AWS DVA無料問題集です。正解と解説を確認する際は右側のボタンを押下してください。
問題集の完全版は以下Udemyにて発売しているためお買い求めください。問題集への質問はUdemyのQA機能もしくはUdemyのメッセージにて承ります。Udemyの問題1から15問抜粋しております。
多くの方にご好評いただき、講師評価 4.5/5.0 を獲得できております。ありがとうございます。

特別価格: 通常2,600円 → 1,500円
講師クーポン適用で42%OFF
講師クーポン【全出題範囲を網羅+詳細な解説】AWS DVA-C02日本語実践問題集260問(ディベロッパーアソシエイト)

問題文:
AWS Lambda関数はイベントを処理するために同期的に呼び出されることがありますが、時折、Lambda関数の処理が失敗することがあります。この場合、失敗したイベントを収集して分析し、問題を修正する必要があります。 開発工数を最小限に抑えつつ、この要件を満たす最適な方法を選択してください。
選択肢:
A. 失敗したイベントに対して再試行するAWS Step Functionsのワークフローを構築します。
B. デッドレターキューを追加し、Amazon Simple Notification Service(SNS)FIFOトピックに失敗したメッセージを送信します。
C. デッドレターキューを追加し、Amazon Simple Queue Service(SQS)スタンダードキューに失敗したメッセージを送信します。
D. Lambda関数の全イベントに対してログ記録ステートメントを追加し、AWS CloudTrailのログをフィルタリングしてエラーを検出します。
正解: C
A. 失敗したイベントに対して再試行するAWS Step Functionsのワークフローを構築します。
不正解 Step Functionsは複雑なワークフローの管理には優れていますが、単純な失敗イベントの収集という要件に対しては過剰なソリューションです。ワークフローの設計、状態遷移の定義、エラーハンドリングの実装など、多くの開発工数が必要になります。また、Step Functionsは実行回数に応じて課金されるため、コスト面でも不利です。さらに、問題の要件は「失敗したイベントを収集して分析する」ことであり、再試行機能は求められていません。
B. デッドレターキューを追加し、Amazon Simple Notification Service(SNS)FIFOトピックに失敗したメッセージを送信します。
不正解 SNS FIFOトピックは、メッセージの順序保証と重複排除が必要な場合に使用されますが、失敗イベントの収集という用途には適していません。SNSは本来、複数のサブスクライバーにメッセージを配信するためのサービスです。失敗したイベントを一時的に保存して後で分析するという要件に対しては、メッセージを永続化できるSQSの方が適切です。また、SNS FIFOトピックはSQSスタンダードキューと比較してコストが高く、この用途には不要な機能に対して余分な費用を支払うことになります。
C. デッドレターキューを追加し、Amazon Simple Queue Service(SQS)スタンダードキューに失敗したメッセージを送信します。
正解 デッドレターキュー(DLQ)は、Lambda関数の処理に失敗した際に、そのイベントを自動的に指定されたSQSキューに送信する仕組みです。SQSスタンダードキューは高いスループットと低コストを提供し、失敗したイベントを確実に保存できます。設定も簡単で、Lambda関数の設定画面でDLQとしてSQSキューを指定するだけで済むため、開発工数を最小限に抑えることができます。また、SQSに蓄積された失敗イベントは後からいつでも取得・分析が可能です。
D. Lambda関数の全イベントに対してログ記録ステートメントを追加し、AWS CloudTrailのログをフィルタリングしてエラーを検出します。
不正解 CloudTrailはAWS APIの呼び出しを記録するサービスであり、Lambda関数内部の処理結果やエラー詳細は記録されません。Lambda関数のエラー情報を取得するにはCloudWatch Logsが適切です。また、全イベントにログ記録ステートメントを追加するのは、Lambda関数のコード修正が必要で開発工数が増加します。さらに、ログからエラーを検出・分析するには手動での作業が多く、効率的ではありません。失敗したイベント自体のデータも取得しにくく、問題の根本原因分析が困難です。
全体的な説明
問われている要件
- Lambda関数が処理に失敗した際に、失敗したイベントを収集できること
- 収集した失敗イベントを後から分析できること
- 実装に必要な開発工数を最小限に抑えること
前提知識
デッドレターキュー(DLQ)とは
