AWS SAA無料問題集です。正解と解説を確認する際は右側のボタンを押下してください。
問題集の完全版は以下Udemyにて発売しているためお買い求めください。問題集への質問はUdemyのQA機能もしくはUdemyのメッセージにて承ります。Udemyの問題1から15問抜粋しております。
多くの方にご好評いただき、講師評価 4.5/5.0 を獲得できております。ありがとうございます。

特別価格: 通常2,600円 → 1,500円
講師クーポン適用で42%OFF
【図解付き】AWS SAP-C02完全対応 2025年版本番同等演習問題集+詳細解説

問題文:
ある企業は複数の大陸にまたがる都市で気温、湿度、大気圧のデータを収集しています。各拠点から毎日収集されるデータの平均量は500GBです。すべての拠点には高速インターネット回線が導入されています。この企業は、世界中のすべての拠点からのデータを可能な限り迅速に単一のAmazon S3バケットに統合したいと考えています。ソリューションは運用上の複雑性を最小限に抑える必要があります。
これらの要件を満たすソリューションはどれでしょうか?
選択肢:
A. 各拠点から最も近いリージョンのS3バケットにデータをアップロードする。S3クロスリージョンレプリケーションを使用してオブジェクトを目的地S3バケットにコピーする。その後、元のS3バケットからデータを削除する。
B. 各拠点から最も近いリージョンのAmazon EC2インスタンスにデータをアップロードする。データをAmazon Elastic Block Store(Amazon EBS)ボリュームに保存する。定期的にEBSスナップショットを取得し、目的地S3バケットが配置されているリージョンにコピーする。そのリージョンでEBSボリュームを復元する。
C. 各拠点から最も近いリージョンにデータを転送するために、AWS Snowball Edge Storage Optimizedデバイスのジョブを毎日スケジュールする。S3クロスリージョンレプリケーションを使用してオブジェクトを目的地S3バケットにコピーする。
D. 目的地となるS3バケットでS3 Transfer Accelerationを有効化する。マルチパートアップロードを利用して拠点データを目的地S3バケットに直接アップロードする。
正解:D
A. 各拠点から最も近いリージョンのS3バケットにデータをアップロードする。S3クロスリージョンレプリケーションを使用してオブジェクトを目的地S3バケットにコピーする。その後、元のS3バケットからデータを削除する。
不正解 このアプローチは技術的には実現可能ですが、複数のステップが必要で運用が複雑になります。最寄りのリージョンへのアップロード、クロスリージョンレプリケーションの設定と監視、元のバケットからのデータ削除など、手動の介入が必要な作業が含まれます。また、クロスリージョンレプリケーションには追加のコストがかかり、データの重複保存期間中のストレージコストも発生します。高速インターネット接続があるにも関わらず、Transfer Accelerationと比較して最適化されていないアプローチとなります。
B. 各拠点から最も近いリージョンのAmazon EC2インスタンスにデータをアップロードする。データをAmazon Elastic Block Store(Amazon EBS)ボリュームに保存する。定期的にEBSスナップショットを取得し、目的地S3バケットが配置されているリージョンにコピーする。そのリージョンでEBSボリュームを復元する。
不正解 最も複雑で非効率的なソリューションです。EC2インスタンス、EBSボリューム、スナップショットという複数のコンポーネントが必要で、運用オーバーヘッドが大幅に増加します。定期的なスナップショットの作成、リージョン間でのスナップショットコピー、EBSボリュームの復元など、多くの手動作業が必要です。データがS3に直接アップロードできるにも関わらず、不要な中間ステップとコストが発生し、データの可用性も低下します。
C. 各拠点から最も近いリージョンにデータを転送するために、AWS Snowball Edge Storage Optimizedデバイスのジョブを毎日スケジュールする。S3クロスリージョンレプリケーションを使用してオブジェクトを目的地S3バケットにコピーする。
不正解 各拠点に高速インターネット接続があるにも関わらず、物理的なSnowball Edgeデバイスを使用することは非効率的です。デバイスの注文、配送、データ転送、返送という一連のプロセスが必要で、日次のデータ転送には適していません。Snowballデバイスは、インターネット接続が限定的な環境や、ペタバイト規模の一回限りのデータ移行に適しています。毎日のデータ転送にSnowball Edgeを使用することは、運用オーバーヘッドとコストの両面で非現実的です。
D. 目的地となるS3バケットでS3 Transfer Accelerationを有効化する。マルチパートアップロードを利用して拠点データを目的地S3バケットに直接アップロードする。
正解 S3 Transfer Accelerationは、Amazon CloudFrontの世界中に分散したエッジロケーションを活用して、長距離でのデータ転送を最適化します。マルチパートアップロードは500GBという大容量ファイルの並列アップロードを可能にし、転送速度と信頼性を大幅に向上させます。この組み合わせは、中間的な保存場所や追加のインフラストラクチャを必要とせず、直接目的地バケットへの最適化されたパスを提供するため、運用の複雑さを最小化します。高速インターネット接続が利用可能な環境では、最も効率的で実用的なソリューションです。
全体的な説明
問われている要件
この問題では以下の要件を満たすソリューションが求められています:
- グローバルな分散環境からの高速データ転送:複数の大陸にある都市からのデータを効率的に集約する必要があります
- 大容量データの効率的な転送:各拠点から日次500GBという大容量のデータを処理する必要があります
- 運用の複雑さの最小化:シンプルで管理しやすいソリューションが求められています
- 高速インターネット接続の活用:各拠点に既存のインフラストラクチャを有効活用する必要があります
前提知識
S3 Transfer Accelerationの適用場面について理解しておく必要があります:
- 地理的に分散したユーザーからのアップロード
- 大容量ファイルの長距離転送
- 高速インターネット接続が利用可能な環境
- 転送速度の予測可能性が重要な場合
マルチパートアップロードの基準も重要です:
- 100MB以上のファイルに推奨される
- 5GB以上のファイルでは必須となる
- 並列処理による速度向上が期待できる
- 部分的な失敗時の再送効率が向上する
AWS Snowballの適用場面についても理解が必要です:
- インターネット接続が限定的な環境
- ペタバイト規模の一回限りのデータ移行
- 高速インターネット接続が利用できない場合
- 継続的なデータ転送には適していない
クロスリージョンレプリケーションの特徴も重要です:
- 災害復旧やコンプライアンス要件に適している
- 追加のコストが発生する
- レプリケーション遅延が発生する可能性がある
- 手動でのデータ削除が必要な場合がある
解くための考え方
S3 Transfer Accelerationの仕組みを理解することが重要です。S3 Transfer Accelerationは、Amazon CloudFrontの世界中に分散したエッジロケーションを活用して、S3バケットへの転送を高速化する機能です。通常のインターネット経由の転送と比較して、50-500%の性能向上が期待できます。
マルチパートアップロードの利点も考慮する必要があります。500GBという大容量ファイルに対しては、マルチパートアップロードが不可欠です。これにより、ファイルを複数の部分に分割して並列アップロードが可能になり、転送速度の向上とネットワーク障害時の復旧性が向上します。
運用の複雑さを評価する際は、各ソリューションに必要なステップ数を比較することが重要です。単一ステップのソリューションは、複数ステップのソリューションと比較して運用が簡単で、障害点も少なくなります。
アーキテクチャ図
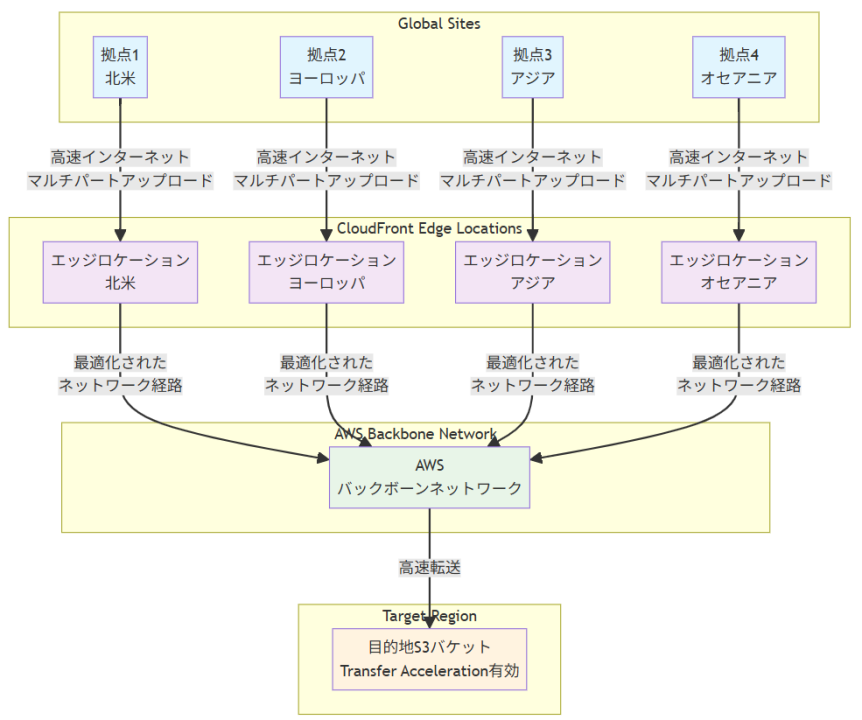
データ転送フロー
S3 Transfer Accelerationを使用した場合のデータ転送フローは以下のようになります。各拠点から収集されたデータは、まず最寄りのCloudFrontエッジロケーションに高速インターネット経由でアップロードされます。この際、マルチパートアップロードによって大容量データの並列転送が行われます。エッジロケーションに到達したデータは、AWSの最適化されたバックボーンネットワークを通じて目的地S3バケットに転送されます。このプロセス全体で、転送速度が大幅に向上し、運用の複雑さが最小化されます。
コストと性能の考慮事項
S3 Transfer Accelerationを使用する場合、加速された転送に対してのみ追加料金が発生します。転送が加速されない場合は、標準の転送料金のみが適用されます。性能面では、特に長距離での大容量ファイル転送において、50-500%の速度向上が期待できます。マルチパートアップロードと組み合わせることで、ネットワーク障害時の復旧性も向上し、全体的な転送効率が最適化されます。
参考資料
問題文:
ある企業は複数の大陸にまたがる都市で気温、湿度、大気圧のデータを収集しています。各拠点から毎日収集されるデータの平均量は500GBです。すべての拠点には高速インターネット回線が導入されています。この企業は、世界中のすべての拠点からのデータを可能な限り迅速に単一のAmazon S3バケットに統合したいと考えています。ソリューションは運用上の複雑性を最小限に抑える必要があります。
これらの要件を満たすソリューションはどれでしょうか?
選択肢:
A. 各拠点から最も近いリージョンのS3バケットにデータをアップロードする。S3クロスリージョンレプリケーションを使用してオブジェクトを目的地S3バケットにコピーする。その後、元のS3バケットからデータを削除する。
B. 各拠点から最も近いリージョンのAmazon EC2インスタンスにデータをアップロードする。データをAmazon Elastic Block Store(Amazon EBS)ボリュームに保存する。定期的にEBSスナップショットを取得し、目的地S3バケットが配置されているリージョンにコピーする。そのリージョンでEBSボリュームを復元する。
C. 各拠点から最も近いリージョンにデータを転送するために、AWS Snowball Edge Storage Optimizedデバイスのジョブを毎日スケジュールする。S3クロスリージョンレプリケーションを使用してオブジェクトを目的地S3バケットにコピーする。
D. 目的地となるS3バケットでS3 Transfer Accelerationを有効化する。マルチパートアップロードを利用して拠点データを目的地S3バケットに直接アップロードする。
正解:D
A. 各拠点から最も近いリージョンのS3バケットにデータをアップロードする。S3クロスリージョンレプリケーションを使用してオブジェクトを目的地S3バケットにコピーする。その後、元のS3バケットからデータを削除する。
不正解 このアプローチは技術的には実現可能ですが、複数のステップが必要で運用が複雑になります。最寄りのリージョンへのアップロード、クロスリージョンレプリケーションの設定と監視、元のバケットからのデータ削除など、手動の介入が必要な作業が含まれます。また、クロスリージョンレプリケーションには追加のコストがかかり、データの重複保存期間中のストレージコストも発生します。高速インターネット接続があるにも関わらず、Transfer Accelerationと比較して最適化されていないアプローチとなります。
B. 各拠点から最も近いリージョンのAmazon EC2インスタンスにデータをアップロードする。データをAmazon Elastic Block Store(Amazon EBS)ボリュームに保存する。定期的にEBSスナップショットを取得し、目的地S3バケットが配置されているリージョンにコピーする。そのリージョンでEBSボリュームを復元する。
不正解 最も複雑で非効率的なソリューションです。EC2インスタンス、EBSボリューム、スナップショットという複数のコンポーネントが必要で、運用オーバーヘッドが大幅に増加します。定期的なスナップショットの作成、リージョン間でのスナップショットコピー、EBSボリュームの復元など、多くの手動作業が必要です。データがS3に直接アップロードできるにも関わらず、不要な中間ステップとコストが発生し、データの可用性も低下します。
C. 各拠点から最も近いリージョンにデータを転送するために、AWS Snowball Edge Storage Optimizedデバイスのジョブを毎日スケジュールする。S3クロスリージョンレプリケーションを使用してオブジェクトを目的地S3バケットにコピーする。
不正解 各拠点に高速インターネット接続があるにも関わらず、物理的なSnowball Edgeデバイスを使用することは非効率的です。デバイスの注文、配送、データ転送、返送という一連のプロセスが必要で、日次のデータ転送には適していません。Snowballデバイスは、インターネット接続が限定的な環境や、ペタバイト規模の一回限りのデータ移行に適しています。毎日のデータ転送にSnowball Edgeを使用することは、運用オーバーヘッドとコストの両面で非現実的です。
D. 目的地となるS3バケットでS3 Transfer Accelerationを有効化する。マルチパートアップロードを利用して拠点データを目的地S3バケットに直接アップロードする。
正解 S3 Transfer Accelerationは、Amazon CloudFrontの世界中に分散したエッジロケーションを活用して、長距離でのデータ転送を最適化します。マルチパートアップロードは500GBという大容量ファイルの並列アップロードを可能にし、転送速度と信頼性を大幅に向上させます。この組み合わせは、中間的な保存場所や追加のインフラストラクチャを必要とせず、直接目的地バケットへの最適化されたパスを提供するため、運用の複雑さを最小化します。高速インターネット接続が利用可能な環境では、最も効率的で実用的なソリューションです。
全体的な説明
問われている要件
この問題では以下の要件を満たすソリューションが求められています:
- グローバルな分散環境からの高速データ転送:複数の大陸にある都市からのデータを効率的に集約する必要があります
- 大容量データの効率的な転送:各拠点から日次500GBという大容量のデータを処理する必要があります
- 運用の複雑さの最小化:シンプルで管理しやすいソリューションが求められています
- 高速インターネット接続の活用:各拠点に既存のインフラストラクチャを有効活用する必要があります
前提知識
S3 Transfer Accelerationの適用場面について理解しておく必要があります:
- 地理的に分散したユーザーからのアップロード
- 大容量ファイルの長距離転送
- 高速インターネット接続が利用可能な環境
- 転送速度の予測可能性が重要な場合
マルチパートアップロードの基準も重要です:
- 100MB以上のファイルに推奨される
- 5GB以上のファイルでは必須となる
- 並列処理による速度向上が期待できる
- 部分的な失敗時の再送効率が向上する
AWS Snowballの適用場面についても理解が必要です:
- インターネット接続が限定的な環境
- ペタバイト規模の一回限りのデータ移行
- 高速インターネット接続が利用できない場合
- 継続的なデータ転送には適していない
クロスリージョンレプリケーションの特徴も重要です:
- 災害復旧やコンプライアンス要件に適している
- 追加のコストが発生する
- レプリケーション遅延が発生する可能性がある
- 手動でのデータ削除が必要な場合がある
解くための考え方
S3 Transfer Accelerationの仕組みを理解することが重要です。S3 Transfer Accelerationは、Amazon CloudFrontの世界中に分散したエッジロケーションを活用して、S3バケットへの転送を高速化する機能です。通常のインターネット経由の転送と比較して、50-500%の性能向上が期待できます。
マルチパートアップロードの利点も考慮する必要があります。500GBという大容量ファイルに対しては、マルチパートアップロードが不可欠です。これにより、ファイルを複数の部分に分割して並列アップロードが可能になり、転送速度の向上とネットワーク障害時の復旧性が向上します。
運用の複雑さを評価する際は、各ソリューションに必要なステップ数を比較することが重要です。単一ステップのソリューションは、複数ステップのソリューションと比較して運用が簡単で、障害点も少なくなります。
アーキテクチャ図
データ転送フロー
S3 Transfer Accelerationを使用した場合のデータ転送フローは以下のようになります。各拠点から収集されたデータは、まず最寄りのCloudFrontエッジロケーションに高速インターネット経由でアップロードされます。この際、マルチパートアップロードによって大容量データの並列転送が行われます。エッジロケーションに到達したデータは、AWSの最適化されたバックボーンネットワークを通じて目的地S3バケットに転送されます。このプロセス全体で、転送速度が大幅に向上し、運用の複雑さが最小化されます。
コストと性能の考慮事項
S3 Transfer Accelerationを使用する場合、加速された転送に対してのみ追加料金が発生します。転送が加速されない場合は、標準の転送料金のみが適用されます。性能面では、特に長距離での大容量ファイル転送において、50-500%の速度向上が期待できます。マルチパートアップロードと組み合わせることで、ネットワーク障害時の復旧性も向上し、全体的な転送効率が最適化されます。
参考資料
問題文:
企業がAWS Cloudでパブリック向けWebアプリケーションの立ち上げを準備しています。アーキテクチャは、Elastic Load Balancer(ELB)の背後にあるVPC内のAmazon EC2インスタンスで構成されています。DNSにはサードパーティサービスが使用されており、変更できません。
企業のソリューションアーキテクトは、大規模なDDoS攻撃を検出し、防御するソリューションを推奨する必要があります。
これらの要件を満たすソリューションはどれでしょうか。
選択肢:
A. アカウントでAmazon GuardDutyを有効にする。
B. AWS Shieldを有効にしてAmazon Route 53を割り当てる。
C. EC2インスタンスでAmazon Inspectorを有効にする。
D. AWS Shield Advancedを有効にしてELBを割り当てる。
正解:D
