
定期実行のデータ処理バッチを構築するにあたりLambdaとGlueの選択肢があります。Lambdaは触ったことがあったが、Glueは触ったことが無かったので簡単な例を出して触ってみました。Glueでデータ処理を設定するための手順を記載していきます。
手間でいうとGlueはLambdaより設定するべき項目が多かったです。Glueを触ってみたいけど何からすればよいのかわからない方や認定資格取得を目指される方の参考になればうれしいです。
Data Engineer Associate(DEA)、Data Analytics Specialty(DAS)
参考:LambdaとGlueの違い
GlueとLambdaでは基本的に同じようなことを実現できますが、以下のような違いがあります。
| 比較項目 | Lambda | Glue |
|---|---|---|
| タイムアウト | 15分 | 2880分(48時間) |
| コスト | ミリ秒単位 | 10分単位 |
| 設定の手間 | 簡単 | 面倒(どのような手順が必要かは後述) |
| 主な用途の例 | 小規模なリアルタイムETL処理、APIベースのデータ変換 | データウェアハウスやデータレイクへの大規模なETLジョブの実行 |
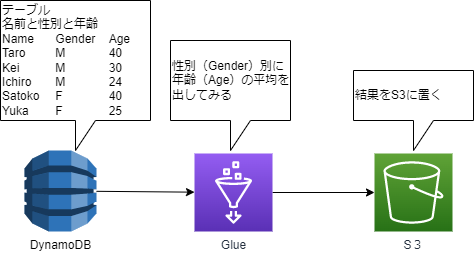
今回検証した構成
簡単な例として、DynamoDBに名前・性別・年齢を記したテーブルを作成し、性別ごとに年齢の平均値を出してみます。
前準備
Glueを設定する前にデータソースであるDynamoDBとデータ出力先であるS3の作成をしておきます。
DynamoDB作成
id(パーティションキー)、年齢、性別、年齢を格納するテーブルを作成しておきます。オンデマンド、プロビジョンなどの設定は何でも大丈夫です。
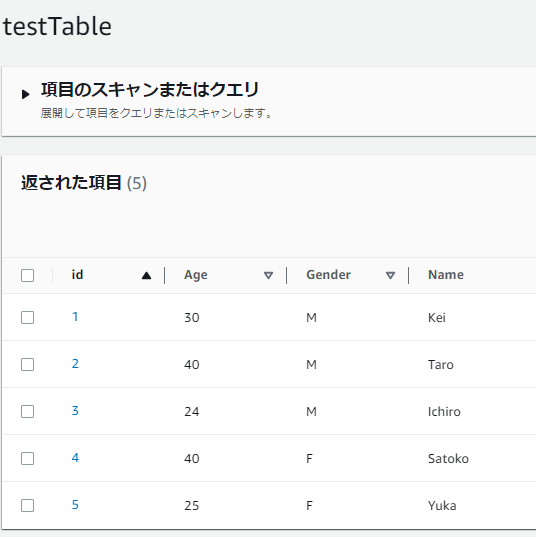
