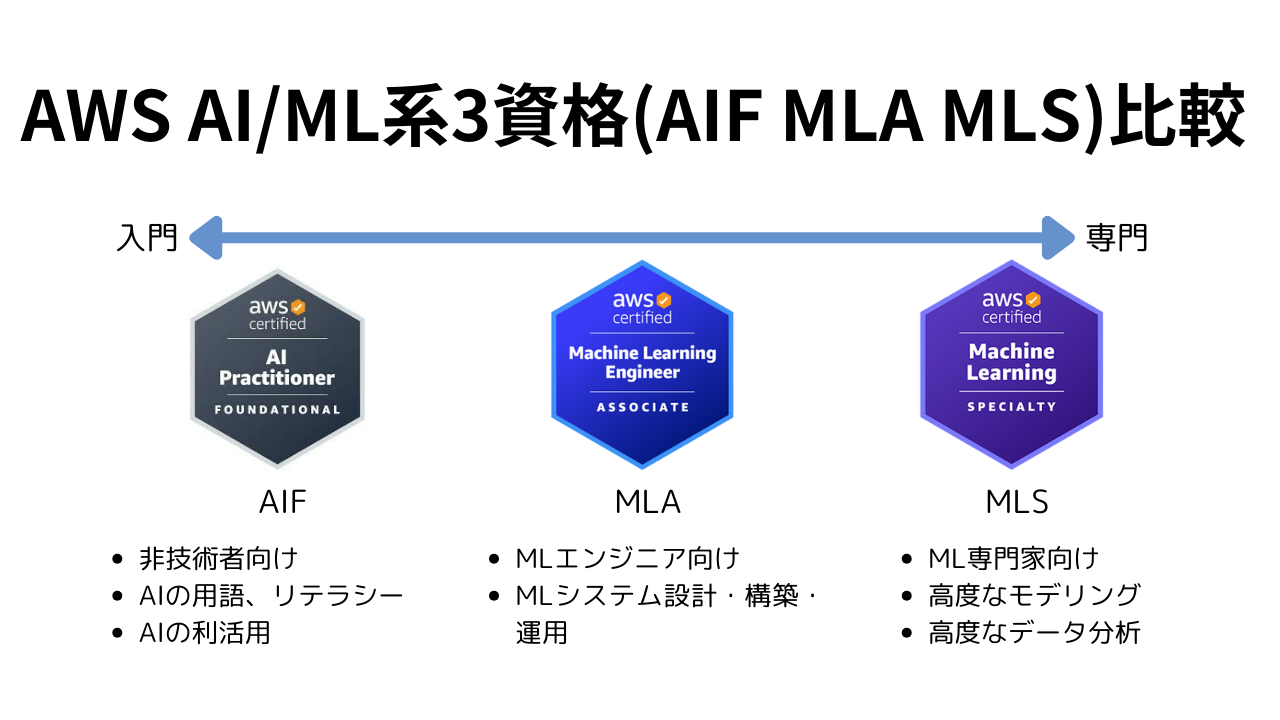
- AI Practitionerは非技術者向けで、ビジネス視点でのAI活用について問われます。
- Machine Learning Engineer Associateは技術的なMLエンジニア向けで、MLシステムの設計・運用に関する実務スキルについて問われます。
- Machine Learning Specialtyは、MLの専門家向けで、より高度なモデリングとデータ分析のスキルが求められます。
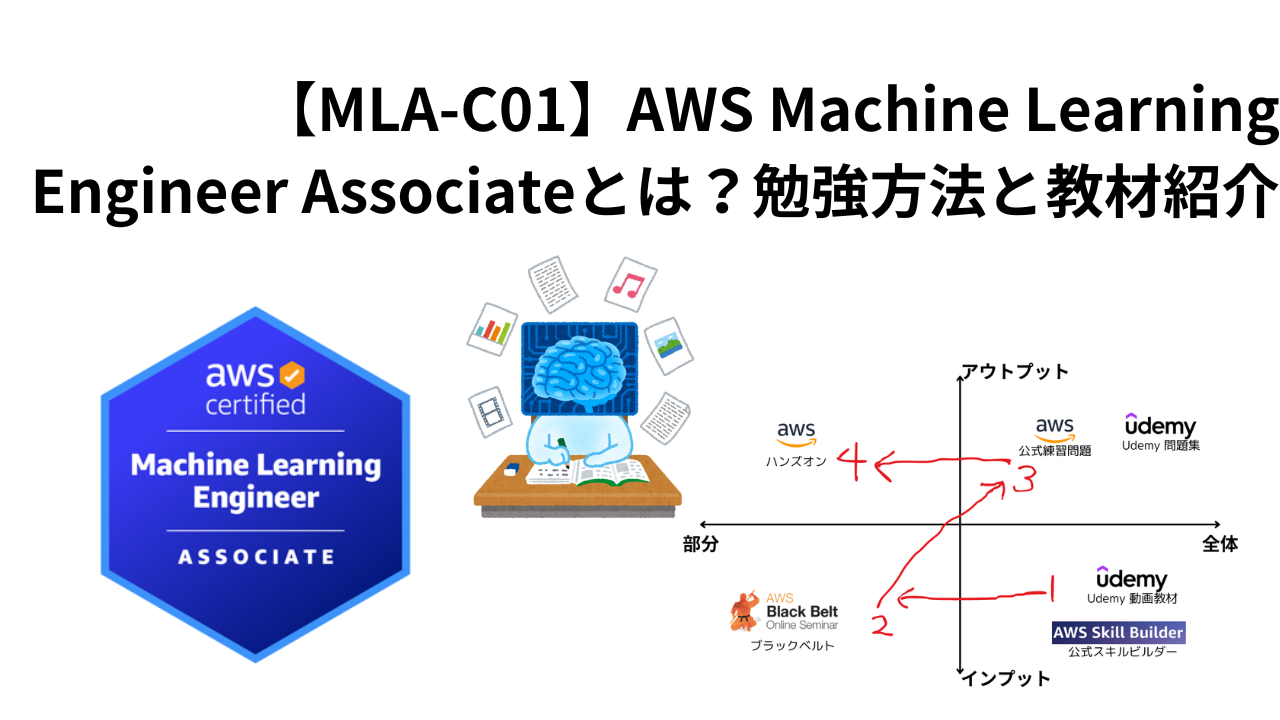
Machine Learning Engineer Associate(MLA)勉強方法と教材
Machine Learning Engineer Associate(MLA)は新しい資格試験であるため、教材の数が限られています。教材とともに学習方法を紹介します。
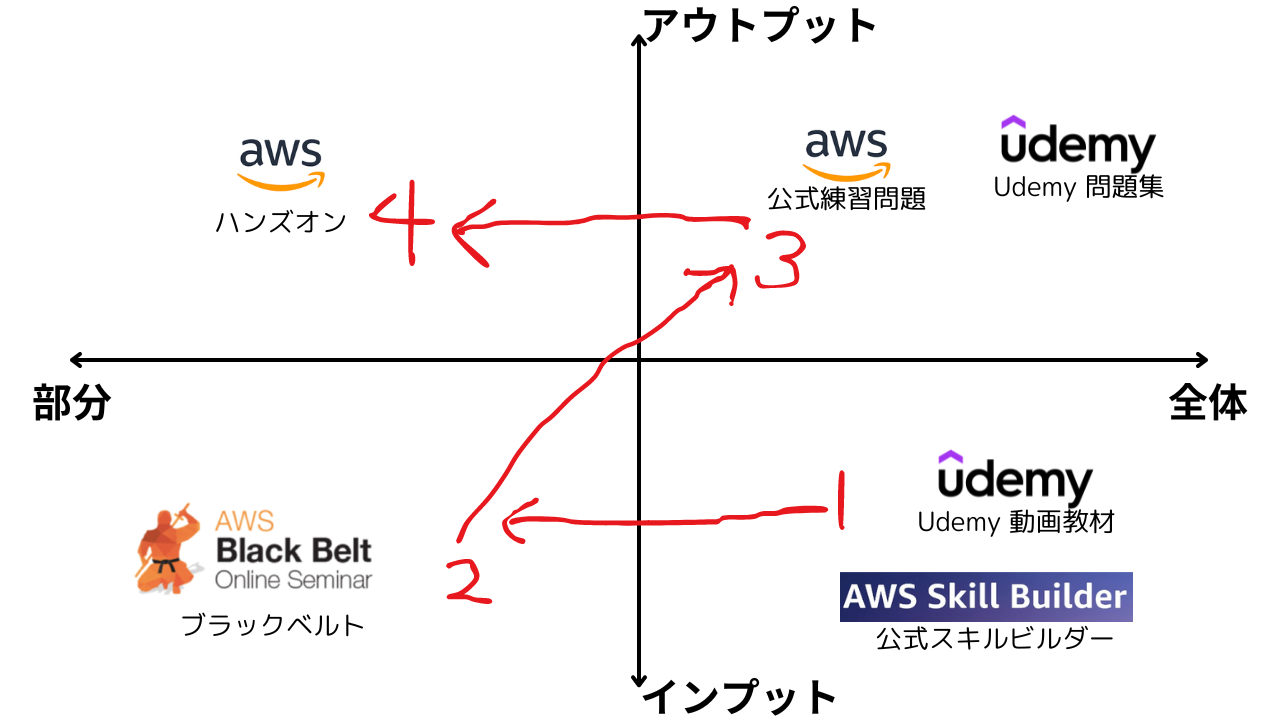
あらゆる資格学習において共通ですが、全体を学習し、その後に部分学習すると効果的です。また学習初期はインプット学習し、次第にアウトプット学習を意識しましょう。学習に詰まったらChatGPTを活用することもおすすめです。後の章で具体的な使い方も紹介します。
-
STEP1: 出題範囲全体を学ぶ(1週間程度)