A. アカウントでAmazon GuardDutyを有効にする。
不正解 Amazon GuardDutyは脅威検出サービスで、AWSアカウント内の悪意のあるアクティビティや不正な行動を特定することに特化しています。機械学習を使用してネットワークアクティビティを分析し、セキュリティ脅威を検出しますが、DDoS攻撃の防御・軽減機能は提供しません。検出は可能でも、実際の攻撃トラフィックをブロックする機能はありません。
B. AWS Shieldを有効にしてAmazon Route 53を割り当てる。
不正解 AWS ShieldはDDoS攻撃の防御に特化したサービスですが、2つの問題があります。まず、問題文で「DNSにはサードパーティサービスが使用されており、変更できません。」と明記されており、Route 53は使用されていません。次に、大規模DDoS攻撃の防御にはShield Advancedが必要で、標準のShieldでは高度で大規模な攻撃に対する十分な保護を提供できません。
C. EC2インスタンスでAmazon Inspectorを有効にする。
不正解 Amazon InspectorはEC2インスタンスとアプリケーションの脆弱性評価サービスです。ソフトウェアの脆弱性、意図しないネットワークアクセス、セキュリティのベストプラクティス違反を特定します。ランタイムでの動作分析により内部セキュリティを強化しますが、外部からのDDoS攻撃の検出や防御には対応していません。
D. AWS Shield Advancedを有効にしてELBを割り当てる。
正解 AWS Shield AdvancedはDDoS攻撃の検出と防御に特化した高度なサービスで、大規模で複雑なDDoS攻撃に対する強化された保護を提供します。ELBとの統合により、ネットワークレベルとアプリケーションレベルの両方で攻撃を軽減できます。AWS DDoS Response Team(DRT)へのアクセス、リアルタイム攻撃通知、詳細な攻撃診断など、包括的なDDoS対策機能を提供します。
全体的な説明
問われている要件
- パブリック向けWebアプリケーションの大規模DDoS攻撃対策
- ELB背後のEC2インスタンス群の保護
- サードパーティDNSサービス環境での実装
- 検出機能と防御機能の両方の提供
- スケーラブルで効果的なDDoS軽減策
前提知識
DDoS防御サービスの特徴について
- AWS Shield StandardはすべてのAWSアカウントに無料で含まれており、最も一般的なネットワークおよびトランスポート層のDDoS攻撃に対する基本的な保護を提供します。CloudFront、Route 53、Elastic Load Balancingなどのサービスで自動的に有効になりますが、高度な攻撃や大規模攻撃には限界があります。
- AWS Shield Advancedは月額料金制の高度なDDoS保護サービスで、より大規模で複雑な攻撃に対応します。EC2、ELB、CloudFront、Route 53、Global Acceleratorを保護対象とし、リアルタイム攻撃通知、AWS WAFとの統合、DDoS Response Team(DRT)によるサポートを提供します。攻撃によるスケーリングコストの保護も含まれます。
セキュリティ監視サービスの特徴について
- Amazon GuardDutyは機械学習、異常検出、統合された脅威インテリジェンスを使用してAWSアカウントとワークロードを保護する脅威検出サービスです。VPCフローログ、DNSログ、CloudTrailイベントログを分析して悪意のあるアクティビティを検出しますが、攻撃の軽減機能は提供しません。
- Amazon InspectorはEC2インスタンスとコンテナイメージの脆弱性管理サービスで、ソフトウェアの脆弱性と意図しないネットワークアクセスを継続的にスキャンします。内部セキュリティの強化には有効ですが、外部からの攻撃の防御には対応していません。
解くための考え方
この問題の鍵は「大規模DDoS攻撃」というキーワードと、システム構成の理解です。まず、大規模DDoS攻撃の対策には、AWSの中でAWS Shield Advancedが最も特化したサービスです。次に、問題文を分析すると、トラフィックはELBを通じてEC2インスタンスに到達するため、ELBレベルでの保護が最も効果的です。
また、「DNSにはサードパーティサービスが使用されており、変更できません。」という記述により、Route 53は環境に含まれていないため、技術的に適用できません。
GuardDutyとInspectorは検出には有効ですが、実際の攻撃トラフィックの軽減・ブロック機能は提供しないため、DDoS攻撃の防御という要件を満たしません。
したがって、Shield AdvancedとELBの組み合わせが唯一の適切な解決策となります。
アーキテクチャ図
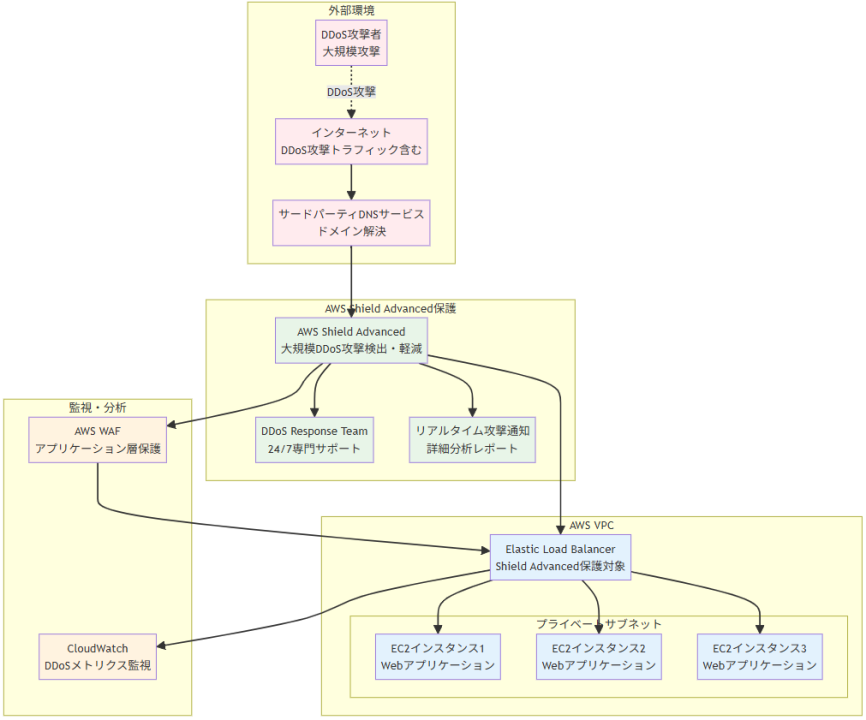
アーキテクチャ図の解説
Shield AdvancedによるELBレベルでのDDoS防御
外部からのトラフィックはサードパーティDNSサービスを経由してAWS環境に到達し、AWS Shield AdvancedがELBレベルで大規模DDoS攻撃を検出・軽減します。Shield Advancedは機械学習ベースの検出エンジンにより、正常なトラフィックと攻撃トラフィックを区別し、攻撃トラフィックを自動的にフィルタリングします。ELBの背後にある複数のEC2インスタンスは、攻撃が軽減された正常なトラフィックのみを受信し、安定したサービス提供を維持できます。リアルタイム攻撃通知により、セキュリティチームは攻撃状況を即座に把握できます。
包括的なDDoS対策と24/7サポート体制
AWS Shield AdvancedはDDoS Response Team(DRT)による24/7の専門サポートを提供し、攻撃発生時には即座に対応を開始します。CloudWatchとの連携により、DDoS攻撃のメトリクスを継続的に監視し、攻撃パターンの分析や対策効果の測定が可能です。また、AWS WAFとの統合により、ネットワーク層の攻撃だけでなく、アプリケーション層の攻撃も防御でき、多層防御アーキテクチャを実現します。攻撃によるスケーリングコストの保護機能により、DDoS攻撃による予期しない課金増加からも保護されます。
他のソリューションとの比較
他のセキュリティサービスと比較すると、Shield Advancedの優位性は明確です。
GuardDutyは攻撃の検出には優れていますが、実際の攻撃トラフィックをブロックする機能は提供しません。
Inspectorは内部の脆弱性評価には有効ですが、外部からのDDoS攻撃とは無関係です。
Shield Standardは基本的な保護は提供しますが、大規模攻撃や高度な攻撃には対応できません。また、問題文でサードパーティDNSサービスが使用されているため、Route 53ベースの解決策は適用できません。
Shield AdvancedとELBの組み合わせのみが、大規模DDoS攻撃の検出と防御の両方を効果的に実現できます。
実装の考慮事項
実装時には、Shield Advancedの有効化とELBへの適用、適切なCloudWatchアラームの設定、DRTとの連携手順の確立が必要です。コスト面では、Shield Advancedは月額$3,000の固定費用に加えて、データ転送量に基づく課金が発生するため、予算計画が重要です。
セキュリティ面では、AWS WAFルールの最適化、アクセスログの分析、定期的な攻撃シミュレーションによる対策効果の検証が推奨されます。また、攻撃発生時の対応手順の文書化、関係者への通知体制の整備、復旧手順の事前準備も重要な考慮事項です。DRTとの効果的な連携のため、攻撃時の連絡先や権限設定も事前に整備する必要があります。
参考資料
問題文:
ある企業がメッセージを取り込むアプリケーションを運用しています。数十の他のアプリケーションとマイクロサービスがこれらのメッセージを迅速に消費する必要があります。メッセージ数は大幅に変動し、時には突然毎秒100,000メッセージまで増加します。
企業はソリューションを分離(デカップリング)し、スケーラビリティを向上させたいと考えています。
これらの要件を満たすソリューションはどれでしょうか。
選択肢:
A. Amazon Kinesis Data Analyticsにメッセージを保存し、コンシューマーアプリケーションがメッセージを読み取って処理するように設定する
B. Auto Scalingグループ内のAmazon EC2インスタンスに取り込みアプリケーションをデプロイし、CPUメトリクスに基づいてEC2インスタンス数をスケールする
C. 単一シャードでAmazon Kinesis Data Streamsにメッセージを書き込み、AWS Lambda関数でメッセージを前処理してAmazon DynamoDBに保存し、コンシューマーアプリケーションがDynamoDBから読み取って処理するように設定する
D. 複数のAmazon Simple Queue Service(Amazon SQS)サブスクリプションを持つAmazon Simple Notification Service(Amazon SNS)トピックにメッセージをパブリッシュし、コンシューマーアプリケーションがキューからメッセージを処理するように設定する
正解:D
A. Amazon Kinesis Data Analyticsにメッセージを保存し、コンシューマーアプリケーションがメッセージを読み取って処理するように設定する
不正解 Kinesis Data Analyticsはリアルタイムデータ分析サービスであり、メッセージのデカップリングや配信には適していません。このサービスはApache Flinkを使用してストリーミングデータを変換・分析することが主目的です。複数のコンシューマーアプリケーションへのメッセージ配信機能は提供されておらず、要件である「数十のアプリケーションとマイクロサービスがメッセージを消費する」という部分を満たすことができません。
B. Auto Scalingグループ内のAmazon EC2インスタンスに取り込みアプリケーションをデプロイし、CPUメトリクスに基づいてEC2インスタンス数をスケールする
不正解 EC2 Auto ScalingはCPUメトリクスに基づいてスケールしますが、突然のメッセージ量増加に対する反応速度が不十分です。インスタンスの起動には時間がかかり、毎秒100,000メッセージという急激な負荷変動に対応できません。また、このアプローチではアプリケーション間のデカップリングが実現されず、取り込みアプリケーションとコンシューマーアプリケーションが直接結合したままになります。運用コストも高くなる傾向があります。
C. 単一シャードでAmazon Kinesis Data Streamsにメッセージを書き込み、AWS Lambda関数でメッセージを前処理してAmazon DynamoDBに保存し、コンシューマーアプリケーションがDynamoDBから読み取って処理するように設定する
不正解 単一シャードのKinesis Data Streamsでは毎秒1,000レコードまでしか処理できず、毎秒100,000メッセージという要件を満たすには大幅にシャード数を増やす必要があります。さらに、DynamoDBからメッセージを読み取る方式では、コンシューマーアプリケーションが継続的にポーリングする必要があり、効率的ではありません。この構成は複雑でコストも高く、真のデカップリングが実現されていません。
D. 複数のAmazon Simple Queue Service(Amazon SQS)サブスクリプションを持つAmazon Simple Notification Service(Amazon SNS)トピックにメッセージをパブリッシュし、コンシューマーアプリケーションがキューからメッセージを処理するように設定する
正解 SNSとSQSを組み合わせたファンアウトパターンは、メッセージの分離と拡張性の両方を実現する最適なソリューションです。SNSトピックに一度パブリッシュされたメッセージは、複数のSQSキューに自動的に配信され、各コンシューマーアプリケーションが独立してメッセージを処理できます。標準SQSキューは実質的に無制限のスループットを提供し、複数キューの並列処理により毎秒100,000メッセージの要件も満たせます。
全体的な説明
問われている要件
- メッセージを取り込むアプリケーションと数十のコンシューマーアプリケーション間のデカップリング実現
- 毎秒100,000メッセージまで対応可能な高いスケーラビリティの確保
- 急激なメッセージ量変動への対応能力
- 複数のマイクロサービスが同一メッセージを並列処理できる仕組みの構築
- コスト効率性と運用の簡素化
前提知識
メッセージングサービスの特徴
- Amazon SNS:フルマネージドなパブリッシュ・サブスクライブメッセージングサービスで、一つのメッセージを複数の宛先に同時配信可能。標準トピックでは実質的に無制限のスループットを提供し、メッセージフィルタリング機能も備えています。FIFOトピックは毎秒300メッセージまでの制限があります。
- Amazon SQS:フルマネージドなメッセージキューサービスで、標準キューは実質無制限のスループット、FIFOキューは毎秒3,000メッセージ(バッチ使用時)まで処理可能。デッドレターキューや可視性タイムアウトなど、信頼性の高いメッセージ処理機能を提供します。
ストリーミングサービスについて
- Amazon Kinesis Data Streams:リアルタイムデータストリーミングサービスで、シャードあたり毎秒1,000レコードまで処理可能。複数のコンシューマーが同一データを並列処理でき、データは最大365日間保持されます。スケーリングには事前のシャード数調整が必要です。
- Amazon Kinesis Data Analytics:Apache Flinkを使用したリアルタイムデータ分析サービスで、SQLやJavaでストリーミングデータを処理できます。分析が主目的で、メッセージの配信には適していません。
コンピューティングサービスの特徴
- Amazon EC2 Auto Scaling:需要に応じてEC2インスタンス数を自動調整するサービスで、CPUやメモリなどのメトリクスに基づいてスケールします。インスタンス起動には通常30秒から数分かかり、急激な負荷変動への対応には限界があります。
解くための考え方
この問題の核心は「デカップリング」と「スケーラビリティ」の両立です。まず、デカップリングの要件を満たすには、メッセージの送信者と受信者が直接接続されない仕組みが必要です。次に、毎秒100,000メッセージという高いスループット要件と急激な負荷変動への対応を考慮する必要があります。選択肢を検討すると、Kinesis Data Analyticsは分析サービスであり配信には不適切、EC2 Auto Scalingは起動時間の問題でリアルタイム性に欠ける、単一シャードのKinesis Data Streamsは容量不足という問題があります。一方、SNS + SQSの組み合わせは、SNSによる1対多のメッセージ配信とSQSによる非同期処理により、完全なデカップリングを実現します。さらに、複数のSQSキューを並列運用することで必要なスループットを確保でき、各コンシューマーアプリケーションが独立してスケールできる理想的なアーキテクチャとなります。
アーキテクチャ図
SNS-SQSファンアウトアーキテクチャ
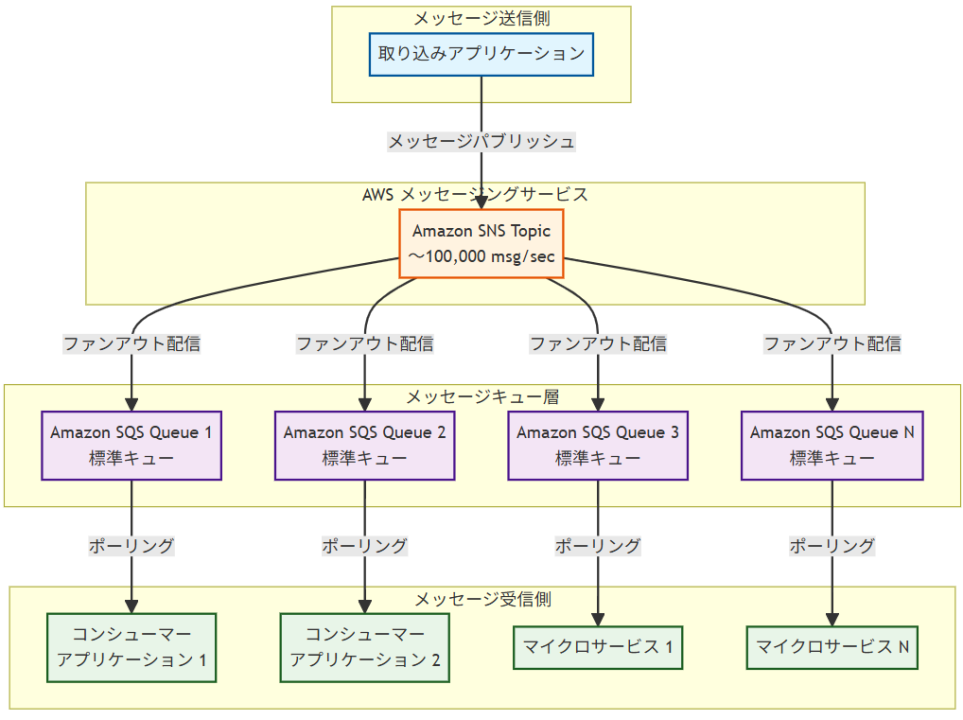
アーキテクチャ図の解説
メッセージフローとファンアウト処理 図に示されているように、取り込みアプリケーションがSNSトピックに一度メッセージをパブリッシュすると、そのメッセージは自動的に複数のSQSキューに同時配信されます。これがファンアウトパターンの核心で、一つのメッセージが数十のコンシューマーアプリケーションやマイクロサービスに確実に届けられます。SNSは毎秒100,000メッセージの要件に対応できる十分なスループットを提供し、メッセージの重複や欠損を防ぐ信頼性の高い配信を保証します。
デカップリングとスケーラビリティの実現 このアーキテクチャでは、取り込みアプリケーションはコンシューマーアプリケーションの存在や状態を意識する必要がありません。各コンシューマーアプリケーションは専用のSQSキューから独立してメッセージを処理でき、処理速度に応じてポーリング頻度を調整できます。新しいコンシューマーアプリケーションの追加は単純にSQSキューの追加とSNSサブスクリプションの設定のみで実現でき、既存システムへの影響を最小限に抑えられます。
高可用性と障害対応 SQSキューはメッセージの一時的な保存機能を提供し、コンシューマーアプリケーションが一時的に利用不可能になってもメッセージが失われることはありません。デッドレターキューの設定により、処理に失敗したメッセージを別途管理でき、システム全体の可用性を向上させます。また、複数のアベイラビリティゾーンにまたがるAWSの冗長化により、高い可用性が確保されています。
他のソリューションとの比較
Kinesis Data Streamsを使用したストリーミング処理と比較すると、SNS + SQSソリューションは運用が簡素でコスト効率に優れています。Kinesisはリアルタイム分析には適していますが、単純なメッセージ配信においては過剰な機能となり、シャード管理の複雑さとコストが増大します。EC2ベースのソリューションと比べて、完全マネージドサービスであるため運用負荷が大幅に軽減され、自動スケーリングにより予期しない負荷変動にも柔軟に対応できます。
実装の考慮事項
実装時には、SQSキューの可視性タイムアウトとメッセージ保持期間を適切に設定し、コンシューマーアプリケーションの処理時間に合わせて調整する必要があります。また、メッセージの順序性が重要な場合はFIFO SQSキューの使用を検討しますが、スループットが制限されるため複数キューでの並列処理が必要です。デッドレターキューの設定により障害時のメッセージ損失を防ぎ、CloudWatchメトリクスを活用した監視体制の構築も重要な要素となります。
参考資料
- Amazon SNS とは – Amazon Simple Notification Service
- Amazon SQS とは – Amazon Simple Queue Service
- SNS から SQS へのファンアウト – Amazon Simple Notification Service
- Amazon Kinesis Data Analytics とは – Amazon Kinesis Data Analytics
- Amazon Kinesis Data Streams とは – Amazon Kinesis Data Streams
- Amazon EC2 Auto Scaling とは – Amazon EC2 Auto Scaling
問題文:
企業はAmazon S3 Standardストレージを使用してバックアップファイルを保存しています。