インポートしたい方のために一応CSVを記しておきます。
"id","Age","Gender","Name"
"5","25","F","Yuka"
"4","40","F","Satoko"
"2","40","M","Taro"
"1","30","M","Kei"
"3","24","M","Ichiro"S3バケット作成
デフォルトの設定のままでよいのでバケットを作成しておきます。なお、GlueがS3にオブジェクトをPutすることを許可するためにバケットポリシーの設定が必要ですが、それは後程行います。

Glueのセットアップ
データベースの作成
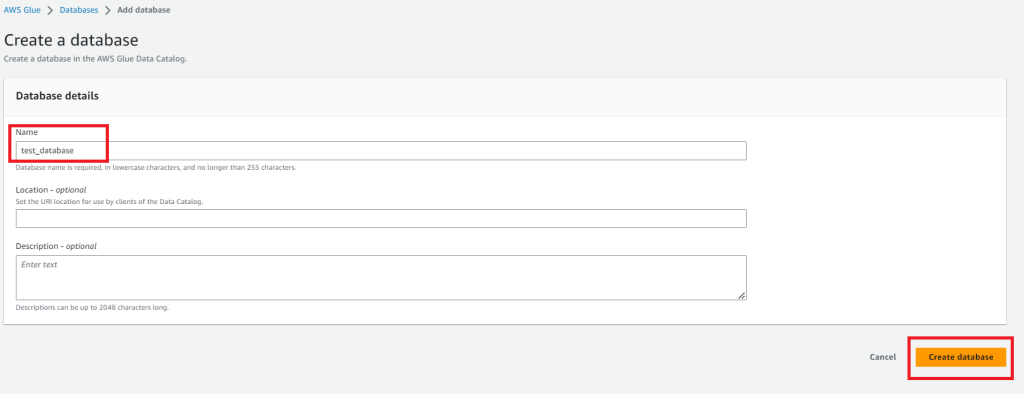
Glueのマネジメントコンソールからdatabasesを選択しAdd Databasesからデータベースの作成を行います。

Nameだけを入力してあとは何も入力せずにCreate databaseを選択します。
クローラー(Crawlers)の作成
GlueのマネジメントコンソールにアクセスしGrawlersを選択します。(文字が細かくて見にくいのでリンクにしています。)
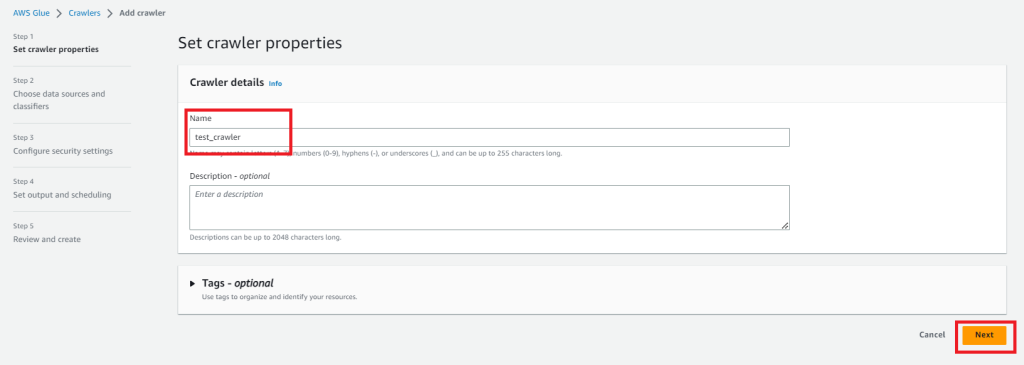
Create crawlersを押下してクローラーを作成します。

まずNameを設定します。Nameを入力したらNextを押下します。
次にデータソースを選択します。Glue tableは作成していないので「Is your data already mapped to Glue tables?」はNot yetにしておきます。(これから作成します。)
データソースを作成するために「Add data source」を選択します。
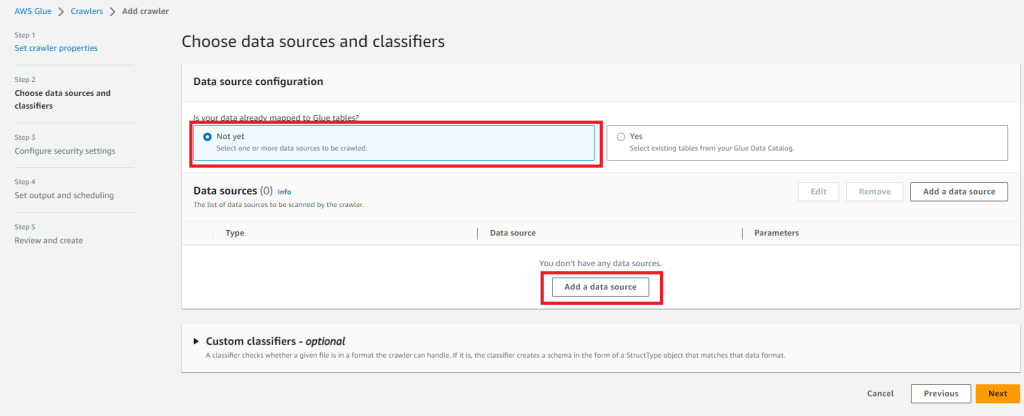
すると子画面が表示されるので以下の通り入力します。
- Data source:DynamoDB