MLAの出題範囲全体をスキルビルダーやUdemy教材を活用して学びます。SAAなどの他の資格に合格している方も出題サービスが異なるため一通り学習することをおすすめします。 -
STEP2: 部分的なサービスの深堀にはブラックベルトシリーズを活用 (1週間程度)
AWSの各サービスを詳しく学ぶためには、AWSブラックベルトシリーズがおすすめです。MLAに頻出なサービスは視聴しておくことをおすすめします。(特にSageMakerは深く勉強しておきましょう。) -
STEP3: 問題演習は必須 (2週間程度)
問題集を解き、出題傾向や弱点を把握して試験対策を進めます。 -
STEP4: 不明点を中心にハンズオン (任意)
実際に手を動かすことで、知識を実践に応用するスキルを身に着けます。資格取得の効率性を重視する方はスキップ可能ですが、実務能力を身に着けたい方はぜひ取り組んでください。
学習にAWS公式教材に加えてUdemy教材がおすすめです。教材のアップデートが早いのでMLAのように新しい資格にも対応できます。また、サブスク制ではなく、買い切りなので時間をかけて学習する方にもおすすめです。
- 30日以内であれば返金可能(気軽に始められる)
- 教材購入後もコンテンツがアップデートされる(頻繁にアップデートされるクラウド学習に最適)
- 不明点を講師に質問可能
- スマホでも視聴可能(隙間時間の活用)
- 月に数回(2~3回)実施するセールでは数万円のコースも2,000円程度に割引される(安価!)