ファイルは1ヶ月間は頻繁にアクセスされます。しかし、1ヶ月後はファイルにアクセスされません。企業はファイルを無期限に保持する必要があります。
これらの要件を最もコスト効率的に満たすストレージソリューションはどれですか。
選択肢:
A. オブジェクトを自動的に移行するためにS3 Intelligent-Tieringを設定します。
B. 1ヶ月後にオブジェクトをS3 StandardからS3 Glacier Deep Archiveに移行するS3 Lifecycle設定を作成します。
C. 1ヶ月後にオブジェクトをS3 StandardからS3 Standard-Infrequent Access(S3 Standard-IA)に移行するS3 Lifecycle設定を作成します。
D. 1ヶ月後にオブジェクトをS3 StandardからS3 One Zone-Infrequent Access(S3 One Zone-IA)に移行するS3 Lifecycle設定を作成します。
正解:B
A. オブジェクトを自動的に移行するためにS3 Intelligent-Tieringを設定します。
不正解 S3 Intelligent-Tieringは予測不可能なアクセスパターンに適していますが、この場合のアクセスパターンは明確で予測可能です(1ヶ月は頻繁、その後はアクセスなし)。また、Intelligent-Tieringは長期アーカイブストレージほど安価ではなく、監視料金も発生するため、明確なアクセスパターンがある場合は手動でのLifecycle設定の方がコスト効率的です。
B. 1ヶ月後にオブジェクトをS3 StandardからS3 Glacier Deep Archiveに移行するS3 Lifecycle設定を作成します。
正解 S3 Glacier Deep ArchiveはAmazon S3で最も安価なストレージクラスで、年に1-2回程度しかアクセスされない長期保存データに最適化されています。1ヶ月後にアクセスされなくなるバックアップファイルを無期限保存する要件に完全に適合し、大幅なコスト削減を実現できます。Lifecycle設定により自動移行が可能で、運用オーバーヘッドも最小限です。
C. 1ヶ月後にオブジェクトをS3 StandardからS3 Standard-Infrequent Access(S3 Standard-IA)に移行するS3 Lifecycle設定を作成します。
不正解 S3 Standard-IAは稀にアクセスされるデータには適していますが、Glacier Deep Archiveと比較するとストレージコストが高くなります。1ヶ月後に全くアクセスされないファイルに対しては、より安価なアーカイブストレージの方が適切です。また、取得料金も発生するため、万が一のアクセス時のコストも考慮する必要があります。
D. 1ヶ月後にオブジェクトをS3 StandardからS3 One Zone-Infrequent Access(S3 One Zone-IA)に移行するS3 Lifecycle設定を作成します。
不正解 S3 One Zone-IAは単一のAvailability Zoneにのみデータを保存するため、AZ障害時にデータが失われるリスクがあります。バックアップファイルという重要なデータに対してはリスクが高すぎます。また、Glacier Deep Archiveほど安価ではなく、長期保存のコスト効率性も劣ります。
全体的な説明
問われている要件
- 1ヶ月間の頻繁なアクセス期間への対応
- 1ヶ月後の完全なアクセス停止パターン
- 無期限の長期保存要件
- 最もコスト効率的なストレージソリューション
- バックアップファイルの確実な保護
前提知識
S3ストレージクラスのコスト比較について
- S3 Standard
- 頻繁アクセス用の高性能ストレージ
- 最も高いストレージ料金だが取得料金なし
- 1ヶ月間の頻繁アクセス期間に最適
- S3 Glacier Deep Archive
- 最も安価なストレージクラス(Standard比約95%削減)
- 年に1-2回程度のアクセス頻度を想定
- 取得時間は5-12時間
- 最小保存期間180日(削除時の課金条件)
- S3 Standard-IA
- 稀なアクセス用、Standardより約50%安価
- 取得料金が発生(GBあたり$0.01)
- 最小保存期間30日
- S3 One Zone-IA
- 単一AZ構成、Standard-IAより約20%安価
- 可用性とデータ保護が大幅に低下
- バックアップ用途には不適切
S3 Lifecycleポリシーの設定について
- 自動移行ルール
- オブジェクト作成日を基準とした自動移行
- 複数ストレージクラス間の段階的移行
- プレフィックスやタグベースでの条件指定
- 移行パス制限
- Standard → Standard-IA → Glacier → Glacier Deep Archive
- 直接的な移行パス:Standard → Glacier Deep Archive
- 逆方向の自動移行は不可
バックアップデータの特性について
- アクセスパターンの予測可能性
- 作成直後の検証・復旧テスト期間
- 長期間のアーカイブ保存期間
- 災害時やコンプライアンス要件での稀な取得
- コスト最適化の要点
- ストレージ料金の大幅削減(長期保存の主要コスト)
- 取得料金の考慮(緊急時アクセスのコスト)
- 運用管理コストの最小化
解くための考え方
この問題は明確で予測可能なアクセスパターン(1ヶ月は頻繁、その後はアクセスなし)と無期限保存要件を持つバックアップデータの最適化問題です。
キーポイントは「最もコスト効率的」という条件です。1ヶ月後に全くアクセスされないファイルを無期限保存する場合、S3 Glacier Deep Archiveが圧倒的に最も安価な選択肢となります。年間ストレージコストをS3 Standardと比較すると約95%の削減が可能で、数年間の保存期間を考慮すると大幅なコスト削減効果が得られます。
Intelligent-Tieringは予測不可能なパターンに有効ですが、明確なパターンがある場合は手動Lifecycle設定の方が効率的です。Standard-IAやOne Zone-IAは中間的な選択肢ですが、長期アーカイブには不十分で、特にOne Zone-IAはバックアップデータの可用性要件を満たしません。Lifecycle設定により1ヶ月後の自動移行が可能で、運用負荷なしに最大のコスト効率を実現できます。
アーキテクチャ図
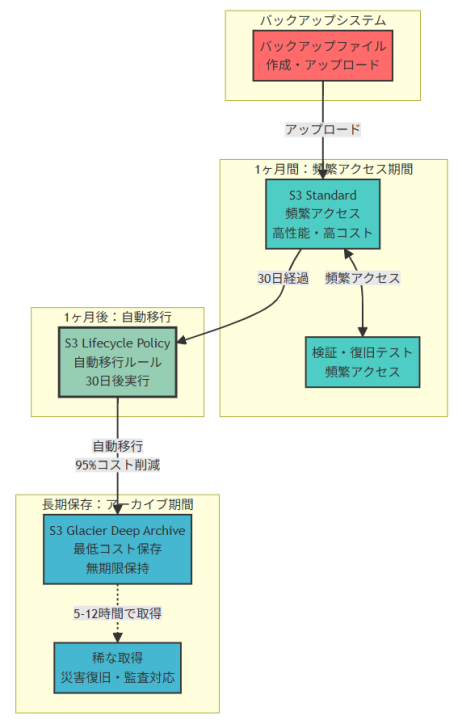
アーキテクチャ図の解説
初期アクセス期間とS3 Standard活用
バックアップファイルの作成直後から1ヶ月間は、S3 Standardストレージクラスで高性能なアクセスを提供します。この期間中は検証作業、復旧テスト、データ整合性確認などが頻繁に実行されるため、低レイテンシーと高スループットが重要です。S3 Standardは取得料金が発生せず、頻繁なアクセスパターンに最適化されています。
自動移行システムとコスト最適化
S3 Lifecycle Policyにより、オブジェクト作成から30日後に自動的にS3 Glacier Deep Archiveへの移行が実行されます。この移行により、ストレージコストを約95%削減できる大幅なコスト最適化が実現されます。手動管理は一切不要で、運用オーバーヘッドなしに継続的なコスト削減効果を得られます。
長期アーカイブ保存と稀なアクセス対応
S3 Glacier Deep Archiveでの無期限保存により、最低コストでの長期データ保護を実現します。災害復旧やコンプライアンス監査などの稀なアクセス要件に対しては、5-12時間の取得時間で対応可能です。バックアップデータの性質上、この取得時間は実用的な範囲内であり、コスト削減効果を大幅に上回る価値を提供します。
他のソリューションとの比較
Intelligent-Tieringは予測不可能なアクセスパターンには有効ですが、明確なパターンがある場合は監視料金が無駄になり、最安価なGlacier Deep Archiveへの移行も行いません。
Standard-IAは中間的な選択肢ですが、長期保存コストがGlacier Deep Archiveの約4倍高く、取得料金も発生します。
One Zone-IAは可用性リスクが高く、バックアップデータには不適切です。
数年間の保存期間を考慮すると、Glacier Deep Archiveによる年間95%のコスト削減効果は圧倒的です。
実装の考慮事項
Lifecycle設定では、オブジェクト作成日を基準とした30日後の自動移行ルールを設定します。Glacier Deep Archiveには180日の最小保存期間がありますが、無期限保存要件により問題となりません。
緊急時のデータ取得には5-12時間の復元時間を考慮した運用手順を準備し、より高速な取得が必要な場合は一部データのStandard-IAでの保存も検討できます。コスト監視では、CloudWatchメトリクスでストレージ使用量を追跡し、移行による削減効果を定量化します。また、データ取得時の料金も事前に把握し、災害復旧計画に組み込む必要があります。
参考資料
問題文:
ある企業が毎時間数百個の.csvファイルをAmazon S3バケットに配置するアプリケーションを持っています。ファイルのサイズは1GBです。
ファイルがアップロードされるたびに、企業はファイルをApache Parquet形式に変換し、出力ファイルをS3バケットに配置する必要があります。
最小限の運用オーバーヘッドでこれらの要件を満たすソリューションはどれですか。
選択肢:
A. AWS Lambda関数を作成して.csvファイルをダウンロードし、ファイルをParquet形式に変換して、出力ファイルをS3バケットに配置します。各S3 PUTイベントに対してLambda関数を呼び出します。
B. アプリケーションが.csvファイルを配置するS3バケット用にAWS GlueテーブルとAWS Glueクローラーを作成します。AWS Lambda関数をスケジュールして定期的にAmazon AthenaでAWS Glueテーブルをクエリし、クエリ結果をParquet形式に変換してS3バケットに出力ファイルを配置します。
C. AWS Glue抽出、変換、ロード(ETL)ジョブを作成して.csvファイルをParquet形式に変換し、出力ファイルをS3バケットに配置します。各S3 PUTイベントに対してETLジョブを呼び出すAWS Lambda関数を作成します。
D. Apache SparkジョブでCSVファイルを読み取り、ファイルをParquet形式に変換して、出力ファイルをS3バケットに配置します。各S3 PUTイベントに対してSparkジョブを呼び出すAWS Lambda関数を作成します。
正解:C
A. AWS Lambda関数を作成して.csvファイルをダウンロードし、ファイルをParquet形式に変換して、出力ファイルをS3バケットに配置します。各S3 PUTイベントに対してLambda関数を呼び出します。
不正解 1GBのファイルサイズは、Lambda関数での処理に複数の制限があります。Lambda の最大実行時間は15分で、1GBのCSVからParquet変換は時間がかかる可能性があります。また、カスタムコードの作成・保守・テストが必要で運用オーバーヘッドが増加します。メモリ使用量とネットワークI/Oの制約も考慮が必要です。
B. アプリケーションが.csvファイルを配置するS3バケット用にAWS GlueテーブルとAWS Glueクローラーを作成します。AWS Lambda関数をスケジュールして定期的にAmazon AthenaでAWS Glueテーブルをクエリし、クエリ結果をParquet形式に変換してS3バケットに出力ファイルを配置します。
不正解 複数のAWSサービス(Glue テーブル、クローラー、Athena、Lambda)を組み合わせた複雑なアーキテクチャで、各コンポーネントの設定と調整が必要です。定期的なスケジューリングによりリアルタイム処理ができず、効率性も劣ります。運用と監視の複雑性も高くなります。
C. AWS Glue抽出、変換、ロード(ETL)ジョブを作成して.csvファイルをParquet形式に変換し、出力ファイルをS3バケットに配置します。各S3 PUTイベントに対してETLジョブを呼び出すAWS Lambda関数を作成します。
正解 AWS Glue ETLは、大容量データの変換処理に最適化された完全マネージドサービスです。CSVからParquetへの変換は標準機能として提供されており、カスタムコード開発が最小限で済みます。インフラ管理、スケーリング、監視がAWSにより自動化され、運用オーバーヘッドが最小になります。
D. Apache SparkジョブでCSVファイルを読み取り、ファイルをParquet形式に変換して、出力ファイルをS3バケットに配置します。各S3 PUTイベントに対してSparkジョブを呼び出すAWS Lambda関数を作成します。
不正解 Apache Sparkクラスターの管理が必要となり、運用オーバーヘッドが大幅に増加します。Sparkジョブの設定、監視、スケーリング、障害対応など、複雑な運用作業が発生します。Lambda との組み合わせにより、アーキテクチャの複雑性も増します。
全体的な説明
問われている要件
- 大容量(1GB)CSVファイルの効率的なParquet変換
- 毎時間数百ファイルの高頻度処理対応
- S3イベント駆動型のリアルタイム処理
- 最小限の運用オーバーヘッドでの実装
- スケーラブルで信頼性の高いデータ変換パイプライン
前提知識
AWS Glue ETLの特徴と利点について
- AWS Glue ETLは、Apache Sparkエンジンをベースとした完全マネージドETLサービスで、大容量データの処理に最適化されています
- CSVからParquetへの変換は組み込み機能として提供されており、コード生成機能により最小限の開発作業で実装できます
- 自動スケーリング機能により、処理負荷に応じてリソースが動的に調整され、コスト効率と性能を両立できます
Lambdaの制限事項と適用範囲について
- AWS Lambdaの最大実行時間は15分、最大メモリは10GBですが、1GBファイルの変換処理は実行時間制限に抵触する可能性があります
- Lambdaは軽量で短時間の処理に最適化されており、大容量データの変換処理には技術的・経済的制約があります
- ネットワークI/O制約により、大きなファイルのダウンロード・アップロードに時間がかかる場合があります
データ変換における運用オーバーヘッドの要因について
- カスタムコードの開発、テスト、デバッグ、保守は継続的な運用作業を必要とします
- インフラストラクチャの管理(サーバー、クラスター、ネットワーク)は専門知識と監視体制を要求します
- 複数サービスの組み合わせは、統合テスト、依存関係管理、障害対応の複雑性を増加させます
解くための考え方
この問題の核心は「最小限の運用オーバーヘッド」という要件です。
まず、1GBという大容量ファイルサイズから、軽量処理向けのLambda単体での実装は技術的制約があることがわかります。
次に、毎時間数百ファイルという高頻度処理から、手動管理が必要なソリューション(Sparkクラスター管理など)は運用負荷が高すぎることが明確です。
「運用オーバーヘッド最小」という要件から、完全マネージドサービスの活用が重要になります。AWS Glue ETLは、データ変換に特化した完全マネージドサービスで、この要件に最適です。
複数サービスの複雑な組み合わせよりも、シンプルで目的に特化したソリューションが運用面で優れています。
アーキテクチャ図
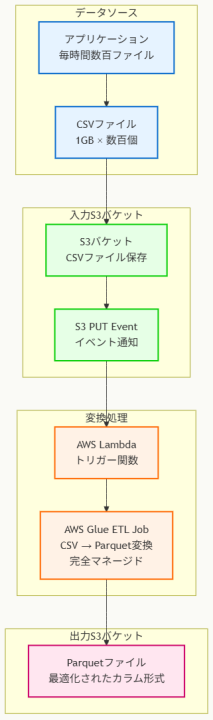
アーキテクチャ図の解説
イベント駆動型リアルタイム処理パイプライン
このアーキテクチャでは、アプリケーションが1GBのCSVファイルを入力S3バケットにアップロードすると、S3 PUTイベントが自動的にLambda関数をトリガーします。Lambda関数は軽量なトリガー機能のみを担当し、実際の重い変換処理はAWS Glue ETLジョブに委譲されます。
この分離により、Lambda の実行時間制限を回避しながら、リアルタイムでの処理開始を実現しています。
AWS Glue ETLによる完全マネージド変換処理
AWS Glue ETLジョブは、Apache Sparkエンジンを基盤とした完全マネージドな変換処理を実行します。CSVからParquetへの変換は標準機能として提供されており、カスタムコードの開発が最小限で済みます。
自動スケーリング機能により、毎時間数百ファイルという高頻度処理にも対応でき、処理負荷に応じてリソースが動的に調整されます。インフラ管理、パッチ適用、監視がAWSにより自動化されています。
運用オーバーヘッド最小化の仕組み
CloudWatch監視、実行ログ記録、エラーハンドリング、自動リトライなどの運用機能がすべて自動化されており、手動による運用作業が大幅削減されます。Parquetファイルは最適化されたカラム形式で出力S3バケットに保存され、後続の分析処理で高いパフォーマンスを実現します。
他のソリューションとの比較
Lambda単体での実装では、1GBファイルの処理時間制限、メモリ制約、ネットワークI/O制約により技術的困難があり、カスタムコード開発の運用負荷も高くなります。
Apache Sparkクラスターの自己管理では、クラスター設定、監視、スケーリング、障害対応、セキュリティパッチ適用などの継続的な運用作業が必要になります。
複数サービス組み合わせによる複雑なアーキテクチャでは、各コンポーネント間の依存関係管理、統合テスト、障害分析が複雑になり、運用オーバーヘッドが増加します。
実装の考慮事項
実装時には、AWS Glue ETLジョブの設定で、CSVファイルの構造に適したスキーマ定義と、Parquet出力の最適化パラメーター(圧縮形式、パーティション設定など)を適切に設定する必要があります。
また、S3イベント通知の設定では、特定のプレフィックスやサフィックスによるフィルタリングにより、関連ファイルのみがETLジョブをトリガーするよう制御できます。
コスト最適化の観点では、Glue ETLジョブのワーカータイプ(Standard、G.1X、G.2X)と最大ワーカー数を、ファイルサイズと処理時間要件に基づいて適切に設定することが重要です。
運用面では、CloudWatchダッシュボードでETLジョブの実行状況、成功率、処理時間を継続監視し、必要に応じてアラート設定を行うことが推奨されます。
参考資料
問題文:
ソリューションアーキテクトが2つのIAMポリシーを作成しました:Policy1とPolicy2です。
Policy1:

Policy2:
両方のポリシーがIAMグループに添付されています。クラウドエンジニアがこのIAMグループにIAMユーザーとして追加されました。このクラウドエンジニアが実行できるアクションはどれですか?
