AWS lambdaで実装した関数のdurationが普段は数msで終わるのに、稀に60,000msを超えることがあった。
調査結果と対策についてまとめます。
結論 boto3の呼び出しで60秒かかっている
AWS boto3内部でタイムアウトが起きている。
デフォルトではタイムアウト時間は60秒となっているので独自設定で上書きして実行する。
from botocore.session import Session
from botocore.config import Config
s = Session()
c = s.create_client('s3', config=Config(connect_timeout=5, read_timeout=5, retries={'max_attempts': 2}))検証した環境 LambdaからFirehoseにputしてみる

Lambdaで処理したデータをfirehose経由でS3に格納するというシンプルな構成です。普段は500msくらいで処理してくれます。ちなみにfirehoseにputする際は下記関数を使用しています。
client.put_recordAWSboto3公式client.put_record
※この関数にかかわらず、60秒問題は起きえます。
発生した事象 Firehoseへのputで60秒かかる
かなりの低頻度ですが、Lambda関数の実行時間が60,000ms以上になります。
メトリクスを確認してもfirehose側でスロットルが起きている様子はありませんでした。
デバック関数を仕込んで調査した結果、下記boto3でFirehoseにputしている個所で60秒かかっていました。
client.put_record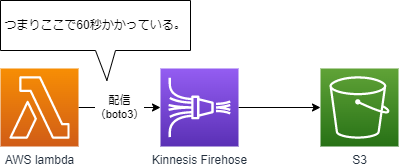
原因調査 boto3とbotocoreをデバックモードで実行してみた
なぜそんなことが起きるのか?を調査してみました。
デバックログを出そうにもboto3関数内部でのことなので自分でデバックログを記述するわけにはいきません。
そこでboto3でDEBUGログを出す方法を発見しました。
【boto3内部のログを出す】boto3.set_stream_logger
下記をソースコードに記述するだけでログが出るようになります。
boto3をデバックモードで実行
boto3をデバックモードで実行するには下記コードを挿入します。
import boto3
boto3.set_stream_logger()ログが大量に出力されるのでCloudWatchのログの課金に注意してください。検証が終わったら上記記述を削除するのをお忘れなく。
botocoreをデバックモードで実行
botocoreをデバックモードで実行するには下記コードを挿入します。
import botocore
botocore.session.Session().set_debug_logger()ログが大量に出力されるのでCloudWatchのログの課金に注意してください。検証が終わったら上記記述を削除するのをお忘れなく。
デバックモードで実行した結果 boto3 ReadTimeoutErrorが発生していた
すると60,000msかかる場合の処理は以下のようなログが出力されました。
raise ReadTimeoutError(endpoint_url=request.url, error=e)
botocore.exceptions.ReadTimeoutError: Read timeout on endpoint URL: ""https://firehose.ap-northeast-1.amazonaws.com/""
method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]
raise six.reraise(type(error), error, _stacktrace)
urllib3.exceptions.ReadTimeoutError: AWSHTTPSConnectionPool(host='firehose.ap-northeast-1.amazonaws.com', port=443): Read timed out. (read timeout=60)
raise ReadTimeoutError(endpoint_url=request.url, error=e)
botocore.exceptions.ReadTimeoutError: Read timeout on endpoint URL: ""https://firehose.ap-northeast-1.amazonaws.com/""
method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]
raise six.reraise(type(error), error, _stacktrace)たくさんログが出ていたのでCloudWatchInsightでの検索が便利でした。
例えば下記クエリで「error」を含むログを抽出できます。
fields @timestamp,@message | filter @message like /(?i)error/ boto3 ReadTimeoutErrorとは? デフォルトのタイムアウト値60秒が原因だった
boto3 ReadTimeoutErrorで調べた結果、原因が書かれているようなAWS公式ドキュメントを見つけたました。
AWS SDK を使用して Lambda 関数を呼び出す際の再試行とタイムアウトの問題は、どのようにしてトラブルシューティングすればよいですか?
以下、一部抜粋です。
AWS SDK で Lambda 関数を呼び出す際に、再試行とタイムアウトの問題が発生する理由としては、以下の 3 つが考えられます。 ・リモート API に到達できないか、API 呼び出しに応答するのに時間がかかり過ぎている。 ・ソケットがタイムアウトするまで、API 呼び出しが応答を受け取れなかった。 ・API 呼び出しが Lambda 関数のタイムアウト期間内に応答を取得しない。AWS SDK を使用して Lambda 関数を呼び出す際の再試行とタイムアウトの問題は、どのようにしてトラブルシューティングすればよいですか?
AWS SDK を使用して Lambda 関数を呼び出す際の再試行とタイムアウトの問題は、どのようにしてトラブルシューティングすればよいですか?