STEP1: 出題範囲全体を学ぶ(1週間程度)
全体のインプット学習にはAWSスキルビルダーとUdemyの動画教材を使った学習がおすすめです。AWSスキルビルダーは無料で完成度も高いため、まずはAWSスキルビルダーで一通り学習し、理解しきれない場合にUdemy動画教材を用いた学習をするのが良いと思います。
筆者はAWSスキルビルダー(スタンダード)で一通り学習した後に知識チェックのためにUdemy動画教材で学習しました。
AWSスキルビルダー
MLAのAWSスキルビルダーにはスタンダード(無料)とエンハンスド(有料)があります。二つの内容はかなり重複しているようです。有料プランは$29/月からのサブスクリプションです。
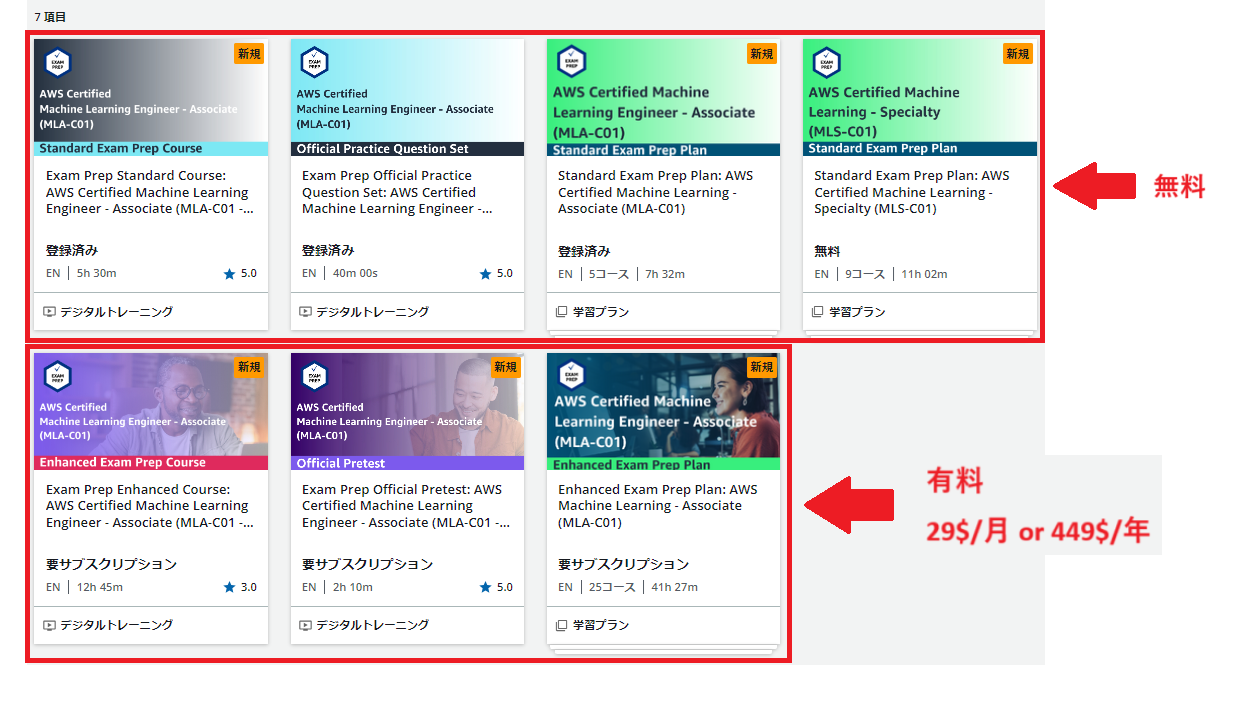
スキルビルダーには20問の練習問題もあるため、まずは問題を解いてみたい方は練習問題から取り掛かってみましょう。
- トレーニングコース スタンダード(無料)英語
- トレーニングコース エンハンスド(有料)英語
- 練習問題20問(無料)英語
- 練習問題65問(有料)英語
英語のコースはブラウザの自動翻訳機能が使えます。
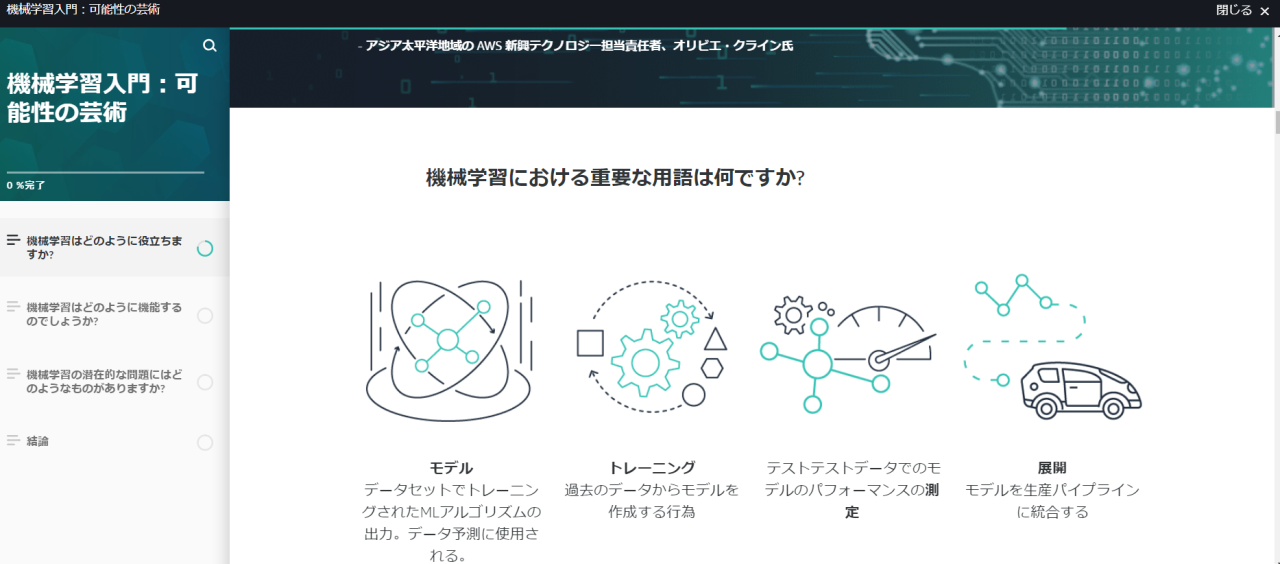
スキルビルダーはブラウザベースでテキストや図を読み込んで学習していくのが大半です。たまに動画もありますがこれも英語です。
「MLAの機械学習用語やAWS構成イメージが湧かない」
そんな悩みを解決する問題集
本問題集の特徴:
✓ 解説にAWSアーキテクチャ図を掲載
✓ 機械学習の概念を図解で説明
✓ AWS・機械学習の両方を初心者向けに解説
✓ 公式ドキュメントへの参照リンク付き
Udemy評価4.4の講師が作成
講師クーポン【図解付き詳細解説】AWS MLA-C01完全攻略問題集 | 構成図&グラフ解説付き
Udemy動画教材 英語
この教材は英語ですが、試験範囲を網羅的に学習できます。スキルビルダーで理解しきれなかったところを学習するのにおすすめです。字幕で日本語を設定できます。また、スライドをダウンロードできるため、手元で日本語のスライドを参照可能です。
Udemy動画教材の使い方について、画面を交えて詳しく説明しています。ぜひ以下の記事をご覧ください。
記事の内容:
- Udemy動画教材の便利な機能紹介: 再生速度調整、トランスクリプト表示、字幕対応などの機能
- スマホ機能の紹介: コースのダウンロード機能やバックグラウンド再生
- QA方法紹介: 講師への質問方法
本教材は、MLA試験範囲を網羅的に学ぶことができる教材です。MLAの出題範囲であるSageMakerやBedrockなどのAWSサービスをしっかりとマスターできます。
↓講座のリンクです。リンク先で60分程度のプレビューを無料視聴可能です。(定価:4,800円 セール時参考価格2,000円程度)
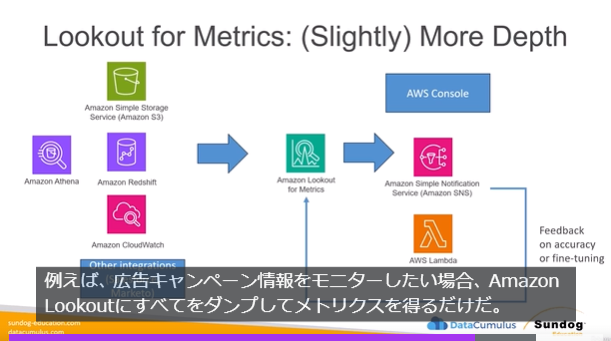
スライドには図が豊富なので英語でも理解しやすいです。スライドはダウンロード可能なので自動翻訳可能です。
字幕も他の動画教材に比べて精度が高い気がします。

-
価格:
- 定価: ¥4,800
- セール時参考価格: ¥2,000
- 動画時間: 23時間
- レビュースコア: (4.7/5)
- 特徴: MLAの網羅学習とハンズオンが可能。試験情報に合わせて購入後もアップデートあり。
- 問題数: 130問(20問の演習問題+110問の確認テスト)
-
良いレビュー:
- このコースと模擬試験で試験に合格できた。現場で役立つ知識も得られた。
-
悪いレビュー:
- 初心者には難しく感じるセクションがある。
STEP2: 部分的なサービスの深堀にはブラックベルトシリーズを活用 (1週間程度)