選択肢:
A. IAMユーザーの削除
B. ディレクトリの削除
C. Amazon CloudWatch Logsからのログ削除
D. Amazon EC2インスタンスの削除


正解:D
A. IAMユーザーの削除
不正解 Policy1では「iam:Get*」と「iam:List*」のアクションのみが許可されており、IAMユーザーの削除に必要な「iam:DeleteUser」権限は含まれていません。IAMに関する読み取り専用権限(Get、List)のみが付与されているため、IAMユーザーの作成、変更、削除などの変更操作は実行できません。IAMリソースの情報取得と一覧表示のみが可能です。
B. ディレクトリの削除
不正解 Policy1では「ds:」によりDirectory Serviceの全操作が許可されていますが、Policy2で「ds:Delete」が明示的に拒否されています。IAMの権限評価では明示的拒否(Deny)が許可(Allow)よりも優先されるため、ディレクトリの削除操作は実行できません。Directory Serviceの他の操作(作成、変更、取得など)は可能ですが、削除系の操作は全て拒否されます。
C. Amazon CloudWatch Logsからのログ削除
不正解 Policy1では「logs:Get*」と「logs:Describe*」のアクションのみが許可されており、CloudWatch Logsからのログ削除に必要な「logs:DeleteLogGroup」や「logs:DeleteLogStream」権限は含まれていません。CloudWatch Logsに関する読み取り専用権限のみが付与されているため、ログの取得と説明情報の参照のみが可能で、削除操作は実行できません。
D. Amazon EC2インスタンスの削除
正解 Policy1で「ec2:*」が指定されており、Amazon EC2サービスのすべての操作が許可されています。これにはEC2インスタンスの作成、開始、停止、削除、設定変更などすべてが含まれます。Policy2にはEC2に関する制限がないため、EC2インスタンスの削除操作は問題なく実行できます。フルアクセス権限により、EC2リソースの完全な管理が可能です。
全体的な説明
問われている要件
- 複数のIAMポリシーが適用されたユーザーの権限評価
- 明示的許可と明示的拒否の優先順位理解
- ワイルドカード権限と具体的権限の関係性
- IAMの権限評価ロジックの実践的適用
- 各AWSサービスに対する権限レベルの把握
前提知識
IAM権限評価の基本原理について
- デフォルト拒否:すべての操作は明示的に許可されない限り拒否される。初期状態では何も実行できない
- 明示的許可:Allowステートメントにより特定のアクションが許可される。Resourceとの組み合わせで対象範囲を限定可能
- 明示的拒否:Denyステートメントによる拒否は最も高い優先度を持つ。いかなる許可よりも優先され、オーバーライド不可
- 権限の継承:ユーザー、グループ、ロールの権限が統合的に評価される
ポリシーの評価順序について
- IAMは以下の順序で権限を評価:1) 明示的拒否の確認、2) 明示的許可の確認、3) デフォルト拒否の適用
- 複数ポリシーの統合:同一ユーザーに複数のポリシーが適用される場合、すべてのポリシーが統合評価される
- 最小権限の原則:必要最小限の権限のみを付与し、過度な権限付与を避ける
アクション指定方法の特徴について
- ワイルドカード():サービス内のすべての操作を包含。「ec2:」はEC2のすべてのアクションを許可
- 部分ワイルドカード:「iam:Get*」のように特定パターンのアクションをグループ化
- 具体的アクション:「ec2:TerminateInstances」のように特定の操作を個別指定
解くための考え方
この問題はIAM権限評価の核心的な理解を求めています。まず重要なのは「明示的拒否が最優先」という原則の理解です。Policy1で広範囲の権限が許可されていても、Policy2で明示的に拒否されているアクションは実行できません。
次に、各選択肢について具体的な権限マッピングを行う必要があります。IAMの場合は読み取り権限のみ、CloudWatch Logsも読み取り権限のみが付与されており、削除操作に必要な権限が不足しています。
Directory Serviceについては、Policy1で「ds:」により全権限が許可されていますが、Policy2で「ds:Delete」が明示的に拒否されているため、削除操作は実行できません。これは明示的拒否の優先原則を示す典型例です。
EC2については、Policy1で「ec2:*」により完全な権限が付与されており、Policy2には制限がないため、すべての操作(削除を含む)が実行可能です。
この分析により、選択肢の中でEC2インスタンスの削除のみが実行可能であることがわかります。
他のソリューションとの比較
権限管理の別のアプローチとして、個別ポリシーの直接アタッチメントがありますが、これは管理の複雑性を増加させます。グループベースの権限管理により、同じ役割のユーザーに一貫した権限を効率的に付与できます。
また、すべての権限を単一ポリシーに統合する方法もありますが、権限の粒度が粗くなり、最小権限の原則から逸脱する可能性があります。許可と拒否を分離したポリシー設計により、柔軟で安全な権限管理が実現できます。
Resource-based policyとの組み合わせも可能ですが、この問題ではIdentity-based policyのみで要件を満たしており、シンプルで理解しやすい構成となっています。
実装の考慮事項
実装時は権限の最小化原則に従い、必要最小限のアクションのみを許可すべきです。ワイルドカード(*)の使用は便利ですが、過度な権限付与につながる可能性があるため、具体的なアクションの列挙も検討する必要があります。
明示的拒否の使用では、将来の要件変更に対する影響を慎重に評価すべきです。過度に広範囲な拒否設定は、正当な業務要件を阻害する可能性があります。
定期的な権限レビューとアクセスログの監視により、実際の権限使用状況を把握し、不要な権限の削除や不足している権限の追加を適切に行うことが重要です。また、IAM Access Analyzerを活用した権限の可視化と最適化も推奨されます。
参考資料
- AWS Identity and Access Management とは – AWS Identity and Access Management
- IAM でのポリシーと許可 – AWS Identity and Access Management
- IAM JSON ポリシー要素: Effect – AWS Identity and Access Management
- ポリシー評価論理 – AWS Identity and Access Management
- IAM グループ – AWS Identity and Access Management
- IAM ポリシーの例 – AWS Identity and Access Management
- IAM Access Analyzer とは – AWS Identity and Access Management
- 最小権限を適用する – AWS Identity and Access Management
問題文:
ある企業が以前にデータウェアハウスソリューションをAWSに移行しました。
この企業にはAWS Direct Connect接続もあります。企業のオフィスユーザーは可視化ツールを使用してデータウェアハウスにクエリを実行しています。データウェアハウスから返されるクエリの平均サイズは50MBで、可視化ツールから送信される各Webページは約500KBです。データウェアハウスから返される結果セットはキャッシュされません。
この企業にとって最も低いデータ転送エグレスコストを提供するソリューションはどれですか。
選択肢:
A. 可視化ツールをオンプレミスでホストし、同じAWSリージョンのDirect Connect接続経由でデータウェアハウスに直接クエリします。
B. 可視化ツールをオンプレミスでホストし、インターネット経由でデータウェアハウスに直接クエリします。
C. 可視化ツールをデータウェアハウスと同じAWSリージョンでホストし、インターネット経由でアクセスします。
D. 可視化ツールをデータウェアハウスと同じAWSリージョンでホストし、同じリージョンのDirect Connect接続経由でアクセスします。
正解:D
A. 可視化ツールをオンプレミスでホストし、同じAWSリージョンのDirect Connect接続経由でデータウェアハウスに直接クエリします。
不正解 Direct Connect接続を使用することでインターネットよりも低いデータ転送料金を実現できますが、依然として50MBという大容量のクエリ結果をオンプレミスに転送する必要があります。可視化ツールがオンプレミスにある限り、大きなデータ移動を避けることができません。
B. 可視化ツールをオンプレミスでホストし、インターネット経由でデータウェアハウスに直接クエリします。
不正解 可視化ツールをオンプレミスでホストし、インターネット経由でデータウェアハウスにアクセスする場合、クエリ結果の50MBがAWSからオンプレミスに転送されるため、最も高いインターネットエグレス料金が発生します。また、インターネット接続による帯域幅制限や遅延の問題も生じる可能性があります。
C. 可視化ツールをデータウェアハウスと同じAWSリージョンでホストし、インターネット経由でアクセスします。
不正解 可視化ツールを同じAWSリージョンにホストすることで、データウェアハウスとの間の50MBデータ転送は無料になりますが、オンプレミスから可視化ツールへのアクセスにインターネット経由で500KBの転送が発生します。Direct Connectを活用しないため、最適なコスト効率を実現できません。
D. 可視化ツールをデータウェアハウスと同じAWSリージョンでホストし、同じリージョンのDirect Connect接続経由でアクセスします。
正解 可視化ツールをデータウェアハウスと同じAWSリージョンに配置することで、50MBのクエリ結果転送が同一リージョン内(無料)で完結します。オンプレミスからはDirect Connect経由で500KBのWebページアクセスのみとなり、エグレスデータ量を大幅に削減できます。既存のDirect Connect接続を効果的に活用し、最低のエグレスコストを実現します。
全体的な説明
問われている要件
- データウェアハウスクエリ(50MB)と可視化ツールアクセス(500KB)の最適化
- 最低のデータ転送エグレスコストの実現
- 既存のDirect Connect接続の効果的活用
- オンプレミスユーザーからの可視化ツールアクセス
- キャッシュされない結果セットの効率的な処理
前提知識
AWSデータ転送料金の仕組みについて
- AWS内の同一リージョン間でのデータ転送は無料で、同一アベイラビリティーゾーン内のEC2インスタンス間転送、RDSとEC2間転送、S3とEC2間転送などが対象となります
- インターネットエグレス料金は転送量に応じて段階的に設定され、最初の1GBは無料、次の9.999TBまでは$0.09/GB、その後さらに安価になる従量制です
- クロスリージョンデータ転送は送信側リージョンで課金され、料金はリージョンペア間で異なります
AWS Direct Connectの料金体系について
- Direct Connectのデータ転送料金はインターネットエグレスより大幅に安価で、通常50-80%のコスト削減が可能です
- 専用線接続の固定費用(ポート時間、回線費用)は既に発生しているため、データ転送量を最小化することが重要です
- Direct Connect Gatewayを使用することで、複数のリージョンやVPCへの接続を効率化できます
データウェアハウスアーキテクチャのベストプラクティスについて
- 可視化ツールはデータソースに近い場所に配置することで、ネットワーク遅延とデータ転送コストを最小化できます
- クエリ結果のキャッシュ機能がない場合、アーキテクチャレベルでのデータ移動最適化が重要です
- BI(Business Intelligence)ツールの配置戦略は、データサイズ、アクセス頻度、ユーザー分散を考慮して決定すべきです
解くための考え方
この問題の核心は、大容量のクエリ結果(50MB)と小容量のWebページ(500KB)という2つの異なるデータフローを理解することです。
まず、各選択肢でのデータ転送パターンを分析する必要があります。可視化ツールがオンプレミスにある場合、50MBのクエリ結果を毎回AWS外部に転送する必要があり、これが最も高コストな要因となります。
一方、可視化ツールをAWS内に配置すれば、データウェアハウスとの間の大容量データ転送は同一リージョン内で完結し、エグレス料金が発生しません。オンプレミスユーザーは500KBの軽量なWebページのみを受信すればよくなります。
さらに、既存のDirect Connect接続を活用することで、残りの500KBのデータ転送もインターネットより安価な料金で実現できます。この組み合わせにより、総エグレスコストを最小化できます。
アーキテクチャ図
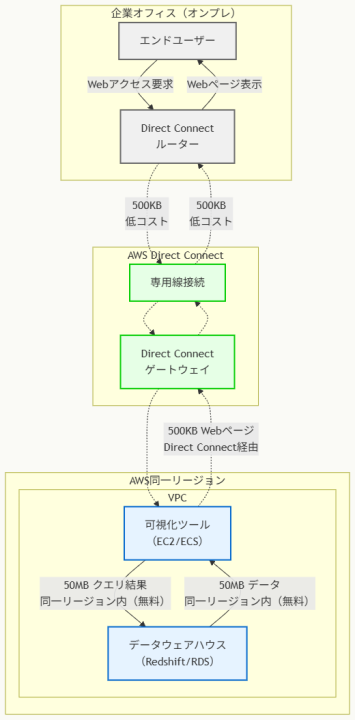
アーキテクチャ図の解説
AWS内無料データ転送の活用
このアーキテクチャの最大の特徴は、大容量のクエリ結果(50MB)を同一AWS リージョン内で処理することです。可視化ツールとデータウェアハウスを同じリージョンに配置することで、データウェアハウスへのクエリ実行と結果の取得が完全にAWS内で完結し、この部分のデータ転送コストは無料になります。
これにより、従来オンプレミスの可視化ツールが必要としていた50MBのエグレストラフィックが完全に削除され、大幅なコスト削減が実現されます。
Direct Connect経由の最適化されたユーザーアクセス
エンドユーザーからのアクセスは、既存のDirect Connect接続を活用して500KBの軽量なWebページのみを転送します。Direct Connectのデータ転送料金はインターネットエグレス料金より大幅に安価であり、さらに転送量も50MBから500KBに削減されているため、コスト効率性が大幅に向上します。
専用線接続により安定した帯域幅と低遅延も確保され、ユーザーエクスペリエンスの向上も期待できます。
データフロー最適化の効果
このアーキテクチャにより、総エグレスデータ量が従来の50MBから500KBへと99%削減されます。可視化ツールがクエリ処理と結果の可視化をAWS内で実行し、完成されたWebページのみをオンプレミスに送信することで、ネットワーク効率性とコスト効率性を両立しています。
結果セットがキャッシュされない環境においても、この最適化により継続的なコスト削減効果が期待できます。
他のソリューションとの比較
オンプレミス可視化ツール + インターネット接続の組み合わせは、50MBの高額なインターネットエグレス料金が毎回発生し、最もコスト効率が悪い選択となります。
AWS内可視化ツール + インターネット接続は、AWS内転送は無料になりますが、500KBのインターネット転送がDirect Connectより高コストです。
オンプレミス可視化ツール + Direct Connect接続は、転送料金は削減されますが、依然として50MBという大容量データの移動が必要で、根本的な最適化には至りません。
実装の考慮事項
実装時には、可視化ツールのAWSへの移行計画を慎重に策定する必要があります。既存のオンプレミス環境からのスムーズな移行のため、段階的な移行アプローチやハイブリッド運用期間の設定を検討すべきです。
また、可視化ツールのインスタンスサイズは、同時ユーザー数とクエリ負荷に基づいて適切に設計し、Auto Scalingによる動的なスケーリング機能も活用できます。
セキュリティ面では、Direct Connect接続のセキュリティ設定、VPC内のネットワークセグメンテーション、IAMによるアクセス制御を適切に設定し、企業のセキュリティポリシーに準拠する必要があります。運用面では、可視化ツールのパフォーマンス監視とコスト監視を継続的に実施することが重要です。
参考資料
問題文:
企業は最近AWSに移行し、プロダクションVPCに出入りするトラフィックを保護するソリューションを実装したいと考えています。企業はオンプレミスデータセンターにインスペクションサーバーを持っていました。このインスペクションサーバーは、トラフィックフロー検査やトラフィックフィルタリングなどの特定の操作を実行していました。企業はAWSクラウドでも同じ機能を持ちたいと考えています。
これらの要件を満たすソリューションはどれですか。
選択肢:
A. プロダクションVPCからのトラフィックをミラーリングしてトラフィック検査とフィルタリングを行うためにTraffic Mirroringを使用します。
B. プロダクションVPCでのトラフィック検査とトラフィックフィルタリングにAmazon GuardDutyを使用します。
C. プロダクションVPCのトラフィック検査とトラフィックフィルタリングに必要なルールを作成するためにAWS Network Firewallを使用します。
D. プロダクションVPCのトラフィック検査とトラフィックフィルタリングに必要なルールを作成するためにAWS Firewall Managerを使用します。
正解:C
A. プロダクションVPCからのトラフィックをミラーリングしてトラフィック検査とフィルタリングを行うためにTraffic Mirroringを使用します。
不正解 Traffic Mirroringはネットワークトラフィックをコピーして別の場所に送信するサービスで、検査は可能ですがフィルタリング機能は提供していません。ミラーリングされたトラフィックは元のトラフィックフローに影響を与えず、実際のトラフィック制御や阻止はできません。検査用途には適していますが、要件のフィルタリング機能を満たしません。
B. プロダクションVPCでのトラフィック検査とトラフィックフィルタリングにAmazon GuardDutyを使用します。
不正解 Amazon GuardDutyは脅威検知サービスで、機械学習を使用してアカウントやワークロードの異常な活動を検出します。ネットワークトラフィックの検査やフィルタリング機能は提供しておらず、主に既存のログやメタデータを分析して脅威を特定するサービスです。VPCトラフィックのリアルタイム制御や阻止機能はありません。
C. プロダクションVPCのトラフィック検査とトラフィックフィルタリングに必要なルールを作成するためにAWS Network Firewallを使用します。
正解 AWS Network Firewallはマネージドなステートフルネットワークファイアウォールサービスで、VPCのトラフィック検査とフィルタリングの両方を提供します。インターネットゲートウェイ、NATゲートウェイ、VPN、Direct Connect経由のトラフィックをフィルタリングでき、カスタムルールグループの作成、パケット検査、TLS検査機能を提供します。オンプレミスのインスペクションサーバーの機能を完全に代替できます。
D. プロダクションVPCのトラフィック検査とトラフィックフィルタリングに必要なルールを作成するためにAWS Firewall Managerを使用します。
不正解 AWS Firewall Managerは複数のAWSアカウントやVPCにわたってファイアウォールルールを一元管理するサービスです。実際のトラフィック検査やフィルタリングを実行するのではなく、セキュリティポリシーの管理と適用を行うオーケストレーションサービスです。Network Firewallやセキュリティグループなどの管理は可能ですが、直接的なトラフィック制御機能はありません。
全体的な説明
問われている要件
- プロダクションVPCに出入りするトラフィックの保護
- オンプレミスインスペクションサーバーと同等のトラフィックフロー検査機能
- トラフィックフィルタリング機能の実装
- AWSクラウドでの一元的なネットワークセキュリティ制御
- インライン処理による実時間トラフィック制御
前提知識
ネットワークセキュリティサービスの特徴について
- AWS Network Firewall
- マネージド型ステートフルネットワークファイアウォールサービス
- レイヤー3からレイヤー7までの検査とフィルタリング機能を提供
- カスタムルールグループと AWS管理ルールグループをサポート
- TLS検査、侵入検知・防止(IDS/IPS)機能を内蔵
- VPCの境界でインラインでトラフィックを処理
- Amazon GuardDuty
- AIと機械学習を活用した脅威検知サービス
- VPCフローログ、DNS クエリログ、CloudTrailイベントログを分析
- 異常な活動や悪意のある動作を検出してアラートを生成
- リアルタイムトラフィック制御機能は提供しない
トラフィック監視・制御サービスについて
- VPC Traffic Mirroring
- EC2インスタンスのネットワークインターフェースからトラフィックをコピー
- 複製されたトラフィックを分析用ターゲットに送信
- 元のトラフィックフローに影響を与えない受動的な監視機能
- ミラーフィルターでコピーするトラフィックを選択可能だが制御機能はなし
- AWS Firewall Manager
- マルチアカウント・マルチリージョンでのセキュリティポリシー管理サービス
- AWS WAF、AWS Network Firewall、セキュリティグループの一元管理
- セキュリティポリシーの自動適用と継続的なコンプライアンス監視
- 実際のトラフィック処理は管理対象のサービスが実行
ネットワーク制御の実装方法について
- インライン処理とアウトオブバンド処理
- インライン:トラフィックパス上でリアルタイム制御(Network Firewall)
- アウトオブバンド:トラフィックをコピーして別途分析(Traffic Mirroring)
- インライン処理はレイテンシーが発生するが確実な制御が可能
- アウトオブバンド処理は元のパフォーマンスに影響しないが制御は不可
解くための考え方
この問題はオンプレミスのインスペクションサーバーの機能をAWSクラウドで再現する最適な方法を求めています。要件として「トラフィックフロー検査」と「トラフィックフィルタリング」の両方が明記されており、これらを同時に実現できるサービスが必要です。AWS Network Firewallは唯一両方の機能を提供するマネージドサービスで、VPCの境界でインラインでトラフィックを処理できます。レイヤー3からレイヤー7までの深いパケット検査、ステートフル接続追跡、カスタムルール作成機能により、オンプレミスのインスペクションサーバーと同等以上の機能を提供します。Amazon GuardDutyは検知のみでフィルタリング機能がなく、Traffic Mirroringは監視専用で制御機能がありません。AWS Firewall Managerはポリシー管理サービスで実際のトラフィック処理は行いません。従って、要件を完全に満たす唯一のソリューションはAWS Network Firewallとなります。
アーキテクチャ図
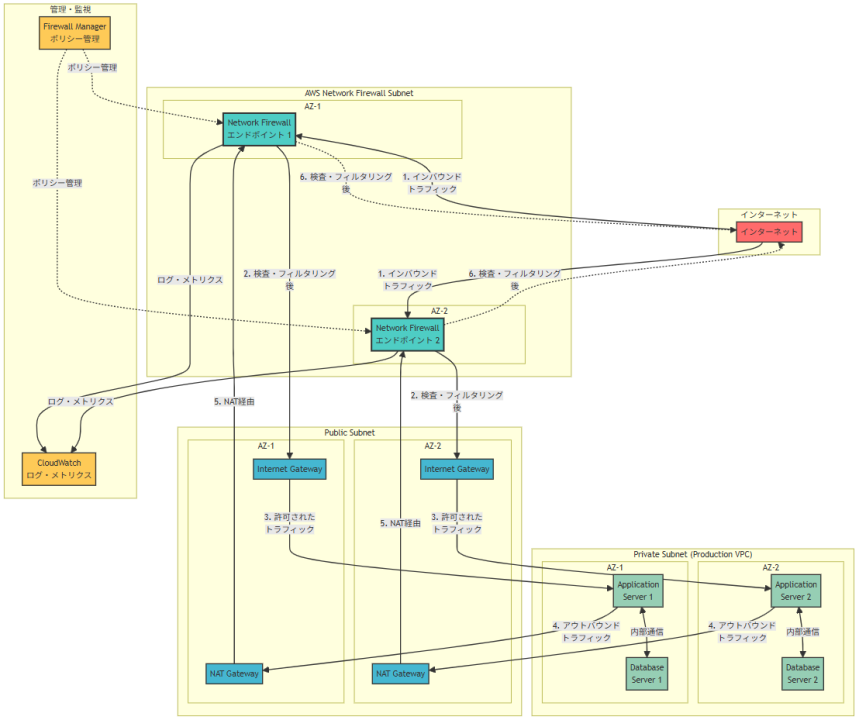
アーキテクチャ図の解説
インライントラフィック制御による包括的保護
このアーキテクチャでは、AWS Network FirewallがプロダクションVPCへの全てのトラフィックフローの中間に配置され、インラインでトラフィック検査とフィルタリングを実行します。インバウンドトラフィックはインターネットからNetwork Firewallエンドポイントを経由してInternet Gatewayに到達し、アウトバウンドトラフィックはNAT Gatewayを経由してNetwork Firewallで検査された後にインターネットに送信されます。この構成により、オンプレミスのインスペクションサーバーと同等の包括的なトラフィック制御が実現されます。
マルチAZ高可用性とスケーラビリティ
Network Firewallエンドポイントは複数のAvailability Zoneに分散配置され、単一AZ障害に対する耐性を提供します。各エンドポイントは自動的にスケーリングし、トラフィック量の増加に対応できます。プロダクションVPC内のアプリケーションサーバーとデータベースサーバーも複数AZに分散配置され、Network Firewallの保護下で安全に運用されます。内部通信は直接行われますが、外部との通信は全てNetwork Firewallを経由することで一元的なセキュリティ制御が実現されます。
統合監視と一元管理機能
CloudWatchにより、Network Firewallのログ、メトリクス、アラートが一元的に監視され、トラフィックパターンや脅威の分析が可能です。AWS Firewall Managerとの統合により、複数のアカウントやVPCにわたるファイアウォールポリシーの一元管理と自動適用が実現されます。これにより、運用の一貫性とコンプライアンスの確保が可能となり、スケーラブルなセキュリティ運用が実現されます。
他のソリューションとの比較
Amazon GuardDutyはログベースの脅威検知サービスで、リアルタイムトラフィック制御機能がないため要件を満たしません。
Traffic Mirroringはトラフィックのコピーと監視には有効ですが、フィルタリング機能がなく、別途インスペクションサーバーの構築・運用が必要となります。
AWS Firewall Managerは管理ツールとして有効ですが、実際のトラフィック処理は行わないため、Network Firewallと組み合わせて使用する必要があります。
これらの比較から、要件を単独で満たせるのはNetwork Firewallのみです。
実装の考慮事項
Network Firewallの実装では、ルートテーブルの適切な設定により全てのトラフィックがファイアウォールを経由するよう構成する必要があります。ルールグループの設計では、アプリケーション要件に応じたきめ細かいルール作成と、パフォーマンスへの影響を最小化するルール最適化が重要です。TLS検査機能を有効化する場合は、証明書管理とプライバシー要件の検討が必要です。コスト面では、処理データ量に応じた従量課金制のため、トラフィック量の予測と最適化が重要となります。また、既存のセキュリティグループやNACLとの適切な役割分担により、多層防御を実現できます。
参考資料
問題文:
ある企業が顧客向けのデモンストレーション環境をAmazon EC2インスタンス上で実行しています。
各環境は独自のVPCで分離されています。企業の運用チームは、環境へのRDPまたはSSHアクセスが確立された時に通知を受け取る必要があります。
ソリューションアーキテクトは何を実行すべきでしょうか。
選択肢:
A. VPC Flow LogsをAmazon CloudWatch Logsに発行する。必要なメトリックフィルターを作成する。アラーム状態の時に通知アクションを持つAmazon CloudWatchメトリックアラームを作成する。
B. AmazonSSMManagedInstanceCoreポリシーがアタッチされたIAMロールを持つIAMインスタンスプロファイルでEC2インスタンスを設定する。
C. EC2 Instance State-change NotificationタイプのイベントをリッスンするためのAmazon EventBridgeルールを設定する。Amazon Simple Notification Service(Amazon SNS)トピックをターゲットとして設定する。運用チームをトピックにサブスクライブする。
D. Amazon CloudWatch Application InsightsがRDPまたはSSHアクセスを検出したときにAWS Systems Manager OpsItemsを作成するように設定する。
正解:A
A. VPC Flow LogsをAmazon CloudWatch Logsに発行する。必要なメトリックフィルターを作成する。アラーム状態の時に通知アクションを持つAmazon CloudWatchメトリックアラームを作成する。
正解 VPC Flow LogsはVPC内のネットワークインターフェースとの間のIPトラフィック情報をキャプチャできます。SSH(ポート22)やRDP(ポート3389)への接続トラフィックを検出し、CloudWatchメトリックフィルターで特定のポートへの接続パターンをフィルタリングできます。CloudWatchアラームにより、検出時に運用チームへの自動通知を実現できる包括的なソリューションです。
B. AmazonSSMManagedInstanceCoreポリシーがアタッチされたIAMロールを持つIAMインスタンスプロファイルでEC2インスタンスを設定する。
不正解 AmazonSSMManagedInstanceCoreポリシーの設定は、Systems Manager Session Managerを使用するための前提条件ですが、RDPやSSHアクセスの検出や通知機能は含まれていません。このポリシーはインスタンスへのアクセス方法を提供するものですが、アクセス監視や通知の仕組みは別途構築する必要があります。
C. EC2 Instance State-change NotificationタイプのイベントをリッスンするためのAmazon EventBridgeルールを設定する。Amazon Simple Notification Service(Amazon SNS)トピックをターゲットとして設定する。運用チームをトピックにサブスクライブする。
不正解 EC2 Instance State-change Notificationは、インスタンスの状態変更(pending、running、stopping、stopped、shutting-down、terminated)をキャプチャします。しかし、RDPやSSHアクセスの確立はインスタンスの状態変更とは無関係で、これらの接続はインスタンスが実行中状態のまま確立されるため、この方法では検出できません。
D. Amazon CloudWatch Application InsightsがRDPまたはSSHアクセスを検出したときにAWS Systems Manager OpsItemsを作成するように設定する。
不正解 CloudWatch Application Insightsは主にアプリケーションの問題検出とパフォーマンス監視に特化したサービスです。RDPやSSHアクセスの検出機能は提供しておらず、ネットワークレベルの接続監視には適していません。また、Systems Manager OpsItemsは運用作業の管理に使用されるもので、リアルタイムの通知要件には適合しません。
全体的な説明
問われている要件
- デモンストレーション環境への不正アクセス監視
- RDPおよびSSH接続の確立時点での即座の通知
- 各VPCで分離された環境での一元的な監視
- 運用チームへの自動通知システムの構築
- ネットワークレベルでのアクセス検出機能
前提知識
VPC Flow Logsの監視機能について
- VPC Flow LogsはVPC内のネットワークインターフェースとの間で送受信されるIPトラフィックに関する情報をキャプチャします。送信元IP、宛先IP、ポート番号、プロトコル、アクション(ACCEPT/REJECT)などの詳細情報を記録できます。
- SSH(ポート22)やRDP(ポート3389)への接続試行は、Flow Logsに記録されるため、これらの特定ポートへの接続パターンを監視できます。成功した接続だけでなく、失敗した接続試行も検出できるため、セキュリティ監視に有効です。
- Flow LogsはCloudWatch Logs、S3、Kinesis Data Firehoseに出力でき、CloudWatch Logsに出力することでリアルタイムに近い監視が可能になります。
CloudWatchメトリックフィルターとアラームについて
- メトリックフィルターは、CloudWatch Logsに送信されるログデータから特定のパターンを検索し、カスタムメトリックを生成できます。正規表現やワイルドカードを使用して、SSH/RDP接続を示すログエントリを検出できます。
- CloudWatchアラームは、メトリックが指定した閾値を超えた場合にアクションを実行できます。SNS通知、Lambda関数の実行、Auto Scalingアクションなどを自動的にトリガーできます。