- Table name:前準備で作成したテーブル名
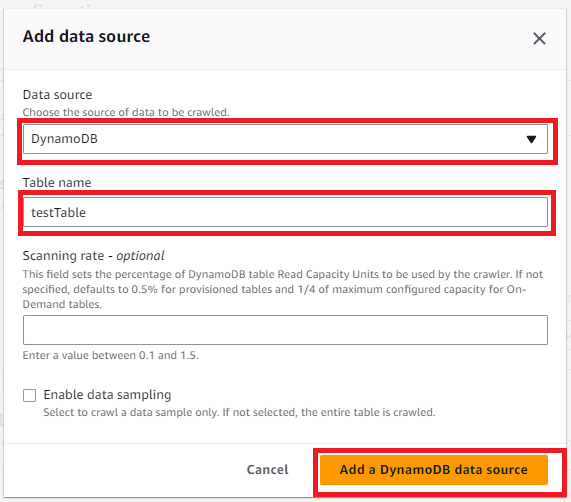
Data sorcesが追加されるのでNextを選択します。
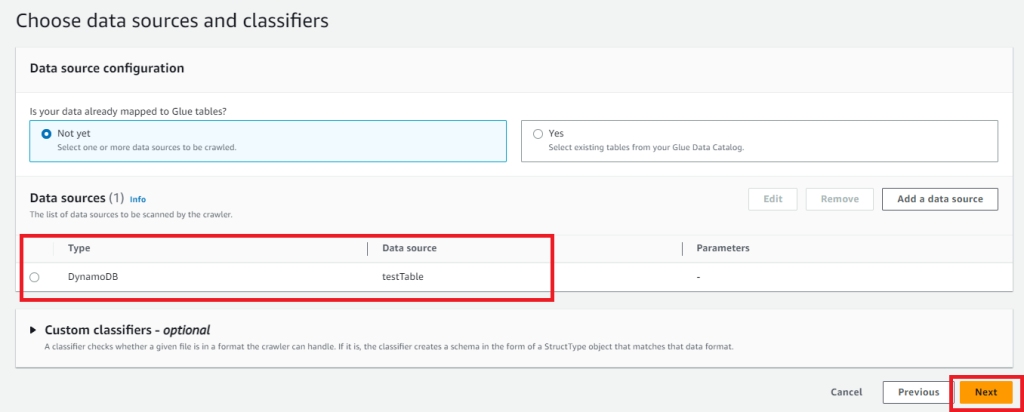
続いてIAMロールの設定です。作成していないと思うので「Create new IAM role」から作成します。
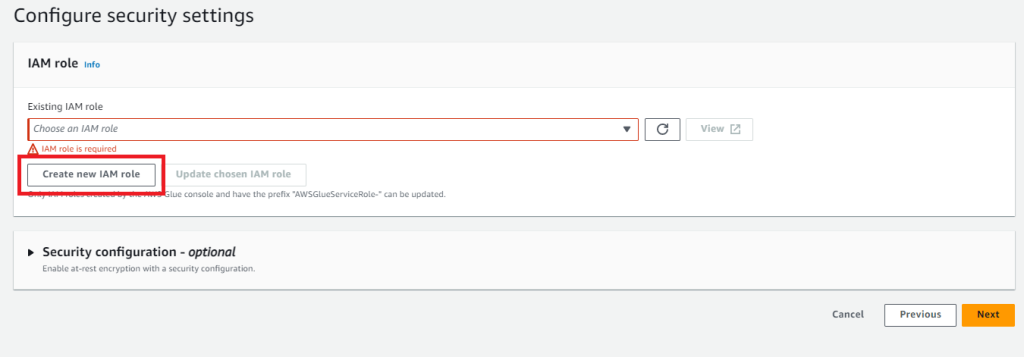
IAMロールの名前を入力する画面になるので名前を入力してCreateを押下します。
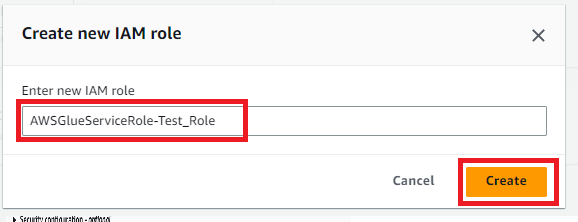
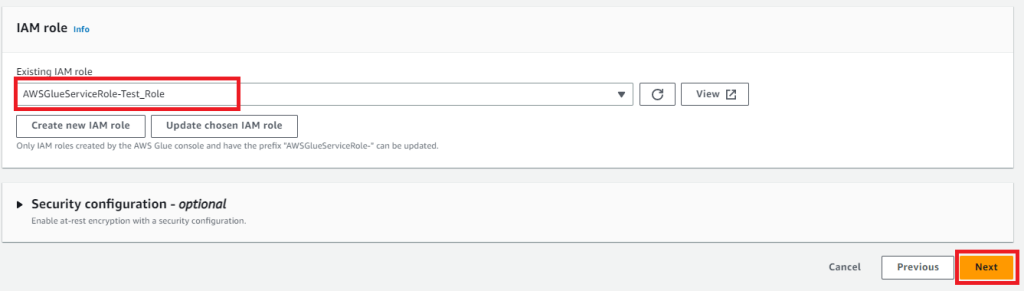
IAMロールが入力されるのでNextを押下します。
補足:作成されるIAMロールについて
作成されるIAMロールには2種類のIAMポリシーが紐づいています。
1つはAWSGlueServiceRoleというマネージドポリシーで、S3へのアクセスやログ出力を許可するものです。
2つめは指定したデータソースのDynamoDBに対しての読み取りを許可するカスタマー管理ポリシーです。
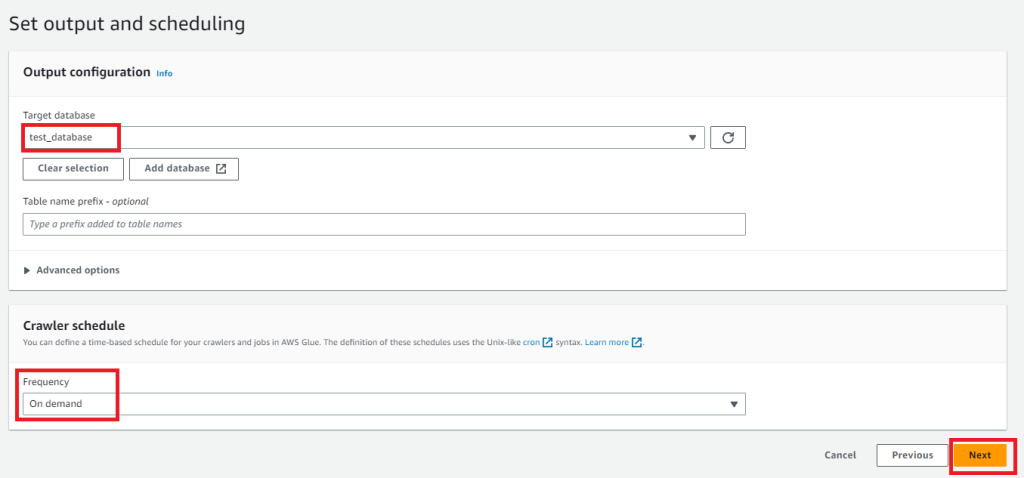
次の画面でデータベースの選択とスケジュールを入力します。
- Target database:作成したdatabaseを選択
- Frequency:必要な実行頻度を選択。例ではOn demand(手動実行)を選択しています。
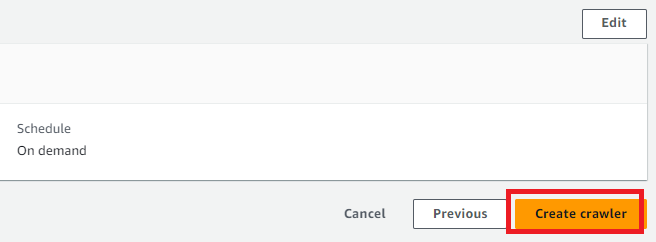
次の画面は確認なので見直しをして問題なければCreateを押下します。
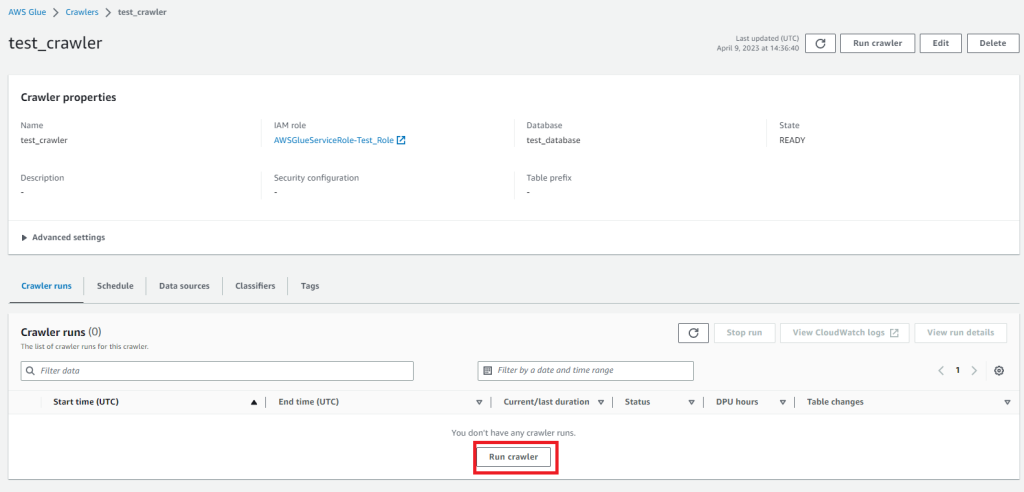
クローラーの実行(データカタログの作成)