AWSブラックベルトシリーズは、AWSの各種サービスや技術に関する日本語の解説資料やウェビナーがあります。各サービスの詳細な技術情報や活用方法がまとめられており、Machine Learning Engineer Associate(MLA)取得の知識補完や部分学習に非常に役立ちます。特に、試験範囲の主要サービスの理解を深めるための教材として最適です。おすすめの使い方は以下の通りです。
- MLA試験で頻出の主要サービスの理解を強化する
- 特にSageMakerについては深く理解しておきましょう
- スキルビルダーや動画教材で理解しきれなかったサービスを深く学習する
- 問題演習で理解が不足していたサービスについて、知識を補完する
以下のサービスの中で、理解が不十分なものがあれば、ぜひブラックベルトで視聴しておきましょう。特に太字はMLA試験に頻出するサービスです。
- 分析: Athena, Data Firehose, EMR, Glue, Glue DataBrew, Glue Data Quality, Kinesis, Lake Formation, Managed Service for Apache Flink, OpenSearch Service, QuickSight, Redshift
- アプリケーション統合: EventBridge, Managed Workflows for Apache Airflow (MWAA), SNS, SQS, Step Functions
- クラウド財務管理: Billing and Cost Management, Budgets, Cost Explorer
- コンピューティング: EC2, Lambda, Serverless Application Repository, Batch
- コンテナ: ECR, ECS, EKS
- データベース: DocumentDB (MongoDB互換), DynamoDB, ElastiCache, Neptune, RDS
- デベロッパーツール: Cloud Development Kit (CDK), CodeArtifact, CodeBuild, CodeDeploy, CodePipeline, X-Ray
- 機械学習: SageMaker, Augmented AI (A2I), Bedrock, CodeGuru, Comprehend, Comprehend Medical, DevOps Guru, Fraud Detector, HealthLake, Kendra, Lex, Lookout for Equipment, Lookout for Metrics, Lookout for Vision, Mechanical Turk, Personalize, Polly, Q, Rekognition, Textract, Transcribe, Translate
- マネジメントとガバナンス: Auto Scaling, Chatbot, CloudFormation, CloudTrail, CloudWatch, CloudWatch Logs, Compute Optimizer, Config, Organizations, Service Catalog, Systems Manager, Trusted Advisor
- メディア: Kinesis Video Streams
- 移行と転送: DataSync
- ネットワークとコンテンツ配信: API Gateway, CloudFront, Direct Connect, VPC
- セキュリティ、アイデンティティ、コンプライアンス: IAM, Key Management Service (KMS), Macie, Secrets Manager
- ストレージ: EBS, EFS, FSx, S3, S3 Glacier, Storage Gateway
BlackBeltは以下のサイトで公開されています。
STEP3: 問題演習は必須 (2週間程度)