- アラーム状態では、メール、SMS、Slack通知など複数の通知チャネルを設定でき、運用チームへの迅速な通知を実現できます。
他のAWSサービスの特徴について
- Amazon EventBridgeはイベント駆動型アーキテクチャを構築するためのサービスですが、EC2インスタンスの状態変更イベントは、インスタンスのライフサイクル(起動、停止、終了など)に関するもので、ネットワーク接続とは無関係です。
- Systems Manager Session Managerは、インスタンスへの安全なアクセス方法を提供しますが、従来のSSH/RDPアクセスとは別のアクセス経路であり、従来の接続方法の監視には直接的には役立ちません。
解くための考え方
この問題の核心は、ネットワークレベルでのRDP/SSH接続の検出と通知の自動化です。RDPやSSH接続は、EC2インスタンスの状態変更を伴わないため、インスタンスレベルのイベントでは検出できません。
ネットワークトラフィックを監視できるVPC Flow Logsは、このような要件に最適なソリューションです。特定のポート(SSH: 22、RDP: 3389)への接続を検出し、CloudWatchの機能を活用して自動通知システムを構築できます。
CloudWatch Application Insightsやsystems Manager関連のソリューションは、アプリケーション監視や管理の観点では有用ですが、ネットワーク接続の検出という特定の要件には適していません。
VPC Flow Logsとメトリックフィルターの組み合わせにより、カスタマイズ可能で拡張性の高い監視システムを構築でき、将来的な要件変更にも柔軟に対応できます。
アーキテクチャ図
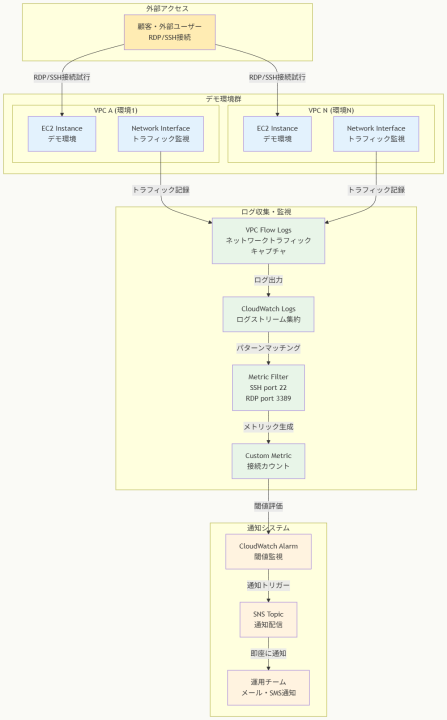
アーキテクチャ図の解説
ネットワークトラフィックの包括的監視
複数のVPCに分離されたデモ環境において、各EC2インスタンスのネットワークインターフェースを通じて送受信されるトラフィックをVPC Flow Logsが包括的にキャプチャします。外部ユーザーからのRDP(ポート3389)やSSH(ポート22)接続試行は、すべてFlow Logsに記録され、CloudWatch Logsに集約されます。この方式により、環境の数が増加しても一元的な監視が可能になります。
自動検出と即座の通知システム
CloudWatch Logsに送信されたトラフィックデータは、メトリックフィルターによってRDP/SSH接続パターンが検出され、カスタムメトリックとして変換されます。このメトリックがCloudWatchアラームで監視され、接続が検出された瞬間にSNSトピック経由で運用チームに自動通知されます。この自動化により、24時間体制でのセキュリティ監視を人的リソースなしで実現できます。
他のソリューションとの比較
EventBridgeによるEC2状態変更監視と比較して、VPC Flow Logsはネットワーク接続という実際の脅威を直接検出できます。インスタンスの起動や停止ではなく、実際のアクセス試行を監視するため、セキュリティ上の意味のあるイベントのみを通知できます。
CloudWatch Application InsightsやSystems Manager関連のソリューションと比較して、VPC Flow Logsは既存のインフラストラクチャに追加設定なしで適用でき、アプリケーションレベルの変更も不要です。また、成功した接続だけでなく失敗した接続試行も検出できるため、より包括的なセキュリティ監視を提供します。
実装の考慮事項
VPC Flow Logsの設定では、必要最小限のフィールド(送信元IP、宛先ポート、アクション)のみをキャプチャしてコストを最適化します。メトリックフィルターでは、正規表現を使用してSSH/RDP接続を正確に識別し、誤検知を最小化する必要があります。
CloudWatchアラームの閾値設定では、正常な管理アクセスと不正アクセスを区別するため、時間帯や接続頻度を考慮した設定を行います。SNS通知では、緊急度に応じて複数の通知チャネル(メール、SMS、Slack)を設定し、運用チームの確実な認知を保証します。
コスト管理の観点では、Flow Logsの保持期間を適切に設定し、古いログは自動的に削除されるよう設定することが重要です。また、大量のトラフィックが予想される場合は、サンプリング機能の活用も検討できます。
参考資料
問題文:
ある企業がAWS Cloudでホストされているメディアアプリケーション用の共有ストレージソリューションを実装しています。
企業はSMBクライアントを使用してデータにアクセスする機能が必要です。ソリューションは完全にマネージドである必要があります。
これらの要件を満たすAWSソリューションはどれですか。
選択肢:
A. Amazon FSx for Windows File Serverファイルシステムを作成します。ファイルシステムを元のサーバーにアタッチします。アプリケーションサーバーをファイルシステムに接続します。
B. AWS Storage Gateway tape gatewayを作成します。Amazon S3を使用するようにテープを設定します。アプリケーションサーバーをtape gatewayに接続します。
C. AWS Storage Gateway volume gatewayを作成します。必要なクライアントプロトコルを使用するファイル共有を作成します。アプリケーションサーバーをファイル共有に接続します。
D. Amazon EC2 Windowsインスタンスを作成します。インスタンスにWindowsファイル共有ロールをインストールして設定します。アプリケーションサーバーをファイル共有に接続します。
正解:A
A. Amazon FSx for Windows File Serverファイルシステムを作成します。ファイルシステムを元のサーバーにアタッチします。アプリケーションサーバーをファイルシステムに接続します。
正解 Amazon FSx for Windows File Serverは、SMBプロトコルをネイティブにサポートする完全にマネージドなWindowsファイルシステムサービスです。ファイルシステムの管理、パッチ適用、バックアップなどがAWSにより自動化され、メディアアプリケーションの共有ストレージ要件を満たします。
B. AWS Storage Gateway tape gatewayを作成します。Amazon S3を使用するようにテープを設定します。アプリケーションサーバーをtape gatewayに接続します。
不正解 AWS Storage Gateway tape gatewayは、仮想テープライブラリ(VTL)インターフェイスを提供し、既存のバックアップソフトウェアとの統合に使用されます。iSCSIプロトコルを使用し、SMBクライアントアクセスは提供されません。メディアアプリケーションの共有ストレージ要件にも適していません。
C. AWS Storage Gateway volume gatewayを作成します。必要なクライアントプロトコルを使用するファイル共有を作成します。アプリケーションサーバーをファイル共有に接続します。
不正解 AWS Storage Gateway volume gatewayは、iSCSIプロトコルを使用するブロックストレージボリュームを提供するサービスです。SMBクライアントアクセスは提供されません。また、ゲートウェイアプライアンス(仮想マシン)の展開と維持管理が必要で、完全にマネージドなソリューションとは言えません。
D. Amazon EC2 Windowsインスタンスを作成します。インスタンスにWindowsファイル共有ロールをインストールして設定します。アプリケーションサーバーをファイル共有に接続します。
不正解 EC2 WindowsインスタンスにWindowsファイル共有を設定することで技術的にはSMBアクセスを提供できますが、インスタンスの管理、パッチ適用、バックアップ、高可用性設定などをユーザーが行う必要があり、完全にマネージドなソリューションではありません。
全体的な説明
問われている要件
- メディアアプリケーション用の共有ストレージソリューション
- SMBクライアントを使用したデータアクセス機能
- 完全にマネージドなソリューション(運用負荷の最小化)
- AWS Cloud上での実装
- 高性能なファイルアクセスの提供
前提知識
Amazon FSx for Windows File Serverの特徴について
- Amazon FSx for Windows File Serverは、Microsoft Windows Server上に構築されたフルマネージドなファイルシステムで、SMB(Server Message Block)プロトコルをネイティブにサポートします
- Active Directory統合、重複排除、圧縮、VSS(Volume Shadow Copy Service)、Windows ACL(Access Control List)などのWindows固有の機能を提供します
- SSDとHDDストレージオプションがあり、メディアファイルのような大容量データに対して高いスループットとIOPSを提供できます
SMBプロトコルとファイル共有について
- SMB(Server Message Block)は、ネットワーク上でファイル、プリンター、シリアルポートを共有するためのプロトコルで、Windowsファイル共有の標準プロトコルです
- SMB 2.0/3.0では、暗号化機能、パフォーマンスの向上、可用性の改善が提供され、企業環境での安全なファイル共有が可能になります
- メディアアプリケーションでは、大容量ファイルの並行アクセス、ストリーミング再生、編集作業での共有が重要な要件となります
AWS Storage Gatewayの制限について
- AWS Storage Gateway file gatewayはSMBをサポートしますが、オンプレミスまたはEC2インスタンス上にゲートウェイアプライアンスを展開する必要があります
- ゲートウェイの運用管理、パッチ適用、監視は顧客が行う必要があり、完全にマネージドなソリューションではありません
- Volume gatewayとtape gatewayは、それぞれiSCSIプロトコルを使用し、SMBクライアントアクセスは提供されません
解くための考え方
この問題では「SMBクライアントアクセス」と「完全にマネージド」という2つの重要な要件を同時に満たす必要があります。
まず、SMBプロトコルのサポートが必要なため、iSCSIベースのvolume gatewayやtape gatewayは除外されます。これらのサービスはブロックストレージやテープストレージの抽象化を提供しますが、ファイルレベルのSMBアクセスは提供しません。
次に、「完全にマネージド」という要件により、EC2インスタンス上での自己管理Windowsファイル共有も除外されます。このアプローチでは、OSの管理、セキュリティパッチ、バックアップ、高可用性設定などの運用作業が必要になります。
Amazon FSx for Windows File Serverは、これらの要件を完全に満たすサービスです。SMBプロトコルをネイティブにサポートし、AWS が完全に管理するため、顧客の運用負荷を最小限に抑えながら高性能なファイル共有を実現できます。
アーキテクチャ図
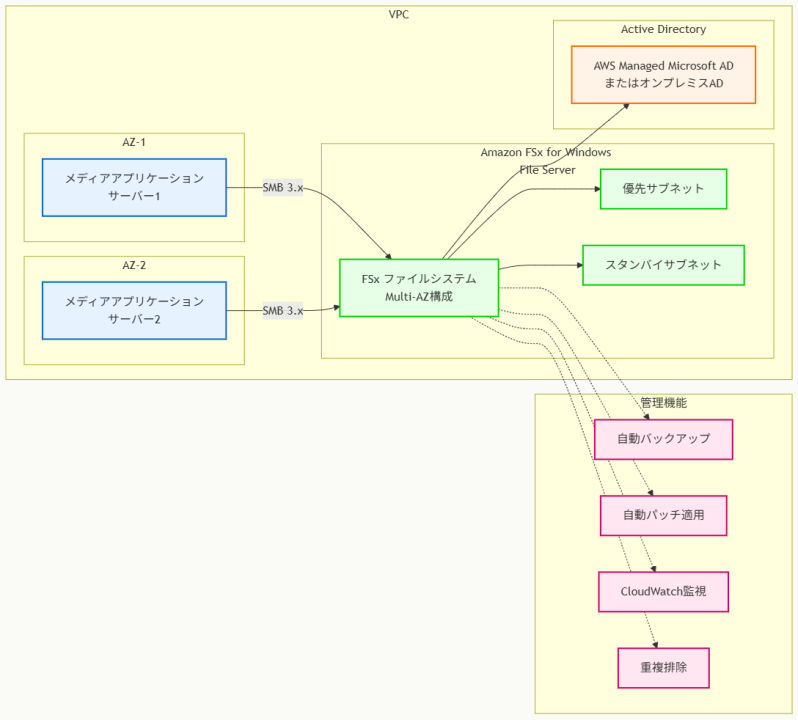
アーキテクチャ図の解説
Multi-AZ FSx for Windows File Serverの高可用性
このアーキテクチャでは、Amazon FSx for Windows File Serverが複数のアベイラビリティーゾーンにまたがって配置され、高可用性を提供しています。優先サブネットでアクティブなファイルサーバーが稼働し、スタンバイサブネットで自動フェイルオーバー機能が待機しています。
メディアアプリケーションサーバーとSMBクライアントは、SMB 3.xプロトコルを使用してファイルシステムに接続し、大容量メディアファイルの読み取り、書き込み、ストリーミングアクセスを実行できます。
Active Directory統合によるセキュリティ管理
FSx for Windows File ServerはActive Directoryと統合され、既存のユーザーアカウントとグループベースのアクセス制御を活用できます。AWS Managed Microsoft ADまたはオンプレミスのActive Directoryとの接続により、企業のセキュリティポリシーに準拠したファイルアクセス管理が実現されます。
Windows ACL(Access Control List)により、ファイルやフォルダレベルでの詳細なアクセス権限設定が可能で、メディアアセットの適切な保護が確保されます。
完全マネージド機能による運用負荷軽減
AWSが提供する完全マネージド機能により、自動バックアップ、パッチ適用、CloudWatch監視、重複排除などが自動化されています。これにより、顧客はメディアアプリケーションの開発と運用に集中でき、インフラストラクチャの管理負荷を大幅に削減できます。
他のソリューションとの比較
Storage Gateway file gatewayもSMBをサポートしますが、ゲートウェイアプライアンスの展開と運用管理が必要で、ハイブリッド環境での使用に最適化されています。完全クラウドベースのメディアアプリケーションには不要な複雑性を追加します。
EC2ベースのWindowsファイル共有は、カスタマイズ性は高いものの、OSレベルの管理、セキュリティパッチ、バックアップ戦略、高可用性設定などの運用作業が必要になります。
Amazon EFSはLinux/Unix環境に最適化されており、SMBプロトコルのサポートやWindows固有の機能は提供されません。
実装の考慮事項
実装時には、メディアファイルのサイズとアクセスパターンに基づいて適切なストレージタイプ(SSDまたはHDD)とスループット容量を選択する必要があります。4K/8K動画編集のような高帯域幅要件がある場合は、SSDストレージと高スループット設定が推奨されます。
また、メディアアセットのライフサイクル管理のため、FSxと Amazon S3との統合やAWS DataSyncを使用したデータ移行戦略も検討できます。
セキュリティ面では、VPCエンドポイントの使用、転送時暗号化の有効化、適切なセキュリティグループ設定により、メディアコンテンツの保護を強化することが重要です。運用面では、CloudWatchメトリクスによるパフォーマンス監視、容量使用率の追跡、バックアップ戦略の定期的な見直しにより、システムの健全性と効率性を確保することが推奨されます。
参考資料
- Amazon FSx for Windows File Server とは – Amazon FSx for Windows File Server
- SMB ファイル共有 – Amazon FSx for Windows File Server
- Active Directory との統合 – Amazon FSx for Windows File Server
- AWS Storage Gateway とは – AWS Storage Gateway
- FSx for Windows File Server のパフォーマンス – Amazon FSx for Windows File Server
- バックアップと復元 – Amazon FSx for Windows File Server
- FSx for Windows File Server の料金 – Amazon Web Services
問題文:
企業はオンプレミスのネットワーク接続ストレージ(NFS)を使用して大容量のビデオファイルを保存しています。各ビデオファイルのサイズは1MBから500GBまでの範囲です。総ストレージ容量は70TBで、もう増加していません。企業はビデオファイルをAmazon S3に移行することを決定しました。企業は、可能な限り最小限のネットワーク帯域幅を使用しながら、可能な限り迅速にビデオファイルを移行する必要があります。
これらの要件を満たすソリューションはどれでしょうか?
