
CloudSearchを使う機会があり、運用監視について調査したので備忘もかねてまとめます。
CloudSearchを使ったシステムの運用監視を考えるにあたって下記については監視したいと思い情報収集しました。
- 検索のレイテンシ
- 検索のスロットリング
- データ投入時のスロットリング
- CloudSearchはインスタンスが作成されるのでインスタンスの何らかの監視
- その他上限緩和にかかわる監視、死活監視
CloudSearchとは 検索システムを作成できるサービス
WEBサイトやドキュメント、ファイルなどの検索システムを作成できるフルマネージドサービスです。
以下AWS公式ドキュメントより引用
Amazon CloudSearch はクラウドにおけるフルマネージドサービスであり、ウェブサイトまたはアプリケーション向けの検索ソリューションを容易に設定、管理、拡張縮小できます。 Amazon CloudSearch を使用して、ウェブページ、ドキュメントファイル、フォーラムの投稿、製品情報など大規模なデータコレクションを検索できます。検索機能を迅速に追加できます。検索の高度な知識を習得したり、ハードウェアの準備、設定、およびメンテナンスについて考える必要はありません。データやトラフィックの変動に伴い、Amazon CloudSearch はニーズに合わせてシームレスにスケーリングします。
AWS公式ドキュメント
今回のシステム構成 DynamoDBのインデックス作成
今回はDynamoDBで柔軟な検索ができるように使用しました。インデックスの作成タイミングはいろいろなものがありますが、DynamoDBの更新とCloudSearchのインデックス更新タイミングのずれを少なくしたかったのでDynamoDBStreamを使用しました。DynamoDBが更新されるたびにLambdaが起動してCloudSearchのインデックスを更新していきます。

オートスケールの動き データ量とトラフィック量に対してスケール
CloudSearchではオートスケールがあります。トラフィックの量とデータの量の二つの側面からスケーリングされるので少々複雑です。それそれ動きを見ていきます。
AWS公式(CloudSearchのオートスケール)に記載されている図を掲載します。
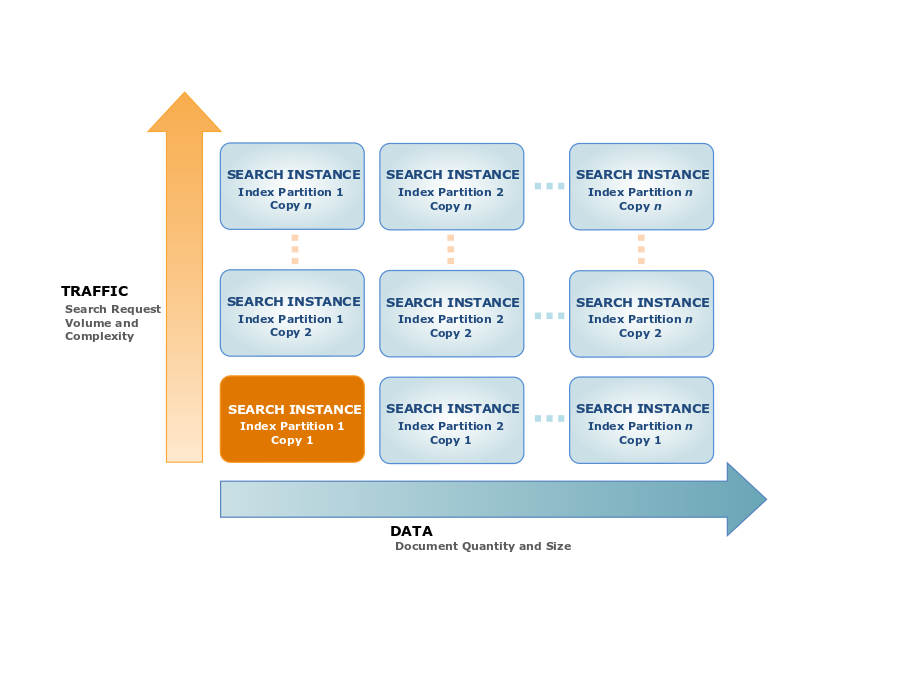
DATA(データ量)
データ量でのオートスケールの優先順です。1から順番に処理されていきます。スケールアウトよりスケールアップが優先されるようです。
- 最初はスモールインスタンス(search.m1.small)から始まる
- データが増えてスモールでは足りなくなると大きなインスタンスタイプに変更する(スケールアップ)
- 最大のインスタンスタイプでも不足する場合はインスタンス数を増やす(スケールアウト)
TRAFFIC(リクエスト数)
- トラフィック量に応じてDATA(データ量)で決定されたインスタンスを複製する。
- この時、DATA(データ量)で決定されたインスタンス数 × N になる
(例えばデータ量で決定された数 = 3, トラフィックによる複製 = 2 の場合、インスタンス数は6になる。)
標準メトリクスの監視 監視に使えそうなメトリクスを探す
自動でスケールしてくれるのは分かりましたが、ちゃんとスケールしてレイテンシなど問題ないのかは監視したいところです。
CloudSearchの標準メトリクス
さて、運用監視設計でまず考えるのは標準メトリクスです。AWSでは数々の標準メトリクスが準備されており、追加料金なしで手軽に監視を実現できます。CloudSearchではどのような標準メトリクスがあるかをAWS公式ドキュメント(CloudSearchメトリクス)から見ていきます。
SuccessfulRequests, SearchableDocuments, IndexUtilization, Partitionsがあります。それぞれ見ていきます。
- SuccessfulRequests(正常に処理された検索リクエストの数)
正常に処理されたリクエストは傾向監視にはよいと思います。異常が起きた時の通知(死活監視)には向いていない印象です。 - SearchableDocuments(検索可能ドキュメントの数)
