AWS SAP無料問題集です。正解と解説を確認する際は右側のボタンを押下してください。
問題集の完全版は以下Udemyにて発売しているためお買い求めください。問題集への質問はUdemyのQA機能もしくはUdemyのメッセージにて承ります。Udemyの問題1から15問抜粋しております。
多くの方にご好評いただき、講師評価 4.5/5.0 を獲得できております。ありがとうございます。

特別価格: 通常2,600円 → 1,500円
講師クーポン適用で42%OFF
【図解付き】AWS SAP-C02完全対応 2025年版本番同等演習問題集+詳細解説

問題文:
企業がハイブリッドDNSソリューションを設計する必要があります。このソリューションは、VPC内に保存されているリソース用のcloud.example.comドメインに対してAmazon Route 53プライベートホストゾーンを使用します。企業には以下のDNS解決要件があります。
オンプレミスシステムがcloud.example.comを解決して接続できること。
すべてのVPCがcloud.example.comを解決できること。
オンプレミス企業ネットワークとAWS Transit Gatewayの間には既にAWS Direct Connect接続があります。
最高のパフォーマンスでこれらの要件を満たすために、企業はどのアーキテクチャを使用すべきでしょうか。
選択肢:
A. プライベートホストゾーンをすべてのVPCに関連付ける。共有サービスVPCにRoute 53 inbound resolverを作成する。すべてのVPCをTransit Gatewayに接続し、オンプレミスDNSサーバーでcloud.example.comのフォワーディングルールを作成してinbound resolverを指すようにする。
B. プライベートホストゾーンをすべてのVPCに関連付ける。共有サービスVPCにAmazon EC2 conditional forwarderを配置する。すべてのVPCをTransit Gatewayに接続し、オンプレミスDNSサーバーでcloud.example.comのフォワーディングルールを作成してconditional forwarderを指すようにする。
C. プライベートホストゾーンを共有サービスVPCに関連付ける。共有サービスVPCにRoute 53 outbound resolverを作成する。すべてのVPCをTransit Gatewayに接続し、オンプレミスDNSサーバーでcloud.example.comのフォワーディングルールを作成してoutbound resolverを指すようにする。
D. プライベートホストゾーンを共有サービスVPCに関連付ける。共有サービスVPCにRoute 53 inbound resolverを作成する。共有サービスVPCをTransit Gatewayに接続し、オンプレミスDNSサーバーでcloud.example.comのフォワーディングルールを作成してinbound resolverを指すようにする。
正解:A
A. プライベートホストゾーンをすべてのVPCに関連付ける。共有サービスVPCにRoute 53 inbound resolverを作成する。すべてのVPCをTransit Gatewayに接続し、オンプレミスDNSサーバーでcloud.example.comのフォワーディングルールを作成してinbound resolverを指すようにする。
正解: プライベートホストゾーンをすべてのVPCに関連付けることで、各VPCが直接ドメインを解決でき、最高のパフォーマンスを実現します。Route 53 inbound resolverによりオンプレミスからのDNSクエリを適切に処理し、Transit Gateway接続により全体的な接続性を確保します。この構成は、DNSクエリの転送が不要で最も効率的です。
B. プライベートホストゾーンをすべてのVPCに関連付ける。共有サービスVPCにAmazon EC2 conditional forwarderを配置する。すべてのVPCをTransit Gatewayに接続し、オンプレミスDNSサーバーでcloud.example.comのフォワーディングルールを作成してconditional forwarderを指すようにする。
不正解: EC2 conditional forwarderは、Active Directoryなどの特定の環境向けのソリューションです。この問題ではRoute 53ベースのDNS解決が求められており、EC2インスタンスでの条件転送はパフォーマンス要件を満たしません。追加のインスタンス管理が必要になり、単一障害点となるリスクもあります。
C. プライベートホストゾーンを共有サービスVPCに関連付ける。共有サービスVPCにRoute 53 outbound resolverを作成する。すべてのVPCをTransit Gatewayに接続し、オンプレミスDNSサーバーでcloud.example.comのフォワーディングルールを作成してoutbound resolverを指すようにする。
不正解: Route 53 outbound resolverはAWSからオンプレミスへのDNSクエリ転送に使用されるもので、この問題の要件とは方向が逆です。また、プライベートホストゾーンを共有サービスVPCのみに関連付けているため、他のVPCが直接ドメインを解決できず、すべてのVPCでの解決要件を満たしません。
D. プライベートホストゾーンを共有サービスVPCに関連付ける。共有サービスVPCにRoute 53 inbound resolverを作成する。共有サービスVPCをTransit Gatewayに接続し、オンプレミスDNSサーバーでcloud.example.comのフォワーディングルールを作成してinbound resolverを指すようにする。
不正解: inbound resolverの使用は正しいですが、プライベートホストゾーンを共有サービスVPCのみに関連付けているため、他のVPCが直接cloud.example.comを解決できません。これにより、すべてのVPCでの解決要件を満たさず、DNSクエリの転送が必要になってパフォーマンスも低下します。
全体的な説明
問われている要件
- オンプレミスシステムからcloud.example.comドメインへの解決と接続
- すべてのVPCからcloud.example.comドメインへの解決
- 既存のDirect ConnectとTransit Gateway接続の活用
- 最高レベルのパフォーマンスの実現
- ハイブリッド環境での統合的なDNS管理
前提知識
DNS解決サービスの特徴
- Route 53プライベートホストゾーンは、VPCに関連付けることでそのVPC内でのプライベートドメイン解決を提供します。複数のVPCに同じプライベートホストゾーンを関連付けることで、各VPCで同じドメインを解決できます。関連付けされていないVPCからは直接解決できず、DNSクエリの転送が必要になります。
- Route 53 Resolverエンドポイントには、inbound(オンプレミスからAWSへ)とoutbound(AWSからオンプレミスへ)の2種類があります。inbound resolverはオンプレミスDNSサーバーからのクエリをRoute 53で処理し、outbound resolverはVPCからのクエリをオンプレミスDNSサーバーに転送します。
ネットワーク接続サービスの特徴
- AWS Transit GatewayはVPCとオンプレミスネットワーク間の中央接続ハブとして機能します。複数のVPCを同時に接続でき、Direct Connectとの組み合わせで高帯域幅・低レイテンシの接続を提供します。フルメッシュ接続を簡素化し、ルーティング管理を集約化します。
- AWS Direct Connectは専用線接続によりオンプレミスとAWS間の安定した高性能通信を実現します。インターネット経由よりも一貫したネットワークパフォーマンスと低レイテンシを提供し、DNSトラフィックにも適用されます。
代替的なDNS転送方式について
- EC2ベースのconditional forwarderは、Windows DNS ServerやBINDなどをEC2インスタンス上で運用する方式です。管理オーバーヘッドが高く、可用性やスケーラビリティの観点でマネージドサービスより劣ります。Active Directory環境との統合などの特定用途で使用されることがあります。
解くための考え方
この問題を解く際は、まず2つの主要要件を明確に分離して考える必要があります。
第一に「すべてのVPCがcloud.example.comを解決できること」という要件から、プライベートホストゾーンをすべてのVPCに関連付ける必要があることが分かります。プライベートホストゾーンを共有サービスVPCのみに関連付けた場合、他のVPCは直接解決できずに転送が必要となり、パフォーマンス要件を満たしません。
第二に「オンプレミスシステムがcloud.example.comを解決・接続できること」という要件から、オンプレミスからAWSへのDNSクエリを処理するinbound resolverが必要であることが判明します。outbound resolverは方向が逆であり、EC2 conditional forwarderは管理複雑性とパフォーマンス面で適切ではありません。
最高のパフォーマンスという要件を考慮すると、各VPCがプライベートホストゾーンに直接関連付けられ、DNSクエリの転送が不要な構成が最適です。
アーキテクチャ図
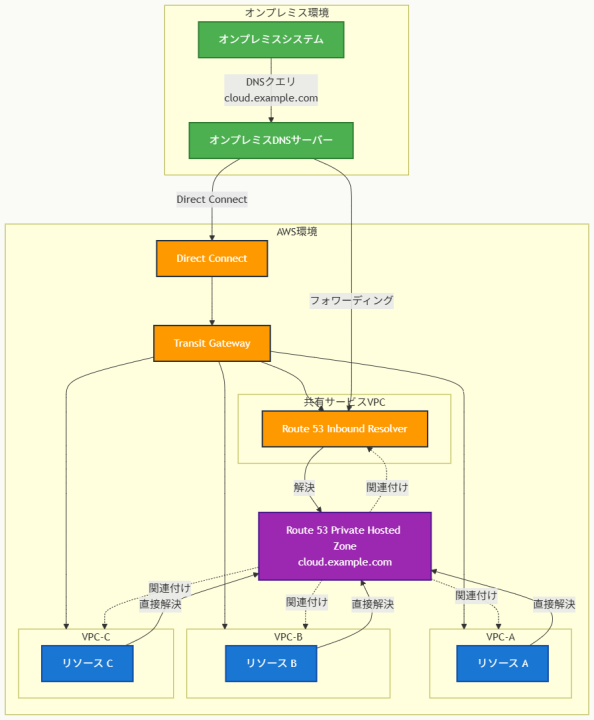
アーキテクチャ図の解説
DNS解決の基盤構成
このアーキテクチャでは、Route 53プライベートホストゾーンが各VPCに直接関連付けられています。VPC-A、VPC-B、VPC-CのそれぞれでRoute 53のDNSリゾルバー(VPCの.2アドレス)がプライベートホストゾーンに直接アクセスし、cloud.example.comの解決を行います。これにより、各VPC内のリソースは追加のネットワークホップなしに高速なDNS解決を実現できます。共有サービスVPCにも同様にプライベートホストゾーンが関連付けられ、inbound resolverエンドポイントからの解決要求に対応します。
ハイブリッド接続とDNSフロー処理
オンプレミスシステムからのcloud.example.comへのDNSクエリは、まずオンプレミスDNSサーバーで受信され、設定されたフォワーディングルールに基づいて共有サービスVPC内のRoute 53 inbound resolverに転送されます。このトラフィックはDirect Connect接続とTransit Gatewayを経由して高速かつ安定的に処理されます。inbound resolverは受信したクエリをRoute 53プライベートホストゾーンで解決し、結果をオンプレミスに返します。この設計により、オンプレミスとクラウド間で統一されたDNS名前空間が実現されます。
他のソリューションとの比較
主要な代替案として、プライベートホストゾーンを共有サービスVPCのみに関連付ける方式が考えられますが、この場合他のVPCからのDNSクエリは必ず共有サービスVPC経由の転送が必要となります。これにより追加のネットワークレイテンシが発生し、パフォーマンス要件を満たしません。また、EC2ベースのconditional forwarderを使用する方式もありますが、インスタンスの管理オーバーヘッド、可用性の課題、スケーラビリティの制限により、マネージドサービスであるRoute 53 Resolverより劣ります。
実装の考慮事項
実装時は、プライベートホストゾーンの各VPCへの関連付けを自動化し、新しいVPCが追加された際の手動作業を最小化することが重要です。inbound resolverエンドポイントは少なくとも2つのアベイラビリティゾーンに配置し、高可用性を確保する必要があります。オンプレミスDNSサーバーでのフォワーディングルール設定は、既存のDNS構成への影響を最小化するよう慎重に計画し、段階的な展開を検討することが推奨されます。また、DNSクエリのログ記録とモニタリング設定により、運用開始後のトラブルシューティングを容易にできます。
参考資料
- Amazon Route 53 とは - Amazon Route 53 ユーザーガイド
- プライベートホストゾーンの使用 - Amazon Route 53 ユーザーガイド
- Route 53 Resolver とは - Amazon Route 53 ユーザーガイド
- inbound エンドポイント - Amazon Route 53 ユーザーガイド
- AWS Transit Gateway とは - Amazon VPC ユーザーガイド
- AWS Direct Connect とは - AWS Direct Connect ユーザーガイド
- VPC とプライベートホストゾーンの関連付け - Amazon Route 53 ユーザーガイド
問題文:
企業が複数の顧客に対してREST APIベースで天気データを提供しています。APIはAmazon API Gatewayでホストされ、各API操作に対して異なるAWS Lambda関数と統合されています。企業はDNSにAmazon Route 53を使用し、weather.example.comのリソースレコードを作成しています。企業はAPIのデータをAmazon DynamoDBテーブルに保存しています。
企業はAPIが別のAWSリージョンにフェイルオーバーする機能を持つソリューションが必要です。これらの要件を満たすソリューションはどれでしょうか。
選択肢:
A. 新しいリージョンにLambda関数の新しいセットを配置する。API Gateway APIを更新して、両リージョンのLambda関数をターゲットとするエッジ最適化APIエンドポイントを使用する。DynamoDBテーブルをグローバルテーブルに変換する。
B. 新しいAPI Gateway APIとLambda関数を別のリージョンに配置する。Route 53 DNSレコードを複数値回答に変更する。両方のAPI Gateway APIを回答に追加する。ターゲットヘルスモニタリングを有効化する。DynamoDBテーブルをグローバルテーブルに変換する。
C. 新しいAPI Gateway APIとLambda関数を別のリージョンに配置する。Route 53 DNSレコードをフェイルオーバーレコードに変更する。ターゲットヘルスモニタリングを有効化する。DynamoDBテーブルをグローバルテーブルに変換する。
D. 新しいAPI Gateway APIを新しいリージョンに配置する。Lambda関数をグローバル関数に変更する。Route 53 DNSレコードを複数値回答に変更する。両方のAPI Gateway APIを回答に追加する。ターゲットヘルスモニタリングを有効化する。DynamoDBテーブルをグローバルテーブルに変換する。
正解:C
A. 新しいリージョンにLambda関数の新しいセットを配置する。API Gateway APIを更新して、両リージョンのLambda関数をターゲットとするエッジ最適化APIエンドポイントを使用する。DynamoDBテーブルをグローバルテーブルに変換する。
不正解: エッジ最適化APIエンドポイントはCloudFrontを活用してグローバルリーチを最適化しますが、API Gateway自体は単一リージョンに配置されるため、異なるAWSリージョンへのフェイルオーバー能力を提供しません。このアプローチはクライアントに最も近いリージョンからの応答を可能にしますが、リージョン障害時のフェイルオーバーには対応できません。
B. 新しいAPI Gateway APIとLambda関数を別のリージョンに配置する。Route 53 DNSレコードを複数値回答に変更する。両方のAPI Gateway APIを回答に追加する。ターゲットヘルスモニタリングを有効化する。DynamoDBテーブルをグローバルテーブルに変換する。
不正解: 複数値回答はアクティブ-アクティブシナリオを実装し、複数のIPアドレスを返してクライアント側でのロードバランシングを行います。これはフェイルオーバーではなく負荷分散の仕組みであり、メインリージョンが正常な場合でも両方のリージョンの接続先情報が提供されるため、問題で要求されているフェイルオーバー機能とは異なります。
C. 新しいAPI Gateway APIとLambda関数を別のリージョンに配置する。Route 53 DNSレコードをフェイルオーバーレコードに変更する。ターゲットヘルスモニタリングを有効化する。DynamoDBテーブルをグローバルテーブルに変換する。
正解: Route 53のフェイルオーバーレコードは、プライマリエンドポイントが正常な間はそちらへトラフィックを向け、プライマリエンドポイントが利用不可になった場合にセカンダリエンドポイントへ自動的に切り替わる、アクティブ-パッシブフェイルオーバーを実現します。ヘルスチェックと組み合わせることで、サービスの可用性に基づいた自動的なフェイルオーバーが可能になります。DynamoDBグローバルテーブルによりデータの一貫性も確保されます。
D. 新しいAPI Gateway APIを新しいリージョンに配置する。Lambda関数をグローバル関数に変更する。Route 53 DNSレコードを複数値回答に変更する。両方のAPI Gateway APIを回答に追加する。ターゲットヘルスモニタリングを有効化する。DynamoDBテーブルをグローバルテーブルに変換する。
不正解: Lambda関数の「グローバル関数」という概念は存在しません。また、複数値回答は負荷分散用の仕組みであり、フェイルオーバー用途には適していません。メインリージョンが正常でも両方のリージョンが名前解決で提供されるため、真のフェイルオーバーソリューションとはなりません。
全体的な説明
問われている要件
- REST APIの別AWSリージョンへのフェイルオーバー機能の実装
- 既存のAPI Gateway + Lambda + DynamoDB構成の維持
- Route 53を使用したDNSベースのフェイルオーバー制御
- ヘルスモニタリングによる自動的な障害検知と切り替え
- セカンダリリージョンでのデータ可用性確保
前提知識
Route 53ルーティングポリシーの特徴
- フェイルオーバールーティングポリシーは、アクティブ-パッシブフェイルオーバーを実装するために使用されます。プライマリレコードとセカンダリレコードを設定し、プライマリが利用不可の場合のみセカンダリに切り替わります。ヘルスチェックと組み合わせることで自動的なフェイルオーバーが可能で、最大30秒程度での切り替えが実現されます。
- 複数値回答ルーティングポリシーは、複数のIPアドレスを返してクライアント側での負荷分散を行います。ヘルスチェックに失敗したレコードは返されませんが、正常なレコードはすべて返されるため、フェイルオーバーではなく負荷分散の仕組みです。最大8つまでの正常なレコードがランダムに返されます。
API Gatewayのデプロイメント形態について
- エッジ最適化APIエンドポイントは、CloudFrontディストリビューションを自動作成してグローバルリーチを最適化します。ただし、API Gateway自体は特定のリージョンに配置され、リージョン障害時にはCloudFrontも機能しません。複数リージョンでのフェイルオーバーには、各リージョンに個別のAPI Gatewayが必要です。
- Regional APIエンドポイントは、特定のリージョン内でのみ利用可能で、そのリージョン内のクライアントに最適化されています。マルチリージョン構成では、各リージョンにリージョナルAPIを配置し、Route 53でトラフィック制御を行うのが一般的です。
データベースのマルチリージョン対応について
- DynamoDB Global Tablesは、複数のAWSリージョン間でテーブルデータを自動的に複製し、各リージョンで読み書きが可能なマルチマスター構成を提供します。結果整合性モデルを採用し、通常は1秒以内でリージョン間のデータ同期が完了します。リージョン障害時でも他のリージョンからデータアクセスが継続可能です。
解くための考え方
この問題では「フェイルオーバー」という要件が明確に示されているため、アクティブ-パッシブ構成を前提として考える必要があります。フェイルオーバーとは、通常時は単一のプライマリシステムが稼働し、障害時のみセカンダリシステムに切り替わる仕組みです。
Route 53のルーティングポリシーを比較すると、フェイルオーバーレコードは明確にアクティブ-パッシブフェイルオーバーを実装するための機能です。一方、複数値回答は複数の正常なエンドポイントを同時に返すため、負荷分散やアクティブ-アクティブ構成に適しており、フェイルオーバーの要件には合いません。
API Gatewayのエッジ最適化エンドポイントは、CloudFrontを使ってレスポンス性能を向上させますが、API Gateway自体は単一リージョンに存在するため、リージョン障害に対するフェイルオーバー機能は提供されません。真のマルチリージョンフェイルオーバーには、各リージョンに独立したAPI Gatewayが必要です。
アーキテクチャ図
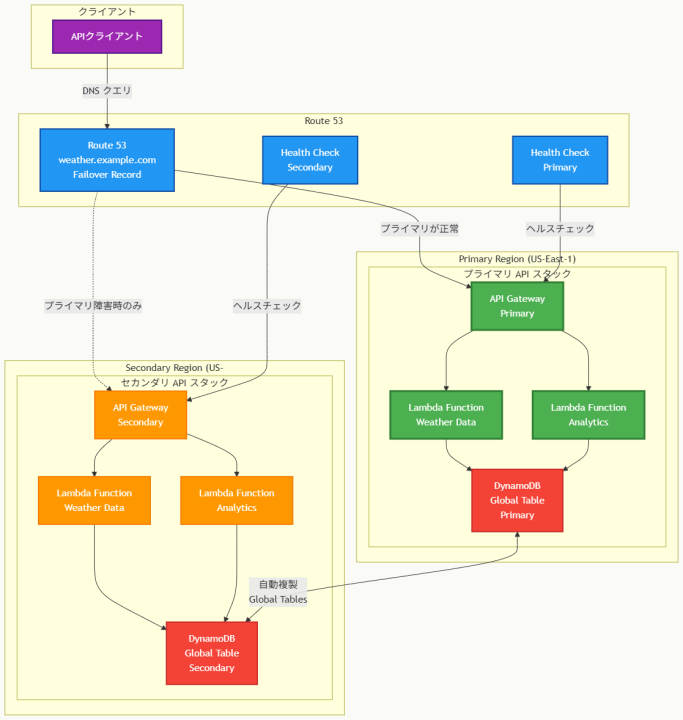
アーキテクチャ図の解説
フェイルオーバーメカニズムの動作原理
このアーキテクチャでは、Route 53のフェイルオーバーレコードがプライマリ-セカンダリ構成を管理します。通常時はRoute 53がweather.example.comのクエリに対してプライマリリージョン(US-East-1)のAPI Gatewayエンドポイントを返します。Route 53ヘルスチェックが継続的にプライマリAPI Gatewayの状態を監視し、応答がない場合や異常なステータスコードが返された場合に障害を検知します。プライマリが利用不可になると、Route 53は自動的にセカンダリリージョン(US-West-2)のAPI Gatewayエンドポイントを返すように切り替わります。
データの一貫性とサービス継続性
DynamoDB Global Tablesにより、両リージョン間でデータが自動的に複製されます。プライマリリージョンでのデータ更新は通常1秒以内にセカンダリリージョンに反映され、フェイルオーバー時にも最新のデータでサービス継続が可能です。各リージョンのLambda関数は同じビジネスロジックを実装しており、API Gatewayからのリクエストを受けてDynamoDBテーブルにアクセスします。この構成により、どちらのリージョンでも同等のAPI機能が提供されます。
他のソリューションとの比較
エッジ最適化エンドポイントは、CloudFrontの分散エッジロケーションを活用してグローバルなレスポンス性能を向上させますが、API Gateway自体は単一リージョンに配置されているため、そのリージョンが障害を起こした場合にはCloudFrontも機能しません。
複数値回答ルーティングポリシーは、複数の正常なエンドポイントを同時に返すため、アクティブ-アクティブ構成での負荷分散に適しています。しかし、プライマリリージョンが正常な場合でも両方のリージョンの情報が返されるため、フェイルオーバーの要件には適合しません。フェイルオーバーレコードは明確にアクティブ-パッシブ構成を実装し、障害時のみセカンダリに切り替わる動作を提供します。
実装の考慮事項