選択肢:
A. AWS Snowball Edgeジョブを作成する。オンプレミスでSnowball Edgeデバイスを受け取る。Snowball Edgeクライアントを使用してデータをデバイスに転送する。AWSがデータをAmazon S3にインポートできるようにデバイスを返送する。
B. オンプレミスネットワークとAWS間にAWS Direct Connect接続を設定する。S3 File Gatewayをオンプレミスに導入する。S3 File Gatewayに接続するためのパブリック仮想インターフェース(VIF)を作成する。S3バケットを作成する。S3 File Gatewayで新しいNFSファイル共有を作成する。新しいファイル共有をS3バケットに向ける。既存のNFSファイル共有からS3 File Gatewayにデータを転送する。
C. S3 File Gatewayをオンプレミスに導入する。S3 File Gatewayに接続するためのパブリックサービスエンドポイントを作成する。S3バケットを作成する。S3 File Gatewayで新しいNFSファイル共有を作成する。新しいファイル共有をS3バケットに向ける。既存のNFSファイル共有からS3 File Gatewayにデータを転送する。
D. S3バケットを作成する。S3バケットに書き込み権限を持つIAMロールを作成する。AWS CLIを使用してすべてのファイルをローカルからS3バケットにコピーする。
正解:A
A. AWS Snowball Edgeジョブを作成する。オンプレミスでSnowball Edgeデバイスを受け取る。Snowball Edgeクライアントを使用してデータをデバイスに転送する。AWSがデータをAmazon S3にインポートできるようにデバイスを返送する。
正解 AWS Snowball Edgeは、大容量データの移行に最適な物理的データ転送サービスです。70TBのデータを扱えるデバイス(80TBまでサポート)を使用し、ネットワーク帯域幅を全く消費しません。デバイスの配送と返送に時間はかかりますが、実際のデータ転送は100Gbpsの高速で実行でき、約1.5時間で完了します。「最小限のネットワーク帯域幅」という要件を完全に満たし、「データはもう増加していない」という一回限りの移行に最適です。
B. オンプレミスネットワークとAWS間にAWS Direct Connect接続を設定する。S3 File Gatewayをオンプレミスに導入する。S3 File Gatewayに接続するためのパブリック仮想インターフェース(VIF)を作成する。S3バケットを作成する。S3 File Gatewayで新しいNFSファイル共有を作成する。新しいファイル共有をS3バケットに向ける。既存のNFSファイル共有からS3 File Gatewayにデータを転送する。
不正解 AWS Direct Connectの設定には数週間から数ヶ月の時間がかかり、「可能な限り迅速に」という要件に反します。また、Direct Connectが設定されても、70TBのデータ転送には大量の帯域幅を消費します。Direct Connectは継続的な高速接続が必要な場合に適していますが、一回限りのデータ移行には過剰で、セットアップ時間が長すぎます。
C. S3 File Gatewayをオンプレミスに導入する。S3 File Gatewayに接続するためのパブリックサービスエンドポイントを作成する。S3バケットを作成する。S3 File Gatewayで新しいNFSファイル共有を作成する。新しいファイル共有をS3バケットに向ける。既存のNFSファイル共有からS3 File Gatewayにデータを転送する。
不正解 S3 File Gatewayは、オンプレミスとクラウドストレージ間の継続的な同期に適したハイブリッドソリューションです。70TBのデータを転送するために大量のネットワーク帯域幅を消費し、インターネット経由での転送に時間がかかります。このソリューションは、継続的なファイルアクセスが必要な場合に適していますが、一回限りの移行には適していません。また、「最小限のネットワーク帯域幅」という要件を満たしません。
D. S3バケットを作成する。S3バケットに書き込み権限を持つIAMロールを作成する。AWS CLIを使用してすべてのファイルをローカルからS3バケットにコピーする。
不正解 AWS CLIを使用して直接S3バケットにファイルをコピーするアプローチは、70TBものデータを転送するのに大量のネットワーク帯域幅を消費します。インターネット経由での転送は時間がかかり、1Gbpsの接続でも6日以上かかる可能性があります。これは「最小限のネットワーク帯域幅を使用する」という要件に反します。また、大容量データの転送中にネットワーク障害が発生した場合の再送信リスクもあります。
全体的な説明
問われている要件
この問題では以下の要件を満たすソリューションが求められています:
- 70TBという大容量のビデオファイルデータを移行する必要がある
- データはもう増加しておらず、一回限りの移行である
- 可能な限り迅速にデータを移行する必要がある
- 最小限のネットワーク帯域幅を使用する必要がある
前提知識
AWS Snow Familyサービスについて理解しておく必要があります:
- AWS Snowball Edgeは、80TBまでのデータを物理的に転送できるデバイスです
- ネットワーク帯域幅を全く使用せず、物理的な輸送によってデータを移行します
- デバイス上で最大100Gbpsの高速データ転送が可能です
- 一回限りの大容量データ移行に最適化されています
S3 File Gatewayの特徴:
- オンプレミスとAmazon S3間のハイブリッド接続を提供します
- NFSやSMBプロトコルを使用してS3にアクセスできます
- 継続的なファイルアクセスとローカルキャッシュを提供します
- 一回限りの移行よりも、継続的な同期用途に適しています
AWS Direct Connectの特徴:
- オンプレミスとAWS間の専用ネットワーク接続を提供します
- 高速で一貫した接続を提供しますが、セットアップに時間がかかります
- 継続的な高速接続が必要な場合に適しています
- 新規セットアップには数週間から数ヶ月かかる場合があります
データ転送の時間計算:
- 70TB = 560Tbits(70TB × 8bits/byte = 560Tbits)
- 1Gbps接続:560Tbits ÷ 1Gbps = 560,000秒 ≈ 6.5日
- 10Gbps接続:560Tbits ÷ 10Gbps = 56,000秒 ≈ 15.5時間
- Snowball Edge:100Gbps相当で約1.5時間の転送時間
解くための考え方
要件の優先順位を理解することが重要です。「最小限のネットワーク帯域幅を使用する」という要件が最も重要で、これはネットワーク帯域幅を全く使用しないSnowball Edgeが最適であることを示しています。
「データはもう増加していない」という記述は、一回限りの移行であることを示しており、継続的な同期が必要なFile Gatewayよりも、バッチ移行に適したSnowball Edgeが適していることを示しています。
時間の観点から各選択肢を評価すると、Direct Connectのセットアップ時間が最も長く、「可能な限り迅速に」という要件に合いません。Snowball Edgeは配送時間がかかりますが、実際のデータ転送は最も高速です。
移行プロセスとタイムライン
Snowball Edgeを使用した移行プロセスは以下のようになります。
まず、AWS Management ConsoleでSnowball Edgeジョブを作成し、デバイスの配送を依頼します。デバイスが到着したら(通常4-6営業日)、Snowball Edgeクライアントを使用してNFSストレージから70TBのデータをデバイスに転送します。この転送は100Gbpsの高速で実行され、約1.5時間で完了します。その後、デバイスをAWSに返送し(2-3営業日)、AWSがデータをS3バケットにインポートします。
セキュリティと暗号化
Snowball Edgeデバイスは、転送中および保存時の暗号化を提供します。デバイスは256ビットの暗号化を使用し、転送プロセス全体でデータのセキュリティを保証します。また、デバイスは改ざん検知機能を備えており、物理的なセキュリティも確保されています。
コスト効率性
Snowball Edgeは、大容量データの移行において最もコスト効率的なソリューションです。ネットワーク帯域幅を使用しないため、データ転送コストがかかりません。また、継続的な接続料金も発生しません。一回限りの移行には、継続的なサービス料金が発生するDirect Connectよりもコスト効率が良いです。
他のソリューションとの比較
AWS CLIを使用した直接転送は、小規模なデータには適していますが、70TBのような大容量データには適していません。S3 File Gatewayは、継続的なハイブリッドアクセスが必要な場合に適していますが、一回限りの移行には過剰です。Direct Connectは、継続的な高速接続が必要な場合に適していますが、セットアップ時間が長すぎます。
スケーラビリティの考慮事項
将来的にデータが増加する場合は、S3 File Gatewayや他のハイブリッドソリューションを検討する必要があります。しかし、問題では「データはもう増加していない」と明記されているため、一回限りの移行に最適化されたSnowball Edgeが最適です。
実装の考慮事項
Snowball Edgeの実装では、デバイスの配送スケジュールを事前に計画し、データ転送の時間を確保する必要があります。また、デバイスの返送前に、すべてのデータが正常に転送されたことを確認する必要があります。さらに、AWS側でのインポートプロセスが完了するまで、元のデータを保持しておくことが推奨されます。
参考資料
問題文:
AWS上でオンラインマーケットプレイスのWebアプリケーションを運営している企業があります。
このアプリケーションはピーク時に数十万のユーザーにサービスを提供しています。企業は、数百万の金融取引の詳細を複数の他の内部アプリケーションと共有するための、スケーラブルで準リアルタイムのソリューションが必要です。また、取引データは機密データを除去してからドキュメントデータベースに保存し、低レイテンシーでの検索ができるようにする必要があります。
これらの要件を満たすために、ソリューションアーキテクトは何を推奨すべきでしょうか。
選択肢:
A. 取引データをAmazon Kinesis Data Firehoseにストリーミングして、Amazon DynamoDBとAmazon S3にデータを保存する。Kinesis Data FirehoseとのAWS Lambda統合を使用して機密データを除去する。他のアプリケーションはAmazon S3に保存されたデータを消費できる。
B. 取引データをAmazon Kinesis Data Streamsにストリーミングする。AWS Lambda統合を使用して各取引から機密データを除去してから、取引データをAmazon DynamoDBに保存する。他のアプリケーションはKinesisデータストリームから取引データを消費できる。
C. バッチ処理された取引データをAmazon S3にファイルとして保存する。AWS Lambdaを使用して各ファイルを処理し、機密データを除去してからAmazon S3でファイルを更新する。その後、Lambda関数がデータをAmazon DynamoDBに保存する。他のアプリケーションはAmazon S3に保存された取引ファイルを消費できる。
D. 取引データをAmazon DynamoDBに保存する。DynamoDBでルールを設定して、書き込み時に各取引から機密データを除去する。DynamoDB Streamsを使用して取引データを他のアプリケーションと共有する。
正解:B
A. 取引データをAmazon Kinesis Data Firehoseにストリーミングして、Amazon DynamoDBとAmazon S3にデータを保存する。Kinesis Data FirehoseとのAWS Lambda統合を使用して機密データを除去する。他のアプリケーションはAmazon S3に保存されたデータを消費できる。
不正解 準リアルタイムという表現はKinesis Data Firehoseに合致しますが、FirehoseはDynamoDBを直接の配信先としてサポートしていません。Firehoseがサポートする配信先は、S3、Redshift、OpenSearch Service、Splunk、HTTP エンドポイントなどに限定されています。したがって、DynamoDBへの直接配信は技術的に不可能です。
B. 取引データをAmazon Kinesis Data Streamsにストリーミングする。AWS Lambda統合を使用して各取引から機密データを除去してから、取引データをAmazon DynamoDBに保存する。他のアプリケーションはKinesisデータストリームから取引データを消費できる。
正解 Kinesis Data Streamsはリアルタイムストリーミングに対応し、数百万のトランザクションを処理できるスケーラビリティを提供します。Lambda統合により機密データの除去処理を行い、処理済みデータをDynamoDBに保存できます。複数のアプリケーションがKinesisストリームから同時にデータを消費でき、準リアルタイムでのデータ共有が実現されます。DynamoDBは低レイテンシーでの検索要件も満たします。
C. バッチ処理された取引データをAmazon S3にファイルとして保存する。AWS Lambdaを使用して各ファイルを処理し、機密データを除去してからAmazon S3でファイルを更新する。その後、Lambda関数がデータをAmazon DynamoDBに保存する。他のアプリケーションはAmazon S3に保存された取引ファイルを消費できる。
不正解 S3へのファイルベースのバッチ処理は、準リアルタイムという要件に適していません。ファイル処理には時間がかかり、レイテンシーが発生します。また、複数のアプリケーションが同時にデータにアクセスする際の効率性も劣ります。数十万のユーザーからのリアルタイムデータには適さないアーキテクチャです。
D. 取引データをAmazon DynamoDBに保存する。DynamoDBでルールを設定して、書き込み時に各取引から機密データを除去する。DynamoDB Streamsを使用して取引データを他のアプリケーションと共有する。
不正解 DynamoDBには書き込み時に機密データを自動的に除去するネイティブなルール機能は存在しません。DynamoDB Streamsはテーブルアイテムの変更を追跡する機能で、リアルタイムデータストリーミングや複数アプリケーションへの配信には最適化されていません。また、大量のトランザクションデータの取り込みには適していません。
全体的な説明
問われている要件
- 数百万の金融取引データの処理
- 複数の内部アプリケーションへの準リアルタイムデータ共有
- 機密データの除去処理
- ドキュメントデータベースでの低レイテンシー検索
- スケーラブルで高可用性のソリューション
前提知識
ストリーミングサービスの特徴について
- Amazon Kinesis Data Streamsはリアルタイムデータストリーミングに特化したサービスで、毎秒数百万のレコードを処理できます。シャードベースのスケーリングにより、データ量に応じて処理能力を調整できます。データは1日から365日まで保持され、複数のコンシューマーが同時にデータを処理できます。Lambda、EC2、EMRなどとの統合が可能で、リアルタイム分析や処理に最適です。
- Amazon Kinesis Data Firehoseは準リアルタイムデータ配信に特化したサービスで、データの変換と配信を自動化します。配信先はS3、Redshift、OpenSearch Service、Splunk、HTTP エンドポイントなどに限定されており、DynamoDBは直接サポートされていません。最低60秒のバッファリング時間があり、完全なリアルタイム処理には適していません。
データベースとストレージの特徴について
- Amazon DynamoDBはNoSQLドキュメントデータベースで、ミリ秒レベルの低レイテンシーを提供します。自動スケーリング機能により、トラフィック量に応じて処理能力を調整できます。DynamoDB Streamsは、テーブルアイテムの変更をキャプチャする機能で、データレプリケーションやトリガー処理に使用されます。
- Amazon S3は高耐久性オブジェクトストレージで、大容量データの保存に適していますが、リアルタイムアクセスやトランザクション処理には最適化されていません。
解くための考え方
この問題の核心は「準リアルタイム」と「DynamoDBへの保存」という2つの要件の両立です。まず、準リアルタイムという表現は通常Kinesis Data Firehoseと合致しますが、技術的制約によりFirehoseはDynamoDBを直接サポートしていません。一方、Kinesis Data Streamsはリアルタイム処理に対応し、Lambda統合によりDynamoDBへの書き込みが可能です。機密データの除去については、Lambdaが最適なソリューションを提供し、イベント駆動での処理により低レイテンシーを実現できます。
複数アプリケーションへのデータ共有では、Kinesisストリームの複数コンシューマー機能により、各アプリケーションが独立してデータを消費できます。スケーラビリティの観点では、Kinesis Data Streamsのシャード機能とDynamoDBの自動スケーリングにより、ピーク時の数十万ユーザーからのトラフィックにも対応できます。
アーキテクチャ図
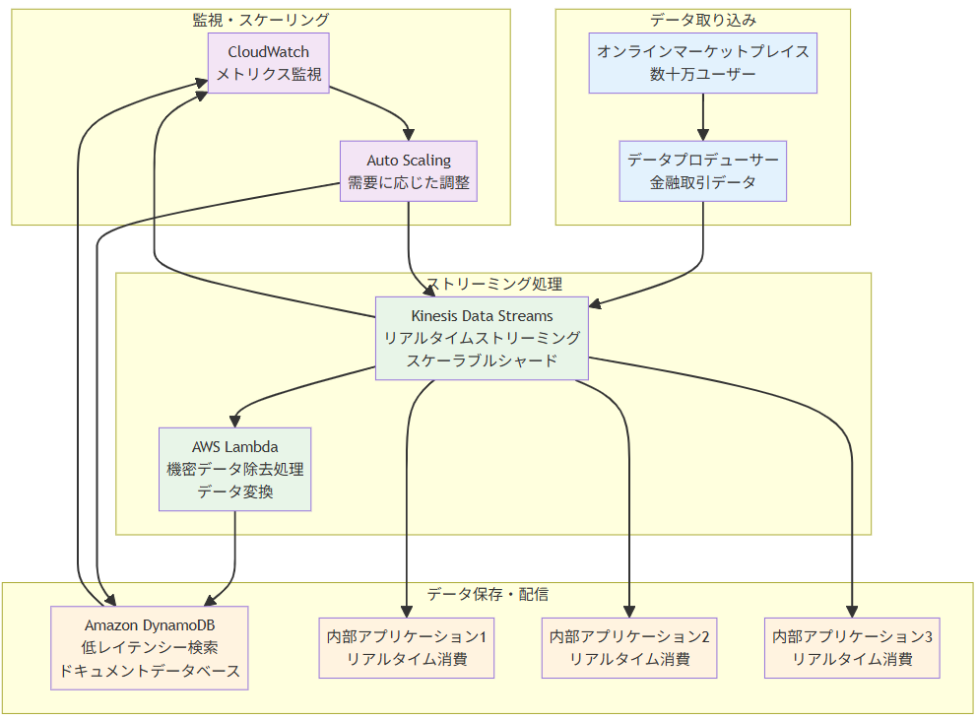
アーキテクチャ図の解説
リアルタイムストリーミングとデータ処理の流れ
オンラインマーケットプレイスから発生する数百万の金融取引データは、データプロデューサーを通じてKinesis Data Streamsにリアルタイムでストリーミングされます。Kinesis Data Streamsはスケーラブルなシャード機能により、ピーク時の大量トラフィックにも対応できます。ストリームされたデータはAWS Lambdaによってリアルタイムで処理され、機密データの除去や必要な変換が行われます。処理済みのデータはAmazon DynamoDBに保存され、低レイテンシーでの検索が可能になります。
複数アプリケーションへの同時配信と監視
Kinesis Data Streamsの複数コンシューマー機能により、3つの内部アプリケーションが同時にストリームからデータを消費できます。各アプリケーションは独立してデータを処理でき、それぞれの要件に応じたリアルタイム処理が可能です。CloudWatchによる監視とAuto Scalingの組み合わせにより、Kinesis ShardsとDynamoDBの処理能力を需要に応じて自動調整し、安定したパフォーマンスを維持します。この仕組みにより、準リアルタイムでのデータ共有と低レイテンシー検索の両方を実現できます。