試験対策として、模擬問題を繰り返し解くことが大切です。出題形式に慣れるためにも、繰り返し演習を行い、安定して80%以上の正答率を達成できるようになれば本番試験の受験を考えてもよいと思います。
最初は問題に慣れていないと思うので不正解が続いても問題ありません。間違える過程で解説を読んで知識を蓄積させていきましょう。間違えた際、解説を熟読するのは勿論のこと、再度STEP1とSTEP2のインプット学習に立ち返ることが大切だと思います。
注意すべき点は、答えを丸暗記しないことです。本質を理解しないまま問題を繰り返すのは逆効果です。同じ問題を解きなおす際は少なくとも3日以上開けると効果的だと思います。間違えた都度、間違えた問題を記録しておきましょう。
もし同じ問題で何度も間違える場合、それはその問題に関連する何らかの知識が不足していると考えられます。この場合は、しっかりとインプット学習に立ち返り、関連する周辺知識も含めて習得することが重要です。
以下のように10問区切りで問題を解いていくと、解いた記憶が新鮮なうちに解説を読むことができるのでおすすめです。
- 10問解く
-
答え合わせを行う
- 間違えた箇所は解説を読む
- 正解した問題も、他の選択肢がなぜ不正解かを考えながら解説を読む
- 理解不足をブラックベルトや動画教材に立ち返って知識を広げる(STEP1~2に立ち返る)
この10問区切りの学習を繰り返すと必ず正答率が上がってきます。そうしたら65問のフルセットを解いてみましょう。80%以上の正答率が出たら、本番受験の申し込みをしましょう。
このようにして、段階的に学習を進めることで、効率よくMLA試験に備えることができます。AWS公式練習問題とUdemyのおすすめWEB問題集を紹介します。
問題集1: AWS公式練習問題(無料)
STEP1で紹介したものと同じです。全20問で何度も受験することができます。
問題数は少ないですが公式が出しているだけあって、難易度や出題形式は本番試験ほぼそのままです。まずは解いてみて出題形式と難易度の把握に利用するのが良いと思います。
この模擬試験を受験するにはAWSスキルビルダーへの登録が必要です。上記リンク先からも無料で登録できるのでおすすめです。
問題集2: AWS公式練習問題(有料)
STEP1で紹介したものと同じです。こちらは全65問です。サブスクしている間は何度も受験することができます。料金は29$/月 からです。
問題集3: Udemy 英語問題集(195問)
Udemyで発売されているMLAの問題集は英語のみです。ベストセラー問題集を紹介します。問題のクォリティが高く、解説も丁寧です。
Udemy問題集の使い方について、実際の画面を交えて詳しく説明しています。ぜひ以下の記事をご覧ください。
記事の内容:
- 【神アップデート!】解答を都度確認する方法を解説。(1問1答)
- Udemyの問題集をPCやスマートフォンで効果的に活用する方法を解説。
- ブラウザ翻訳機能を使い英語問題集を日本語に翻訳する手順を紹介。
- 問題演習画面の操作方法や解答確認の仕方を詳しく説明。
- 講師への質問方法を説明。
ブラウザの自動翻訳機能を使用することによって日本語で解くことができます。本問題集はサンプル問題が付属しているので以下に紹介します。
問題集のサンプル問題を確認する(Chrome自動翻訳)
サンプル質問:
あなたは金融サービス会社でデータ サイエンティストとして働いており、信用リスク予測モデルの開発を担当しています。ロジスティック回帰、決定木、サポート ベクター マシンなど、いくつかのモデルを試した結果、どのモデルも個別には必要なレベルの精度と堅牢性を達成できないことがわかりました。あなたの目標は、これらのモデルを組み合わせて、それぞれの長所を活かしながら短所を最小限に抑えることで、モデル全体のパフォーマンスを向上させることです。
このシナリオでは、次のアプローチのうち、モデルのパフォーマンスを向上させる可能性が最も高いのはどれでしょうか?