Route 53ヘルスチェックの設定では、適切なチェック間隔と失敗閾値を設定することが重要です。デフォルトの30秒間隔、3回連続失敗でのフェイルオーバーが一般的ですが、サービスの要件に応じて調整が必要です。API Gatewayのヘルスチェックエンドポイントは、単純なHTTP 200応答だけでなく、DynamoDBへの接続確認を含む実際のサービス状態を反映するよう実装することを推奨します。
DynamoDB Global Tablesの設定時には、結果整合性モデルの特性を理解し、アプリケーションレベルでの競合解決戦略を検討する必要があります。また、フェイルオーバー後のプライマリリージョン復旧時には、自動的にプライマリに戻るか手動切り替えにするかを運用ポリシーとして決定しておくことが重要です。
参考資料
- Amazon API Gateway による DNS フェイルオーバーの設定 – Amazon API Gateway 開発者ガイド
- フェイルオーバールーティング – Amazon Route 53 開発者ガイド
- Route 53 ヘルスチェックの作成と DNS フェイルオーバーの設定 – Amazon Route 53 開発者ガイド
- DynamoDB Global Tables – Amazon DynamoDB 開発者ガイド
- 複数値回答ルーティング – Amazon Route 53 開発者ガイド
- API Gateway エンドポイントのタイプの選択 – Amazon API Gateway 開発者ガイド
- AWS Lambda 関数の設定 – AWS Lambda 開発者ガイド
- Route 53 ヘルスチェックの作成、更新、削除 – Amazon Route 53 開発者ガイド
問題文:
企業がAWS Organizationsを使用して、Productionという名前の単一のOUで複数のアカウントを管理しています。すべてのアカウントはProduction OUのメンバーです。管理者は組織のルートで拒否リスト SCPを使用して、制限されたサービスへのアクセスを管理しています。
企業は最近新しい事業部門を買収し、新しい部門の既存のAWSアカウントを組織に招待しました。オンボーディング後、新しい事業部門の管理者は、企業のポリシーを満たすために既存のAWS Configルールを更新できないことを発見しました。
管理者が変更を行い、追加の長期メンテナンスを導入することなく現在のポリシーを引き続き実施できるオプションはどれでしょうか。
選択肢:
A. AWS Configへのアクセスを制限する組織のroot SCPを削除する。企業の標準AWS ConfigルールのためのAWS Service Catalogプロダクトを作成し、新しいアカウントを含む組織全体に展開する。
B. 新しいアカウント用にOnboardingという名前の一時的なOUを作成する。Onboarding OUにSCPを適用してAWS Configアクションを許可する。AWS Configの調整が完了したら新しいアカウントをProduction OUに移動する。
C. 組織のroot SCPを拒否リスト SCPから許可リスト SCPに変換して、必要なサービスのみを許可する。新しいアカウントのプリンシパルのみにAWS Configアクションを許可するSCPを組織のrootに一時的に適用する。
D. 新しいアカウント用にOnboardingという名前の一時的なOUを作成する。Onboarding OUにSCPを適用してAWS Configアクションを許可する。組織のroot SCPをProduction OUに移動する。AWS Configの調整が完了したら新しいアカウントをProduction OUに移動する。
正解:D
A. AWS Configへのアクセスを制限する組織のroot SCPを削除する。企業の標準AWS ConfigルールのためのAWS Service Catalogプロダクトを作成し、新しいアカウントを含む組織全体に展開する。
不正解: root SCPを削除することで、組織全体のセキュリティ制御が緩和され、設定ミスのリスクが増大します。また、AWS Service Catalogの使用は既存のAWS Configルールの更新問題を解決しません。Service Catalogプロダクトの作成と維持は継続的なメンテナンス負荷を増やし、問題の要求に反します。
B. 新しいアカウント用にOnboardingという名前の一時的なOUを作成する。Onboarding OUにSCPを適用してAWS Configアクションを許可する。AWS Configの調整が完了したら新しいアカウントをProduction OUに移動する。
不正解: root レベルで拒否リスト SCPがAWS Configを制限している場合、下位レベルのOnboarding OUでallow SCPを適用しても、rootのdenyが依然として優先されます。SCPは権限をフィルタリングするのみで追加することはできないため、上位レベルでブロックされた権限は下位レベルのallowでは克服できません。
C. 組織のroot SCPを拒否リスト SCPから許可リスト SCPに変換して、必要なサービスのみを許可する。新しいアカウントのプリンシパルのみにAWS Configアクションを許可するSCPを組織のrootに一時的に適用する。
不正解: 拒否リストから許可リスト SCPへの変換は、組織全体にわたる大幅な変更となり、多くのサービスを意図せずブロックする可能性があります。許可リストアーキテクチャは管理が困難で、新しいAWSサービスが追加されるたびに定期的な更新が必要となり、長期的なメンテナンス負荷を大幅に増加させます。
D. 新しいアカウント用にOnboardingという名前の一時的なOUを作成する。Onboarding OUにSCPを適用してAWS Configアクションを許可する。組織のroot SCPをProduction OUに移動する。AWS Configの調整が完了したら新しいアカウントをProduction OUに移動する。
正解: 制限的なSCPをrootからProduction OUに移動することで、Onboarding OUがこれらの制限から解放されます。現在すべてのアカウントがProduction OUに属しているため、この移動は既存アカウントへの影響を与えません。Onboarding OUには AWS Configアクションを許可する寛容なSCPを適用でき、設定完了後にアカウントをProduction OUに移動することで元の制限が再適用されます。
全体的な説明
問われている要件
- 新しいアカウントでのAWS Configルール更新権限の一時的な付与
- 既存のProduction OUアカウントに対する現在のポリシーの継続実施
- 追加の長期メンテナンス負荷の回避
- 組織全体のセキュリティ制御レベルの維持
- 長期メンテナンス無しの解決策での対応
前提知識
AWS Organizations SCPの動作原理について
- Service Control Policy(SCP)は権限をフィルタリングする機能のみを持ち、権限を付与することはありません。上位レベル(root、OU)でDenyされた権限は、下位レベル(OU、アカウント)でAllowを明記しても克服できません。権限が有効になるには、rootからアカウントまでのすべてのレベルで明示的なAllowが必要です。SCPは階層的に評価され、最も制限的なポリシーが適用されます。
- 拒否リスト戦略では、デフォルトでアクションが許可され、特定のサービスやアクションが禁止されます。許可リスト戦略では、デフォルトでアクションが禁止され、特定のサービスやアクションのみが明示的に許可されます。拒否リスト から許可リストへの変更は、組織全体の権限モデルを根本的に変更する大規模な作業です。
組織構造とOU管理について
- AWS Organizationsでは、rootは管理アカウントとすべてのOUおよびアカウントを含むコンテナです。rootレベルに適用されたSCPは、組織内のすべてのOUとアカウントに継承されます。OUレベルのSCPは、そのOU内のアカウントとサブOUにのみ適用されます。一時的なOUを作成することで、特定のアカウントに異なるポリシーセットを適用できます。
- アカウントの移動は、適用されるSCPセットを変更する効果的な方法です。アカウントを異なるOUに移動すると、新しいOUのSCPが適用され、以前のOUのSCPは適用されなくなります。この仕組みを活用して段階的なオンボーディングプロセスを実装できます。
AWS Service Catalogとの比較について
- AWS Service Catalogは標準化された製品(テンプレート)を通じてAWSリソースの配布を管理するサービスです。AWS Configルールの標準化には有効ですが、既存ルールの更新権限問題は解決しません。Service Catalogプロダクトの作成、維持、更新は継続的な管理作業を必要とし、長期メンテナンス負荷を増加させます。
解くための考え方
この問題の核心は、SCPの継承メカニズムを理解することです。rootレベルで拒否リスト SCPがAWS Configを制限している状況では、下位のOUでallow SCPを設定しても、rootのdenyが優先され、結果として権限は付与されません。
解決策を評価する際は、「一時的な変更で永続的な効果を得る」という観点が重要です。正解となる選択肢では、rootのSCPをProduction OUに移動することで、既存のすべてのアカウント(すべてProduction OUに属している)には同じ制限が継続して適用されます。同時に、新しいOnboarding OUは rootの制限から解放され、AWS Configアクションを許可するSCPを適用できます。
この構造変更は一時的でありながら、将来的な同様のオンボーディング作業でも再利用可能です。新しいアカウントの設定が完了すれば、そのアカウントをProduction OUに移動することで、組織の標準的な制限が自動的に適用されます。
アーキテクチャ図
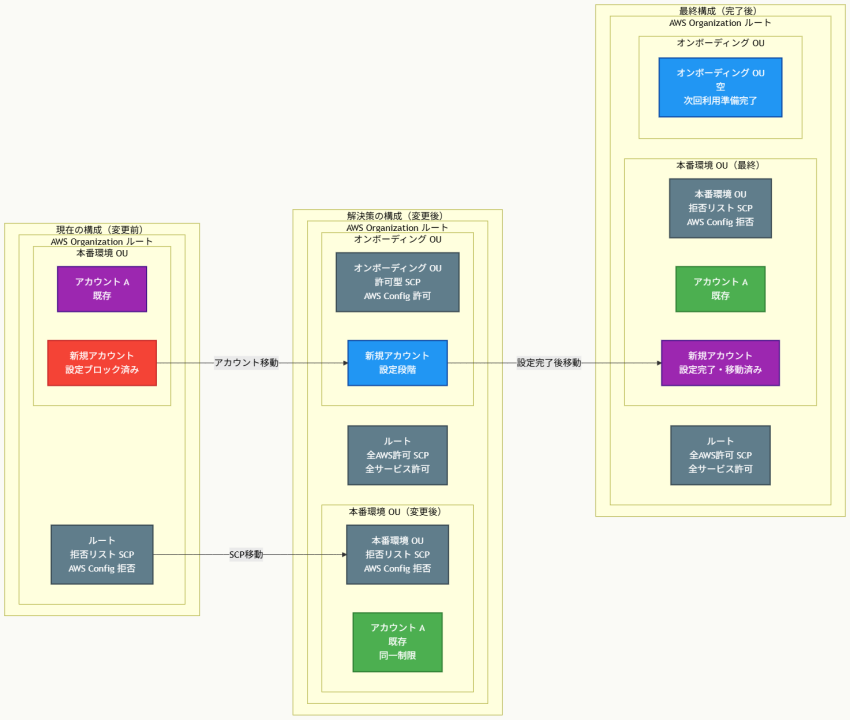
アーキテクチャ図の解説
フェイルオーバーメカニズムの動作原理
このアーキテクチャでは、組織構造の段階的変更を通じて、SCP継承の問題を解決します。現在の構成では、rootレベルの拒否リスト SCPがすべてのアカウントに適用され、新規アカウントのAWS Config設定を阻害しています。解決策の実装段階では、制限的なSCPをrootからProduction OUに移動し、代わりにrootには全AWS許可SCPを配置します。同時に新しいOnboarding OUを作成し、AWS Config操作を許可する寛容なSCPを適用することで、新規アカウントが必要な設定作業を実行できます。
権限制御の継続性確保
この構造変更の巧妙な点は、既存のすべてのアカウントがProduction OU内に留まるため、移動されたSCPにより従来と全く同じ制限を受け続けることです。rootレベルでの制限緩和は、新しく作成されたOnboarding OU配下のアカウントにのみ影響し、既存の本番環境への影響は皆無です。新規アカウントの設定完了後は、そのアカウントをProduction OUに移動することで、自動的に組織標準のセキュリティポリシーが適用され、一貫した権限管理が実現されます。
他のソリューションとの比較
根本的なSCP継承理解の違い 単純に一時的OUを作成してallow SCPを適用する手法では、rootレベルのdeny SCPが依然として全組織に影響するため、下位レベルでの許可設定は無効化されます。これは、SCPが権限をフィルタリングするのみで、上位レベルの制限を下位レベルで覆すことができないという基本原則によるものです。
一方、root SCPの完全削除やService Catalog導入による手法は、組織全体のセキュリティ制御を永続的に変更し、継続的なメンテナンス負荷を大幅に増加させます。また、拒否リストから許可リストへの根本的変更は、すべてのサービスを個別に許可する必要があり、新規AWSサービス追加時の対応も継続的に必要となります。正解手法は最小限の構造変更で問題を解決し、将来の同様ケースでも再利用可能な持続可能なソリューションを提供します。
実装の考慮事項
SCP移動時の影響範囲検証 実装前には、現在すべてのアカウントがProduction OUに属していることを厳密に確認し、root SCPの移動が既存運用に与える影響がないことを検証する必要があります。移動対象のSCPの具体的な制限内容を詳細に把握し、Production OUレベルでの適用が技術的に問題ないことを事前テストすることが重要です。
また、Onboarding OUの設計では、AWS Config設定に必要な最小権限のみを許可し、不要なサービスへのアクセスは制限することで、セキュリティリスクを最小化します。新規アカウントのオンボーディング完了基準を明確に定義し、Production OUへの移行タイミングと手順を標準化することで、運用の一貫性と再現性を確保することが推奨されます。
参考資料
- Service Control Policy (SCP) の管理 – AWS Organizations ユーザーガイド
- SCP のアタッチとデタッチ – AWS Organizations ユーザーガイド
- SCP の評価ロジック – AWS Organizations ユーザーガイド
- SCP の使用戦略 – AWS Organizations ユーザーガイド
- 組織単位 (OU) の管理 – AWS Organizations ユーザーガイド
- アカウントの組織単位間での移動 – AWS Organizations ユーザーガイド
- AWS Config の設定 – AWS Config 開発者ガイド
- 一時的な組織単位の使用 – AWS Organizations ホワイトペーパー
問題文:
企業がオンプレミスのデータセンターで2階層のWebベースアプリケーションを実行しています。アプリケーション層は、ステートフルアプリケーションを実行する単一サーバーで構成されています。アプリケーションは別サーバーで実行されているPostgreSQLデータベースに接続しています。アプリケーションのユーザーベースは大幅に増加すると予想されるため、企業はアプリケーションとデータベースをAWSに移行しています。このソリューションはAmazon Aurora PostgreSQL、Amazon EC2 Auto Scaling、Elastic Load Balancingを使用します。
アプリケーション層とデータベース層の両方をスケールできる一貫したユーザー体験を提供するソリューションはどれでしょうか。
選択肢:
A. Aurora ReplicasでAurora Auto Scalingを有効化する。最小未処理リクエストルーティングアルゴリズムとスティッキーセッションを有効にしたNetwork Load Balancerを使用する。
B. Aurora ライターでAurora Auto Scalingを有効化する。ラウンドロビンルーティングアルゴリズムとスティッキーセッションを有効にしたApplication Load Balancerを使用する。
C. Aurora ReplicasでAurora Auto Scalingを有効化する。ラウンドロビンルーティングとスティッキーセッションを有効にしたApplication Load Balancerを使用する。
D. Aurora ライターでAurora Scalingを有効化する。最小未処理リクエストルーティングアルゴリズムとスティッキーセッションを有効にしたNetwork Load Balancerを使用する。
正解:C
解説:
A. Aurora ReplicasでAurora Auto Scalingを有効化する。最小未処理リクエストルーティングアルゴリズムとスティッキーセッションを有効にしたNetwork Load Balancerを使用する。
不正解 Aurora ReplicasでのAuto Scalingは正しい機能ですが、Network Load Balancerは最小未処理リクエストルーティングアルゴリズムをサポートしていません。NLBはFlow hashアルゴリズムのみサポートし、ラウンドロビンや最小未処理リクエストなどの高レベルルーティング機能は提供されません。また、ステートフルアプリケーションに必要なスティッキーセッション管理も限定的です。
B. Aurora ライターでAurora Auto Scalingを有効化する。ラウンドロビンルーティングアルゴリズムとスティッキーセッションを有効にしたApplication Load Balancerを使用する。
不正解 Aurora ライターに対するAuto Scalingは存在しない機能です。Auroraクラスターでは、シングルマスターモードにおいて常に単一のライターインスタンスが存在し、writeインスタンスの数を自動的にスケールする機能はありません。Aurora Auto Scalingは読み取り専用のAurora Replicasに対してのみ利用可能です。
C. Aurora ReplicasでAurora Auto Scalingを有効化する。ラウンドロビンルーティングとスティッキーセッションを有効にしたApplication Load Balancerを使用する。
正解 Aurora Auto Scalingは読み取りレプリカに対して正しく機能し、読み取り集約的なワークロードのスケーリングを実現します。Application Load Balancerはラウンドロビンルーティングとスティッキーセッションの両方をサポートし、ステートフルアプリケーションに必要なセッション親和性を維持できます。この組み合わせにより、アプリケーション層の水平スケーリングと一貫したユーザー体験を同時に実現できます。
D. Aurora ライターでAurora Scalingを有効化する。最小未処理リクエストルーティングアルゴリズムとスティッキーセッションを有効にしたNetwork Load Balancerを使用する。
不正解 Aurora ライターに対するスケーリング機能は存在せず、さらにNetwork Load Balancerは最小未処理リクエストアルゴリズムをサポートしていません。NLBの基本的な制限により、Webアプリケーションのレイヤーでのインテリジェントなトラフィック分散や適切なセッション管理を実現できません。
全体的な説明
問われている要件
- ステートフルアプリケーションの一貫したユーザー体験の維持
- アプリケーション層とデータベース層の両方でのスケーラビリティ
- PostgreSQLデータベースのAurora PostgreSQLへの移行対応
- EC2 Auto Scalingを活用した動的なアプリケーション層スケーリング
- 適切なロードバランサーの選択とルーティングアルゴリズム設定
前提知識
Amazon Aurora Auto Scalingの特徴
- Aurora Auto Scalingは読み取り専用のAurora Replicasに対してのみ利用可能で、アプリケーションのワークロードに基づいて自動的にレプリカを追加・削除します。CPUやコネクション使用率などのメトリクスを監視し、スケーリングポリシーに基づいて1分から15分のスケーリング期間で動的に調整します。各クラスターは最大15個のAurora Replicasまでサポートし、読み取りパフォーマンスを向上させます。
- Auroraライターに対するAuto Scalingは技術的に存在しません。Auroraクラスターは常に単一のプライマリーライター instanceを持ち、write操作は必ずこのインスタンスを経由します。Multi-master構成も存在しますが、これはAuto Scalingとは異なる概念で、複数のwrite-capable instanceを手動で管理する仕組みです。
Load Balancerのルーティング機能について
- Application Load Balancer(ALB)は、HTTPSレベルでの高度なルーティング機能を提供し、ラウンドロビン、最小未処理リクエスト、ウェイテッドターゲット等の複数のアルゴリズムをサポートします。スティッキーセッション(セッション親和性)機能により、同一ユーザーからのリクエストを一貫して同じターゲットにルーティングできます。WebアプリケーションのHTTP/HTTPSトラフィックに最適化されています。
- Network Load Balancer(NLB)は、TCPレイヤーでの高性能な負荷分散を提供し、主にFlow hashアルゴリズムを使用します。NLBは超高スループットと低レイテンシに最適化されているものの、アプリケーションレベルでのインテリジェントなルーティングやHTTPベースのスティッキーセッション管理は限定的です。
ステートフルアプリケーションの要件について
- ステートフルアプリケーションは、ユーザーセッション情報やアプリケーション状態をサーバー側で保持するため、同一ユーザーのリクエストを一貫して同じサーバーインスタンスに送信する必要があります。スティッキーセッション機能により、ロードバランサーがcookieやIP hashingを使用して特定のクライアントを特定のバックエンドサーバーに関連付けます。これにより、セッション情報の一貫性が保たれ、ユーザー体験が維持されます。
解くための考え方
この問題を解く際の核心は、Aurora Auto Scalingの正確な理解とロードバランサーの機能制限の認識です。
まず、Aurora Auto Scalingが読み取りレプリカ(Aurora Replicas)に対してのみ利用可能であることを理解する必要があります。Auroraクラスターでは、常に単一のプライマリー ライターが存在し、すべての書き込み操作はこのインスタンスを経由します。読み取り処理の負荷分散とスケーリングは、Aurora Replicasを追加することで実現されます。
次に、ステートフルアプリケーションの要件を考慮すると、スティッキーセッション機能が必須となります。ユーザーセッション情報がサーバー側で管理されているため、同一ユーザーからのリクエストは一貫して同じアプリケーションインスタンスに送信される必要があります。
Network Load BalancerとApplication Load Balancerの機能比較では、NLBは主にTCPレベルでの高性能負荷分散に特化しており、アプリケーションレベルでのインテリジェントなルーティング機能は限定的です。一方、ALBはHTTPSレベルでの高度な機能を提供し、ラウンドロビンアルゴリズムとスティッキーセッションの両方を完全にサポートします。
アーキテクチャ図
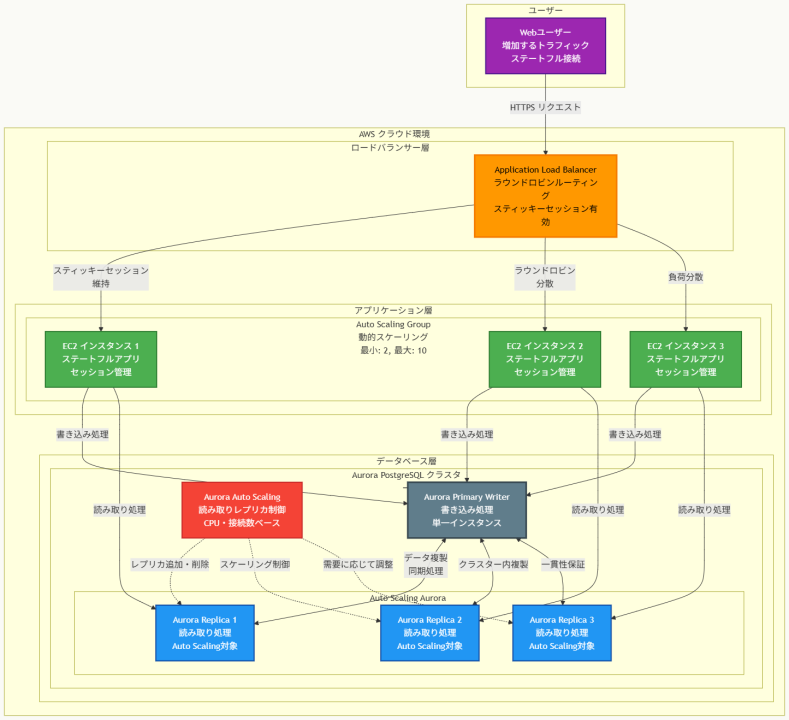
アーキテクチャ図の解説
スケーラブルなアプリケーション層の構成
このアーキテクチャでは、Application Load Balancerがスティッキーセッション機能を使用して、同一ユーザーからのリクエストを一貫して同じEC2インスタンスにルーティングします。ラウンドロビンアルゴリズムにより、新規ユーザーのトラフィックは利用可能なインスタンス間で均等に分散され、EC2 Auto Scaling Groupが需要に応じてインスタンス数を動的に調整します。この設計により、ステートフルアプリケーションのセッション一貫性を維持しながら、水平スケーリングを実現できます。
データベース層の読み取りスケーリング戦略
Aurora PostgreSQLクラスターでは、単一のプライマリー ライターインスタンスがすべての書き込み処理を担当し、複数のAurora Replicasが読み取り処理を分散して処理します。Aurora Auto Scalingサービスが、CPU使用率やデータベース接続数などのメトリクスを監視し、読み取り負荷に応じてレプリカの数を自動的に調整します。この構成により、読み取り集約的なワークロードに対して効率的なスケーリングを提供し、アプリケーションの応答性能を向上させます。