DynamoDBからGlueのテーブルを作成するためには「Run crawler」を選択してクローラーを動かします。
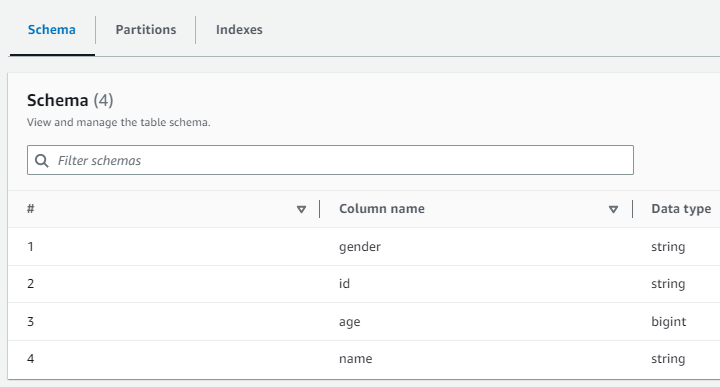
これを実行するとテータカタログが作成されます。GlueのコンソールのTablesから確認できます。
GlueのコンソールのTablesから確認するとDynamoDBからスキーマが作成されているのが確認できます。
ジョブの作成
AWS Glue StudioからJobの作成を行います。
- Visual with a source and target
- Sorce:DynamoDB
- Target:S3
を選択します。
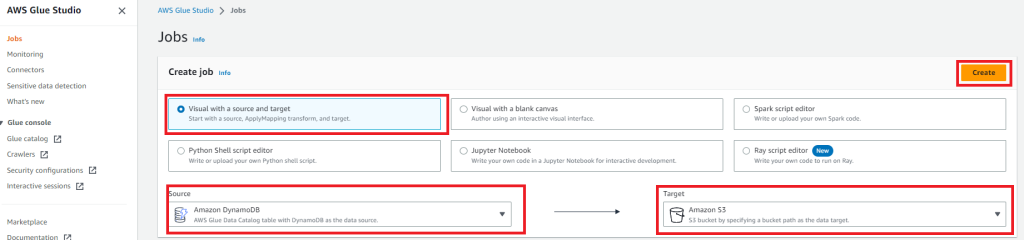
AWS GlueのジョブにはSparkとPython Shellの2つのジョブタイプがあります。Visual with a source and targetを選択するとSparkタイプとして作成されます。
Sparkタイプは、Apache Sparkを使用したデータの分散処理が可能なため、大規模データのETL処理に向いています。
Python Shellタイプは、Pythonを使用したスクリプトの実行が可能なため、Sparkタイプを使う程ではないがGlueジョブとして実行させたい処理に向いています。
Python Shellタイプを使用する場合はPython Shell script editorを選択します。(こちらはビジュアルエディタではなく、Lambdaと同じような感覚でコードを書くことができます。)
作成すると以下のようなビジュアル画面が表示されるのでソース、トランスフォーム、ターゲットを順に設定していきます。
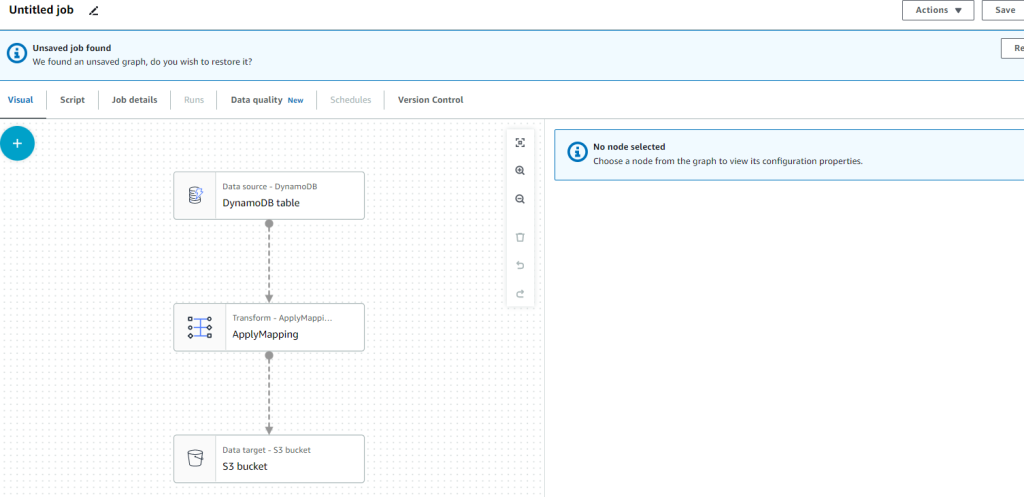
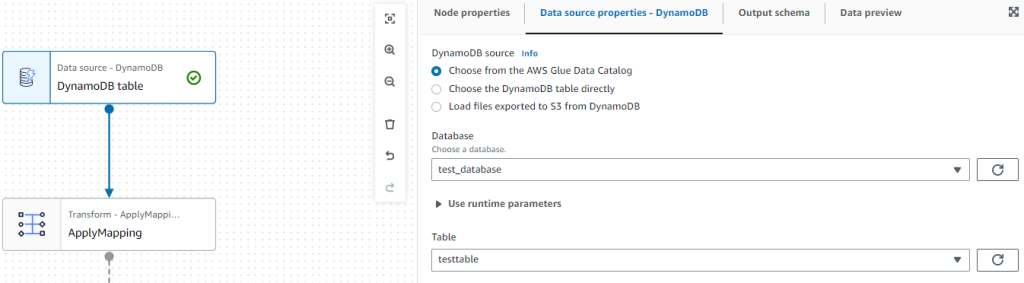