デッドレターキューは、メッセージ処理システムにおいて処理に失敗したメッセージを別の場所に隔離・保存する仕組みです。AWS Lambdaでは、関数の実行に失敗した際に、そのイベントデータを指定されたSQSキューまたはSNSトピックに自動的に送信できます。
Lambda関数のエラーハンドリング
Lambda関数が同期的に呼び出される場合、処理が失敗するとエラーレスポンスが呼び出し元に返されます。デッドレターキューが設定されていると、失敗したイベントのデータが自動的に指定された宛先に送信されるため、データの損失を防げます。
SQSとSNSの違い
- SQS(Simple Queue Service):メッセージを一時的に保存するキューサービス。メッセージは取得されるまで保持され、1対1のメッセージ配信に適しています
- SNS(Simple Notification Service):複数の宛先にメッセージを配信する通知サービス。1対多のメッセージ配信に適しています
各サービスの特徴
- SQSスタンダードキュー:高いスループット、低コスト、メッセージの永続化が可能
- SNS FIFOトピック:メッセージの順序保証と重複排除機能を提供、コストは高め
- Step Functions:複雑なワークフローの管理とエラーハンドリングが可能、設計が複雑
- CloudTrail:AWS APIの呼び出しログを記録、Lambda関数内部の処理は記録しない
解くための考え方
この問題では、失敗イベントの収集という要件を満たしつつ、開発工数を最小化する方法を選択する必要があります。
デッドレターキューとSQSスタンダードキューの組み合わせは、Lambda関数の設定画面での簡単な設定変更のみで実現でき、失敗したイベントを確実に保存できます。
他の選択肢は、要件に対して過剰に複雑であったり、適切なサービスの組み合わせではないため、開発工数やコストの観点で不適切です。
参考資料
問題文:
開発者が、Amazon S3 バケットへのアクセスを提供するために、以下の IAM ポリシーを作成しました。

s3:GetObject および s3:PutObject アクションに関して、ポリシーはどのアクセスを許可しますか?
選択肢:
A. 「secrets」で始まるオブジェクトを除く「DOC-EXAMPLE-BUCKET」バケット内のすべてのオブジェクトへのアクセス
B. 「DOC-EXAMPLE-BUCKET」バケットを除くすべてのバケットへのアクセス
C. 「DOC-EXAMPLE-BUCKET/secrets」バケットを除く「DOC-EXAMPLE-BUCKET」で始まるすべてのバケットへのアクセス
D. 「DOC-EXAMPLE-BUCKET」バケット内のすべてのオブジェクトへのアクセスと、「secrets」で始まる「DOC-EXAMPLE-BUCKET」バケット内のオブジェクトのすべての S3 アクションへのアクセス
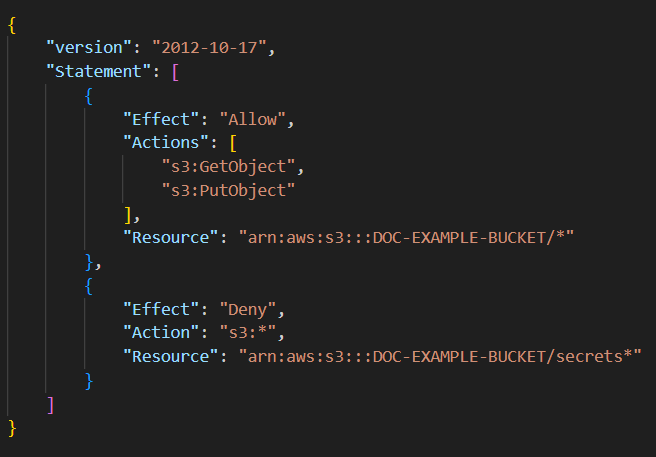
正解: A
A. 「secrets」で始まるオブジェクトを除く「DOC-EXAMPLE-BUCKET」バケット内のすべてのオブジェクトへのアクセス
正解 このポリシーの動作を正確に反映しています。1つ目のAllowステートメントはDOC-EXAMPLE-BUCKET内のすべてのオブジェクトに対してs3:GetObjectおよびs3:PutObjectアクションを許可します。しかし、2つ目のDenyステートメントにより「secrets」で始まるオブジェクトに対してはすべてのS3アクションが拒否されます。IAMの評価論理では明示的な拒否が許可より優先されるため、結果として「secrets」で始まるオブジェクト以外のすべてのオブジェクトにアクセス可能となります。
B. 「DOC-EXAMPLE-BUCKET」バケットを除くすべてのバケットへのアクセス
不正解 このポリシーの適用対象を誤解しています。ポリシー内のResourceで指定されているのは「arn:aws:s3:::DOC-EXAMPLE-BUCKET/*」であり、このポリシーはDOC-EXAMPLE-BUCKETにのみ適用されます。他のバケットには一切影響を与えません。また、DOC-EXAMPLE-BUCKETを除外するのではなく、DOC-EXAMPLE-BUCKETに対してアクセスを制御しています。
C. 「DOC-EXAMPLE-BUCKET/secrets」バケットを除く「DOC-EXAMPLE-BUCKET」で始まるすべてのバケットへのアクセス
不正解 この選択肢は「DOC-EXAMPLE-BUCKET/secrets」をバケット名として誤解しています。実際には「secrets」はオブジェクトキーのプレフィックスであり、バケット名ではありません。S3では「DOC-EXAMPLE-BUCKET/secrets」というバケット名は存在せず、Denyステートメントの対象は「DOC-EXAMPLE-BUCKET」バケット内の「secrets」で始まるオブジェクトです。