他のソリューションとの比較
Network Load Balancerとの機能的差異
Network Load Balancerは超高性能なTCPレベルでの負荷分散を提供しますが、HTTPSレベルでのインテリジェントなルーティング機能が限定的です。最小未処理リクエストアルゴリズムはNLBでサポートされておらず、Flow hashアルゴリズムのみが利用可能です。また、WebアプリケーションのセッションCookieベースのスティッキーセッション管理も制約があり、ステートフルWebアプリケーションには適していません。
Application Load Balancerは、HTTP/HTTPSトラフィックに特化した高度な機能を提供し、アプリケーションレベルでのルーティング決定、コンテンツベースルーティング、完全なスティッキーセッション管理を実現します。Webアプリケーションの要件には、ALBの方が技術的に適合します。
Aurora ライター Auto Scalingの技術的制約
一部の選択肢で言及されているAurora ライター Auto Scalingは、技術的に存在しない機能です。Auroraアーキテクチャでは、クラスター内で常に単一のプライマリー ライターインスタンスが存在し、書き込み処理の一貫性と整合性を保証します。Aurora Multi-Master構成も存在しますが、これは複数の書き込み対応インスタンスを手動で管理する仕組みであり、Auto Scalingとは異なります。読み取りスケーリングのみがAurora Auto Scalingで自動化されています。
実装の考慮事項
セッション管理とスティッキーセッション設定 ステートフルアプリケーションの移行時には、セッション情報の永続化戦略を慎重に検討する必要があります。インメモリセッション管理から、外部セッションストア(ElastiCache等)の利用への移行を検討することで、より堅牢なスケーリング対応が可能になります。ALBのスティッキーセッション設定では、適切なCookie有効期間とフェイルオーバー戦略を設定し、インスタンス障害時のセッション継続性を確保します。
Aurora Auto Scalingのメトリクス調整 Aurora Auto Scalingの設定では、CPUUtilizationやDatabaseConnectionsなどのメトリクスしきい値を、アプリケーションの実際の負荷パターンに基づいて調整することが重要です。スケールアウト・スケールインのクールダウン期間を適切に設定し、頻繁なスケーリング動作によるコスト増加や性能低下を防止します。また、読み取り専用クエリとトランザクション処理を適切に分離し、レプリカでの読み取り処理を最大化するアプリケーション設計の見直しも推奨されます。
参考資料
- Amazon Aurora Auto Scaling の使用 – Amazon Aurora ユーザーガイド
- Aurora レプリカ – Amazon Aurora ユーザーガイド
- Application Load Balancer とは – Elastic Load Balancing
- スティッキーセッション – Elastic Load Balancing
- Amazon EC2 Auto Scaling とは – Amazon EC2 Auto Scaling
- Network Load Balancer とは – Elastic Load Balancing
- Aurora PostgreSQL の使用 – Amazon Aurora ユーザーガイド
問題文:
小売企業が、ビジネスパートナーである他の企業に対してデータファイル群を提供する必要があります。これらのファイルは小売企業のアカウント(Account A)のAmazon S3バケットに保存されています。
パートナー企業は自社のAWSアカウント(Account B)のIAMユーザー「User_DataProcessor」がそのファイルにアクセスできるようにしたいと考えています。
User_DataProcessorがS3バケットに正常にアクセスできるようにするために、両社が実行すべき手順の組み合わせはどれですか。(2つ選択)
選択肢:
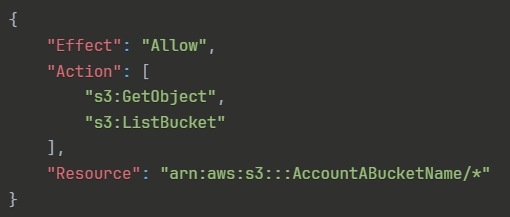
A. Account AのS3バケットでクロスオリジンリソース共有(CORS)機能を有効にする
B. Account Aで、S3バケットポリシーを以下のように設定する:

C. Account Aで、S3バケットポリシーを以下のように設定する:
D. Account Bで、User_DataProcessorの権限を以下のように設定する:
E. Account Bで、User_DataProcessorの権限を以下のように設定する:
正解:C, D
解説:
A. Account AのS3バケットでクロスオリジンリソース共有(CORS)機能を有効にする
不正解 CORS機能は、ウェブブラウザからの異なるドメイン間でのリソースアクセスを制御するセキュリティ機能です。これはHTTPリクエストレベルでの制御であり、AWSアカウント間でのAPIアクセスには関係ありません。クロスアカウントアクセスの実現にはIAMポリシーとバケットポリシーの組み合わせが必要で、CORSは不適切な選択肢です。
B. Account Aで、S3バケットポリシーを以下のように設定する:
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::AccountABucketName/*"
}不正解 このバケットポリシーにはPrincipal要素が含まれていません。バケットポリシーではPrincipalによってアクセスを許可する対象を明示的に指定する必要があります。Principalが未指定の場合、どのアカウントやユーザーがこの権限を行使できるかが不明確となり、セキュリティ上の問題が発生します。有効なバケットポリシーには必ずPrincipalが必要です。
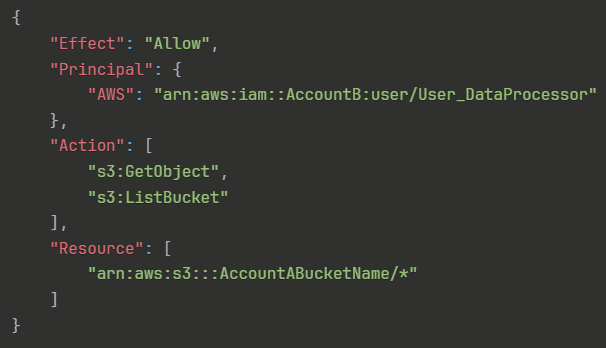
C. Account Aで、S3バケットポリシーを以下のように設定する:
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::AccountB:user/User_DataProcessor"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::AccountABucketName/*"
]
}正解 Account BのUser_DataProcessorを明示的にPrincipalとして指定し、s3:GetObjectとs3:ListBucketアクションを許可する適切なバケットポリシーです。クロスアカウントアクセスでは、リソース側(Account A)でリソースベースポリシーによって他のアカウントのプリンシパルに明示的に権限を付与する必要があります。このポリシーがクロスアカウントアクセスの基盤となります。
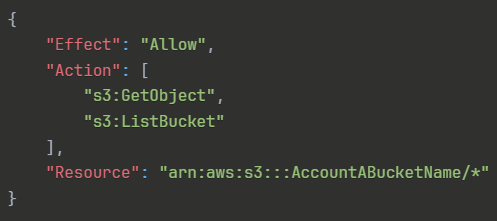
D. Account Bで、User_DataProcessorの権限を以下のように設定する:
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::AccountABucketName/*"
}正解 Account BのUser_DataProcessorにAccount AのS3バケットへのアクセス権限を付与するIAMポリシーです。クロスアカウントアクセスでは、リソース側のバケットポリシーだけでなく、アクセスする側のプリンシパルにも適切な権限が必要です。このアイデンティティベースポリシーによって、ユーザーが実際にS3 APIを呼び出す権限を取得できます。
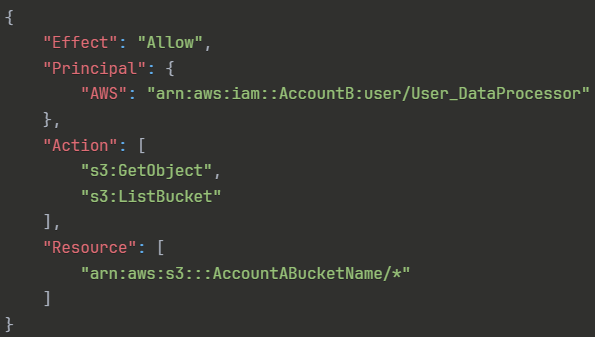
E. Account Bで、User_DataProcessorの権限を以下のように設定する:
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::AccountB:user/User_DataProcessor"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::AccountABucketName/*"
]
}不正解 IAMポリシーにはPrincipal要素を含めるべきではありません。IAMポリシーは既に特定のプリンシパル(ユーザー、グループ、ロール)にアタッチされるため、ポリシー内でPrincipalを再度指定することは冗長で構文的にも不正確です。この形式はバケットポリシーなどのリソースベースポリシーで使用されるべき構文です。
全体的な説明
問われている要件
- Account AのS3バケットに対するAccount BのIAMユーザーからのクロスアカウントアクセス
- ファイルの読み取り権限(s3:GetObject)とバケット一覧権限(s3:ListBucket)の提供
- セキュアで最小権限の原則に基づいた権限設定
- 両社間でのセキュリティ境界を跨いだデータ共有の実現
- 特定のIAMユーザーに限定した細かい粒度でのアクセス制御
前提知識
クロスアカウントアクセスの仕組みについて
- AWSでは異なるアカウント間でのリソース共有時に、両方のアカウントでの明示的な許可が必要です。これは「明示的許可の原則」として知られ、セキュリティを確保するための重要な機能です。
- リソースベースポリシー(バケットポリシーなど)とアイデンティティベースポリシー(IAMポリシー)の両方による許可が必要となります。一方のみでは不十分で、両方の許可が揃って初めてアクセスが可能になります。
S3のアクセス制御メカニズムについて
- バケットポリシーは特定のバケットに適用されるリソースベースポリシーで、どのプリンシパルがどのようなアクションを実行できるかを定義します。Principal要素でアクセス対象を明示的に指定する必要があります。
- IAMポリシーはユーザー、グループ、ロールにアタッチされるアイデンティティベースポリシーで、そのプリンシパルが実行可能なアクションとリソースを定義します。
- s3:ListBucketはバケットレベルの権限で、s3:GetObjectはオブジェクトレベルの権限です。両者のリソースARNの形式が異なることに注意が必要です。
IAMとS3の権限評価について
- AWSの権限評価では、明示的な拒否が最優先され、次に明示的な許可が評価されます。デフォルトではすべてのアクセスが拒否されています。
- クロスアカウントアクセスでは、リソース側とアクセス元側の両方でAllow文が存在する必要があり、どちらか一方でもDenyがあればアクセスは拒否されます。
解くための考え方
この問題は典型的なクロスアカウントアクセス問題です。AWSにおけるクロスアカウントアクセスの実現には、必ず両側での明示的な許可設定が必要という原則を理解することが重要です。
まず、リソース所有者側(Account A)では、バケットポリシーによって他のアカウントのプリンシパルに対する明示的なアクセス許可を設定する必要があります。この際、Principal要素でアクセスを許可する対象を具体的に指定することが必須です。プリンシパルが未指定のポリシーでは、セキュリティ上の問題があり機能しません。
次に、アクセス元側(Account B)では、対象ユーザーにIAMポリシーをアタッチして実際にS3 APIを呼び出す権限を付与する必要があります。これらの二つの設定が揃って初めて、セキュアなクロスアカウントアクセスが実現できます。
CORSは、ウェブブラウザからの異なるドメインへのリクエスト制御機能であり、AWS API呼び出しには関係ありません。また、IAMポリシー内でのPrincipal指定は構文的に不正確で、IAMポリシーは既にプリンシパルにアタッチされているため冗長です。
アーキテクチャ図
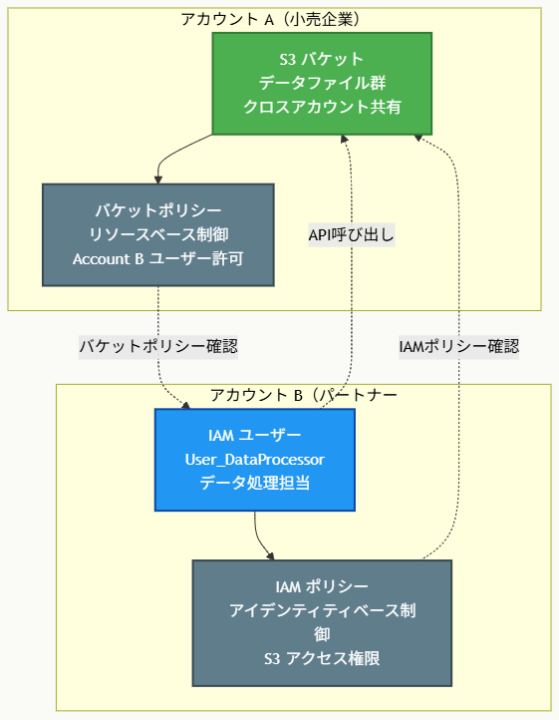
アーキテクチャ図の解説
アクセス権限の双方向設定
このアーキテクチャでは、クロスアカウントアクセスに必要な二つの重要な権限設定が示されています。Account AのS3バケットに設定されるバケットポリシーは、リソース側からの明示的な許可を表し、Account BのUser_DataProcessorを具体的なPrincipalとして指定してアクセスを許可します。一方、Account BのIAMポリシーは、ユーザー側からのアクション実行権限を表し、外部アカウントのS3リソースに対するAPI呼び出しを可能にします。
権限評価フローとセキュリティ
図中の矢印は権限評価の流れを示しています。User_DataProcessorがS3 APIを呼び出すと、まずAWSは該当ユーザーのIAMポリシーを確認してアクション実行権限があるかを検証します。次に、対象S3バケットのバケットポリシーを確認して、そのプリンシパルからのアクセスが許可されているかを評価します。両方の確認で許可が得られた場合のみアクセスが成功し、どちらか一方でも許可がない場合はアクセスが拒否されます。
最小権限の原則の実装
この構成では、必要最小限の権限のみが付与されており、s3:GetObjectとs3:ListBucketという特定のアクションのみに限定されています。バケットポリシーでは特定のユーザーのみをPrincipalとして指定し、IAMポリシーでは特定のリソースARNのみを対象としているため、セキュリティリスクを最小限に抑えながら効果的なデータ共有が実現されています。
他のソリューションとの比較
この問題では、バケットポリシーのみで十分という考え方や、IAMポリシー内でPrincipal要素を使用する方法についても検討する必要があります。
バケットポリシーのみでのアクセス制御では、リソース側からの許可は得られますが、Account Bのユーザーが実際にS3 APIを呼び出す権限がないため機能しません。クロスアカウントアクセスでは必ず両側での許可が必要という原則があるため、アクセス元側での権限設定も必須となります。
IAMポリシー内でPrincipal要素を使用する方法については、これはリソースベースポリシーでのみ使用されるべき構文であり、IAMポリシーとしては不適切です。適切な構文による両側での明示的許可を実現する組み合わせが、セキュアで確実なクロスアカウントアクセスを実現する唯一の正解となります。
実装の考慮事項
実装時にはいくつかの重要な点を考慮する必要があります。s3:ListBucket権限は実際にはバケット自体に対する権限であるため、ResourceにはバケットARN(「arn:aws:s3:::AccountABucketName」)も含めるべきですが、問題の選択肢では簡略化されています。
また、バケットポリシーのサイズ制限(20KB)やIAMポリシーのサイズ制限(2KB for inline、6KB for managed)を考慮し、将来的な拡張性も検討してマネージドポリシーの使用を検討すべきです。
セキュリティ面では、MFA要求やIP制限などの追加条件も検討し、アクセスログの設定によって監査要件も満たす必要があります。
参考資料
問題文:
企業が従来のWebアプリケーションをAmazon EC2インスタンス上で実行しています。同社はこのアプリケーションをコンテナ上で動作するマイクロサービスとしてリファクタリングする必要があります。アプリケーションには本番環境とテスト環境という2つの異なる環境で別々のバージョンが存在します。アプリケーションの負荷は変動しますが、最小負荷と最大負荷は分かっています。
ソリューションアーキテクトは、運用の複雑さを最小限に抑えるサーバーレスアーキテクチャでアップデートされたアプリケーションを設計する必要があります。
これらの要件を最もコスト効率よく満たすソリューションはどれですか。
選択肢:
A. コンテナイメージをAWS Lambdaに関数としてアップロードする。関連するLambda関数に予想されるピーク負荷を処理するための同時実行制限を設定する。Amazon API Gateway内で2つの別々のLambda統合を設定する:1つは本番用、もう1つはテスト用。
B. コンテナイメージをAmazon Elastic Container Registry(Amazon ECR)にアップロードする。予想される負荷を処理するためにFargate起動タイプを使用した2つの自動スケーリングされるAmazon Elastic Container Service(Amazon ECS)クラスターを設定する。ECRイメージからタスクをデプロイする。ECSクラスターにトラフィックを振り分けるために2つの別々のApplication Load Balancerを設定する。
C. コンテナイメージをAmazon Elastic Container Registry(Amazon ECR)にアップロードする。予想される負荷を処理するためにFargate起動タイプを使用した2つの自動スケーリングされるAmazon Elastic Kubernetes Service(Amazon EKS)クラスターを設定する。ECRイメージからタスクをデプロイする。EKSクラスターにトラフィックを振り分けるために2つの別々のApplication Load Balancerを設定する。
D. コンテナイメージをAWS Elastic Beanstalkにアップロードする。Elastic Beanstalkで、本番環境とテスト環境用に別々の環境とデプロイメントを作成する。Elastic Beanstalkデプロイメントにトラフィックを振り分けるために2つの別々のApplication Load Balancerを設定する。
正解:B
解説:
A. コンテナイメージをAWS Lambdaに関数としてアップロードする。関連するLambda関数に予想されるピーク負荷を処理するための同時実行制限を設定する。Amazon API Gateway内で2つの別々のLambda統合を設定する:1つは本番用、もう1つはテスト用。
不正解 Lambdaは2020年からコンテナイメージをサポートしていますが、選択肢の表現「コンテナイメージをAWS Lambdaにアップロード」は技術的に不正確です。実際にはECRにイメージをアップロードし、Lambdaがそこからプルするのが正しい手順です。また、従来のWebアプリケーションをLambdaで実行する際には15分の実行時間制限やコールドスタートの問題があり、アプリケーションの大幅な改修が必要となる場合があります。
B. コンテナイメージをAmazon Elastic Container Registry(Amazon ECR)にアップロードする。予想される負荷を処理するためにFargate起動タイプを使用した2つの自動スケーリングされるAmazon Elastic Container Service(Amazon ECS)クラスターを設定する。ECRイメージからタスクをデプロイする。ECSクラスターにトラフィックを振り分けるために2つの別々のApplication Load Balancerを設定する。
正解 ECRにコンテナイメージを格納し、ECSとFargateを使用した完全なサーバーレス環境を提供します。Fargateはインフラ管理を完全に排除し、使用したリソース分のみの課金となります。自動スケーリング機能により負荷変動に対応でき、ALBによる適切な負荷分散が可能です。本番環境とテスト環境の分離も実現でき、運用複雑性を最小限に抑えながらコスト効率性を実現できます。
C. コンテナイメージをAmazon Elastic Container Registry(Amazon ECR)にアップロードする。予想される負荷を処理するためにFargate起動タイプを使用した2つの自動スケーリングされるAmazon Elastic Kubernetes Service(Amazon EKS)クラスターを設定する。ECRイメージからタスクをデプロイする。EKSクラスターにトラフィックを振り分けるために2つの別々のApplication Load Balancerを設定する。
不正解 EKSはKubernetesベースの高度なコンテナオーケストレーションサービスですが、この問題の要件に対してはオーバーエンジニアリングとなります。EKSはECSと比較してコントロールプレーンの追加料金が発生し、Kubernetesの専門知識が必要で運用複雑性が高くなります。単純なマイクロサービス化の要件に対してはコスト効率が劣ります。
D. コンテナイメージをAWS Elastic Beanstalkにアップロードする。Elastic Beanstalkで、本番環境とテスト環境用に別々の環境とデプロイメントを作成する。Elastic Beanstalkデプロイメントにトラフィックを振り分けるために2つの別々のApplication Load Balancerを設定する。
不正解 Elastic BeanstalkはPaaSサービスですが、基盤となるEC2インスタンスを使用するためサーバーレスアーキテクチャではありません。インフラの管理要素が残り、サーバーの起動時間やアイドル時間に対する課金が発生するため、サーバーレス要件を満たさず、コスト効率性でも劣ります。
全体的な説明
問われている要件
- 従来のWebアプリケーションのマイクロサービス化とコンテナ化
- 本番環境とテスト環境の明確な分離
- 可変負荷に対応する自動スケーリング機能
- 運用複雑性を最小限に抑えるサーバーレスアーキテクチャ
- 最もコスト効率的なソリューションの実現
前提知識
サーバーレスコンテナサービスの特徴について
- AWS Fargateは完全なサーバーレスコンピュートエンジンで、EC2インスタンスの管理が不要です。使用したCPUとメモリリソースに基づいて秒単位の課金が行われ、最低1分の課金単位があります。
- ECS(Elastic Container Service)はAWS独自のコンテナオーケストレーションサービスで、シンプルな設定でコンテナを運用でき、Fargateとの組み合わせで完全なサーバーレス環境を構築できます。
- EKS(Elastic Kubernetes Service)はKubernetesベースの高機能なサービスですが、コントロールプレーンの管理費用が別途発生し、Kubernetesの専門知識が必要で運用が複雑になります。
コンテナ管理とスケーリングについて
- Amazon ECRはフルマネージドなDockerコンテナレジストリで、高可用性とセキュリティを提供し、他のAWSサービスとのシームレスな統合が可能です。
- Application Load Balancer(ALB)はレイヤー7での負荷分散を提供し、コンテナベースのアプリケーションに最適化された機能を持ちます。パスベースやホストベースのルーティングにより、マイクロサービス間の通信を効率化できます。
- 自動スケーリング機能により、CPU使用率やメモリ使用率などのメトリクスに基づいてコンテナインスタンスを動的に増減できます。
Lambdaコンテナサポートについて
- AWS Lambdaは2020年12月からコンテナイメージのサポートを開始し、最大10GBまでのイメージに対応しています。しかし、15分の実行時間制限があり、従来のWebアプリケーションには適さない場合があります。
- Lambdaのコンテナ機能を使用する場合でも、実際にはECRにイメージを格納し、Lambdaがプルする仕組みとなります。直接Lambdaにアップロードするわけではありません。