- 単純な投票アンサンブルを使用し、最終的な予測はロジスティック回帰、決定木、サポートベクターマシンモデルからの多数決に基づいて行われます。
- ロジスティック回帰、決定木、サポートベクターマシンなど、異なるタイプのモデルを順番にトレーニングしてブースティングを実装します。新しいモデルはそれぞれ、以前のモデルのエラーを修正します。
- スタッキングを適用する。ロジスティック回帰、決定木、サポートベクターマシンからの予測をランダムフォレストなどのメタモデルへの入力として使用し、最終的な予測を行う。
- バギングを使用する。ロジスティック回帰、決定木、サポートベクターマシンなどの異なるタイプのモデルをデータの異なるサブセットでトレーニングし、それらの予測を平均して最終結果を生成する。
あなたの推測は何ですか? 答えについては下にスクロールしてください。
正解: 3
説明:
正しい選択肢:
スタッキングを適用する。ロジスティック回帰、決定木、サポートベクターマシンからの予測をランダムフォレストなどのメタモデルへの入力として使用し、最終的な予測を行う。
バギングでは、データ サイエンティストは複数のデータセットで複数の弱い学習者を同時にトレーニングすることで、弱い学習者の精度を向上させます。対照的に、ブースティングでは、弱い学習者を 1 つずつトレーニングします。
スタッキングでは、複数のベース モデルの予測に基づいてメタモデルをトレーニングします。このアプローチでは、メタモデルが各ベース モデルの長所を活用しながら弱点を補うことを学習するため、パフォーマンスが大幅に向上します。
特定のユースケースでは、ランダム フォレストのようなメタモデルを活用することで、ロジスティック回帰、決定木、サポート ベクター マシンの予測間の関係を把握するのに役立ちます。
<ソリューション参考画像>
<参照リンク経由>
誤ったオプション:
単純な投票アンサンブルを使用します。この場合、最終的な予測は、ロジスティック回帰、決定木、およびサポート ベクター マシン モデルからの多数決に基づきます。投票アンサンブルは、モデルを組み合わせる簡単な方法であり、パフォーマンスを向上させることができます。ただし、通常、スタッキングほど効果的にモデル間の複雑な相互作用をキャプチャすることはできません。
ロジスティック回帰、決定木、サポート ベクター マシンなど、異なるタイプのモデルを順番にトレーニングしてブースティングを実装します。新しいモデルはそれぞれ、以前のモデルのエラーを修正します。ブースティングは、モデルを順番にトレーニングして、各モデルが以前のモデルのエラーを修正することに焦点を当てることで、モデルのパフォーマンスを向上させる強力な手法です。ただし、通常は、異なるタイプのモデルを組み合わせるのではなく、決定木 (XGBoost など) などの同じベース モデルを使用します。
バギングを使用します。バギングでは、ロジスティック回帰、決定木、サポート ベクター マシンなどの異なるタイプのモデルがデータの異なるサブセットでトレーニングされ、それらの予測が平均化されて最終結果が生成されます。ブースティングと同様に、バギングは、特に決定木などの高分散モデルの場合、分散を減らしてモデルの安定性を向上させるのに効果的です。ただし、通常は、異なるタイプのモデルを組み合わせるのではなく、同じモデル タイプ (ランダム フォレストの決定木など) の複数のインスタンスをトレーニングする必要があります。
<AWS ドキュメントからの複数の参照リンク付き>
195問で定価6,200円です。セール時には1,800円程度になることがあります。
Practice Exams: AWS Machine Learning Engineer Associate Cert
-
価格:
- 定価: ¥6,200
- セール時参考価格: ¥1,800
- レビュースコア: (4.6/5)
- 特徴: 品質の高い問題に詳細な解説。自動翻訳で日本語化可能。
- 問題数: 195問
-
良いレビュー:
- Associateレベルに適した問題が収録されており役立った。試験合格に直結した。
-
悪いレビュー:
- 一部問題が簡単すぎると感じた。
問題集4: Udemy 日本語問題集(340問 日本語模試ベストセラー)
340問収録されている問題集が発売されました。合格した後に発売された問題集のため、筆者はこの問題集を使用していませんが、レビューや教材ページを確認すると、本番と同じレベル感の問題が収録されているようです。
340問で定価4,200円です。セール時には1,800円程度になることがあります。
MLA-C01 / AWS認定 Machine Learning Engineer Associate 模擬試験4回+@
-
価格:
- 定価: ¥4,200
- セール時参考価格: ¥1,800
- レビュースコア: (4.6/5)
- 特徴: 唯一の日本語問題集
- 問題数: 340問
-
良いレビュー:
- 本番で似たような問題が出題された。問題集のアップデートがあった。
-
悪いレビュー:
- 不正解選択肢の解説が欲しかった。
STEP4: 不明点を中心にハンズオン (2週間以上 任意)
ハンズオンで実際にデータ分析やAIを触ってみると実務に役立つ知識を身に着けることができます。
取り合えず試験合格の効率性を重視する方はハンズオンをスキップしても構いません。ハンズオンは実践的な知識を身に着けるには最適ですが、時間がかかります。
いくつかのハンズオン教材を紹介します。
AWS公式ハンズオン
AWS公式でAI、機械学習の初心者向けのハンズオン教材が公開されています。登録は必要ですが、無料で視聴することができます。MLA取得に役立ちそうなハンズオンは以下の通りです。(ハンズオンにおいては下位資格のAIFと同じものを紹介しています。他の公式初心者向けハンズオンはこちらから。)
- AWS Managed AI/ML サービス はじめの一歩
- Amazon SageMaker Canvas 〜 ノーコードで機械学習を始めよう 〜
- AWS Lambda と AWS AI Services を組み合わせて作る音声文字起こし & 感情分析パイプライン
- Amazon Kendra で簡単に検索システムを作ろう!