D. 「DOC-EXAMPLE-BUCKET」バケット内のすべてのオブジェクトへのアクセスと、「secrets」で始まる「DOC-EXAMPLE-BUCKET」バケット内のオブジェクトのすべての S3 アクションへのアクセス
不正解 この選択肢は「secrets」で始まるオブジェクトに対するすべてのS3アクションが許可されているという誤った解釈を示しています。実際には、Denyステートメントにより「secrets」で始まるオブジェクトに対してはすべてのS3アクション(s3:*)が明示的に拒否されます。IAMでは明示的な拒否が最も高い優先度を持つため、これらのオブジェクトにはアクセスできません。
全体的な説明
問われている要件
- 提示されたIAMポリシーの動作を正確に理解する
- s3:GetObjectとs3:PutObjectアクションに関して、どのアクセスが許可されるかを特定する
- AllowとDenyステートメントの組み合わせによる効果を判断する
前提知識
IAMポリシーの基本構造 IAMポリシーはJSON形式で記述され、以下の要素から構成されます:
- Version:ポリシー言語のバージョン(通常は2012-10-17)
- Statement:権限設定を定義する配列
- Effect:AllowまたはDenyを指定
- Action:実行を許可または拒否するAPIアクション
- Resource:対象となるAWSリソースのARN
IAMポリシーの評価論理 IAMでは以下の優先順位でアクセス許可が決定されます:
- 明示的な拒否(Explicit Deny):最も高い優先度
- 明示的な許可(Explicit Allow):中程度の優先度
- 暗黙的な拒否(Implicit Deny):デフォルト状態
つまり、どこかでDenyが指定されていれば、他の場所でAllowが指定されていても、そのアクションは拒否されます。
S3のアクションとリソース
- s3:GetObject:オブジェクトの読み取り権限
- s3:PutObject:オブジェクトの書き込み権限
- s3:*:すべてのS3アクションを表すワイルドカード
S3のARN形式
- バケット:arn:aws:s3:::bucket-name
- オブジェクト:arn:aws:s3:::bucket-name/object-key
- バケット内すべてのオブジェクト:arn:aws:s3:::bucket-name/*
プレフィックスマッチング 「secrets*」はsecretsで始まるすべてのオブジェクトキーにマッチします。例えば:
- secrets/file1.txt
- secretsdata.json
- secrets-backup/archive.zip
解くための考え方
まず、ポリシー内の各ステートメントを個別に分析します。 1つ目のAllowステートメントはDOC-EXAMPLE-BUCKET内のすべてのオブジェクトに対してGetObjectとPutObjectを許可します。
次に、2つ目のDenyステートメントを確認します。 これは同じバケット内の「secrets」で始まるオブジェクトに対してすべてのS3アクションを拒否します。
IAMの評価論理では明示的な拒否が最優先されるため、最終的な結果は「secrets」で始まるオブジェクト以外へのアクセスが許可されます。
参考資料
問題文:
開発チームは、継続的インテグレーション / 継続的デリバリー (CI/CD) パイプラインを構築したいと考えています。チームは AWS CodePipeline を使用して、コードのビルドとデプロイを自動化しています。さらに、アーティファクトを EC2 インスタンスとオンプレミスサーバーの両方にデプロイ したいと考えています。 アプリケーションアーティファクトをデプロイするための最適な AWS サービスを選択してください。
選択肢:
A. AWS CodeCommit
B. Amazon CodeGuru
C. AWS CodeDeploy
D. AWS CodeArtifact
正解: C
A. AWS CodeCommit
不正解 AWS CodeCommitは、Gitベースのソースコード管理サービスです。プライベートGitリポジトリをクラウド上で提供し、チームでのコラボレーション、ブランチ管理、マージリクエスト機能などを支援します。CodeCommitはCI/CDパイプラインのソースステージとして重要な役割を果たしますが、アプリケーションのビルドやデプロイメント機能は提供していません。コードの保存と管理に特化したサービスであり、アーティファクトのデプロイには適していません。
B. Amazon CodeGuru