解くための考え方
この問題の解決には、サーバーレスアーキテクチャの定義と各サービスの特性を正確に理解することが重要です。要件として「運用複雑性の最小化」と「最もコスト効率的」という2つのキーポイントが示されています。
まず、サーバーレスアーキテクチャの定義から考えると、インフラ管理が不要で、使用した分だけ課金されるサービスを選択する必要があります。Lambdaは確かに完全なサーバーレスですが、従来のWebアプリケーションをそのままマイクロサービス化する場合、実行時間制限やコールドスタートの問題を考慮する必要があります。
一方、ECS+Fargateの組み合わせは、コンテナに特化したサーバーレスソリューションとして設計されており、従来のWebアプリケーションの移行に適しています。インフラ管理は完全に排除され、必要なリソース分のみの課金となるため、コスト効率性も優れています。
運用複雑性の観点では、EKSはKubernetesの専門知識が必要で複雑すぎます。Elastic BeanstalkはEC2ベースでサーバーレス要件を満たしません。したがって、要件を満たすバランスの取れたソリューションとしてECS+Fargateの組み合わせが最適となります。
アーキテクチャ図
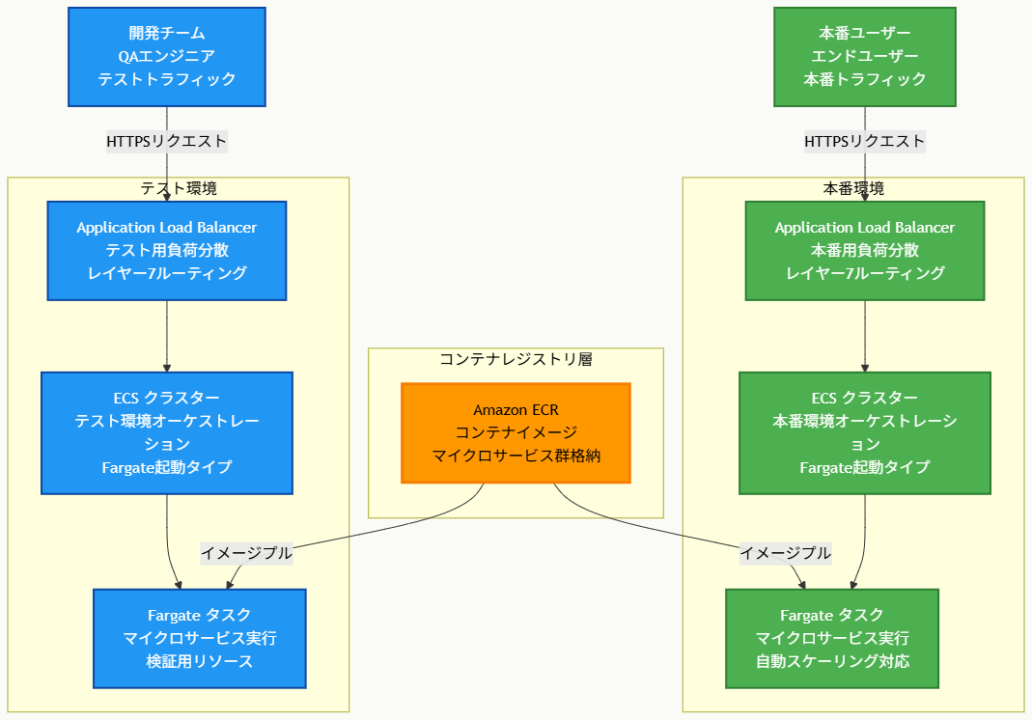
アーキテクチャ図の解説
コンテナイメージの一元管理と配信
Amazon ECRが全体のコンテナレジストリとして機能し、マイクロサービス化されたアプリケーションのコンテナイメージを安全に格納します。ECRからは本番環境とテスト環境の両方のFargateタスクに対してイメージがプルされ、一貫性のあるデプロイメントが実現されます。このアーキテクチャにより、イメージの管理が一元化され、セキュリティスキャンやバージョン管理も効率的に行えます。
環境分離とサーバーレス実行
本番環境とテスト環境は完全に分離されたECSクラスターとして構築されており、それぞれ独立したApplication Load Balancerによってトラフィックが制御されます。各環境のFargateタスクは完全にサーバーレスで動作し、インフラの管理が不要でありながら、負荷に応じた自動スケーリングが可能です。これにより運用複雑性が大幅に軽減されます。
負荷分散とトラフィック制御
各環境のApplication Load Balancerは、マイクロサービス間の効率的な負荷分散を提供し、パスベースやホストベースのルーティングによって個々のサービスへの適切なトラフィック振り分けを実現します。自動スケーリング機能と連携することで、変動する負荷に対して動的にリソースを調整し、コスト効率性と性能の両立を図ります。
他のソリューションとの比較
Lambdaベースのソリューションとの比較では、確かにLambdaは完全なサーバーレスでインボケーション単位の課金となりますが、従来のWebアプリケーションをマイクロサービス化する際の実用性に課題があります。15分の実行時間制限は長時間処理やセッション管理を必要とするWebアプリケーションには不適切で、コールドスタートによる初回レスポンス遅延も問題となります。
一方、ECS+Fargateのソリューションは、コンテナ化されたWebアプリケーションに最適化されており、実行時間制限がなく、継続的なセッション管理やステートフルな処理にも対応できます。また、実際の使用リソースに基づく秒単位の課金により、コスト効率性も確保されています。
EKSとの比較においても、Kubernetesの高度な機能は今回の要件には過剰であり、コントロールプレーンの追加コストや専門知識の要求が運用複雑性を増加させます。ECSは設定がシンプルで、マイクロサービス化の基本的な要件を満たしながらコスト効率性を重視した最適解となります。
実装の考慮事項
実装時にはセキュリティ、モニタリング、デプロイメント戦略の3つの側面を重視する必要があります。ECRのイメージスキャン機能を活用してコンテナの脆弱性検査を自動化し、IAMロールによる最小権限の原則を適用してタスク間のアクセス制御を行います。
また、CloudWatchによる包括的なモニタリング設定により、各マイクロサービスのパフォーマンスメトリクス、ログ、アラームを統合管理することが重要です。Application Insightsやサービスマップ機能を活用して、マイクロサービス間の依存関係と通信パターンを可視化し、問題の早期発見と解決を可能にします。
デプロイメント戦略では、Blue/Greenデプロイメントやローリングアップデートを活用して、本番環境への影響を最小限に抑えながら継続的なデプロイメントを実現します。CodePipelineやCodeDeployとの統合により、CI/CDパイプラインを構築し、テスト環境での検証を経て本番環境へ安全にデプロイする仕組みを整備することが推奨されます。
参考資料
問題文:
企業がApplication Load Balancer(ALB)の背後にあるAmazon EC2インスタンス群で動作する複数層Webアプリケーションを運用しています。インスタンスはAuto Scalingグループ内にあります。ALBとAuto Scalingグループはバックアップ用AWSリージョンでも複製されています。Auto Scalingグループの最小値と最大値はゼロに設定されています。Amazon RDS マルチAZ DBインスタンスがアプリケーションのデータを格納しており、DBインスタンスはバックアップリージョンにリードレプリカを持っています。アプリケーションはAmazon Route 53レコードを使用してエンドユーザーにエンドポイントを提供しています。
同社は、アプリケーションがバックアップリージョンに自動的にフェイルオーバーできる機能を提供することで、RTOを15分未満に短縮する必要があります。同社にはアクティブ・アクティブ戦略に対する十分な予算がありません。
これらの要件を満たすためにソリューションアーキテクトが推奨すべきものは何ですか。
選択肢:
A. アプリケーションのRoute 53レコードを、2つのALB間でトラフィックを負荷分散するレイテンシベースルーティングポリシーで再設定する。バックアップリージョンにAWS Lambda関数を作成してリードレプリカを昇格させ、Auto Scalingグループの値を変更する。プライマリリージョンのALBのHTTPCode_Target_5XX_Countメトリクスに基づくAmazon CloudWatchアラームを作成する。CloudWatchアラームがLambda関数を呼び出すように設定する。
B. バックアップリージョンにAWS Lambda関数を作成してリードレプリカを昇格させ、Auto Scalingグループの値を変更する。Webアプリケーションを監視し、ヘルスチェックステータスが異常な場合にAmazon Simple Notification Service(Amazon SNS)通知をLambda関数に送信するヘルスチェックでRoute 53を設定する。ヘルスチェック失敗時にバックアップリージョンのALBにトラフィックをルーティングするフェイルオーバーポリシーでアプリケーションのRoute 53レコードを更新する。
C. バックアップリージョンのAuto Scalingグループを、プライマリリージョンのAuto Scalingグループと同じ値に設定する。2つのALB間でトラフィックを負荷分散するレイテンシベースルーティングポリシーでアプリケーションのRoute 53レコードを再設定する。リードレプリカを削除する。リードレプリカを独立したRDS DBインスタンスに置き換える。スナップショットとAmazon S3を使用してRDS DBインスタンス間でクロスリージョンレプリケーションを設定する。
D. 2つのALBを同じ重みのターゲットとしてAWS Global Acceleratorでエンドポイントを設定する。バックアップリージョンにAWS Lambda関数を作成してリードレプリカを昇格させ、Auto Scalingグループの値を変更する。プライマリリージョンのALBのHTTPCode_Target_5XX_Countメトリクスに基づくAmazon CloudWatchアラームを作成する。CloudWatchアラームがLambda関数を呼び出すように設定する。
正解:B
解説:
A. アプリケーションのRoute 53レコードを、2つのALB間でトラフィックを負荷分散するレイテンシベースルーティングポリシーで再設定する。バックアップリージョンにAWS Lambda関数を作成してリードレプリカを昇格させ、Auto Scalingグループの値を変更する。プライマリリージョンのALBのHTTPCode_Target_5XX_Countメトリクスに基づくAmazon CloudWatchアラームを作成する。CloudWatchアラームがLambda関数を呼び出すように設定する。
不正解 レイテンシベースルーティングポリシーは両方のリージョンに継続的にトラフィックを分散させるため、実質的にアクティブ・アクティブ戦略となります。これは予算制約に合いません。また、HTTPCode_Target_5XX_Countメトリクスのみでは、完全なリージョン障害や部分的なサービス停止を適切に検知できない場合があります。
B. バックアップリージョンにAWS Lambda関数を作成してリードレプリカを昇格させ、Auto Scalingグループの値を変更する。Webアプリケーションを監視し、ヘルスチェックステータスが異常な場合にAmazon Simple Notification Service(Amazon SNS)通知をLambda関数に送信するヘルスチェックでRoute 53を設定する。ヘルスチェック失敗時にバックアップリージョンのALBにトラフィックをルーティングするフェイルオーバーポリシーでアプリケーションのRoute 53レコードを更新する。
正解 フェイルオーバーポリシーによるアクティブ・パッシブ戦略で、平常時はプライマリリージョンのみが稼働するためコスト効率的です。Route 53のヘルスチェック機能がWebアプリケーションを監視し、異常検知時にSNS通知を介してLambda関数が起動されます。Lambda関数がリードレプリカの昇格とAuto Scalingグループの設定変更を自動実行し、15分以内のRTO要件を満たします。
C. バックアップリージョンのAuto Scalingグループを、プライマリリージョンのAuto Scalingグループと同じ値に設定する。2つのALB間でトラフィックを負荷分散するレイテンシベースルーティングポリシーでアプリケーションのRoute 53レコードを再設定する。リードレプリカを削除する。リードレプリカを独立したRDS DBインスタンスに置き換える。スナップショットとAmazon S3を使用してRDS DBインスタンス間でクロスリージョンレプリケーションを設定する。
不正解 バックアップリージョンのAuto Scalingグループを常に稼働状態に設定し、レイテンシベースルーティングで負荷分散するため、完全なアクティブ・アクティブ戦略となります。これは予算制約に明確に反します。また、スナップショットベースのレプリケーションはリアルタイム性に欠け、データ損失のリスクが高くなります。
D. 2つのALBを同じ重みのターゲットとしてAWS Global Acceleratorでエンドポイントを設定する。バックアップリージョンにAWS Lambda関数を作成してリードレプリカを昇格させ、Auto Scalingグループの値を変更する。プライマリリージョンのALBのHTTPCode_Target_5XX_Countメトリクスに基づくAmazon CloudWatchアラームを作成する。CloudWatchアラームがLambda関数を呼び出すように設定する。
不正解 Global Acceleratorで両方のALBを同じ重みで設定することは、トラフィックを両リージョンに分散させるアクティブ・アクティブ戦略を意味します。これも予算制約に合わず、通常時からバックアップリージョンのリソースが稼働するため運用コストが高くなります。
全体的な説明
問われている要件
- RTOを15分未満に短縮する自動フェイルオーバー機能の実装
- アクティブ・アクティブ戦略に対する予算制約の考慮
- 複数層Webアプリケーションの可用性確保
- プライマリリージョンとバックアップリージョン間の効果的な切り替え
- データベースレプリカの自動昇格機能
前提知識
ディザスタリカバリ戦略の種類について
- アクティブ・パッシブ戦略では、平常時は一つのリージョンのみが稼働し、障害時に別のリージョンに切り替えます。コスト効率が高い反面、切り替え時間が必要です。
- アクティブ・アクティブ戦略では、複数のリージョンが同時に稼働してトラフィックを分散処理します。高可用性を実現しますが、運用コストが大幅に増加します。
- RTOは障害発生から復旧完了までの時間で、RPOは障害時点から最後のバックアップまでのデータ損失許容時間です。
Route 53のヘルスチェックとルーティングポリシーについて
- フェイルオーバーポリシーはプライマリとセカンダリのリソースを定義し、プライマリの障害時にセカンダリに自動切り替えを行います。アクティブ・パッシブ戦略に最適です。
- レイテンシベースルーティングは各リージョンの応答時間に基づいてトラフィックを分散し、実質的にアクティブ・アクティブ戦略となります。
- ヘルスチェック機能は定期的にエンドポイントの状態を監視し、異常検知時にSNS通知やRoute 53のフェイルオーバーを自動実行できます。
AWS Lambda とRDSレプリカ管理について
- Lambda関数はRDS APIを使用してリードレプリカを独立したDBインスタンスに昇格させることができます。この処理は通常数分で完了します。
- Auto Scaling GroupのMinCapacityとMaxCapacityの変更により、バックアップリージョンのEC2インスタンスを迅速に起動できます。
- SNSとLambdaの統合により、Route 53のヘルスチェック失敗を契機とした自動化されたフェイルオーバープロセスを構築できます。
解くための考え方
この問題の核心は、コスト制約がある中でのディザスタリカバリ戦略の選択です。予算制約により「アクティブ・アクティブ戦略ではない」という明確な要件が示されており、これがソリューション選択の決定的な要因となります。
まず、アクティブ・アクティブ戦略を採用する選択肢を除外する必要があります。レイテンシベースルーティングや重み付きルーティング、Global Acceleratorでの同等な重み分散は、いずれも複数リージョンで継続的にリソースを稼働させるため、運用コストが大幅に増加します。
次に、15分以内のRTO要件を満たすためには、障害検知から復旧完了までの各ステップを自動化する必要があります。Route 53のヘルスチェックによる障害検知、SNS通知によるイベント伝達、Lambda関数による自動復旧処理(リードレプリカ昇格、Auto Scaling設定変更)の組み合わせが、この要件を効率的に満たします。
HTTPCode_Target_5XX_Countメトリクスのみでは、ALBレベルでの部分的な障害は検知できても、完全なリージョン障害や基盤インフラの問題を適切に検知できない可能性があります。一方、Route 53のヘルスチェックは、エンドツーエンドでのアプリケーション動作を監視するため、より包括的な障害検知が可能となります。
アーキテクチャ図
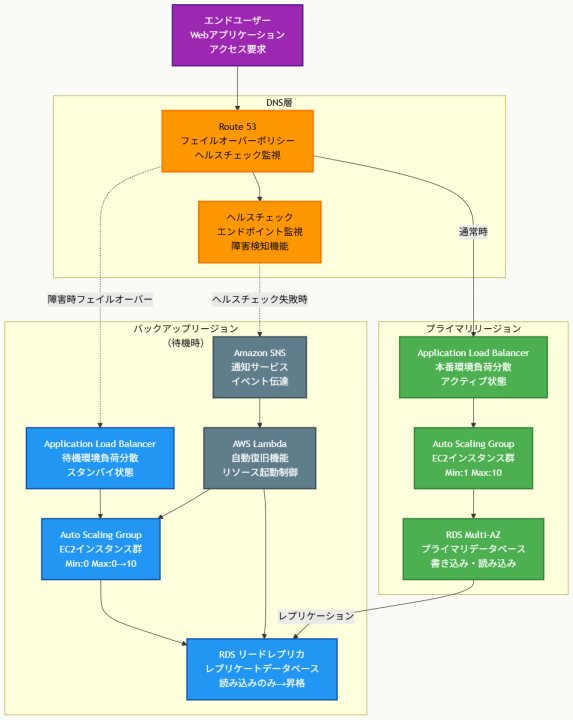
アーキテクチャ図の解説
アクティブ・パッシブ戦略による効率的な障害対応
このアーキテクチャでは、通常時はプライマリリージョンのみが稼働し、バックアップリージョンは最小限のリソース(Auto Scalingグループの最小値:0)で待機状態を維持します。Route 53のフェイルオーバーポリシーにより、プライマリリージョンの障害検知時に自動的にトラフィックがバックアップリージョンに切り替わります。この方式により、通常時の運用コストを大幅に削減しながら、障害時には迅速な復旧を実現できます。
自動化された復旧プロセスの実装
障害検知から復旧までの全プロセスが自動化されています。Route 53のヘルスチェックがプライマリリージョンの異常を検知すると、SNS通知を通じてバックアップリージョンのLambda関数が起動されます。Lambda関数は並行してリードレプリカの独立DBインスタンスへの昇格とAuto Scalingグループの設定変更(最小値・最大値の更新)を実行し、数分以内にバックアップリージョンでの完全な運用環境を構築します。
コスト効率性と可用性の両立
平常時はプライマリリージョンのリソースとバックアップリージョンの最小限のリソース(RDSリードレプリカ、設定済みALBとAuto Scalingグループ)のみが稼働するため、アクティブ・アクティブ戦略と比較して運用コストが大幅に削減されます。同時に、自動化された復旧プロセスにより15分以内のRTO要件を満たし、ビジネス継続性を確保できます。
他のソリューションとの比較
レイテンシベースルーティングやGlobal Acceleratorを使用するソリューションでは、複数リージョンに継続的にトラフィックが分散されるため、実質的にアクティブ・アクティブ戦略となります。これらの方式では両方のリージョンでEC2インスタンスとRDSインスタンスを常時稼働させる必要があり、運用コストが2倍近くに増加します。
CloudWatchアラームのHTTPCode_Target_5XX_Countメトリクスのみに依存するアプローチでは、ALBレベルでの局所的な問題は検知できても、ネットワーク障害や完全なリージョン停止のような包括的な障害を適切に検知できない可能性があります。一方、Route 53のヘルスチェックはエンドツーエンドでのアプリケーション動作を監視するため、より確実な障害検知が可能です。
フェイルオーバーポリシーとSNS統合によるソリューションは、障害検知の精度、復旧の自動化レベル、コスト効率性のバランスが最も優れており、予算制約下での災害復旧要件を最適に満たします。
実装の考慮事項
実装時には、ヘルスチェックの設定が重要な要素となります。ヘルスチェックの頻度は30秒から300秒の間で設定でき、障害検知の迅速性とコストのバランスを考慮して決定する必要があります。また、ヘルスチェックエンドポイントには、データベース接続やバックエンドサービスの状態も含めた包括的な診断機能を実装することが推奨されます。
Lambda関数の実装では、RDSレプリカの昇格処理とAuto Scalingグループの設定変更を並行実行することで、復旧時間の短縮を図ることができます。また、Lambda関数の実行時間制限(最大15分)を考慮し、長時間を要する処理についてはStep Functionsの使用も検討すべきです。
セキュリティ面では、Lambda関数に必要最小限のIAM権限のみを付与し、SNSトピックのアクセス制御も適切に設定する必要があります。また、復旧プロセスの監査ログを確実に記録し、復旧後の検証手順も事前に定義しておくことが重要です。
参考資料
- Route 53 ヘルスチェックの設定 – Amazon Route 53
- DNS フェイルオーバーの設定 – Amazon Route 53
- フェイルオーバールーティングポリシー – Amazon Route 53
- RDS リードレプリカの昇格 – Amazon RDS
- Auto Scaling グループの設定変更 – Amazon EC2 Auto Scaling
- Amazon SNS と AWS Lambda の統合 – Amazon SNS
- 災害対策のベストプラクティス – AWS Well-Architected
- マルチリージョン災害復旧アーキテクチャ – AWS アーキテクチャセンター
問題文:
企業が重要なアプリケーションを単一のAmazon EC2インスタンス上でホスティングしています。アプリケーションはインメモリデータストアとしてAmazon ElastiCache for Redisシングルノードクラスターを使用しています。アプリケーションはリレーショナルデータベースとしてAmazon RDS for MariaDB DBインスタンスを使用しています。アプリケーションが機能するためには、インフラストラクチャの各部分が健全でアクティブな状態でなければなりません。
ソリューションアーキテクトは、インフラストラクチャが可能な限り最小のダウンタイムで障害から自動的に復旧できるように、アプリケーションのアーキテクチャを改善する必要があります。
これらの要件を満たす手順の組み合わせはどれですか。(3つ選択)
選択肢:
A. Elastic Load Balancerを使用して複数のEC2インスタンス間でトラフィックを分散する。EC2インスタンスが最小容量2インスタンスのAuto Scalingグループの一部であることを確認する。
B. Elastic Load Balancerを使用して複数のEC2インスタンス間でトラフィックを分散する。EC2インスタンスがunlimited modeで設定されていることを確認する。
C. 同じアベイラビリティーゾーン内にリードレプリカを作成するためにDBインスタンスを変更する。障害シナリオでリードレプリカをプライマリDBインスタンスに昇格させる。
D. 2つのアベイラビリティーゾーンに展開するマルチAZ配置を作成するためにDBインスタンスを変更する。
E. ElastiCache for Redisクラスター用のレプリケーショングループを作成する。最小容量2インスタンスのAuto Scalingグループを使用するようにクラスターを設定する。
F. ElastiCache for Redisクラスター用のレプリケーショングループを作成する。クラスターでマルチAZを有効にする。
正解:A, D, F
解説:
A. Elastic Load Balancerを使用して複数のEC2インスタンス間でトラフィックを分散する。EC2インスタンスが最小容量2インスタンスのAuto Scalingグループの一部であることを確認する。
正解 Elastic Load BalancerとAuto Scalingグループを組み合わせることで、EC2層の高可用性を実現します。最小容量2インスタンスの設定により、常に複数のインスタンスが稼働し、一つのインスタンスに障害が発生しても自動的に他のインスタンスがトラフィックを処理します。ELBがヘルスチェックを実行し、異常なインスタンスを自動的に切り離すことで、ダウンタイムを最小限に抑えることができます。
B. Elastic Load Balancerを使用して複数のEC2インスタンス間でトラフィックを分散する。EC2インスタンスがunlimited modeで設定されていることを確認する。
不正解 「unlimited mode」はEC2インスタンスの実際の設定オプションではありません。この選択肢は技術的に正確ではない表現を含んでおり、高可用性の実現に寄与しません。また、複数インスタンスの管理やフェイルオーバー機能についても具体的な仕組みが説明されていないため、要件を満たしません。
C. 同じアベイラビリティーゾーン内にリードレプリカを作成するためにDBインスタンスを変更する。障害シナリオでリードレプリカをプライマリDBインスタンスに昇格させる。
不正解 同じアベイラビリティーゾーン内にリードレプリカを作成しても、AZ障害が発生した場合にはプライマリとレプリカの両方が影響を受けるため、真の高可用性は実現されません。災害復旧の観点からも、同一AZ内での冗長化では単一障害点が残存し、自動復旧機能として不十分です。
D. 2つのアベイラビリティーゾーンに展開するマルチAZ配置を作成するためにDBインスタンスを変更する。