他のソリューションとの比較
Kinesis Data Firehoseを使用する選択肢と比較すると、技術的制約が明確です。FirehoseはDynamoDBを直接の配信先としてサポートしておらず、S3やRedshiftなどの限定された配信先のみ対応しています。
また、Firehoseは最低60秒のバッファリング時間があり、完全なリアルタイム処理には適していません。DynamoDB Streamsを使用する選択肢では、テーブル変更の追跡機能しか提供されず、大量データの取り込みや複数アプリケーションへの配信には不適切です。バッチ処理の選択肢は、準リアルタイム要件を満たさず、運用複雑性も高くなります。
実装の考慮事項
実装時には、Kinesis Data Streamsのシャード数を適切に設計し、データ量とコンシューマー数に応じて調整する必要があります。Lambda関数では、機密データの除去ロジックを効率的に実装し、DynamoDBへの書き込み最適化を行うことが重要です。セキュリティ面では、IAM権限の適切な設定、データの暗号化、ネットワークセキュリティの実装が必要です。監視については、Kinesis メトリクス、Lambda 実行時間、DynamoDB スループットを継続的に監視し、パフォーマンスボトルネックを早期発見できるアラートを設定することが推奨されます。また、災害復旧のためのクロスリージョンレプリケーションやバックアップ戦略も考慮する必要があります。
参考資料
問題文:
ある企業が7つのAmazon EC2インスタンスを使用してAWS上でWebアプリケーションをホストしています。
この企業は、DNSクエリに対してすべての健全なEC2インスタンスのIPアドレスが返されることを要求しています。
この要件を満たすために使用すべきポリシーはどれですか。
選択肢:
A. 複数値回答ルーティングポリシー
B. 地理的位置ルーティングポリシー
C. レイテンシールーティングポリシー
D. シンプルルーティングポリシー
正解:A
A. 複数値回答ルーティングポリシー
正解 複数値回答ルーティングポリシーは、DNSクエリに対して最大8つの健全なレコードをランダムに選択して返します。ヘルスチェック機能と組み合わせることで、障害インスタンスを自動的に除外し、健全なインスタンスのIPアドレスのみを返すことができます。7つのEC2インスタンスという要件に最適です。
B. 地理的位置ルーティングポリシー
不正解 地理的位置ルーティングポリシーは、DNSクエリの送信元地域に基づいて特定のリソースを選択します。地域ごとに最適なリソースを返す設計で、特定地域のユーザーには決まったリソースのみが返されるため、すべての健全なインスタンスを返すという要件を満たせません。
C. レイテンシールーティングポリシー
不正解 レイテンシールーティングポリシーは、ユーザーから最も低い遅延でアクセス可能なリソースを選択してDNSレスポンスに含めます。最適なパフォーマンスを提供する単一または少数のリソースを返す設計で、すべての健全なインスタンスのIPアドレスを同時に返すという要件には適していません。
D. シンプルルーティングポリシー
不正解 シンプルルーティングポリシーは単一のリソースに対して複数のIPアドレスを設定できますが、ヘルスチェック機能がありません。すべてのIPアドレスが健全性に関係なく返されるため、障害インスタンスのIPも含まれてしまいます。健全なインスタンスのみを返すという要件を満たすことができません。
全体的な説明
問われている要件
- 7つのEC2インスタンスでのWebアプリケーション運用
- DNSクエリ応答でのすべての健全なインスタンスIP取得
- 障害インスタンスの自動除外機能
- 負荷分散またはフェイルオーバー対応のDNS設定
- Route 53ルーティングポリシーの最適選択
前提知識
Route 53ルーティングポリシーの種類と特徴について
- シンプルルーティングポリシーは最も基本的なルーティング方式で、1つのリソースに対して複数のIPアドレスを関連付けることができますが、ヘルスチェック機能は提供されず、すべてのIPアドレスがランダムな順序で返されます
- 複数値回答ルーティングポリシーはDNSクエリに対して最大8つの健全なレコードを返し、各レコードにヘルスチェックを関連付けることで、障害があるリソースを自動的に除外できます
- レイテンシールーティングポリシーは複数のリージョンでリソースを運用する場合に、ユーザーから最も低い遅延でアクセス可能なリソースを選択します
ヘルスチェック機能の重要性について
- Route 53ヘルスチェックは指定されたエンドポイントを定期的に監視し、HTTP、HTTPS、TCPプロトコルでの応答を確認します
- ヘルスチェックが失敗したリソースは自動的にDNS応答から除外され、トラフィックの分散先から排除されます
- 複数値回答ポリシーと組み合わせることで、常に健全なリソースのみがDNS応答に含まれることが保証されます
DNSによる負荷分散の仕組みについて
- DNS ベースの負荷分散では、クライアントが複数のIPアドレスを受信し、通常は最初のIPアドレスに接続を試行します
- 複数値回答ポリシーでは、IPアドレスがランダムな順序で返されるため、複数のクライアントからのリクエストが異なるインスタンスに分散されます
- この方式により、ハードウェアロードバランサーを使用せずにDNSレベルでの負荷分散が実現できます
解くための考え方
この問題の核心は「すべての健全なEC2インスタンス」のIPアドレスを返すという要件を理解することです。
まず、「健全な」という条件により、ヘルスチェック機能が必要であることが明確になります。シンプルルーティングポリシーはヘルスチェック機能がないため、この時点で除外されます。
次に、「すべての」という要件により、特定の条件(地理的位置、遅延)に基づいて一部のリソースのみを選択するポリシーは適さないことがわかります。レイテンシールーティングと地理的位置ルーティングは、最適化された単一または少数のリソースを返す設計のため除外されます。
複数値回答ルーティングポリシーは、ヘルスチェック機能と複数レコードの同時返却機能を組み合わせており、この要件に完全に適合します。7つのEC2インスタンスは、複数値回答ポリシーの最大8レコード制限内に収まります。
アーキテクチャ図
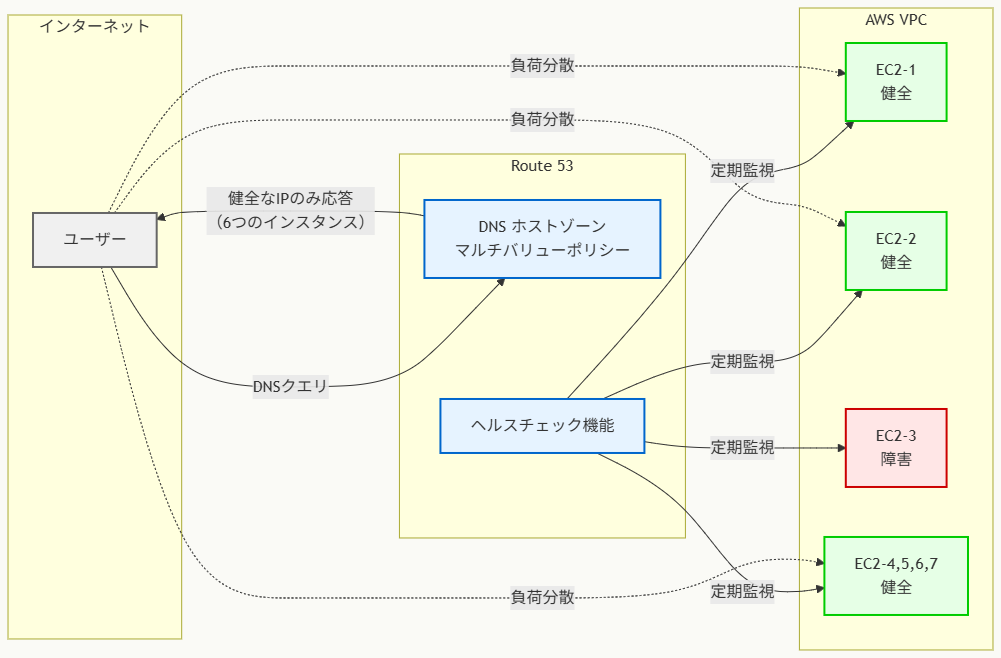
アーキテクチャ図の解説
複数値回答ポリシーによるDNS応答機能
このアーキテクチャでは、Route 53の複数値回答ポリシーが7つのEC2インスタンスに対応する複数のDNSレコードを管理しています。ユーザーからのDNSクエリに対して、健全なインスタンスのIPアドレスのみをランダムな順序で返します。
図の例では、EC2-3が障害状態のため、このインスタンスはDNS応答から自動的に除外され、残り6つの健全なインスタンスのIPアドレスが返されます。
ヘルスチェックによる自動障害検出
Route 53のヘルスチェック機能が各EC2インスタンスの状態を定期的に監視しています。HTTP/HTTPSプロトコルを使用してインスタンスの健全性を確認し、ヘルスチェックが失敗したインスタンスは自動的にDNS応答から除外される仕組みです。
このヘルスチェック機能により、障害インスタンスへの新規トラフィック送信を防ぎ、ユーザーエクスペリエンスの劣化を最小限に抑えることができます。
負荷分散とフェイルオーバーの実現
複数値回答ポリシーにより、複数のクライアントからのリクエストが健全なインスタンスに分散されます。DNSレベルでの負荷分散により、専用のロードバランサーを使用せずにトラフィック分散が実現され、インフラストラクチャのコストと複雑性を削減できます。
また、個別のインスタンス障害時には該当インスタンスが自動的にトラフィック分散から除外され、シームレスなフェイルオーバー機能も提供されます。
他のソリューションとの比較
シンプルルーティングポリシーは複数のIPアドレスを返すことができますが、ヘルスチェック機能がないため、障害インスタンスも含めてすべてのIPアドレスが返されてしまいます。
レイテンシールーティングポリシーは、地理的に分散したリソース間で最適なパフォーマンスを提供する単一のリソースを選択するため、複数インスタンスの同時活用には適していません。
地理的位置ルーティングポリシーも同様に、ユーザーの所在地に基づいて特定のリソースを選択する設計で、すべての健全なリソースを活用する要件とは異なります。
実装の考慮事項
実装時には、各EC2インスタンスに対して適切なヘルスチェック設定を行う必要があります。ヘルスチェックのパス(例:/health)、ポート番号、チェック間隔、失敗しきい値を慎重に設定し、アプリケーションの特性に合わせた監視を実現します。
また、DNS TTL(Time To Live)値の設定も重要で、短いTTL値により障害時の切り替え時間を短縮できますが、DNSクエリ頻度が増加します。
セキュリティ面では、ヘルスチェック用のエンドポイントが適切に保護され、かつRoute 53からのアクセスが許可されるようセキュリティグループを設定する必要があります。運用面では、ヘルスチェック結果とDNS応答状況の継続的な監視により、システム全体の健全性を確保することが推奨されます。
参考資料
問題文:
VPC-AのAmazon EC2インスタンスで動作するアプリケーションが、VPC-Bの別のEC2インスタンス内のファイルにアクセスする必要があります。両方のVPCは異なるAWSアカウントに配置されています。
ネットワーク管理者は、VPC-AからVPC-BのEC2インスタンスへの安全なアクセスを設定するソリューションを設計する必要があります。接続には単一障害点や帯域幅の制約があってはなりません。
これらの要件を満たすソリューションはどれですか。
選択肢:
A. VPC-Bに仮想プライベートゲートウェイをアタッチし、VPC-Aからのルーティングを設定します。
B. VPC-Bで動作するEC2インスタンス用にVPCゲートウェイエンドポイントを設定します。
C. VPC-Bで動作するEC2インスタンス用にプライベート仮想インターフェース(VIF)を作成し、VPC-Aから適切なルートを追加します。
D. VPC-AとVPC-B間でVPCピアリング接続を設定します。
正解:D
A. VPC-Bに仮想プライベートゲートウェイをアタッチし、VPC-Aからのルーティングを設定します。
不正解 仮想プライベートゲートウェイを使用する場合はVPN接続の設定が必要となり、追加の複雑性と潜在的な単一障害点を導入します。また、VPN接続には帯域幅制限があり、問題の要件である「帯域幅の制約がない」という条件を満たしません。設定と運用の複雑さも増加します。
B. VPC-Bで動作するEC2インスタンス用にVPCゲートウェイエンドポイントを設定します。
不正解 VPCゲートウェイエンドポイントはAmazon S3やDynamoDBへのアクセス専用のサービスで、EC2インスタンス間の通信には使用できません。この選択肢は技術的に実現不可能であり、問題で求められているVPC間のEC2インスタンス通信の要件を満たすことができません。
C. VPC-Bで動作するEC2インスタンス用にプライベート仮想インターフェース(VIF)を作成し、VPC-Aから適切なルートを追加します。
不正解 プライベート仮想インターフェース(VIF)はAWS Direct Connectを使用してオンプレミスインフラストラクチャとAWSを接続するためのサービスです。VPC間の通信には適用されず、この問題のシナリオには技術的に不適切です。また、Direct Connectは物理的な専用線接続を必要とするため、コストと複雑性が大幅に増加します。
D. VPC-AとVPC-B間でVPCピアリング接続を設定します。
正解 VPCピアリング接続は異なるAWSアカウント間のVPC間でも設定可能で、プライベートIPアドレスを使用した安全な通信を実現します。AWSの既存VPCインフラストラクチャを活用するため物理的なハードウェアに依存せず、単一障害点や帯域幅のボトルネックが発生しません。クロスアカウント接続にも対応しており、要件を完全に満たします。
全体的な説明
問われている要件
- 異なるAWSアカウントのVPC間でのEC2インスタンス通信の実現
- セキュアなアクセス(プライベートネットワーク経由での通信)
- 単一障害点の排除(高可用性の確保)
- 帯域幅制約のない通信(パフォーマンス要件)
- シンプルで効率的なネットワーク設計
前提知識
VPC間接続サービスの特徴について
- VPCピアリング接続は同一アカウント内だけでなく、異なるAWSアカウント間のVPCも接続可能で、プライベートIPアドレスを使用した直接通信を実現し、インターネットゲートウェイ、VPN、NATデバイスは不要です
- VPCピアリングはAWSの既存インフラストラクチャを活用するため、物理的なハードウェアに依存せず、単一障害点や帯域幅ボトルネックが発生しません
- 仮想プライベートゲートウェイはVPN接続やDirect Connect接続のためのAWS側のコンポーネントで、オンプレミスとAWS間の接続に使用されます
VPCエンドポイントの種類と用途について
- VPCゲートウェイエンドポイントはAmazon S3とDynamoDB専用のサービスで、VPC内からこれらのサービスにプライベートアクセスを提供しますが、EC2インスタンス間通信には使用できません
- VPCインターフェースエンドポイントは多数のAWSサービスへのプライベートアクセスを提供しますが、他のVPC内のEC2インスタンスへの接続には使用されません
Direct Connect関連サービスについて
- プライベート仮想インターフェース(VIF)はAWS Direct Connectの機能で、オンプレミスのプライベートネットワークとVPC間の専用接続を提供します
- Direct ConnectはVPC間通信ではなく、オンプレミス-AWS間の接続に特化したサービスで、物理的な専用線が必要です
解くための考え方
この問題では、異なるAWSアカウント間のVPC間通信という特殊な要件と、単一障害点・帯域幅制約がないという技術要件を同時に満たす必要があります。
まず、各選択肢の技術的適用可能性を評価する必要があります。VPCゲートウェイエンドポイントとプライベートVIFは、そもそもVPC間のEC2通信という用途に技術的に適合しないため除外されます。
残るVPCピアリングと仮想プライベートゲートウェイの比較では、要件の「単一障害点がない」「帯域幅制約がない」という条件が決定要因となります。VPCピアリングはAWSの分散インフラストラクチャを活用するため、これらの要件を満たします。
一方、仮想プライベートゲートウェイを使用したVPN接続は、ゲートウェイ自体が単一障害点となり、VPN接続の帯域幅制限も問題となります。また、異なるアカウント間でのVPCピアリングは AWS によって正式にサポートされており、設定も比較的簡単です。
アーキテクチャ図
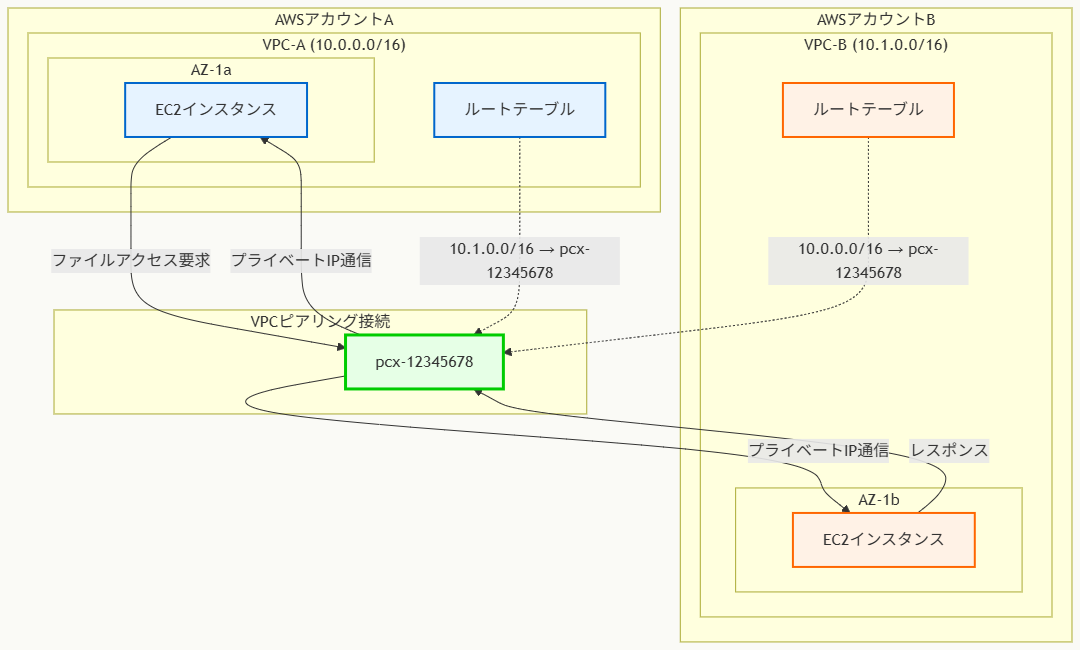
アーキテクチャ図の解説
VPCピアリング接続の基本構造
このアーキテクチャでは、異なるAWSアカウントのVPC-A(10.0.0.0/16)とVPC-B(10.1.0.0/16)間でVPCピアリング接続(pcx-12345678)を確立しています。VPCピアリング接続は論理的なネットワークリンクとして機能し、両VPC間でのプライベートIPアドレスを使用した直接通信を可能にします。この接続はAWSの分散インフラストラクチャ上で動作するため、物理的なハードウェアに依存せず、単一障害点が発生しません。
ルーティング設定とトラフィックフロー
各VPCのルートテーブルには、対向VPCのCIDRブロックに対するルートエントリが設定されます。VPC-Aからは宛先10.1.0.0/16をターゲットpcx-12345678に、VPC-Bからは宛先10.0.0.0/16を同じピアリング接続にルーティングします。EC2インスタンス間の通信は、このルーティング設定に従ってVPCピアリング接続を経由し、インターネットを通過することなく完全にプライベートネットワーク内で実行されます。
セキュリティとアクセス制御
通信を実現するためには、ルーティング設定に加えて、各EC2インスタンスのセキュリティグループとネットワークACLで適切な通信許可設定が必要です。セキュリティグループでは対向VPCのCIDRブロックからの必要なポート(ファイルアクセスに必要なプロトコル)への接続を許可し、ネットワークACLでもサブネットレベルでの通信を許可する必要があります。この設定により、セキュアでありながら効率的なクロスアカウントVPC間通信が実現されます。
他のソリューションとの比較
VPN接続を使用した仮想プライベートゲートウェイソリューションは、追加のVPNトンネル設定が必要で運用が複雑になります。また、VPNゲートウェイ自体が単一障害点となり、暗号化処理による帯域幅制限も発生します。
Direct Connectとプライベート仮想インターフェースの組み合わせは、オンプレミス-AWS間接続用の技術で、VPC間通信には適用されません。
VPCエンドポイントは特定のAWSサービス(S3、DynamoDB等)への接続専用で、EC2インスタンス間通信には使用できません。
実装の考慮事項
VPCピアリング接続の実装では、まず両アカウント間でのピアリング要求と承認プロセスが必要です。要求側アカウントがピアリング接続を作成し、受信側アカウントが承認することで接続が確立されます。
CIDRブロックの重複がないことを事前に確認し、ルートテーブルへの適切なエントリ追加、セキュリティグループとネットワークACLの設定調整を行います。
また、DNSホスト名解決を有効にすることで、プライベートIPアドレスだけでなくプライベートDNS名を使用した通信も可能になります。コスト面では、同一アベイラビリティーゾーン内のピアリング通信は無料で、異なるアベイラビリティーゾーン間では標準的なデータ転送料金が適用されます。
参考資料
- VPC ピアリングとは – Amazon Virtual Private Cloud
- 別の AWS アカウントの VPC とのピアリング接続の作成 – Amazon Virtual Private Cloud
- VPC ピアリング接続のルートテーブルの更新 – Amazon Virtual Private Cloud
- VPC ピアリング接続のセキュリティグループルールの更新 – Amazon Virtual Private Cloud
- VPC エンドポイント – Amazon Virtual Private Cloud
- 仮想プライベートゲートウェイ – AWS Site-to-Site VPN
- 仮想インターフェイス – AWS Direct Connect
- VPC ピアリング接続の料金 – Amazon VPC 料金
筆者のUdemy講師ページはこちら。
スポンサーリンク
以下スポンサーリンクです。
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。