特に1の「AWS Managed AI/ML サービス はじめの一歩」はMLAの主要サービスを浅く広く学べるため試験対策の入門としておすすめです。
勿論日本語で受講可能です。
Udemy動画教材(STEP1)のハンズオンパート
Udemy動画教材は解説パートに加えてハンズオンパートもあります。1周目は解説パートだけ視聴して、2週目はハンズオンを実施するという使い方もおすすめです。
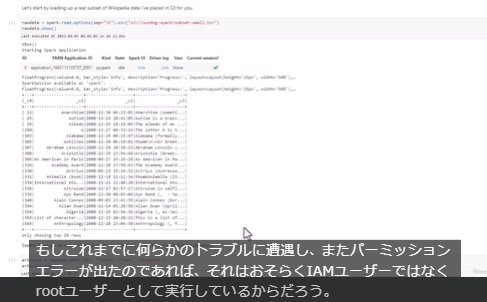
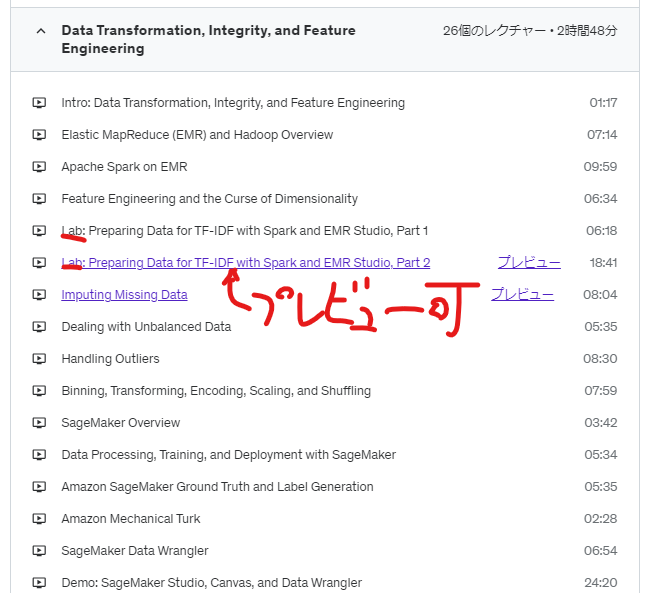
ハンズオンパートではAWSマネジメントコンソールを投影しながら丁寧に解説してくれます。
Spark、EMRのハンズオンの一部はプレビューで登録なしで無料視聴できるのでぜひ確認してみてください。(Labとついている章がハンズオンです。)
学習補助ツール: ChatGPTの活用方法を紹介
学習を進めていて疑問が生じたときは、ChatGPTに質問することで疑問を解消できます。ChatGPT単に「〜とは何ですか?」と聞くだけでも答えてくれますが、以下のポイントを意識することで、より有益な回答が得られます。
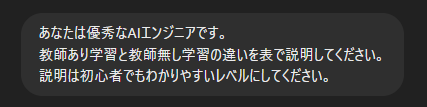
- 誰になってほしいのかを示す。
- 例:「あなたは優秀なAWSエンジニアです。」、「あなたは優秀なAIエンジニアです。」など
- 求める情報の粒度やレベルを示す。
- 例:「300文字以内で説明してください。」「初心者にもわかるように説明してください。」など
- 何かを比較したい場合は表も作成できる。
- 例:「教師あり学習と教師無し学習の違いを表で説明してください。」
- 解答が間違っている可能性があることを理解する
- 生成AIは間違った情報を返すこともあります。AWS公式HP等で裏どりするとベストです。
- 最新のChatGPT 4oでは、かなり正確な情報が得られるようになったと感じていますが、常に裏付けを取る姿勢が大切です。
以下の例では教師あり学習と教師無し学習について聞いてみました。
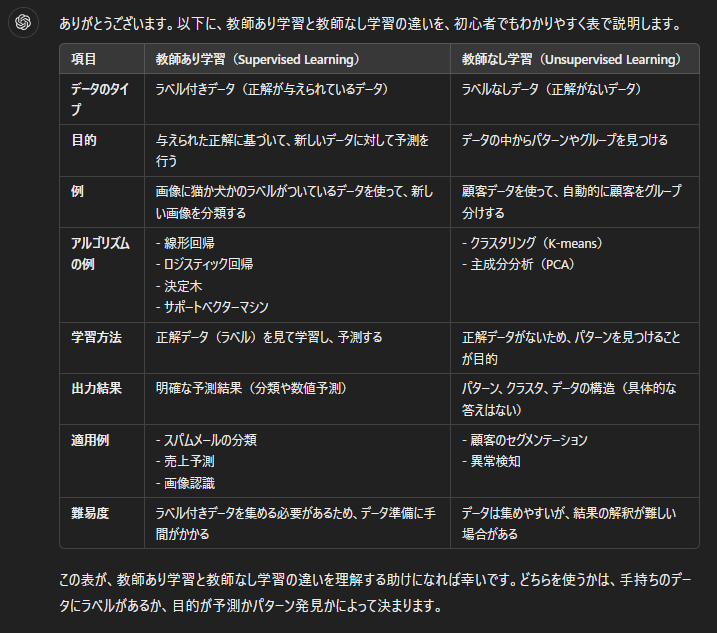
かなり参考になる応答が返されました。チャットの中で気になる点がある場合、続けて質問することもできます。

追加質問の回答の内容も非常に正確でわかりやすい内容が返却されていました。まるでAIに詳しいエンジニアが知恵袋などで回答してくれているように感じます。
MLAを受けるにあたって最低限知っておくべき機械学習用語
MLAを受験するにあたって最低限知っておくべき機械学習用語を紹介します。MLAではAWSサービスに加えて一般的な機械学習用語の理解も必須です。
以下は、MLA 試験を受けるにあたって最低限知っておくべき一般的な機械学習の用語とその簡単な解説です。
-
機械学習 (Machine Learning, ML)
コンピュータがデータを基にパターンを学習し、明示的にプログラムされずに予測や意思決定を行う技術です。例えば、スパムメールを分類するモデルを作成する際に、過去のメールの特徴を基に学習させます。 -
トレーニング (Training)
モデルにデータを使って学習させる過程です。データからパターンを見つけ、将来的な予測に役立つルールをモデルが自動的に生成します。 -
アルゴリズム (Algorithm)
機械学習でモデルを作るための計算方法や手順です。一般的なアルゴリズムには、線形回帰や決定木、サポートベクターマシンなどがあります。 -
線形回帰 (Linear Regression)
最も基本的な回帰アルゴリズムで、数値を予測するために使われます。目的は、入力データと出力データの関係を直線で表すことです。例えば、家の面積と価格の関係を予測する場合、面積が増えるにつれて価格がどのように変化するかを線形回帰でモデル化できます。数式では、予測値は「y = ax + b」の形で表され、「a」が傾き、「b」が切片です。この手法は、データが直線的な関係を持つ場合に有効です。 -
決定木 (Decision Tree)
分類と回帰の両方に使えるアルゴリズムです。データを「木」のように分岐させ、各分岐(ノード)で質問を行い、それに基づいて分類や予測を行います。例えば、「年齢が30歳以上か?」という質問でデータを分け、その後「収入が500万円以上か?」といった条件でさらに細かく分類します。最終的に、木の末端(リーフ)に到達することで予測や分類を行います。決定木の利点は、直感的で理解しやすく、データのパターンが複雑な場合でも強力に働くことです。 -
サポートベクターマシン (Support Vector Machine, SVM)
分類問題でよく使用されるアルゴリズムです。データを「境界線」で分けることで、2つのクラスに分類します。SVMの特徴は、データを分けるための「最も広いマージン」を持つ線(または超平面)を探す点です。これにより、データの誤分類が最小化され、正確な分類が行われます。例えば、スパムメールと通常メールを分類する際に、SVMはスパムと非スパムを分ける最も適切な境界線を見つけます。データが線形に分けられない場合でも、カーネル法を用いて複雑な境界を作ることができます。 -
特徴量 (Feature)
モデルが学習に使うデータの属性や項目です。例えば、家の価格を予測する場合、部屋の数や面積などが特徴量にあたります。 -
ラベル (Label)
モデルが予測する目標値です。例えば、メールがスパムかどうかを予測する場合、「スパム」や「非スパム」がラベルになります。 -