正解 RDS マルチAZ配置により、プライマリDBインスタンスとスタンバイレプリカが異なるAZに自動的に配置されます。プライマリインスタンスに障害が発生した場合、数分以内に自動フェイルオーバーが実行され、スタンバイがプライマリに昇格します。この仕組みによってデータベース層の高可用性が確保され、アプリケーションの継続性が維持されます。
E. ElastiCache for Redisクラスター用のレプリケーショングループを作成する。最小容量2インスタンスのAuto Scalingグループを使用するようにクラスターを設定する。
不正解 ElastiCacheにはAuto Scalingグループという概念は存在しません。ElastiCacheのスケーリングはレプリケーショングループとノードレベルでの設定により管理されます。この選択肢は技術的に不正確な表現を含んでおり、実際の実装が不可能です。
F. ElastiCache for Redisクラスター用のレプリケーショングループを作成する。クラスターでマルチAZを有効にする。
正解 ElastiCache for Redisのレプリケーショングループを作成し、マルチAZ機能を有効にすることで、キャッシュ層の高可用性が実現されます。プライマリノードに障害が発生した場合、リードレプリカが自動的にプライマリロールに昇格し、数秒以内にサービスが復旧します。これにより、インメモリデータストアの単一障害点が解消されます。
全体的な説明
問われている要件
- 現在の単一インスタンス構成から高可用性アーキテクチャへの移行
- すべてのインフラストラクチャコンポーネントの自動障害復旧機能
- 最小限のダウンタイムでの復旧実現
- EC2、ElastiCache、RDS各層での冗長性確保
- 障害検知と自動フェイルオーバーの実装
前提知識
高可用性アーキテクチャの基本原則について
- 単一障害点(Single Point of Failure)の排除が高可用性の基本原則です。各コンポーネントで冗長性を確保し、一つのリソースに障害が発生しても他のリソースが処理を継続できるようにします。
- マルチAZ配置により、アベイラビリティーゾーン全体の障害に対しても耐性を持つアーキテクチャを構築できます。AZ障害は比較的稀ですが、発生時の影響を最小限に抑えるために重要な対策です。
- 自動フェイルオーバー機能により、人的介入なしで障害からの復旧が可能となり、MTTRを大幅に短縮できます。
EC2とロードバランサーの高可用性について
- Application Load Balancer(ALB)やNetwork Load Balancer(NLB)は、複数のAZに分散配置されたターゲットへのトラフィック分散を行います。ヘルスチェック機能により異常なインスタンスを自動的に切り離し、健全なインスタンスのみにトラフィックをルーティングします。
- Auto Scalingグループは、設定された最小容量、希望容量、最大容量に基づいてEC2インスタンス数を動的に調整します。インスタンス障害時には自動的に新しいインスタンスを起動し、サービスレベルを維持します。
- 複数AZでのインスタンス配置により、AZ障害に対する耐性を確保できます。Auto Scalingグループは自動的にAZ間でインスタンスを均等に分散配置します。
RDS マルチAZ配置とElastiCacheレプリケーションについて
- RDS マルチAZ配置では、プライマリDBインスタンスとは異なるAZに同期スタンバイレプリカが自動的に維持されます。フェイルオーバーは通常1-2分で完了し、アプリケーション側での接続文字列変更は不要です。
- ElastiCache for Redisのレプリケーショングループでは、1つのプライマリノードと最大5つのリードレプリカノードを構成できます。マルチAZ設定により、プライマリノード障害時に自動的にリードレプリカが昇格します。
- これらの自動フェイルオーバー機能により、データ層での高可用性が確保され、アプリケーションの継続的な運用が可能となります。
解くための考え方
この問題は3層アーキテクチャ(プレゼンテーション層、キャッシュ層、データ層)のそれぞれで高可用性を実現する包括的な設計を求めています。現在のシングルインスタンス構成では、各層に単一障害点が存在するため、各層での冗長性確保が必要です。
EC2層(プレゼンテーション層)では、単一インスタンスから複数インスタンス構成への移行が必要です。Elastic Load Balancerによる負荷分散とAuto Scalingグループによる自動スケーリング機能の組み合わせが最も効果的です。最小容量2インスタンスの設定により、常に冗長性が確保されます。
RDS層(データ層)では、Single-AZ構成からマルチAZ構成への移行が必要です。マルチAZ配置により、プライマリDBインスタンスの障害時に自動フェイルオーバーが実行され、数分以内にサービスが復旧します。リードレプリカを同一AZ内に作成する選択肢は、AZ障害に対する耐性がないため不適切です。
ElastiCache層(キャッシュ層)では、シングルノードクラスターからレプリケーショングループ+マルチAZ構成への移行が必要です。これにより、プライマリノードの障害時に自動的にリードレプリカが昇格し、キャッシュサービスの継続性が確保されます。
アーキテクチャ図
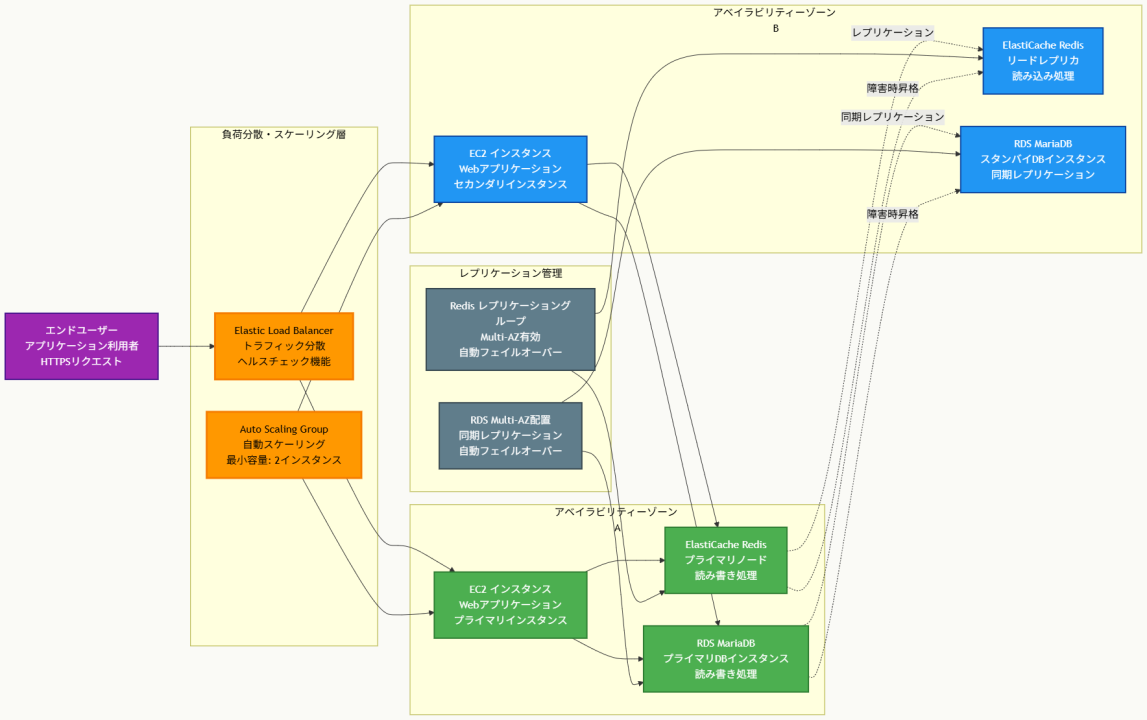
アーキテクチャ図の解説
3層冗長構成による高可用性の実現
このアーキテクチャでは、プレゼンテーション層(EC2)、キャッシュ層(ElastiCache)、データ層(RDS)のそれぞれで冗長性を確保しています。Elastic Load Balancerが複数のAZに分散配置されたEC2インスタンス間でトラフィックを分散し、Auto Scalingグループが最小容量2インスタンスを維持することで、インスタンスレベルでの単一障害点を排除しています。各層での自動フェイルオーバー機能により、障害発生時でも数秒から数分以内にサービスが復旧します。
自動フェイルオーバーとレプリケーション機能
ElastiCache for RedisのレプリケーショングループとマルチAZ機能により、プライマリノード障害時にリードレプリカが自動的に昇格します。RDS マルチAZ配置では、プライマリDBインスタンスとスタンバイレプリカ間で同期レプリケーションが実行され、障害時には透過的なフェイルオーバーが実現されます。これらの自動化機能により、運用者の手動介入なしで障害復旧が完了し、MTTRが大幅に短縮されます。
AZレベルでの障害対応とスケーラビリティ
各コンポーネントが異なるAZに配置されているため、単一AZ全体の障害に対しても継続的なサービス提供が可能です。Auto Scalingグループは負荷変動に応じて動的にインスタンス数を調整し、パフォーマンス要件を満たしながらコスト最適化も実現します。ELBのヘルスチェック機能と連携して、異常なインスタンスは自動的に切り離され、新しいインスタンスが起動されます。
他のソリューションとの比較
同一AZ内でのリードレプリカ作成によるソリューションでは、AZ障害が発生した場合にプライマリとレプリカの両方が影響を受けるため、真の高可用性は実現されません。災害復旧の観点からも、地理的な分離が重要であり、異なるAZ間でのレプリケーションが必須となります。
Auto Scalingグループを使用したElastiCacheの管理については、技術的に正確でない概念です。ElastiCacheのスケーリングは、レプリケーショングループ内でのノード追加・削除やシャーディング機能により実現されます。Auto ScalingグループはEC2インスタンスの管理に特化した機能であり、マネージドサービスであるElastiCacheには適用されません。
正解の組み合わせは、各層での適切な冗長化技術を選択しており、実装の実現性、運用の自動化レベル、コスト効率性のバランスが最も優れています。特に、マルチAZ機能とレプリケーショングループの組み合わせにより、最小限のダウンタイムでの自動復旧が可能となります。
実装の考慮事項
実装時には、ヘルスチェックの設定が重要な要素となります。ELBのヘルスチェックは、単純なHTTP応答確認だけでなく、データベース接続やキャッシュアクセスを含む包括的なアプリケーション正常性をチェックするエンドポイントを設定することが推奨されます。これにより、インフラは正常でもアプリケーションレベルで問題がある場合を適切に検知できます。
Auto Scalingグループの設定では、スケーリングポリシーとクールダウン期間の適切な調整が必要です。急激な負荷変動に対応しつつ、不必要なインスタンス起動・終了を避けるバランスが重要です。また、AMIの更新戦略やデプロイメント手法(Blue/Greenデプロイメントなど)も事前に計画する必要があります。
監視とアラート体制も重要な要素です。CloudWatchメトリクスを活用して各層での異常を早期検知し、SNSやPagerDutyなどと統合してエスカレーション体制を構築することが推奨されます。また、定期的な障害テストや復旧訓練により、実際の障害時における復旧手順の有効性を検証することも必要です。
参考資料
- Elastic Load Balancing と Auto Scaling – Amazon EC2
- Amazon RDS マルチAZ 配置 – Amazon RDS
- ElastiCache for Redis レプリケーション – Amazon ElastiCache
- ElastiCache マルチAZ と自動フェイルオーバー – Amazon ElastiCache
- Application Load Balancer のヘルスチェック – Elastic Load Balancing
- Auto Scaling グループの設定 – Amazon EC2 Auto Scaling
- 高可用性とフォルトトレラント設計 – AWS Well-Architected
- AWS での災害復旧 – AWS災害復旧
問題文:
小売企業がAWS上でeコマースアプリケーションを運用しています。アプリケーションはApplication Load Balancer(ALB)の背後にあるAmazon EC2インスタンス上で実行されています。同社はデータベースバックエンドとしてAmazon RDS DBインスタンスを使用しています。Amazon CloudFrontはALBを指す1つのオリジンで設定されています。静的コンテンツはキャッシュされています。Amazon Route 53はすべてのパブリックゾーンをホストするために使用されています。
アプリケーションのアップデート後、ALBが時々502ステータスコード(Bad Gateway)エラーを返すようになりました。根本原因は、ALBに返される不正な形式のHTTPヘッダーです。エラー発生直後にソリューションアーキテクトがウェブページをリロードすると、ページは正常に返されます。
同社が問題に取り組んでいる間、ソリューションアーキテクトは標準のALBエラーページの代わりに、訪問者にカスタムエラーページを提供する必要があります。
最小の運用オーバーヘッドでこの要件を満たす手順の組み合わせはどれですか。(2つ選択)
選択肢:
A. Amazon S3バケットを作成する。S3バケットを静的ウェブページをホストするように設定する。カスタムエラーページをAmazon S3にアップロードする。
B. ALBヘルスチェック応答Target.FailedHealthChecksが0より大きい場合にAWS Lambda関数を呼び出すAmazon CloudWatchアラームを作成する。公開アクセス可能なWebサーバーを指すようにALBでの転送ルールを変更するようにLambda関数を設定する。
C. ヘルスチェックを追加して既存のAmazon Route 53レコードを変更する。ヘルスチェックが失敗した場合のフォールバックターゲットを設定する。公開アクセス可能なウェブページを指すようにDNSレコードを変更する。
D. ALBヘルスチェック応答Elb.InternalErrorが0より大きい場合にAWS Lambda関数を呼び出すAmazon CloudWatchアラームを作成する。公開アクセス可能なWebサーバーを指すようにALBでの転送ルールを変更するようにLambda関数を設定する。
E. CloudFrontカスタムエラーページを設定してカスタムエラー応答を追加する。公開アクセス可能なウェブページを指すようにDNSレコードを変更する。
正解:A, E
解説:
A. Amazon S3バケットを作成する。S3バケットを静的ウェブページをホストするように設定する。カスタムエラーページをAmazon S3にアップロードする。
正解 Amazon S3は静的コンテンツのホスティングに最適化されたサービスで、高可用性、低コスト、簡単な設定が特徴です。カスタムエラーページのような静的HTMLファイルを配置するのに理想的で、設定も簡単で運用オーバーヘッドが最小限です。S3の静的ウェブサイトホスティング機能により、パブリックにアクセス可能なエンドポイントが提供され、CloudFrontからの参照が可能となります。
B. ALBヘルスチェック応答Target.FailedHealthChecksが0より大きい場合にAWS Lambda関数を呼び出すAmazon CloudWatchアラームを作成する。公開アクセス可能なWebサーバーを指すようにALBでの転送ルールを変更するようにLambda関数を設定する。
不正解 CloudWatchアラームとLambda関数を使用してALBの転送ルールを動的に変更するアプローチは、運用の複雑性を大幅に増加させます。Lambda関数の開発、デプロイ、監視が必要となり、さらにALBルールの動的変更は全ユーザーに影響を与えるため、502エラーが発生した特定のリクエストのみを対象とする要件に適していません。
C. ヘルスチェックを追加して既存のAmazon Route 53レコードを変更する。ヘルスチェックが失敗した場合のフォールバックターゲットを設定する。公開アクセス可能なウェブページを指すようにDNSレコードを変更する。
不正解 Route 53のヘルスチェックとフォールバック機能は、サービス全体の可用性制御に使用される仕組みです。502エラーが発生した個別のリクエストに対してカスタムエラーページを表示するのではなく、DNSレベルで全トラフィックを別のエンドポイントにリダイレクトしてしまうため、この問題の要件に適していません。
D. ALBヘルスチェック応答Elb.InternalErrorが0より大きい場合にAWS Lambda関数を呼び出すAmazon CloudWatchアラームを作成する。公開アクセス可能なWebサーバーを指すようにALBでの転送ルールを変更するようにLambda関数を設定する。
不正解 Lambda関数を使用したALBルールの動的変更は運用複雑性が高く、全ユーザーへの影響があるため不適切です。また、Elb.InternalErrorメトリクスの監視による自動化は、一時的な問題に対する過剰な自動化となり、予期しない動作を引き起こす可能性があります。
E. CloudFrontカスタムエラーページを設定してカスタムエラー応答を追加する。公開アクセス可能なウェブページを指すようにDNSレコードを変更する。
正解 CloudFrontのカスタムエラーページ機能は、オリジン(ALB)からの特定のHTTPエラーコード(502など)を検知した際に、自動的に事前定義されたカスタムエラーページを表示する標準機能です。設定は簡単で運用オーバーヘッドが最小限であり、502エラーが発生した個別のリクエストにのみ影響するため、この問題の要件に最適です。
全体的な説明
問われている要件
- ALBからの502エラー発生時のカスタムエラーページ表示
- 最小限の運用オーバーヘッドでの実装
- 既存のCloudFront構成を活用した効率的な解決策
- 一時的な問題に対する迅速で簡潔な対応
- エラーが発生した特定のリクエストのみを対象とした制御
前提知識
CloudFrontカスタムエラーページ機能について
- CloudFrontは、オリジンサーバーからの4xx、5xx系のHTTPエラーレスポンスを検知すると、設定されたカスタムエラーページを自動的に表示する機能を提供します。
- カスタムエラーページの設定では、特定のエラーコード(例:502)に対して、代替のHTTPステータスコード(例:200)とカスタムエラーページのパスを指定できます。
- この機能により、エンドユーザーはオリジンサーバーのエラーを直接見ることなく、適切にデザインされたエラーページを表示されます。
- エラーページのキャッシュ設定も可能で、頻繁なエラー発生時の負荷軽減にも効果があります。
Amazon S3静的ウェブサイトホスティングについて
- S3の静的ウェブサイトホスティング機能は、HTMLファイル、CSS、JavaScript、画像などの静的コンテンツを高可用性で配信するマネージドサービスです。
- 設定は簡単で、バケットポリシーでパブリックアクセスを許可し、インデックスドキュメントとエラードキュメントを指定するだけで運用開始できます。
- 99.999999999%(11 9’s)の耐久性と高い可用性を提供し、自動的に複数のアベイラビリティーゾーンにデータが複製されます。
- コスト効率が高く、使用した分のみの課金で、静的コンテンツの配信に最適化されています。
CloudWatchアラームとLambda連携の複雑性について
- CloudWatchアラーム、Lambda関数、ALB設定変更を連携させるソリューションは、複数のサービス間の統合が必要で運用複雑性が高くなります。
- Lambda関数の開発、デプロイ、バージョン管理、エラーハンドリング、ログ監視などの運用タスクが追加されます。
- ALBの転送ルールを動的に変更することは、全ユーザーのトラフィックフローに影響を与えるため、慎重な設計と十分なテストが必要です。
解くための考え方
この問題の核心は「最小の運用オーバーヘッド」という要件です。ALBが時々502エラーを返し、すぐにリロードすると成功するという状況から、これは一時的で局所的な問題であることが分かります。
このような場合、全体のアーキテクチャを大幅に変更したり、複雑な自動化システムを構築したりする必要はありません。むしろ、既存のCloudFront構成を活用して、エラーが発生した個別のリクエストに対してのみカスタムエラーページを表示する方が適切です。
CloudFrontのカスタムエラーページ機能は、まさにこのような用途のために設計された標準機能です。オリジンからの502エラーを検知すると、自動的に事前に準備されたカスタムエラーページを表示し、エンドユーザーエクスペリエンスを向上させます。
カスタムエラーページの配置先としては、高可用性、低コスト、簡単な設定というすべての要件を満たすAmazon S3が最適です。S3の静的ウェブサイトホスティング機能により、HTMLファイルをアップロードするだけで即座に運用開始できます。
Lambda関数やDNS設定変更を伴う選択肢は、いずれも運用オーバーヘッドが大きく、問題の規模に対して過剰なソリューションとなります。
アーキテクチャ図
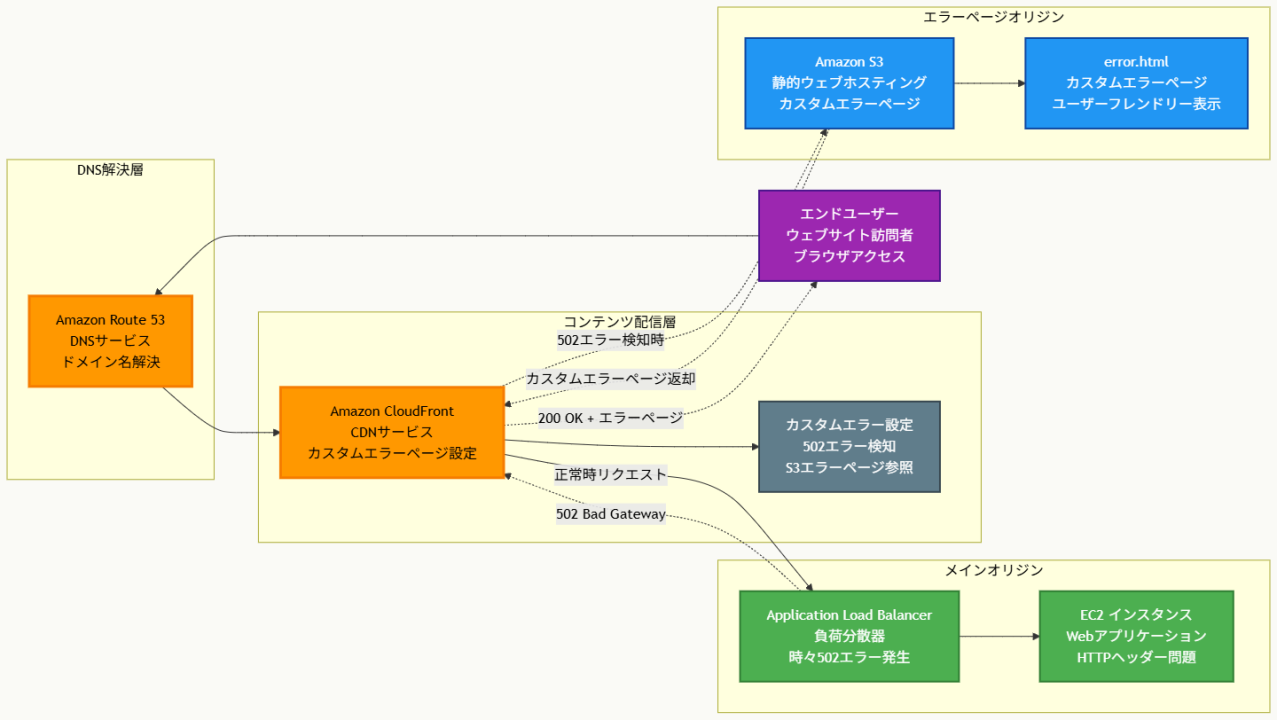
アーキテクチャ図の解説
通常時のトラフィックフローと502エラー発生メカニズム
通常時、エンドユーザーのリクエストはRoute 53でドメイン名解決され、CloudFrontを経由してALBに転送されます。ALBは複数のEC2インスタンスに負荷を分散し、EC2インスタンスがRDSからデータを取得してレスポンスを生成します。しかし、アプリケーションアップデート後に不正な形式のHTTPヘッダーが原因で502 Bad Gatewayエラーが時々発生するようになりました。このエラーは一時的で、リロードすると成功する性質があります。
CloudFrontカスタムエラーページ機能による自動エラー処理
CloudFrontにカスタムエラー設定を追加することで、ALBからの502エラーを自動的に検知し、事前に準備されたカスタムエラーページで置き換えることができます。502エラーが発生すると、CloudFrontは設定に従ってS3にホストされたerror.htmlファイルを取得し、HTTPステータスコード200でエンドユーザーに返却します。これにより、エンドユーザーは技術的なエラーメッセージではなく、分かりやすいカスタムエラーページを見ることができます。
運用オーバーヘッドを最小化する設計思想
この構成では、既存のCloudFront配信インフラを活用し、新たに追加するのはS3バケットとHTMLファイルのみです。Lambda関数や複雑なヘルスチェック機能は不要で、CloudFrontの標準機能だけでエラーハンドリングが完結します。S3は高可用性でコスト効率が良く、静的ファイルのホスティングに最適です。この方式により、メインアプリケーションの修正を並行して進めながら、エンドユーザーエクスペリエンスを即座に改善できます。
他のソリューションとの比較
Route 53のヘルスチェックとDNSフェイルオーバーを使用するアプローチでは、サービス全体を別のエンドポイントに切り替えてしまうため、502エラーが発生した個別のリクエストのみを対象とするという要件に適していません。DNSの変更は伝播に時間がかかる場合があり、キャッシュされたDNSレコードの影響で即座に反映されない可能性もあります。
CloudWatchアラームとLambda関数を使用してALBの転送ルールを動的に変更するアプローチは、技術的には可能ですが運用複雑性が大幅に増加します。Lambda関数の開発、テスト、デプロイ、監視が必要となり、ALBルールの変更は全ユーザーに影響するため、一時的な問題に対する解決策としては過剰です。
CloudFrontのカスタムエラーページ機能は、エラーが発生したリクエストのみを対象とし、他のリクエストには影響を与えません。設定も簡単で、運用開始までの時間も短く、問題の性質と要件に最も適したソリューションです。
実装の考慮事項
実装時には、S3バケットのパブリックアクセス設定とバケットポリシーの適切な構成が重要です。カスタムエラーページはパブリックに読み取り可能である必要がありますが、書き込み権限は適切に制限する必要があります。
CloudFrontのカスタムエラー設定では、エラーページのキャッシュTTLも設定できます。頻繁に502エラーが発生する場合は、エラーページをある程度キャッシュすることでS3への負荷を軽減できます。しかし、エラー解決後に古いエラーページが表示され続けることを避けるため、適切なTTL値を設定する必要があります。
また、カスタムエラーページのデザインでは、ユーザーに適切な情報を提供し、可能であれば代替アクション(リロードボタン、サポート連絡先など)を含めることが推奨されます。アクセシビリティとユーザビリティを考慮したデザインにより、エラー発生時のユーザーエクスペリエンスを最大限に改善できます。
参考資料
問題文:
企業が多くのAWSアカウントを持ち、それらすべてを管理するためにAWS Organizationsを使用しています。ソリューションアーキテクトは、同社が複数のアカウント間で共通ネットワークを共有するために使用できるソリューションを実装する必要があります。同社のインフラストラクチャチームは、VPCを持つ専用のインフラストラクチャアカウントを持っています。インフラストラクチャチームは、このアカウントを使用してネットワークを管理する必要があります。個別のアカウントは独自のネットワークを管理する能力を持てません。
しかし、個別のアカウントはサブネット内でAWSリソースを作成できる必要があります。