オートスケールでいうところのDATA量を監視するメトリクスです。傾向監視向きな印象です。 - IndexUtilization(使用された検索インスタンスのインデックス容量の割合)
DATA量とインスタンス数、インスタンスサイズによって決定する。オートスケールが動いていれば一定の使用率になってからスケーリングされて下がるので傾向監視と死活監視に利用できそうです。 - Partitions(パーティションの数)
DATA量の増加によりパーティションが増加すると増えるメトリクスです。オートスケールの履歴を追うために使用できる傾向監視向けのメトリクスで使用できそうです。パーティション数には上限があるので上限の監視にもよさそうです。
標準メトリクスだけの監視では要件を満たせなかった
結局、標準メトリクスだけではすべての監視要件(検索のレイテンシ、検索のスロットリング、データ投入時のスロットリング、インスタンス監視)を満たすのは難しそうですが、CloudSearchのクオータを確認するとIndexUtilizationとPartitionsは監視しておいた方が良い旨が記載されていたのでCloudWatchで監視するように設計しました。
Amazon CloudSearch の制限を理解する
検索パーティション 検索インデックスは、最大 10 のパーティションに分割できます。この制限を引き上げる必要がある場合は、リクエストを送信できます。 検索クエリの失敗を回避するために、Amazon CloudSearch ドメインはこの最大パーティション制限を超えることがありますが、 新しいドキュメントの追加は拒否されます。このシナリオが発生した場合は、ドキュメントを削除し、IndexDocuments API をトリガーします。 あるいは、制限緩和をリクエストします。 Amazon CloudWatch IndexUtilization および Partitions メトリクスをモニタリングして、 最大パーティション制限を超える前にアクションを実行できます。
Amazon CloudSearch の制限を理解する
要件を満たした監視設計のためにエラーハンドリングを実装する
標準メトリクスですべての監視要件(検索のレイテンシ、検索のスロットリング、データ投入時のスロットリング、インスタンス監視、上限の監視、死活監視)は満たせそうにありません。検討した結果どのように要件を満す設計にしたのかを記載します。
- 検索のレイテンシ、検索のスロットリング、データ投入時のスロットリング
検索、データ投入時のAPIを呼び出した時の4XXエラーのハンドリングを行いカスタムメトリクスを発行して通知 - インスタンス監視
フルマネージドサービスなのでインスタンスの責任共有はAWS側。ユーザ側でのインスタンス監視は不要 - 上限緩和の監視
標準メトリクスIndexUtilizationとPartitionsの監視 - 死活監視
CloudSearchのHealthの監視
システムによって監視要件は異なると思うので監視設計の一助になればうれしいです。
PR
当ブログはWordPressテーマSWELLを使用しています。非常に使いやすく、簡単にプロのようなデザインを使えるのでお勧めです!!
SWELL – シンプル美と機能性両立を両立させた、圧巻のWordPressテーマ![]()
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。

システムエンジニア
AWSを中心としたクラウド案件に携わっています。
IoTシステムのバックエンド開発、Datadogを用いた監視開発など経験があります。
IT資格マニアでいろいろ取得しています。
AWS認定:SCS, ANS, AIP, SAP, DOP, SAA, DVA, SOA, CLF
Azure認定:AZ-104, AZ-300
ITIL Foundation
Oracle Master Bronze (DBA)
Oracle Master Silver (SQL)
Oracle Java Silver SE
■略歴
理系の大学院を卒業
IT企業に就職
AWSのシステム導入のプロジェクトを担当