ハイパーパラメータ (Hyperparameter)
モデルの学習プロセスを制御するための設定です。例えば、決定木の最大深さやニューラルネットワークの学習率などがハイパーパラメータです。これは手動で設定されます。 -
オーバーフィッティング (Overfitting)
過学習とも言います。モデルがトレーニングデータに対して過剰に適応しすぎる現象です。これにより、未知のデータに対しての予測精度が低下します。つまり、学習した内容が限定的になりすぎて新しいデータに対応できない状態です。 -
アンダーフィッティング (Underfitting)
過小適合とも言います。モデルがトレーニングデータの重要なパターンを学習できていない状態です。この場合、トレーニングデータでもテストデータでも良い予測ができません。 -
精度 (Accuracy)
モデルが予測した結果のうち、正解した割合を示します。100件の予測のうち80件が正解であれば、精度は80%となります。 -
F1スコア
正解率(precision)と再現率(recall)のバランスを測る指標です。データが不均衡(正例と負例の割合が極端に異なる場合)な場合でも有効にモデルのパフォーマンスを評価できる指標です。 -
混同行列 (Confusion Matrix)
モデルの予測結果と実際の結果を比較する表です。実際のクラスとモデルの予測結果を照らし合わせ、正解数や誤分類数を確認します。 -
ROC曲線 (Receiver Operating Characteristic Curve)
モデルの性能を視覚化するグラフで、真陽性率(正しく「スパム」と判定した割合)と偽陽性率(「スパムではない」と誤って判定した割合)の関係を示します。 -
エポック (Epoch)
トレーニングデータ全体をモデルが一通り学習する一回分のサイクルを指します。エポック数が多いほど、モデルはデータを深く学習しますが、オーバーフィッティング(過学習)のリスクもあります。 -
バッチサイズ (Batch Size)
トレーニングデータをいくつかの小さなグループ(バッチ)に分けてモデルに学習させる際の各グループのサイズです。バッチサイズが大きいほど一度に処理するデータが増えます。 -
正則化 (Regularization)
モデルの複雑さを制限してオーバーフィッティング(過学習)を防ぐ手法です。L1正則化やL2正則化が一般的で、モデルのパラメータにペナルティを加えることで、過剰な適合を防ぎます。
受験した感想
勉強を始めたばかりの頃は、機械学習の専門用語が分からず、問題が何を問うているのかすら理解できませんでした。しかし、少しずつ用語を覚えていくと、出題の意図が分かるようになり、考えて解答できるようになりました。MLA試験は、機械学習の用語を知っていれば解ける問題が多くあると感じたので、用語の学習に力を入れたことは正解だったと思います。
また、機械学習用語を知らなくても解ける問題もいくつか出題されます。特によく出るのは、機械学習データの保存先や共有方法に関する問題です。こうした問題に正解するためには、SAAの知識が役立ちましたので、SAAを事前に取得しておいてよかったと感じました。
機械学習用語やSageMaker、MLパイプラインについて理解しておけば、MLA試験はそれほど難しいものではないと思います。
「MLAの機械学習用語やAWS構成イメージが湧かない」
そんな悩みを解決する問題集
本問題集の特徴:
✓ 解説にAWSアーキテクチャ図を掲載
✓ 機械学習の概念を図解で説明
✓ AWS・機械学習の両方を初心者向けに解説
✓ 公式ドキュメントへの参照リンク付き
Udemy評価4.4の講師が作成
講師クーポン【図解付き詳細解説】AWS MLA-C01完全攻略問題集 | 構成図&グラフ解説付き
まとめ
AWS Machine Learning Engineer Associate (MLA-C01) 試験は、機械学習の技術者向けに設計された中級レベルの資格です。この試験では、AWSのサービスを使用した機械学習モデルの構築、デプロイ、監視に関する深い知識が問われます。効果的な学習方法としては、全体を網羅するインプット学習、特定サービスの深堀り、問題演習、そしてハンズオンを組み合わせることをおすすめします。
使用する教材としては、AWSスキルビルダーやUdemyの動画教材、AWS公式ハンズオンが挙げられます。これらを活用することで、実務的なスキルも向上させながら試験対策を効率的に進めることができます。最終的に、本質的な理解を重視し、演習問題を繰り返すことで確実に合格へ近づくことができるでしょう。
以上です。最後までお読みいただきありがとうございました!
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。

システムエンジニア
AWSを中心としたクラウド案件に携わっています。
IoTシステムのバックエンド開発、Datadogを用いた監視開発など経験があります。
IT資格マニアでいろいろ取得しています。
AWS認定:SAP, DOP, SAA, DVA, SOA, CLF
Azure認定:AZ-104, AZ-300
ITIL Foundation
Oracle Master Bronze (DBA)
Oracle Master Silver (SQL)
Oracle Java Silver SE
■略歴
理系の大学院を卒業
IT企業に就職
AWSのシステム導入のプロジェクトを担当