これらの要件を満たすために、ソリューションアーキテクトが実行すべきアクションの組み合わせはどれですか。(2つ選択)
選択肢:
A. インフラストラクチャアカウントでtransit gatewayを作成する。
B. AWS Organizations管理アカウントからリソース共有を有効にする。
C. AWS Organizations内の各AWSアカウントでVPCを作成する。VPCがインフラストラクチャアカウントのVPCと同じCIDR範囲とサブネットを共有するように設定する。各個別アカウントのVPCをインフラストラクチャアカウントのVPCとピアリングする。
D. インフラストラクチャアカウントでAWS Resource Access Managerでリソースシェアを作成する。共有ネットワークを使用する特定のAWS Organizations OUを選択する。リソースシェアに関連付ける各サブネットを選択する。
E. インフラストラクチャアカウントでAWS Resource Access Managerでリソースシェアを作成する。共有ネットワークを使用する特定のAWS Organizations OUを選択する。リソースシェアに関連付ける各prefix listを選択する。
正解:B, D
解説:
A. インフラストラクチャアカウントでtransit gatewayを作成する。
不正解 Transit Gatewayは複数のVPC間を接続するためのサービスですが、この問題では1つのVPCを複数のアカウント間で共有する「VPC共有」というアプローチを取るため、Transit Gatewayは必要ありません。VPC共有では、他のアカウントは独自のVPCを持つのではなく、インフラストラクチャアカウントのVPCのサブネットを直接使用します。
B. AWS Organizations管理アカウントからリソース共有を有効にする。
正解 AWS Organizationsでリソース共有機能を有効にすることは、RAMを使用して組織内のアカウント間でリソースを共有するための前提条件です。この設定により、組織内のアカウント間でのリソース共有が可能になり、個別のアカウント招待プロセスを省略できます。管理アカウントでこの機能を有効にしないと、RAMでのリソース共有ができません。
C. AWS Organizations内の各AWSアカウントでVPCを作成する。VPCがインフラストラクチャアカウントのVPCと同じCIDR範囲とサブネットを共有するように設定する。各個別アカウントのVPCをインフラストラクチャアカウントのVPCとピアリングする。
不正解 各アカウントで個別にVPCを作成することは、「個別のアカウントは独自のネットワークを管理する能力を持てない」という要件に直接反します。また、同じCIDR範囲を使用する複数のVPC間でのピアリング接続は技術的に不可能です。さらに、このアプローチでは運用の複雑性が大幅に増加し、要件を満たしません。
D. インフラストラクチャアカウントでAWS Resource Access Managerでリソースシェアを作成する。共有ネットワークを使用する特定のAWS Organizations OUを選択する。リソースシェアに関連付ける各サブネットを選択する。
正解 AWS RAMを使用してサブネットを共有することで、他のアカウントがインフラストラクチャアカウントのVPCのサブネット内にリソースを作成できるようになります。これは「VPC共有」と呼ばれるアプローチで、ネットワーク管理を中央集約化しながら、個別アカウントでのリソース作成を可能にします。OUレベルでの共有により、管理効率も向上します。
E. インフラストラクチャアカウントでAWS Resource Access Managerでリソースシェアを作成する。共有ネットワークを使用する特定のAWS Organizations OUを選択する。リソースシェアに関連付ける各prefix listを選択する。
不正解 Prefix listは主にセキュリティグループやルートテーブルでのIP範囲管理に使用されるリソースです。この問題の要件である「サブネット内でのリソース作成」を実現するためには、サブネット自体を共有する必要があります。Prefix listの共有だけでは、他のアカウントがインフラストラクチャVPCにリソースを作成することはできません。
全体的な説明
問われている要件
- AWS Organizations環境での複数アカウント間のネットワーク共有
- インフラストラクチャアカウントによる中央集約的なネットワーク管理
- 個別アカウントでの独自ネットワーク管理の禁止
- 個別アカウントでの共有サブネット内でのリソース作成権限
- 運用効率性と管理の簡素化
前提知識
VPC共有とAWS Resource Access Managerについて
- VPC共有は、1つのVPCのサブネットを複数のAWSアカウント間で共有する機能です。VPCオーナーがサブネットを他のアカウントと共有し、参加者アカウントはそのサブネット内にリソースを作成できます。
- AWS Resource Access Manager(RAM)は、AWSリソースを他のアカウントや組織と安全に共有するためのサービスです。VPCサブネット、Transit Gateway、License Manager設定など、様々なリソースタイプに対応しています。
- 共有されたサブネットでは、参加者アカウントはEC2インスタンス、RDS、Lambda関数などのリソースを作成できますが、サブネットの設定やルートテーブルの変更はできません。
- セキュリティグループは各アカウントが独自に管理できますが、共有サブネットのNACLはVPCオーナーのみが管理できます。
AWS Organizationsでのリソース共有設定について
- デフォルトでは、AWS Organizationsでのリソース共有機能は無効になっています。管理アカウントでこの機能を明示的に有効にする必要があります。
- リソース共有が有効になると、組織内のアカウント間でのリソース共有時に個別の招待プロセスが不要になり、OUやアカウント指定による自動共有が可能になります。
- この設定により、RAMでのリソースシェア作成時に、組織内の特定のOUやアカウントを直接指定できるようになります。
Transit Gatewayとの違いについて
- Transit Gatewayは複数のVPC間を接続するハブ・アンド・スポーク型のネットワークサービスです。各アカウントが独自のVPCを持つ場合に適用されます。
- VPC共有では、そもそも複数のVPCが存在せず、1つのVPCのサブネットを複数アカウントで使用するため、VPC間接続の仕組みは不要です。
- コスト面でも、Transit Gatewayは接続数やデータ処理量に基づく課金がありますが、VPC共有では追加のネットワーク課金は発生しません。
解くための考え方
この問題の核心は「VPC共有」というアーキテクチャパターンの理解です。従来のマルチアカウント環境では、各アカウントが独自のVPCを持ち、VPCピアリングやTransit Gatewayで接続するアプローチが一般的でした。しかし、VPC共有では、1つのVPCを複数のアカウントで共有することで、ネットワーク管理を大幅に簡素化できます。
要件から「個別のアカウントは独自のネットワークを管理する能力を持てない」とあることから、各アカウントでVPCを作成するアプローチは除外されます。同時に「個別のアカウントはサブネット内でAWSリソースを作成できる必要がある」とあることから、何らかの方法でサブネットアクセスを提供する必要があります。
VPC共有アプローチでは、インフラストラクチャアカウントがVPCとサブネットを所有・管理し、AWS RAMを通じて特定のサブネットを他のアカウントと共有します。共有を受けたアカウントは、そのサブネット内でリソースを作成できますが、ネットワーク設定自体は変更できません。
AWS Organizationsでのリソース共有機能の有効化は、RAMでの組織内共有を可能にするための前提条件であり、運用効率を大幅に向上させます。
アーキテクチャ図
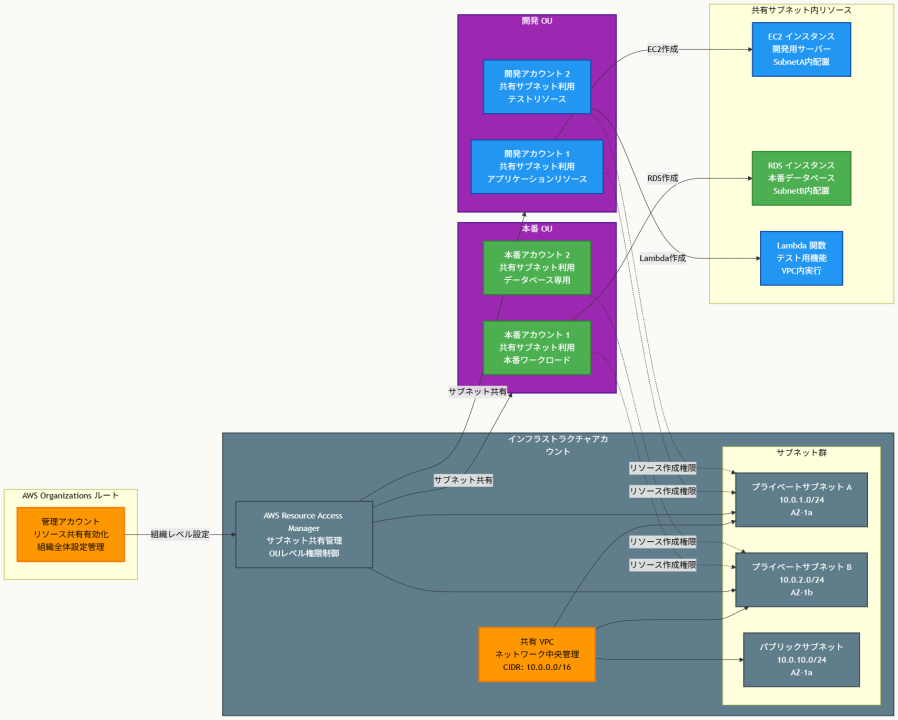
アーキテクチャ図の解説
中央集約型ネットワーク管理の実現
このアーキテクチャでは、インフラストラクチャアカウントが唯一のVPCを所有し、すべてのネットワーク設定を管理します。管理アカウントでリソース共有機能を有効化することで、AWS RAMによる組織内でのサブネット共有が可能になります。各参加者アカウントは独自のVPCを持たず、共有されたサブネットを直接利用するため、ネットワーク管理の複雑性が大幅に削減されます。
OUレベルでの権限制御と運用効率性
RAMでのリソース共有設定では、個別アカウントではなくOU(組織単位)レベルでサブネット共有を行います。これにより、新しいアカウントがOUに追加された際に自動的にサブネットアクセス権限が付与され、運用効率が向上します。開発OUには開発・テスト用サブネットを、本番OUには本番用サブネットを共有することで、環境分離も適切に実現されます。
リソース作成権限と制限の実装
参加者アカウントは共有されたサブネット内でEC2インスタンス、RDS、Lambda関数などのAWSリソースを自由に作成できますが、サブネットの設定変更やルートテーブルの修正はできません。これにより、「サブネット内でAWSリソースを作成できる」という要件と「独自のネットワークを管理する能力を持てない」という制約の両方を満たします。セキュリティグループは各アカウントが独自に管理できるため、適切なアクセス制御も維持されます。
他のソリューションとの比較
Transit Gatewayベースのアプローチでは、各アカウントが独自のVPCを持ち、Transit Gatewayを通じて相互接続する形になります。しかし、これは「個別のアカウントは独自のネットワークを管理する能力を持てない」という要件に反し、また運用コストと複雑性も大幅に増加します。
各アカウントでVPCを作成してピアリング接続するアプローチも、同様に個別アカウントでのネットワーク管理が必要となり、要件に適していません。さらに、同じCIDRブロックを使用する複数のVPC間でのピアリングは技術的に不可能です。
Prefix listの共有アプローチでは、ルートテーブルやセキュリティグループでのIP範囲管理は効率化できますが、実際にリソースを配置するサブネットが提供されないため、根本的な要件を満たしません。
VPC共有アプローチは、ネットワーク管理の中央集約化、運用コストの最適化、セキュリティ境界の維持という3つの要件を同時に満たす最適なソリューションです。
実装の考慮事項
実装時には、サブネット共有の範囲を適切に設計することが重要です。すべてのサブネットを全アカウントと共有するのではなく、環境(開発・テスト・本番)や用途(アプリケーション・データベース)に応じて適切にサブネットを分割し、必要最小限の共有範囲を設定する必要があります。
セキュリティ面では、共有サブネット内でのリソース間通信を制御するため、セキュリティグループルールを適切に設定する必要があります。各アカウントが独自にセキュリティグループを管理できるため、アカウント間での意図しない通信を防ぐための設計が重要です。
監視とログ記録では、VPC Flow Logsを有効化してネットワークトラフィックを監視し、CloudTrailでRAMでのリソース共有操作をログ記録することで、セキュリティとコンプライアンス要件を満たす必要があります。また、各アカウントでのリソース作成状況を一元的に監視する仕組みも構築すべきです。
参考資料
問題文:
企業がサードパーティのSoftware-as-a-Service(SaaS)アプリケーションを使用したいと考えています。サードパーティのSaaSアプリケーションは複数のAPI呼び出しを通じて利用されます。サードパーティのSaaSアプリケーションもVPC内のAWS上で実行されています。企業はVPC内からサードパーティのSaaSアプリケーションを利用します。企業には、インターネットを経由しないプライベート接続の使用を義務付ける内部セキュリティポリシーがあります。企業のVPC内で実行されるリソースは、企業のVPC外部からアクセスされることは許可されません。すべての権限は最小権限の原則に準拠する必要があります。
これらの要件を満たすソリューションはどれですか。
選択肢:
A. AWS PrivateLink interface VPCエンドポイントを作成する。このエンドポイントをサードパーティSaaSアプリケーションが提供するエンドポイントサービスに接続する。エンドポイントへのアクセスを制限するセキュリティグループを作成する。セキュリティグループをエンドポイントに関連付ける。
B. サードパーティSaaSアプリケーションと企業のVPC間でAWS Site-to-Site VPN接続を作成する。VPNトンネル間のアクセスを制限するためにネットワークACLを設定する。
C. サードパーティSaaSアプリケーションと企業のVPC間でVPCピアリング接続を作成する。ピアリング接続に必要なルートを追加してルートテーブルを更新する。
D. AWS PrivateLinkエンドポイントサービスを作成する。サードパーティSaaSプロバイダーにこのエンドポイントサービス用のinterface VPCエンドポイントを作成してもらう。エンドポイントサービスに対してサードパーティSaaSプロバイダーの特定アカウントに権限を付与する。
正解:A
解説:
A. AWS PrivateLink interface VPCエンドポイントを作成する。このエンドポイントをサードパーティSaaSアプリケーションが提供するエンドポイントサービスに接続する。エンドポイントへのアクセスを制限するセキュリティグループを作成する。セキュリティグループをエンドポイントに関連付ける。
正解 AWS PrivateLink interface VPCエンドポイントは、サードパーティSaaSアプリケーションにプライベートに接続するための標準的なアプローチです。企業(サービスコンシューマー)がinterface endpointを作成し、SaaSプロバイダー(サービスプロバイダー)が提供するendpoint serviceに接続します。トラフィックはAWSのプライベートネットワークを経由してインターネットを通らず、セキュリティグループによる細かいアクセス制御で最小権限を実現できます。
B. サードパーティSaaSアプリケーションと企業のVPC間でAWS Site-to-Site VPN接続を作成する。VPNトンネル間のアクセスを制限するためにネットワークACLを設定する。
不正解 Site-to-Site VPN接続は技術的には機能しますが、複数の運用上の課題があります。両VPCのCIDRブロックが重複している可能性や、VPN接続の帯域幅制限が問題となる場合があります。また、VPN接続の管理とメンテナンスが必要で、PrivateLinkと比較して運用オーバーヘッドが高くなります。
C. サードパーティSaaSアプリケーションと企業のVPC間でVPCピアリング接続を作成する。ピアリング接続に必要なルートを追加してルートテーブルを更新する。
不正解 VPCピアリング接続も同様の問題を抱えています。特に、両VPC間でCIDRブロックが重複している場合はピアリング接続を確立できません。また、ピアリング接続では双方向の通信が可能になるため、「企業のVPCのリソースは外部からアクセスされてはならない」という要件に適切に対応するためには追加の設定が必要となります。
D. AWS PrivateLinkエンドポイントサービスを作成する。サードパーティSaaSプロバイダーにこのエンドポイントサービス用のinterface VPCエンドポイントを作成してもらう。エンドポイントサービスに対してサードパーティSaaSプロバイダーの特定アカウントに権限を付与する。
不正解 この選択肢は役割が逆転しています。通常のPrivateLinkアーキテクチャでは、サービスプロバイダー(SaaSベンダー)がendpoint serviceを作成し、サービスコンシューマー(利用企業)がinterface endpointを作成します。企業がSaaSアプリケーションを「消費」する側であることから、企業がendpoint serviceを作成するのは不適切です。
全体的な説明
問われている要件
- サードパーティSaaSアプリケーションへのAPI経由でのアクセス
- インターネットを経由しないプライベート接続の確保
- 企業VPCリソースの外部アクセス防止
- 最小権限の原則に基づくアクセス制御
- AWS環境間でのセキュアな通信の実現
前提知識
AWS PrivateLinkの基本概念について
- AWS PrivateLinkは、VPC間やAWSサービス間でプライベートな接続を提供するマネージドサービスです。トラフィックはAWSのプライベートネットワークを経由し、インターネットを通過しません。
- エンドポイントサービス(Endpoint Service)はサービスプロバイダー側が作成し、自身のサービスを他のVPCに公開するために使用します。Network Load Balancerの背後にあるサービスを公開できます。
- Interface VPCエンドポイントはサービスコンシューマー側が作成し、特定のエンドポイントサービスへのプライベート接続を確立します。ENI(Elastic Network Interface)として実装されます。
- PrivateLinkを使用することで、サービス間の接続を確立しながら、ネットワークの複雑性を最小限に抑え、セキュリティを向上させることができます。
SaaSアプリケーション統合のアーキテクチャパターンについて
- SaaSアプリケーションとの統合では、通常、SaaSプロバイダーがエンドポイントサービスを提供し、顧客企業がinterface endpointを作成してアクセスします。
- このパターンにより、SaaSプロバイダーは複数の顧客企業に対してスケーラブルにサービスを提供でき、各顧客は独立したプライベート接続を確立できます。
- API経由でのアクセスでは、通常HTTPSトラフィックを使用するため、PrivateLinkのInterface Endpointが適しています。Gateway Endpointは主にS3やDynamoDBなど特定のAWSサービス向けです。
セキュリティ制御とアクセス管理について
- Interface VPCエンドポイントにはセキュリティグループを関連付けることができ、特定のポートやプロトコル、送信元IPアドレスに基づいてアクセスを制御できます。
- エンドポイントポリシーを使用して、エンドポイント経由でアクセス可能なリソースやアクションを制限できます。これにより最小権限の原則を実現できます。
- PrivateLink接続は一方向性を持ち、コンシューマー側からプロバイダー側へのアクセスのみが可能で、逆方向のアクセスは自動的に防止されます。
解くための考え方
この問題の解決の鍵は、SaaSアプリケーションとの統合における「サービスコンシューマー」と「サービスプロバイダー」の役割を正しく理解することです。問題文で企業がSaaSアプリケーションを「消費」すると明記されているため、企業がサービスコンシューマーの役割を担います。
PrivateLinkアーキテクチャでは、サービスプロバイダー(この場合はSaaSベンダー)がエンドポイントサービスを作成・管理し、サービスコンシューマー(この場合は企業)がinterface endpointを作成してサービスに接続します。この標準的な構成により、スケーラビリティとセキュリティの両方が確保されます。
セキュリティ要件の観点では、「インターネットを経由しないプライベート接続」という要件はPrivateLinkによって満たされ、「企業VPCリソースの外部アクセス防止」という要件は、PrivateLinkの一方向性とセキュリティグループの適切な設定によって実現されます。
VPNやピアリング接続などの他のオプションは、CIDR重複の問題や双方向通信の課題、運用の複雑性といった点で、この要件には最適ではありません。
アーキテクチャ図
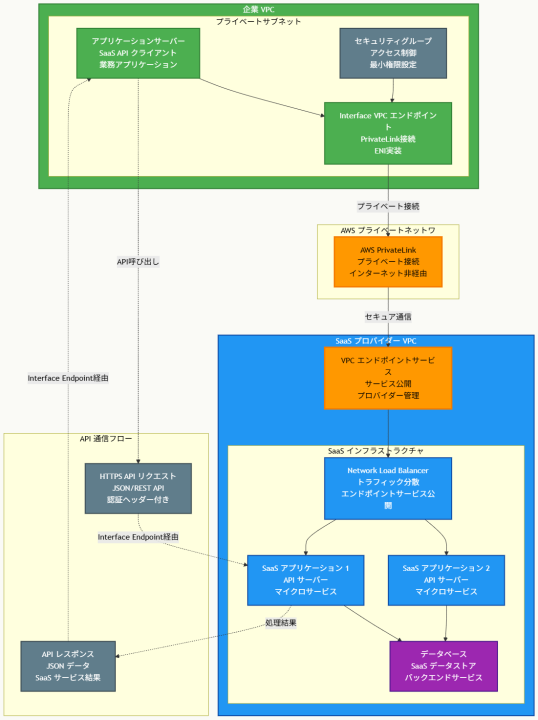
アーキテクチャ図の解説
プライベート接続によるセキュアなAPI通信
このアーキテクチャでは、企業のアプリケーションサーバーがInterface VPCエンドポイントを通じてSaaSアプリケーションのAPIに接続します。すべての通信はAWS PrivateLinkを経由してAWSプライベートネットワーク内で行われ、インターネットを経由することはありません。Interface Endpointは実際にはENI(Elastic Network Interface)として実装され、企業VPC内でプライベートIPアドレスを持ちます。
一方向性通信とセキュリティ制御
PrivateLinkの重要な特徴として、通信が一方向性を持つことがあります。企業側からSaaSアプリケーションへのアクセスは可能ですが、SaaSアプリケーション側から企業VPC内のリソースへの逆方向アクセスは自動的に防止されます。さらに、セキュリティグループを適切に設定することで、特定のポートやプロトコル、送信元に基づいてアクセスを制限し、最小権限の原則を実現します。
スケーラブルなSaaSプロバイダーアーキテクチャ
SaaSプロバイダー側では、Network Load Balancerの背後に複数のアプリケーションインスタンスを配置し、VPCエンドポイントサービスを通じて外部に公開します。この構成により、複数の顧客企業からの接続を効率的に処理でき、各顧客は独立したプライベート接続を持ちながら、共通のSaaSインフラストラクチャを利用できます。
他のソリューションとの比較
Site-to-Site VPN接続によるアプローチでは、両VPC間でCIDRブロックが重複している場合に接続できない可能性があります。また、VPN接続では暗号化とトンネリングのオーバーヘッドにより、API通信のレイテンシが増加する可能性があります。さらに、VPN接続の管理とメンテナンス、接続の監視といった運用負荷も発生します。
VPCピアリング接続も同様のCIDR重複問題を抱えているほか、ピアリング接続では本質的に双方向通信が可能となるため、「企業VPCリソースの外部アクセス防止」要件を満たすためには追加のセキュリティ設定が必要となります。また、ピアリング接続では複数の企業が同じSaaSプロバイダーに接続する場合、接続数が増加して管理が複雑になります。
逆方向のPrivateLink設定(企業がエンドポイントサービスを作成)は、SaaSアプリケーション統合の標準的なパターンに反しており、スケーラビリティとセキュリティの観点から不適切です。この構成では、SaaSプロバイダーが各顧客企業のエンドポイントサービスに個別に接続する必要があり、運用が非効率的になります。
実装の考慮事項
Interface VPCエンドポイントの実装では、適切なサブネット選択とセキュリティグループ設定が重要です。エンドポイントは複数のアベイラビリティーゾーンに配置することで高可用性を確保し、セキュリティグループでは必要最小限のポート(通常はHTTPS用の443番ポート)のみを許可します。
エンドポイントポリシーの設定により、特定のAPIエンドポイントやリソースへのアクセスをさらに細かく制御できます。これにより、アプリケーションが必要とするSaaS機能のみにアクセスを制限し、最小権限の原則を徹底できます。
監視とログ記録では、VPC Flow Logsを有効化してネットワークトラフィックを監視し、CloudTrailでエンドポイント関連のAPI呼び出しをログ記録します。また、SaaSアプリケーション側でも適切なログ記録とAPI使用量の監視を実装し、セキュリティインシデントの早期検知と対応を可能にする必要があります。