ジョブの設定:データソース
- Database:作成したデータベース
- Table:作成したテーブル
を選択します。
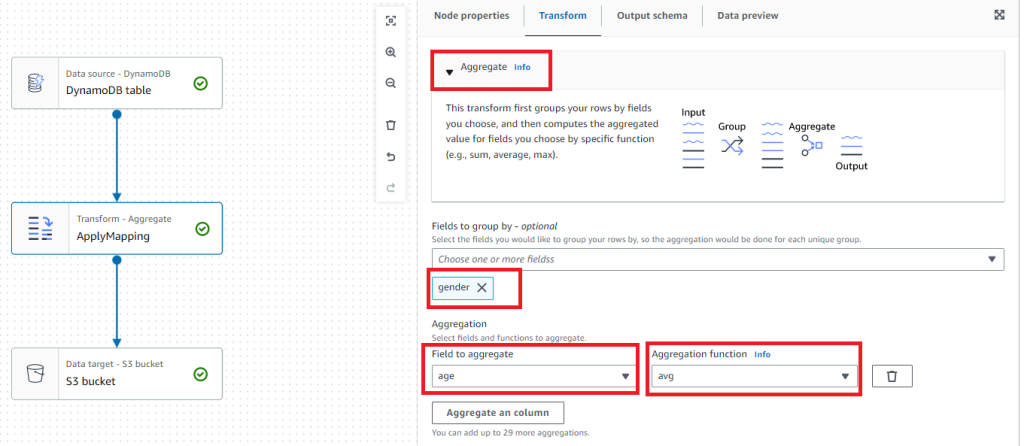
ジョブの設定:Transform
Node propertiesのタブを選択します。Aggregateを選択し、集計の条件を入力します。今回はgenderごとのageの平均とするので以下の通り入力します。
- Fields to group by – optional:gender
- Field to aggregate:age
- Aggregation function:avg
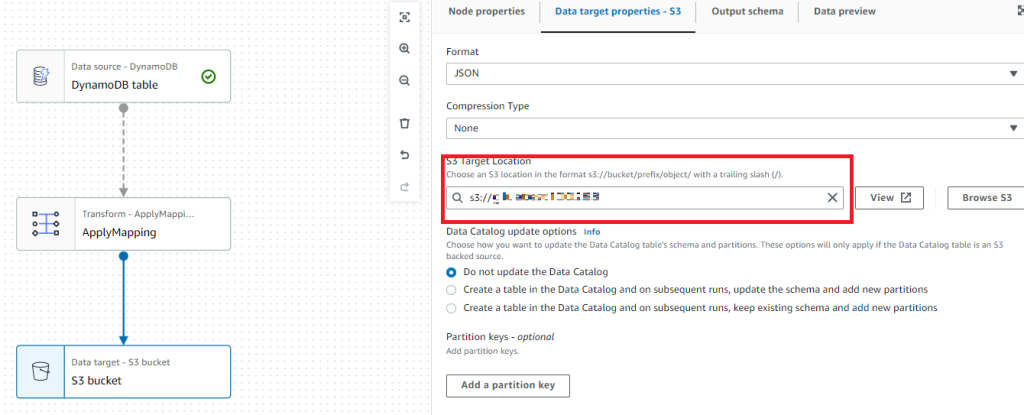
作成したS3バケットを選択しておきます。
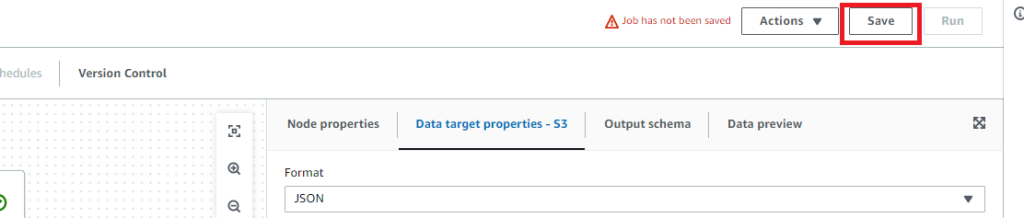
保存とエラー取り
忘れずにSaveしておきます。
するとエラーになるので直していきます。
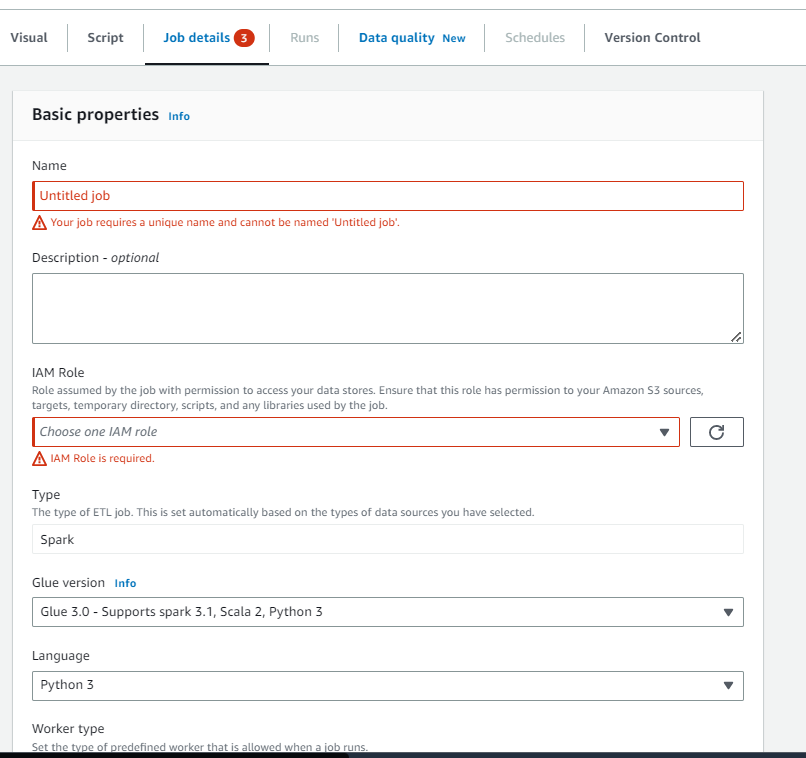
- Name:ジョブの名前
- IAM Role:作成したロールの名前
を入力します。
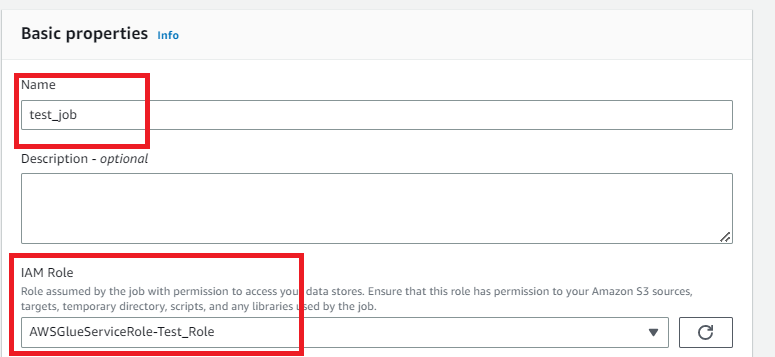
さらに下にスクロールしてAdvanced propertiesを展開します。
Script filenameに任意のスクリプト名を入力します。

そしてSaveを押下すると保存できるはずです。

補足:生成されるスクリプト
Scriptタブを確認するとこれまでコンソールでポチポチ選択した内容がスクリプトで表示されます。コンソールでは選択しきれない細かな集計を行いたい場合はこのスクリプトを編集すればよさそうです。
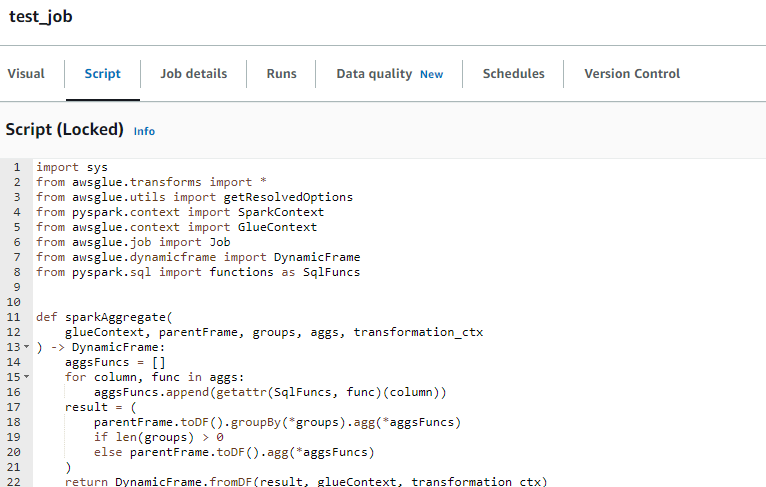