AWS SDK 最大再試行回数 接続タイムアウト ソケットタイムアウト Python (Boto 3) サービスにより異なる 60 秒 60 秒
接続タイムアウト、ソケットタイムアウトともに60秒とある。なるほど!これか!!
最大試行回数がサービスにより異なるとは? botocoreのソースコード_retry.jsonに定義あり
ちなみにPython (Boto 3)に関しては最大再試行回数はサービスにより異なると記載があります。具体的にどのようにサービスにより異なるのかを深堀して見ていきます。
gitのbotocoreのソースを確認すると_retry.jsonなるものを見つけました。
_retry.json
上記はデフォルト設定が定義されたうえで、サービス毎に上書きできるような設定になっていて、おそらくこれが、「サービス毎に異なる」という点だと思われます。
"retry": {
"__default__": {
"max_attempts": 5,
"delay": {
"type": "exponential",
"base": "rand",
"growth_factor": 2
}
実際には、サービス毎に回数が定義されているのはDynamoDBだけのように見えます。他はデフォルト値のようです。
"dynamodb": {
"__default__": {
"max_attempts": 10,
"delay": {
"type": "exponential",
"base": 0.05,
"growth_factor": 2
},
client.py
色々追うのは大変ですが、140行目付近で、jsonファイルにある設定値を利用しつつ、オブジェクトを生成しています。
cls = self._create_client_class(service_name, service_model)また、client.pyではjsonファイルにある定義を使いつつ、リトライ可能な例外を設定値として読み込んでいるようです。
retryhandler.py
スロットル発生時など再度実施しても同じエラーになる可能性が高いときはリトライしない、そうではなく何かしらの不整合が起きている可能性がある場合はリトライしているように見えます。かなり考えられていますね。
頭がいい人が作ったソースコードは理解するのが大変です。
対策 独自にタイムアウトとリトライ回数を設定しよう
調査の通り、boto3内部の通信タイムアウトが原因でした。対策についてもAWS公式ドキュメントに示されています。
AWS SDK を使用して Lambda 関数を呼び出す際の再試行とタイムアウトの問題は、どのようにしてトラブルシューティングすればよいですか?
内容としてはタイムアウト時間、リトライ回数について自由に設定できるので各自設定してみてくださいといったものです。
サンプルコードとして、下記は接続タイムアウト5秒、読込タイムアウト5秒、最大試行回数2回で設定してみたものになります。
from botocore.session import Session
from botocore.config import Config
s = Session()
c = s.create_client('s3', config=Config(connect_timeout=5, read_timeout=5, retries={'max_attempts': 2}))デフォルトではタイムアウト時間が60秒となっているので最大60秒待たされていましたが、上記ではタイムアウトが5秒、最大試行回数2回となっています。5秒待っても応答がなかったら最大2回までやり直すね、といった設定です。
やはりクラウドを使うときには冪等性(べきとうせい)を持った設計が必要となりますね。これでlambdaの実行時間が60,000msを超えることはなくなりました!
おまけ 実際何回リトライされたのかをログに出す
独自のタイムアウト、試行回数を設定できることは分かった。では実際に何回リトライされたのかを知りたくなったので調査しました。
boto3のresponceの中にあるResponseMetadataの中にRetryAttemptsがありました。
boto3 error-handling
タイムアウトの設定、boto3の呼び出し、リトライ回数のログ出力までのサンプルコードを記載しておきます。
※ソースを簡単にするため、firehoseではなく、S3に対するlistとしています。
from botocore.session import Session
from botocore.config import Config
import logging
# Set up our logger
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger()
s = Session()
# タイムアウト時間、リトライ回数の設定
config=Config(connect_timeout=5, read_timeout=5, retries=dict(max_attempts=10))
# client生成
c = s.create_client('firehose', )
# boto3実行(firehoseへのput)
response = c.put_record(XXXXXX)
# responseからリトライ回数の取り出し
retrycnt = response['ResponseMetadata']['RetryAttempts']
logger.debug('RetryAttempts: {retrycnt}')これでデバックログにリトライ回数が出力されました。
今回はこのあたりで以上です。お読みいただきありがとうございました。
PR
当ブログはWordPressテーマSWELLを使用しています。非常に使いやすく、簡単にプロのようなデザインを使えるのでお勧めです!!
SWELL – シンプル美と機能性両立を両立させた、圧巻のWordPressテーマ![]()
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。

システムエンジニア
AWSを中心としたクラウド案件に携わっています。
IoTシステムのバックエンド開発、Datadogを用いた監視開発など経験があります。
IT資格マニアでいろいろ取得しています。
AWS認定:SAP, DOP, SAA, DVA, SOA, CLF
Azure認定:AZ-104, AZ-300
ITIL Foundation
Oracle Master Bronze (DBA)
Oracle Master Silver (SQL)
Oracle Java Silver SE
■略歴
理系の大学院を卒業
IT企業に就職
AWSのシステム導入のプロジェクトを担当