参考資料
- AWS PrivateLink を使用した SaaS アプリケーションへのアクセス – Amazon VPC
- VPC エンドポイントサービスの作成 – Amazon VPC
- Interface VPC エンドポイント – Amazon VPC
- AWS PrivateLink を使用した新しい SaaS 戦略 – AWS ブログ
- VPC エンドポイントポリシー – Amazon VPC
- Network Load Balancer のターゲットグループ – Elastic Load Balancing
- SaaS アプリケーション統合のベストプラクティス – AWS Well-Architected
問題文:
企業がApplication Load Balancerの背後にあるAuto ScalingグループのAmazon EC2インスタンス群でアプリケーションを実行しています。アプリケーションの負荷は1日を通じて変動し、EC2インスタンスは定期的にスケールインおよびスケールアウトされます。EC2インスタンスからのログファイルは15分ごとに中央のAmazon S3バケットにコピーされています。
セキュリティチームは、終了されたEC2インスタンスの一部からログファイルが欠落していることを発見しました。
終了されるEC2インスタンスから確実にログファイルが中央のS3バケットにコピーされるようにするアクションセットはどれですか。
選択肢:
A. ログファイルをAmazon S3にコピーするスクリプトを作成し、EC2インスタンス上のファイルにスクリプトを保存する。Auto Scalingライフサイクルフックとライフサイクルイベントを検知するAmazon EventBridgeルールを作成する。autoscaling:EC2_INSTANCE_TERMINATING遷移でAWS Lambda関数を呼び出してAuto ScalingグループにABANDONを送信して終了を防ぎ、スクリプトを実行してログファイルをコピーしてから、AWS SDKを使用してインスタンスを終了する。
B. ログファイルをAmazon S3にコピーするスクリプトを含むAWS Systems Managerドキュメントを作成する。Auto Scalingライフサイクルフックとライフサイクルイベントを検知するAmazon EventBridgeルールを作成する。autoscaling:EC2_INSTANCE_TERMINATING遷移でAWS Lambda関数を呼び出してAWS Systems Manager API SendCommandオペレーションを呼び出し、ドキュメントを実行してログファイルをコピーし、Auto ScalingグループにCONTINUEを送信してインスタンスを終了する。
C. ログ配信頻度を5分ごとに変更する。ログファイルをAmazon S3にコピーするスクリプトを作成し、EC2インスタンスユーザーデータにスクリプトを追加する。EC2インスタンス終了を検知するAmazon EventBridgeルールを作成する。EventBridgeルールからAWS Lambda関数を呼び出し、AWS CLIを使用してユーザーデータスクリプトを実行してログファイルをコピーしてインスタンスを終了する。
D. ログファイルをAmazon S3にコピーするスクリプトを含むAWS Systems Managerドキュメントを作成する。Amazon Simple Notification Service(Amazon SNS)トピックにメッセージを発行するAuto Scalingライフサイクルフックを作成する。SNS通知からAWS Systems Manager API SendCommandオペレーションを呼び出してドキュメントを実行してログファイルをコピーし、Auto ScalingグループにABANDONを送信してインスタンスを終了する。
正解:B
解説:
A. ログファイルをAmazon S3にコピーするスクリプトを作成し、EC2インスタンス上のファイルにスクリプトを保存する。Auto Scalingライフサイクルフックとライフサイクルイベントを検知するAmazon EventBridgeルールを作成する。autoscaling:EC2_INSTANCE_TERMINATING遷移でAWS Lambda関数を呼び出してAuto ScalingグループにABANDONを送信して終了を防ぎ、スクリプトを実行してログファイルをコピーしてから、AWS SDKを使用してインスタンスを終了する。
不正解 ABANDONシグナルを使用して終了を防ぐアプローチは適切ではありません。これによりAuto Scalingの正常な動作が阻害され、予期しない問題が発生する可能性があります。また、スクリプトをEC2インスタンス内に保存することは管理の複雑性を増し、インスタンスが異常な状態の場合にスクリプトが実行されない可能性があります。
B. ログファイルをAmazon S3にコピーするスクリプトを含むAWS Systems Managerドキュメントを作成する。Auto Scalingライフサイクルフックとライフサイクルイベントを検知するAmazon EventBridgeルールを作成する。autoscaling:EC2_INSTANCE_TERMINATING遷移でAWS Lambda関数を呼び出してAWS Systems Manager API SendCommandオペレーションを呼び出し、ドキュメントを実行してログファイルをコピーし、Auto ScalingグループにCONTINUEを送信してインスタンスを終了する。
正解 Systems Managerドキュメントを使用することで、スクリプトを中央管理でき、複数のインスタンスで再利用可能です。ライフサイクルフックにより終了プロセスが一時停止され、EventBridgeがイベントを検知してLambda関数を呼び出し、SendCommandでドキュメントを実行します。処理完了後にCONTINUEシグナルを送信することで、Auto Scalingの正常な終了プロセスが継続されます。
C. ログ配信頻度を5分ごとに変更する。ログファイルをAmazon S3にコピーするスクリプトを作成し、EC2インスタンスユーザーデータにスクリプトを追加する。EC2インスタンス終了を検知するAmazon EventBridgeルールを作成する。EventBridgeルールからAWS Lambda関数を呼び出し、AWS CLIを使用してユーザーデータスクリプトを実行してログファイルをコピーしてインスタンスを終了する。
不正解 ログ配信頻度を5分に変更しても、インスタンス終了時のタイミングの問題は根本的に解決されません。また、ユーザーデータスクリプトはインスタンス起動時にのみ実行され、終了時には実行されないため、このアプローチは機能しません。EventBridgeでEC2終了イベントを検知しても、既に終了したインスタンスではスクリプトを実行できません。
D. ログファイルをAmazon S3にコピーするスクリプトを含むAWS Systems Managerドキュメントを作成する。Amazon Simple Notification Service(Amazon SNS)トピックにメッセージを発行するAuto Scalingライフサイクルフックを作成する。SNS通知からAWS Systems Manager API SendCommandオペレーションを呼び出してドキュメントを実行してログファイルをコピーし、Auto ScalingグループにABANDONを送信してインスタンスを終了する。
不正解 ABANDONシグナルを使用して終了を防ぐアプローチは適切ではありません。これによりAuto Scalingの正常な動作が阻害され、予期しない問題が発生する可能性があります。また、EventBridge経由ではなくSNS経由でのイベント処理は、追加の複雑性を生み、直接的なソリューションではありません。ABANDONシグナルは他のライフサイクルフックの実行を防ぐため、意図しない副作用を引き起こす可能性があります。
全体的な説明
問われている要件
- Auto Scalingによるインスタンス終了時のログファイル保護
- 定期的なログコピープロセス(15分間隔)の補完
- 終了されるインスタンスからの確実なログ取得
- Auto Scalingの正常な動作を阻害しない仕組み
- スケーラブルで管理しやすいソリューション
前提知識
Auto Scalingライフサイクルフックについて
- ライフサイクルフックは、Auto Scalingグループがインスタンスを起動または終了する前に一時停止し、カスタムアクションを実行する機能です。
- EC2_INSTANCE_TERMINATING状態では、インスタンスは完全に終了される前に待機状態となり、指定されたタイムアウト期間内でカスタム処理を実行できます。
- ライフサイクルアクションの完了後、CONTINUEシグナルで正常な終了プロセスを継続するか、ABANDONシグナルで異常終了として処理するかを選択できます。
- デフォルトのタイムアウトは3600秒(1時間)ですが、設定により調整可能です。
AWS Systems Manager SendCommandについて
- SendCommandは、マネージドインスタンスに対してリモートでコマンドやスクリプトを実行する機能です。
- Systems Managerドキュメント(SSMドキュメント)を使用して、実行するコマンドやスクリプトを定義できます。
- EC2インスタンスにSSM Agentがインストールされ、適切なIAMロールが設定されていれば、リモートからの確実なコマンド実行が可能です。
- 実行結果や出力をCloudWatch Logsに記録し、実行状況を監視できます。
EventBridgeとAuto Scalingの統合について
- EventBridgeは、Auto Scalingライフサイクルイベントを自動的に検知し、対応するターゲット(Lambda関数など)を呼び出すことができます。
- イベントパターンによって特定のライフサイクル状態(TERMINATING、LAUNCHING等)をフィルタリングし、適切なアクションをトリガーできます。
- Lambda関数からAuto Scaling APIを呼び出して、CompleteLifecycleActionによりCONTINUEまたはABANDONシグナルを送信できます。
解くための考え方
この問題の核心は、Auto Scalingによる予期しないインスタンス終了からログファイルを保護することです。15分間隔でのログコピーでは、最大15分分のログが失われる可能性があるため、インスタンス終了時に最新のログを確実に保存する仕組みが必要です。
ライフサイクルフックを活用することで、インスタンス終了プロセスを一時停止し、その間にログファイルのコピー処理を実行できます。重要なのは、処理完了後にCONTINUEシグナルを送信してAuto Scalingの正常な動作を継続することです。
Systems Managerドキュメントを使用することで、ログコピースクリプトを中央管理でき、複数のインスタンス間での一貫性と保守性を確保できます。また、SendCommand APIにより、リモートからの確実なスクリプト実行が可能となります。
EventBridgeによる自動検知とLambda関数による処理の組み合わせは、人的介入なしでの完全自動化を実現し、運用負荷を最小限に抑えます。
アーキテクチャ図
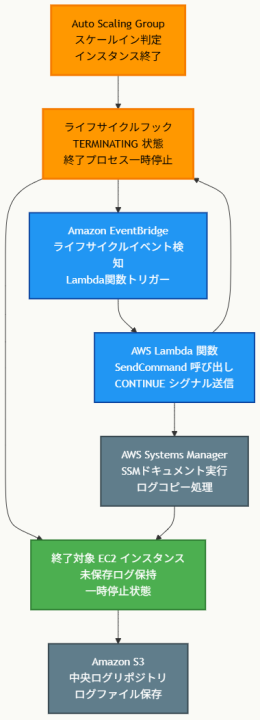
アーキテクチャ図の解説
自動化されたログ保護フロー
Auto Scalingグループがインスタンス終了を判定すると、ライフサイクルフックが終了プロセスを一時停止し、インスタンスをTERMINATING状態で待機させます。EventBridgeがこのライフサイクルイベントを自動検知してLambda関数をトリガーし、Lambda関数はSystems Manager SendCommandを呼び出して対象インスタンス上でログコピースクリプトを実行します。
確実なログ保存とプロセス継続
Systems ManagerのSSMドキュメントに定義されたスクリプトが実行され、インスタンス内のログファイルがS3バケットに確実にコピーされます。処理完了後、Lambda関数はライフサイクルフックにCONTINUEシグナルを送信し、Auto Scalingの正常な終了プロセスが再開されます。この仕組みにより、定期的なログコピーでは保護できない最新のログも確実に保存されます。
他のソリューションとの比較
ABANDONシグナルを使用するアプローチでは、Auto Scalingグループの正常な動作が阻害される可能性があります。ABANDONは異常終了として扱われ、他のライフサイクルフックの実行を停止させるため、意図しない副作用を引き起こす可能性があります。
ユーザーデータスクリプトによるアプローチは、根本的に機能しません。ユーザーデータはインスタンス起動時にのみ実行され、終了時には利用できません。また、EC2終了イベントの検知時点では、既にインスタンスがアクセス不能な状態になっている可能性があります。
ログ配信頻度の短縮だけでは、インスタンス終了のタイミングによってはログが失われる問題を根本的に解決できません。5分間隔にしても、最大5分分のログが失われる可能性は残ります。
SNSを経由するアプローチは、EventBridgeによる直接的な統合と比較して追加の複雑性を生み、レイテンシも増加します。また、処理の透明性と監視可能性の観点でも劣ります。
実装の考慮事項
実装時には、EC2インスタンスにSSM Agentがインストールされ、Systems Managerへの通信が可能な適切なIAMロールが設定されている必要があります。また、S3バケットへのアップロード権限も必要です。
ライフサイクルフックのタイムアウト値は、ログファイルのサイズと転送時間を考慮して適切に設定する必要があります。大量のログがある場合は、圧縮処理や並列転送を検討すべきです。
エラーハンドリングでは、ログコピー処理が失敗した場合のリトライ機能や、最終的にCONTINUEシグナルを送信してインスタンス終了を継続する仕組みを実装することが重要です。無限に待機状態にならないよう、適切なタイムアウト処理も必要です。
監視面では、CloudWatch Logsでスクリプト実行ログを記録し、CloudWatchアラームで処理失敗を検知する体制を構築することが推奨されます。また、S3への転送完了を確認するためのS3イベント通知の設定も考慮すべきです。
参考資料
- Auto Scalingライフサイクルフック – Amazon EC2 Auto Scaling
- Auto Scalingインスタンス終了前のコード実行 – AWSブログ
- Systems Manager SendCommand – AWS Systems Manager
- Lambda関数とライフサイクルフック – AWS チュートリアル
- EventBridgeとAuto Scaling – Amazon EventBridge
- Systems Manager ドキュメント – AWS Systems Manager
- Auto Scaling CompleteLifecycleAction – Amazon EC2 Auto Scaling
- ログ管理のベストプラクティス – AWS Well-Architected
問題文:
企業が複数のAWSアカウントを使用しています。DNSレコードはAccount AのAmazon Route 53プライベートホストゾーンに保存されています。企業のアプリケーションとデータベースはAccount Bで実行されています。
ソリューションアーキテクトは新しいVPCに2層アプリケーションをデプロイします。設定を簡素化するために、Amazon RDSエンドポイント用のdb.example.com CNAMEレコードセットがAmazon Route 53のプライベートホストゾーンに作成されました。
デプロイ中、アプリケーションの起動に失敗しました。トラブルシューティングにより、Amazon EC2インスタンス上でdb.example.comが名前解決できないことが判明しました。ソリューションアーキテクトは、Route 53でレコードセットが正しく作成されていることを確認しました。
この問題を解決するためにソリューションアーキテクトが取るべき手順の組み合わせはどれですか。(2つ選択)
選択肢:
A. 新しいVPC内の別のEC2インスタンスにデータベースをデプロイする。プライベートホストゾーン内でインスタンスのプライベートIP用のレコードセットを作成する。
B. SSHを使用してアプリケーション層EC2インスタンスに接続する。/etc/resolv.confファイルにRDSエンドポイントIPアドレスを追加する。
C. Account AのプライベートホストゾーンをAccount Bの新しいVPCと関連付ける認証を作成する。
D. Account Bでexample.comドメイン用のプライベートホストゾーンを作成する。AWSアカウント間でRoute 53レプリケーションを設定する。
E. Account Bの新しいVPCをAccount Aのホストゾーンと関連付ける。Account Aの関連付け認証を削除する。
正解:C, E
解説:
A. 新しいVPC内の別のEC2インスタンスにデータベースをデプロイする。プライベートホストゾーン内でインスタンスのプライベートIP用のレコードセットを作成する。
不正解 データベースを別のEC2インスタンスにデプロイしても、クロスアカウントDNS解決の根本問題は解決されません。Account BのVPCがAccount Aのプライベートホストゾーンにアクセスできない状況は変わらず、レコードセットを作成してもAccount BのEC2インスタンスからは依然として名前解決できません。
B. SSHを使用してアプリケーション層EC2インスタンスに接続する。/etc/resolv.confファイルにRDSエンドポイントIPアドレスを追加する。
不正解 /etc/resolv.confファイルの手動編集は一時的な回避策にすぎず、スケーラブルではありません。Auto Scalingでインスタンスが新規作成される度に設定が失われ、RDSエンドポイントのIPアドレス変更時にも対応できません。また、企業が目指すDNSの一元管理アーキテクチャに反します。
C. Account AのプライベートホストゾーンをAccount Bの新しいVPCと関連付ける認証を作成する。
正解 Route 53でクロスアカウントのプライベートホストゾーン関連付けを行うには、まずホストゾーンを所有するアカウント(Account A)で関連付け認証を作成する必要があります。この認証により、他のアカウント(Account B)のVPCがプライベートホストゾーンと関連付けられることが許可されます。
D. Account Bでexample.comドメイン用のプライベートホストゾーンを作成する。AWSアカウント間でRoute 53レプリケーションを設定する。
不正解 Route 53には組み込みのレプリケーション機能がありません。Account Bで別のプライベートホストゾーンを作成することは、企業が求める一元的なDNS管理の方針に反し、管理の複雑性を増加させます。また、レプリケーション設定は実装が困難で不要です。
E. Account Bの新しいVPCをAccount Aのホストゾーンと関連付ける。Account Aの関連付け認証を削除する。
正解 Account Aで認証を作成した後、Account BのVPCをAccount Aのプライベートホストゾーンと実際に関連付けます。関連付け完了後は、セキュリティベストプラクティスとして認証を削除します。これにより同じ認証が再利用されることを防ぎ、セキュリティリスクを軽減できます。
全体的な説明
問われている要件
- マルチアカウント環境でのプライベートDNS解決の実現
- Account AのRoute 53プライベートホストゾーンの利用継続
- Account BのVPC内EC2インスタンスからの名前解決機能
- 企業の一元的なDNS管理アーキテクチャの維持
- セキュリティベストプラクティスに従った実装
前提知識
Route 53プライベートホストゾーンのクロスアカウント関連付けについて
- プライベートホストゾーンは通常、同一アカウント内のVPCとのみ関連付けることができますが、適切な手順により他のアカウントのVPCとも関連付け可能です。
- クロスアカウント関連付けには2段階のプロセスが必要です:まず認証の作成、次に実際の関連付けの実行です。
- 関連付け認証は、ホストゾーンを所有するアカウントが他のアカウントのVPCとの関連付けを許可するためのメカニズムです。
- 関連付け完了後は、セキュリティベストプラクティスとして認証を削除することが推奨されます。
DNS解決メカニズムとVPC設定について
- VPC内のEC2インスタンスは、VPCのDNS解決設定とRoute 53リゾルバーを使用してDNSクエリを処理します。
- プライベートホストゾーンがVPCと関連付けられている場合、そのVPC内のリソースはホストゾーン内のレコードを解決できます。
- 関連付けがない場合、VPC内のリソースはプライベートホストゾーン内のレコードにアクセスできず、パブリックDNSやデフォルトのAWSサービスドメインのみが解決されます。
マルチアカウントアーキテクチャのベストプラクティスについて
- 一元的なDNS管理により、複数のアカウント間での一貫性とガバナンスを確保できます。
- 各アカウントで独立したDNSインフラを構築すると、管理の複雑性が増加し、一貫性の維持が困難になります。
- セキュリティの観点から、必要最小限の権限と一時的な認証の使用が重要です。
解くための考え方
この問題の核心は、マルチアカウント環境でのRoute 53プライベートホストゾーンのクロスアカウントアクセスです。問題文から、企業は一元的なDNS管理(Account A)を採用しており、この方針を維持したいことが分かります。
Account BのEC2インスタンスがdb.example.comを解決できない原因は、Account AのプライベートホストゾーンとAccount BのVPCが関連付けられていないことです。Route 53のレコードは正しく作成されているため、問題はアクセス権限にあります。
Route 53でのクロスアカウントプライベートホストゾーン関連付けは、2段階のプロセスで実行されます。まず、ホストゾーンを所有するAccount Aで関連付け認証を作成し、次にAccount BからVPCを関連付けます。この順序は重要で、認証なしには関連付けができません。
関連付け完了後の認証削除は、セキュリティベストプラクティスであり、同じ認証が後に悪用されるリスクを防ぎます。
アーキテクチャ図
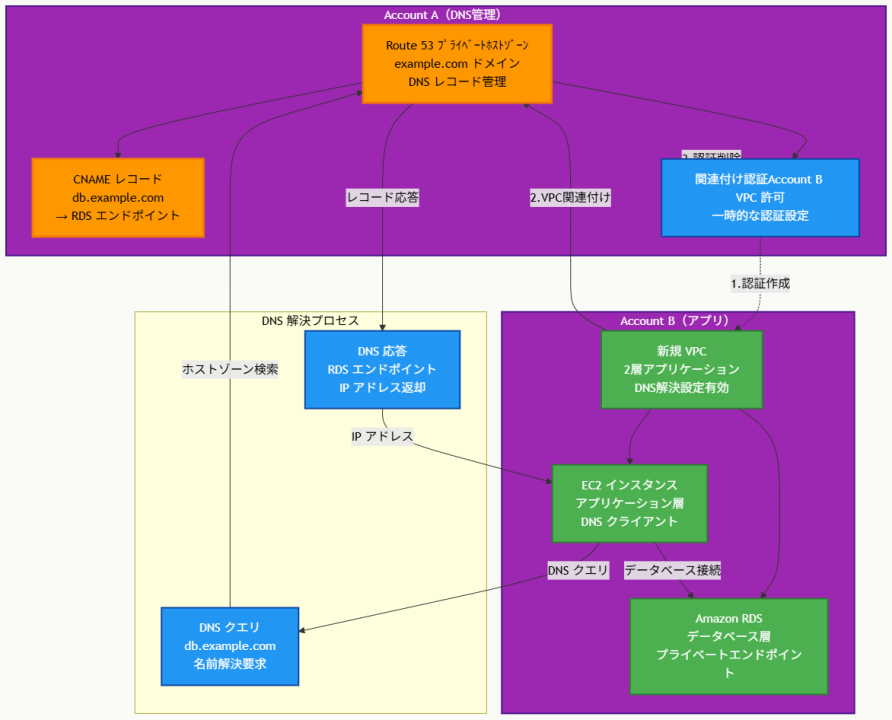
アーキテクチャ図の解説
段階的なクロスアカウント関連付けプロセス
このアーキテクチャでは、Route 53プライベートホストゾーンのクロスアカウントアクセスを実現する3段階のプロセスが示されています。まず、Account Aで関連付け認証を作成してAccount BのVPCからのアクセスを許可し、次にAccount BからVPCをプライベートホストゾーンと関連付けます。最後に、セキュリティベストプラクティスとして認証を削除し、再利用を防止します。
DNS解決フローの実現