参考までに出力されたスクリプトを記載しておきます。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql import functions as SqlFuncs
def sparkAggregate(
glueContext, parentFrame, groups, aggs, transformation_ctx
) -> DynamicFrame:
aggsFuncs = []
for column, func in aggs:
aggsFuncs.append(getattr(SqlFuncs, func)(column))
result = (
parentFrame.toDF().groupBy(*groups).agg(*aggsFuncs)
if len(groups) > 0
else parentFrame.toDF().agg(*aggsFuncs)
)
return DynamicFrame.fromDF(result, glueContext, transformation_ctx)
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node DynamoDB table
DynamoDBtable_node1 = glueContext.create_dynamic_frame.from_catalog(
database="test_database",
table_name="testtable",
transformation_ctx="DynamoDBtable_node1",
)
# Script generated for node ApplyMapping
ApplyMapping_node2 = sparkAggregate(
glueContext,
parentFrame=DynamoDBtable_node1,
groups=["gender"],
aggs=[["age", "avg"]],
transformation_ctx="ApplyMapping_node2",
)
# Script generated for node S3 bucket
S3bucket_node3 = glueContext.write_dynamic_frame.from_options(
frame=ApplyMapping_node2,
connection_type="s3",
format="json",
connection_options={"path": "s3://XXXXXXXXXXXXX", "partitionKeys": []},
transformation_ctx="S3bucket_node3",
)
job.commit()
S3のバケットポリシーの設定
Glueに割り当てているIAMロールからS3へのアクセスを許可するためにバケットポリシーの設定を行います。
対象のバケットのアクセス許可タブからバケットポリシーを選択します。
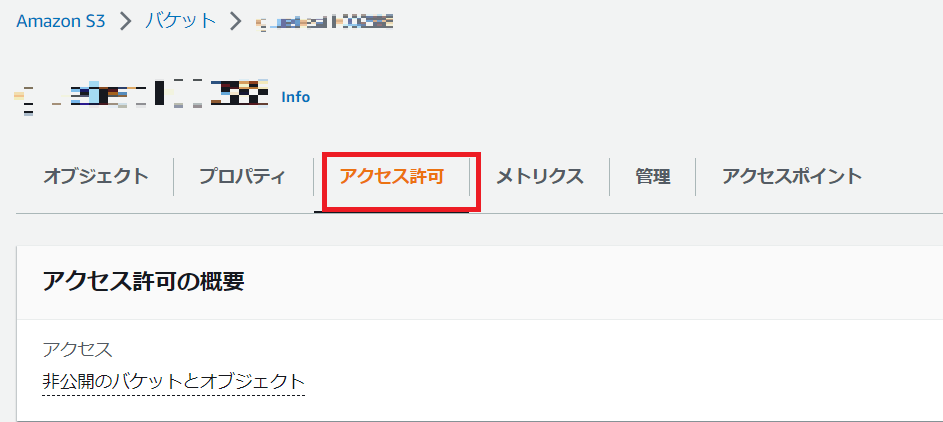
そしてバケットポリシーに以下を入力して保存してください。
{
"Version": "2012-10-17",
"Id": "PolicyAWSGlue",
"Statement": [
{
"Sid": "PolicyAWSGlue",
"Effect": "Allow",
"Principal": {
"AWS": "[作成したIAMロールのarn]"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::[バケット名]/*"
}
]
}Jobを実行して結果を確認する
再びGlue Studioのコンソールからジョブを選択してRunを押下して実行してみます。
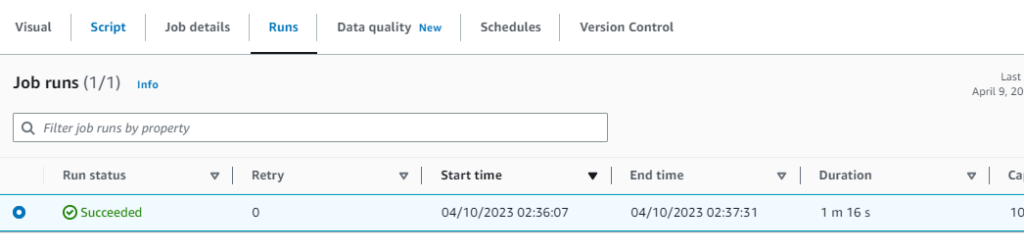