不正解 Amazon CodeGuruは機械学習を活用したコード品質とアプリケーションパフォーマンスの改善サービスです。CodeGuru ReviewerはコードレビューとJavaアプリケーションのセキュリティ分析を行い、CodeGuru Profilerはランタイムパフォーマンスの分析と最適化を支援します。これらの機能はコード品質向上には有効ですが、アプリケーションアーティファクトをEC2インスタンスやオンプレミスサーバーにデプロイする機能は提供していません。CI/CDパイプラインでのデプロイステージには適用できません。
C. AWS CodeDeploy
正解 AWS CodeDeployは、アプリケーションのデプロイメント自動化に特化したマネージドサービスです。Amazon EC2インスタンス、オンプレミスサーバー、AWS Lambda関数、Amazon ECSサービスに対してアプリケーションを自動デプロイできます。Blue/Greenデプロイメント、ローリングデプロイメント、インプレースデプロイメントなど複数のデプロイ戦略をサポートし、デプロイ中の自動ロールバック機能も提供します。CodePipelineとのネイティブ統合により、CI/CDパイプラインのデプロイステージとして簡単に組み込むことができます。
D. AWS CodeArtifact
不正解 AWS CodeArtifactは、ソフトウェア開発で使用される依存関係やパッケージを安全に保存・管理・共有するためのパッケージリポジトリサービスです。npm、pip、Maven、NuGetなどの一般的なパッケージマネージャーと統合でき、組織内でのパッケージ管理を簡素化します。しかし、アプリケーションアーティファクトを実際のサーバー環境にデプロイする機能は持っていません。CodeArtifactはパッケージの保存と配布に特化しており、デプロイメント自動化には別のサービスが必要です。
全体的な説明
問われている要件
- CI/CDパイプラインでのデプロイメント自動化
- Amazon EC2インスタンスとオンプレミスサーバーの両方への対応
- AWS CodePipelineとの統合によるアーティファクトデプロイ
- 継続的デリバリープロセスの効率化
前提知識
AWS CodeDeployの概要
AWS CodeDeployは、アプリケーションのデプロイメントを自動化するフルマネージドサービスです:
- 多様な環境対応: EC2、オンプレミス、Lambda、ECSへのデプロイメント
- デプロイ戦略: Blue/Green、ローリング、インプレース、カナリアデプロイメント
- 自動ロールバック: デプロイ失敗時の自動的な前バージョンへの復旧
- 統合性: CodePipelineやその他のCI/CDツールとのシームレスな統合
EC2インスタンスへのデプロイメント
EC2インスタンスでのCodeDeploy利用には以下が必要です:
- CodeDeployエージェント: インスタンス上で動作するデプロイメント処理プログラム
- IAMサービスロール: CodeDeployがEC2インスタンスにアクセスするための権限
- アプリケーション仕様ファイル: appspec.ymlによるデプロイ手順の定義
- デプロイグループ: デプロイ対象インスタンスの論理的なグループ化
オンプレミスサーバーへのデプロイメント
オンプレミス環境では追加の設定が必要です:
- インスタンス登録: オンプレミスサーバーをCodeDeployに登録
- タグベース管理: サーバーの分類と管理のためのタグ付け
- ネットワーク接続: AWSサービスへのHTTPS接続確保
- 認証設定: IAMユーザーまたはロールによる認証
CI/CDパイプラインでの統合
CodePipelineとCodeDeployの統合により以下が実現できます:
- 自動トリガー: ソースコード変更時の自動デプロイ開始
- ステージ管理: 開発、ステージング、本番環境への段階的デプロイ
- 承認プロセス: 手動承認ステップの組み込み
- 並列デプロイ: 複数環境への同時デプロイメント
デプロイメント戦略
CodeDeployは複数のデプロイメント戦略を提供します:
- インプレースデプロイメント: 既存インスタンス上でのアプリケーション更新
- Blue/Greenデプロイメント: 新しい環境でのテスト後のトラフィック切り替え
- ローリングデプロイメント: インスタンスを段階的に更新
- カナリアデプロイメント: 一部のトラフィックで新バージョンをテスト
解くための考え方
CI/CDパイプラインでEC2インスタンスとオンプレミスサーバーの両方にデプロイするには、AWS CodeDeployが最適な選択です。
CodeDeployは、これら両方の環境に対応した唯一のAWSマネージドデプロイメントサービスです。CodePipelineとのネイティブ統合により、ソースコード変更から本番環境デプロイまでの全プロセスを自動化できます。