関連付けが完了すると、Account BのEC2インスタンスからのDNSクエリ(db.example.com)がAccount AのRoute 53プライベートホストゾーンで処理されます。CNAMEレコードによりRDSエンドポイントのIPアドレスが返却され、EC2インスタンスは正常にデータベースに接続できるようになります。この仕組みにより、マルチアカウント環境でも一元的なDNS管理が維持されます。
他のソリューションとの比較
手動でのDNS設定によるアプローチでは、/etc/resolv.confファイルを編集してRDSエンドポイントのIPアドレスを直接指定する方法がありますが、これは管理上の問題を引き起こします。Auto Scalingによる新しいインスタンス起動時に設定が失われ、RDSエンドポイントのIPアドレス変更時にも手動で更新が必要となります。
Account Bに独立したプライベートホストゾーンを作成するアプローチでは、企業の一元的DNS管理方針に反し、管理の複雑性が増加します。レプリケーション設定は技術的に困難で、データの一貫性を保つことも困難です。また、複数のアカウントで同じドメインのホストゾーンを管理することは、管理上の混乱を招く可能性があります。
データベースをEC2インスタンスに移行するアプローチは、マネージドサービスであるRDSの利点を放棄することになり、運用負荷の増加とセキュリティリスクの向上を招きます。また、クロスアカウントDNS解決の根本問題は解決されません。
実装の考慮事項
実装時には、両方のアカウントで適切なIAM権限が設定されている必要があります。Account AではRoute 53の関連付け認証作成権限が、Account BではVPC関連付け権限が必要です。
関連付け認証の管理では、認証の有効期限やスコープを適切に設定し、必要最小限のアクセス権限のみを付与することが重要です。認証作成から関連付け完了までの時間を最小限に抑え、セキュリティリスクを軽減します。
VPC設定では、DNS解決とDNSホスト名の設定が有効になっている必要があります。これらの設定が無効の場合、プライベートホストゾーンとの関連付けが完了してもDNS解決が機能しません。
監視とログ記録では、DNS解決の状況をCloudWatch Logsで監視し、関連付けの状態変更をCloudTrailで記録することが推奨されます。これにより、DNS解決の問題が発生した際の迅速な診断と対応が可能になります。
参考資料
問題文:
企業がブログサイトをホストするためにAmazon EC2インスタンスを使用してWebフリートをデプロイしました。EC2インスタンスはApplication Load Balancer(ALB)の背後にあり、Auto Scalingグループで設定されています。WebアプリケーションはすべてのブログコンテンツをAmazon EFSボリュームに保存しています。
同社は最近、ブロガーが投稿に動画を追加できる機能を追加し、以前の10倍のユーザートラフィックを集めています。1日のピーク時間帯に、ユーザーはサイトにアクセスしたり動画を視聴しようとする際にバッファリングとタイムアウトの問題を報告しています。
ユーザーの問題を解決する最もコスト効率的でスケーラブルなデプロイメントはどれですか。
選択肢:
A. Amazon EFSを最大I/Oを有効にするように再設定する。
B. ストレージにインスタンスストアボリュームを使用するようにブログサイトを更新する。起動時にサイトコンテンツをボリュームにコピーし、シャットダウン時にAmazon S3にコピーする。
C. Amazon CloudFront配信を設定する。配信をS3バケットに向けて、動画をEFSからAmazon S3に移行する。
D. すべてのサイトコンテンツ用にAmazon CloudFront配信を設定し、配信をALBに向ける。
正解:C
解説:
A. Amazon EFSを最大I/Oを有効にするように再設定する。
不正解 EFSの最大I/Oモードは高いIOPSを提供しますが、レイテンシが増加するため、動画配信には逆効果となる可能性があります。また、既存のEFSファイルシステムでは最大I/Oモードを有効にできないため、新しいファイルシステムの作成とデータ移行が必要になります。動画配信の根本的な問題であるネットワーク帯域幅とエッジキャッシングの課題は解決されません。
B. ストレージにインスタンスストアボリュームを使用するようにブログサイトを更新する。起動時にサイトコンテンツをボリュームにコピーし、シャットダウン時にAmazon S3にコピーする。
不正解 インスタンスストアボリュームは一般的にEBSよりも高コストで、Auto Scalingグループでの一貫性の問題があります。新しいインスタンスが起動する度にサイトコンテンツをコピーする必要があり、スケーラビリティに欠けます。また、CDNなしでは地理的に分散したユーザーに対する性能改善が限定的です。
C. Amazon CloudFront配信を設定する。配信をS3バケットに向けて、動画をEFSからAmazon S3に移行する。
正解 CloudFrontとS3の組み合わせにより、動画コンテンツを世界中のエッジロケーションでキャッシュし、ユーザーに最も近い場所から配信できます。S3は動画などの大容量静的コンテンツに最適化された低コストストレージサービスです。この構成により静的コンテンツ(動画)と動的コンテンツ(ブログページ)を分離し、それぞれに最適化されたインフラを使用できます。
D. すべてのサイトコンテンツ用にAmazon CloudFront配信を設定し、配信をALBに向ける。
不正解 すべてのサイトコンテンツをCloudFrontで配信することは性能向上をもたらしますが、動画をEFSに保存し続けることでストレージコストが高くなります。EFSはファイルシステムストレージで動画保存には不適切で、S3と比較して大幅にコストが高くなります。また、動的コンテンツまでCDN経由となることで不要なコストが発生します。
全体的な説明
問われている要件
- 動画機能追加による10倍のトラフィック増加への対応
- バッファリングとタイムアウト問題の解決
- コスト効率性とスケーラビリティの両立
- 既存のAuto Scalingアーキテクチャとの統合
- 高可用性とパフォーマンスの確保
前提知識
CloudFrontとコンテンツ配信について
- Amazon CloudFrontは世界中に分散されたエッジロケーションを持つコンテンツ配信ネットワーク(CDN)サービスです。静的コンテンツをユーザーに最も近いエッジロケーションにキャッシュすることで、レイテンシを大幅に削減できます。
- 動画コンテンツは大容量で帯域幅を多く消費するため、CDNによるエッジキャッシュが特に効果的です。オリジンサーバーへの負荷を軽減し、エンドユーザーエクスペリエンスを向上させます。
- CloudFrontは様々なオリジンタイプ(S3、ALB、カスタムオリジン)をサポートし、コンテンツタイプに応じた最適な配信戦略を実装できます。
Amazon S3による静的コンテンツ保存について
- S3は11 9’s(99.999999999%)の耐久性を提供し、静的コンテンツの保存に最適化されています。動画ファイルのような大容量コンテンツに対してコスト効率的なストレージを提供します。
- 複数のストレージクラス(Standard、IA、Glacier等)により、アクセス頻度に応じたコスト最適化が可能です。
- CloudFrontとの統合により、オリジンフェッチの最適化とキャッシュ効率の向上が実現されます。
Amazon EFSの特性と制限について
- EFSは共有ファイルシステムとして設計されており、複数のEC2インスタンスから同時にマウント可能です。アプリケーションファイルや設定ファイルの共有には適していますが、大容量の静的コンテンツには最適ではありません。
- スループットモード(General Purpose、Provisioned、Max I/O)の選択により性能特性が変わりますが、レイテンシとコストのトレードオフが存在します。
- 動画配信のようなワークロードでは、S3+CloudFrontの組み合わせが一般的により適切なソリューションとなります。
解くための考え方
この問題の核心は、動画機能追加による急激なトラフィック増加とそれに伴うパフォーマンス問題への対処です。動画コンテンツは大容量で帯域幅を多く消費するため、従来のWebサーバーベースの配信では限界があります。
問題分析から、現在の構成(EFS + EC2 + ALB)は動的なWebコンテンツには適していますが、静的な大容量動画コンテンツの配信には最適化されていないことが分かります。バッファリングやタイムアウト問題は、主にネットワーク帯域幅の制約とエッジキャッシュの不足によるものです。
解決策として、静的コンテンツ(動画)と動的コンテンツ(ブログページ)を分離し、それぞれに最適化されたインフラを使用するアプローチが最も効果的です。動画をS3に移行してCloudFrontで配信することで、世界中のエッジロケーションからの高速配信が可能になり、オリジンサーバーの負荷も軽減されます。
コスト効率性の観点では、S3はEFSよりも大幅に安価で、CloudFrontの従量課金モデルにより必要な分だけの費用で済みます。選択肢のうち、すべてのコンテンツをCDN経由にするアプローチは不要なコストを発生させるため最適ではありません。
アーキテクチャ図
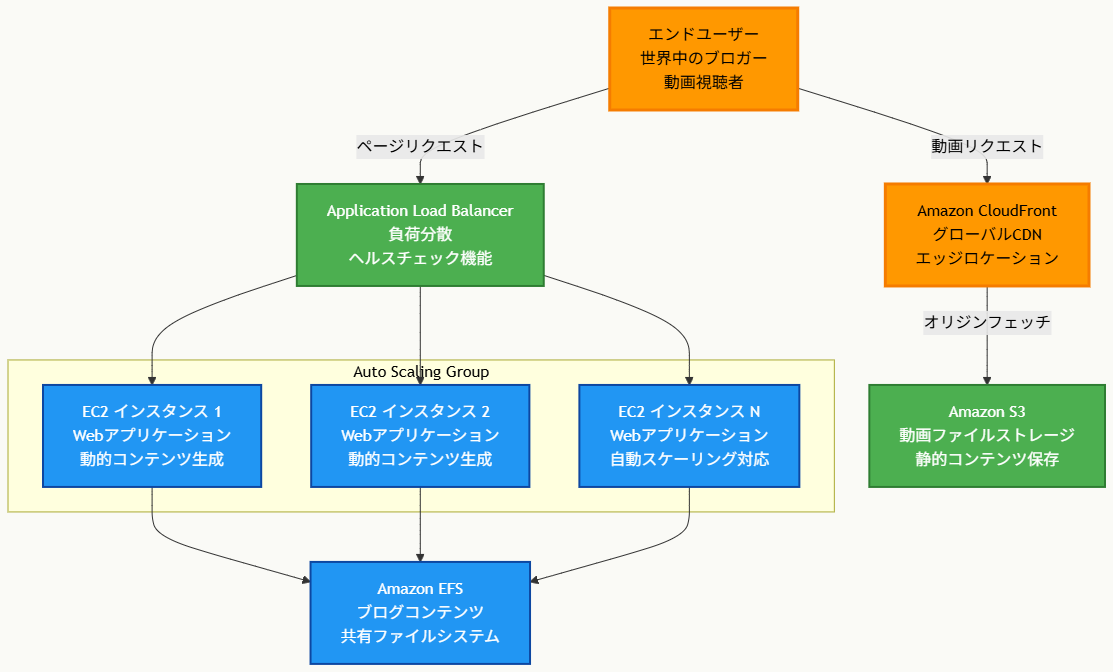
アーキテクチャ図の解説
静的・動的コンテンツの最適化分離
このアーキテクチャでは、動画コンテンツ(静的)とブログページ(動的)を異なるインフラで処理することで、それぞれに最適化された配信を実現しています。エンドユーザーからの動画リクエストはCloudFrontが処理してS3から配信し、ブログページリクエストは従来通りALBがAuto ScalingされたEC2インスタンス群に振り分けます。この分離により、大容量動画による負荷が既存のWebアプリケーションインフラに影響することを防ぎます。
グローバルエッジキャッシュによる性能向上
CloudFrontの世界中に分散されたエッジロケーションにより、動画コンテンツはユーザーに最も近い場所から配信されます。初回アクセス時にS3からオリジンフェッチされた動画は、その後のアクセスではエッジキャッシュから高速配信されるため、バッファリングやタイムアウト問題が大幅に改善されます。また、オリジンサーバーへの負荷も軽減され、EC2インスタンスは動的コンテンツ処理に専念できます。
他のソリューションとの比較
EFSの最大I/O設定によるアプローチでは、IOPSは向上しますが、レイテンシが増加するため動画配信には適していません。また、既存ファイルシステムでは設定変更ができないため、データ移行が必要となりコストと時間がかかります。
インスタンスストアボリュームを使用するアプローチは、Auto Scalingによる新しいインスタンス起動時の一貫性問題があります。各インスタンスでのデータ同期が困難で、地理的分散配信の課題も解決されません。
全サイトコンテンツをCloudFrontで配信するアプローチは性能向上をもたらしますが、動画を高コストなEFSに保存し続けることでコスト効率性が損なわれます。また、動的コンテンツまでCDN経由とすることで不要なコストが発生し、キャッシュ制御の複雑性も増加します。
実装の考慮事項
動画コンテンツのS3移行では、既存のEFSからS3への一括移行スクリプトを作成し、ダウンタイムを最小限に抑えた移行戦略が必要です。また、Webアプリケーションの動画リンクをCloudFrontのURLに更新する必要があります。
CloudFrontの設定では、動画コンテンツに適したキャッシュポリシー(長期キャッシュ)と、必要に応じて地理的制限を設定します。S3では、アクセス頻度に応じたストレージクラスの選択により、さらなるコスト最適化が可能です。
監視面では、CloudWatchを使用してCloudFrontのキャッシュヒット率、S3のリクエスト数、エラー率を監視し、パフォーマンスの継続的な最適化を行います。また、コスト監視により、予想外の費用増加を早期に検知する体制も重要です。
参考資料
問題文:
グローバルオフィスを持つ企業が、単一のAWSリージョンに対して単一の1 Gbps AWS Direct Connect接続を持っています。企業のオンプレミスネットワークは、この接続を使用してAWS Cloud内の企業リソースと通信しています。接続には、単一のVPCに接続する単一のプライベート仮想インターフェースがあります。
ソリューションアーキテクトは、同じリージョンに冗長なDirect Connect接続を追加するソリューションを実装する必要があります。また、ソリューションは、企業が他のリージョンに拡張する際に、同じDirect Connect接続のペアを通じて他のリージョンへの接続も提供する必要があります。
これらの要件を満たすソリューションはどれですか。
選択肢:
A. Direct Connect gatewayをプロビジョニングする。既存の接続から既存のプライベート仮想インターフェースを削除する。2番目のDirect Connect接続を作成する。各接続に新しいプライベート仮想インターフェースを作成し、両方のプライベート仮想インターフェースをDirect Connect gatewayに接続する。Direct Connect gatewayを単一のVPCに接続する。
B. 既存のプライベート仮想インターフェースを維持する。2番目のDirect Connect接続を作成する。新しい接続に新しいプライベート仮想インターフェースを作成し、新しいプライベート仮想インターフェースを単一のVPCに接続する。
C. 既存のプライベート仮想インターフェースを維持する。2番目のDirect Connect接続を作成する。新しい接続に新しいパブリック仮想インターフェースを作成し、新しいパブリック仮想インターフェースを単一のVPCに接続する。
D. transit gatewayをプロビジョニングする。既存の接続から既存のプライベート仮想インターフェースを削除する。2番目のDirect Connect接続を作成する。各接続に新しいプライベート仮想インターフェースを作成し、両方のプライベート仮想インターフェースをtransit gatewayに接続する。transit gatewayを単一のVPCに関連付ける。
正解:A
解説:
A. Direct Connect gatewayをプロビジョニングする。既存の接続から既存のプライベート仮想インターフェースを削除する。2番目のDirect Connect接続を作成する。各接続に新しいプライベート仮想インターフェースを作成し、両方のプライベート仮想インターフェースをDirect Connect gatewayに接続する。Direct Connect gatewayを単一のVPCに接続する。
正解 Direct Connect Gatewayは、複数のDirect Connect接続を統合し、マルチリージョンVPC接続を提供するグローバルサービスです。既存のプライベート仮想インターフェースを削除して両方の接続に新しいVIFを作成し、Direct Connect Gatewayに接続することで、冗長性と将来的なマルチリージョン展開への対応を同時に実現できます。この構成により、単一の管理ポイントから複数リージョンのVPCへの接続が可能になります。
B. 既存のプライベート仮想インターフェースを維持する。2番目のDirect Connect接続を作成する。新しい接続に新しいプライベート仮想インターフェースを作成し、新しいプライベート仮想インターフェースを単一のVPCに接続する。
不正解 この構成は現在のVPCに対する冗長性は提供しますが、マルチリージョン接続の要件を満たしません。2つの独立したプライベート仮想インターフェースが同じVPCに接続されることで、ルーティングの複雑性や設定の一貫性に問題が生じる可能性もあります。将来的なリージョン拡張時に追加の設定変更が必要となります。
C. 既存のプライベート仮想インターフェースを維持する。2番目のDirect Connect接続を作成する。新しい接続に新しいパブリック仮想インターフェースを作成し、新しいパブリック仮想インターフェースを単一のVPCに接続する。
不正解 パブリック仮想インターフェースはVPCリソースへの接続には使用できません。パブリックVIFは、S3やCloudFrontなどのAWSパブリックサービスへのアクセスに使用されるもので、VPC内のプライベートリソースとの通信には適していません。この選択肢は技術的に実現不可能です。
D. transit gatewayをプロビジョニングする。既存の接続から既存のプライベート仮想インターフェースを削除する。2番目のDirect Connect接続を作成する。各接続に新しいプライベート仮想インターフェースを作成し、両方のプライベート仮想インターフェースをtransit gatewayに接続する。transit gatewayを単一のVPCに関連付ける。
不正解 Transit Gatewayはリージョナルサービスであり、単体ではマルチリージョン接続を提供できません。また、Direct ConnectからTransit Gatewayへの接続には通常、Transit仮想インターフェース(Transit VIF)が必要で、プライベートVIFでの直接接続は標準的な構成ではありません。リージョン間のピアリングが必要となり、設定の複雑性が増します。
全体的な説明
問われている要件
- 既存のDirect Connect接続に対する冗長性の追加
- 同じリージョン内での高可用性確保
- 将来的なマルチリージョン展開への対応
- 同一のDirect Connect接続ペアでの複数リージョン接続
- スケーラブルで管理しやすいアーキテクチャ
前提知識
Direct Connect Gatewayの特徴について
- Direct Connect Gatewayは、複数のDirect Connect接続を統合し、世界中の複数リージョンのVPCへの接続を提供するグローバルサービスです。
- 最大10のリージョンにわたって最大100のVPCに接続できる高いスケーラビリティを提供します。
- 自動フェイルオーバー機能により、Direct Connect接続の障害時に冗長接続への切り替えが自動実行されます。
- ルート集約機能により、オンプレミスからの単一ルート設定で複数リージョンのVPCにアクセス可能です。
Transit Gatewayとの違いについて
- Transit Gatewayはリージョナルサービスで、単一リージョン内でのVPC間接続とオンプレミス接続を統合します。
- マルチリージョン接続には、リージョン間でのTransit Gateway Peeringが必要となり、設定の複雑性が増します。
- Direct ConnectからTransit Gatewayへの接続には、通常Transit VIFまたはDirect Connect Gateway経由での接続が推奨されます。
仮想インターフェース(VIF)の種類について
- プライベートVIF:特定のVPCへのプライベート接続を提供し、VPC内リソースへの直接アクセスを可能にします。
- パブリックVIF:AWSのパブリックサービス(S3、CloudFrontなど)への接続を提供しますが、VPCリソースには接続できません。
- Transit VIF:Transit GatewayやDirect Connect Gatewayとの接続に使用される特別なVIFタイプです。
解くための考え方
この問題の核心は、現在のシンプルな単一接続構成から、冗長性とマルチリージョン対応を両立する将来性のあるアーキテクチャへの移行です。
現在の構成(単一Direct Connect + 単一プライベートVIF + 単一VPC)は、単一障害点が存在し、将来的なリージョン拡張にも対応できません。要件として「同じDirect Connect接続ペアを通じて他のリージョンへの接続」が明示されているため、グローバルサービスであるDirect Connect Gatewayの活用が最適です。
Direct Connect Gatewayを使用することで、複数のDirect Connect接続を統合し、世界中のリージョンのVPCに対する統一されたアクセスポイントを提供できます。既存のプライベートVIFを削除して新しいアーキテクチャに移行することで、設定の一貫性と管理の簡素化を実現できます。
Transit Gatewayはリージョナルサービスのため、マルチリージョン要件を満たすには複数のTransit Gateway間でのピアリング設定が必要となり、Direct Connect Gatewayと比較して設定が複雑になります。
アーキテクチャ図
アーキテクチャ図の解説
冗長性とグローバル接続の統合
このアーキテクチャでは、2つのDirect Connect接続がそれぞれプライベートVIFを通じてDirect Connect Gatewayに接続されています。Direct Connect Gatewayはグローバルサービスとして機能し、複数のDirect Connect接続からの冗長性を提供しながら、世界中の複数リージョンのVPCへの統一されたアクセスポイントとなります。BGPルーティングプロトコルにより、接続障害時の自動フェイルオーバーが実現されます。
スケーラブルなマルチリージョン展開
現在のリージョンの既存VPCはVirtual Private Gatewayを通じてDirect Connect Gatewayに接続されており、将来的な他のリージョンへの展開時も、同様の構成で簡単に追加できます。企業のオンプレミスネットワークからは、単一のルーティング設定で全てのリージョンのVPCにアクセス可能となり、ネットワーク管理の複雑性が大幅に軽減されます。
他のソリューションとの比較
単一VPCへの複数プライベートVIF接続によるアプローチでは、冗長性は確保できますが、ルーティングテーブルの管理が複雑になり、将来的なマルチリージョン展開時に大幅な設定変更が必要となります。また、BGPの設定や経路制御も複雑化します。
Transit Gatewayベースのソリューションでは、リージョナルサービスの制約により、マルチリージョン接続にはリージョン間ピアリングが必要となります。これは追加の設定複雑性とコストを発生させ、Direct Connect接続から各リージョンのTransit Gatewayへの個別接続管理も必要となります。
パブリックVIFを使用するアプローチは、技術的に実現不可能です。パブリックVIFはAWSのパブリックサービスへのアクセス専用で、VPC内のプライベートリソースとは通信できません。
実装の考慮事項
既存のプライベートVIFから新しいアーキテクチャへの移行では、ダウンタイムを最小限に抑える段階的移行戦略が重要です。新しいDirect Connect接続とVIFを先に準備し、Direct Connect Gatewayの設定完了後に既存接続からの切り替えを実行します。
BGPルーティング設定では、適切なAS-PATH属性とLocal Preferenceの設定により、プライマリ・バックアップ経路の制御を行います。また、BFD(Bidirectional Forwarding Detection)を有効化して、リンク障害の迅速な検知を実現します。
監視とアラート体制では、CloudWatchメトリクスを使用してDirect Connect接続の状態、BGPセッションの状態、トラフィック量を監視し、接続障害やパフォーマンス低下を早期検知する仕組みを構築します。
参考資料
筆者のUdemy講師ページはこちら。
スポンサーリンク
以下スポンサーリンクです。
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。