Runsタブから進捗を確認することができます。しばらくすると実行が完了するはずです。
するとS3に以下のファイルが出力されていました。(空のファイルも出力されていましたが、空のものは省略します。)
{"gender":"M","avg(age)":31.333333333333332}{"gender":"F","avg(age)":32.5}性別ごとの年齢の平均値が正しく出力されました!
最後に(感想)
GlueはよくLambdaと比較されるかと思います。Lambdaのタイムアウト時間(15分)以上かかるバッチ処理はGlueを使うことがあると思います。実際にGlueを構築してみて思ったより設定するべき項目が多くて大変だった印象でした。
設定できる箇所が多いということはそれだけ自由度も高いと思うのでじっくり使い方を勉強したいと思います。
PR
当ブログはWordPressテーマSWELLを使用しています。非常に使いやすく、簡単にプロのようなデザインを使えるのでお勧めです!!
SWELL – シンプル美と機能性両立を両立させた、圧巻のWordPressテーマ![]()
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。

システムエンジニア
AWSを中心としたクラウド案件に携わっています。
IoTシステムのバックエンド開発、Datadogを用いた監視開発など経験があります。
IT資格マニアでいろいろ取得しています。
AWS認定:SAP, DOP, SAA, DVA, SOA, CLF
Azure認定:AZ-104, AZ-300
ITIL Foundation
Oracle Master Bronze (DBA)
Oracle Master Silver (SQL)
Oracle Java Silver SE
■略歴
理系の大学院を卒業
IT企業に就職
AWSのシステム導入のプロジェクトを担当