Blue/Greenデプロイメントやローリングデプロイメントなどの高度なデプロイ戦略により、本番環境でのリスクを最小化しながら継続的デリバリーを実現できます。また、自動ロールバック機能により、問題発生時の迅速な復旧も可能です。
他の選択肢は、コード品質向上(CodeGuru)、パッケージ管理(CodeArtifact)、ソースコード管理(CodeCommit)に特化しており、デプロイメント自動化という要件を満たしません。
参考資料
問題文:
開発者は、EC2インスタンスが Amazon CloudWatch にカスタムメトリクスを送信する必要がある Auto Scaling グループを作成しています。 CloudWatch PUT リクエストを認証する最も安全な方法を選択してください。
選択肢:
A. PutMetricData 権限を持つ IAM ユーザーを作成し、Auto Scaling 起動テンプレートを修正して、ユーザー認証情報をインスタンスユーザーデータに挿入します。
B. PutMetricData 権限を持つ IAM ユーザーを作成し、ユーザー認証情報をプライベートリポジトリに配置します。必要に応じて、アプリケーションに認証情報をプルさせます。
C. CloudWatch メトリクスポリシーを変更して、Auto Scaling グループのインスタンスに PutMetricData 権限を許可しています。
D. PutMetricData 権限を持つ IAM ロールを作成し、そのロールを使用してインスタンスを起動するように Auto Scaling 起動テンプレートを変更します。
正解: D
A. PutMetricData 権限を持つ IAM ユーザーを作成し、Auto Scaling 起動テンプレートを修正して、ユーザー認証情報をインスタンスユーザーデータに挿入します。
不正解 この方法は重大なセキュリティリスクを伴います。IAMユーザーの認証情報(アクセスキーとシークレットキー)をユーザーデータに含めることは、認証情報の漏洩につながる可能性が高いです。ユーザーデータはプレーンテキストで保存され、EC2インスタンスのメタデータサービス経由でアクセス可能なため、インスタンスにアクセスできる任意のユーザーや悪意のあるプロセスが認証情報を取得できてしまいます。また、起動テンプレートやスナップショット、ログにも認証情報が残る可能性があります。
B. PutMetricData 権限を持つ IAM ユーザーを作成し、ユーザー認証情報をプライベートリポジトリに配置します。必要に応じて、アプリケーションに認証情報をプルさせます。
不正解 認証情報をプライベートリポジトリに保存することは、非常に深刻なセキュリティリスクです。リポジトリへのアクセス権を持つ開発者や、リポジトリが侵害された場合に、認証情報が露出する可能性があります。また、バージョン管理システムの履歴に認証情報が残り続けるため、削除が困難になります。さらに、認証情報の定期的なローテーション、配布、更新などの管理負荷も発生します。この方法はAWSセキュリティベストプラクティスに反しています。
C. CloudWatch メトリクスポリシーを変更して、Auto Scaling グループのインスタンスに PutMetricData 権限を許可しています。
不正解 「CloudWatch メトリクスポリシー」という概念はAWSには存在しません。CloudWatchはメトリクスの収集と監視を行うサービスですが、IAMのようなアクセス制御機能は持っていません。EC2インスタンスにAWSサービスへのアクセス権限を付与するには、IAMロールまたはIAMユーザーの認証情報を使用する必要があります。
D. PutMetricData 権限を持つ IAM ロールを作成し、そのロールを使用してインスタンスを起動するように Auto Scaling 起動テンプレートを変更します。
正解 この方法はAWSのセキュリティベストプラクティスに完全に準拠した最も安全なアプローチです。IAMロールをEC2インスタンスに関連付けることで、インスタンス上のアプリケーションがAWS STSを通じて一時的な認証情報を自動取得できます。これらの認証情報は定期的に自動更新され、手動管理が不要です。認証情報がコードやファイルに埋め込まれることがないため、漏洩リスクが最小化されます。また、IAMロールの権限は最小権限の原則に従って細かく制御できます。
全体的な説明
問われている要件
- EC2インスタンスからCloudWatchへのカスタムメトリクス送信
- Auto Scalingグループでのセキュアな認証方法の実装
- CloudWatch PutMetricData APIの安全な利用
- 最小権限の原則に基づくアクセス制御の確立
前提知識
IAMロールとEC2インスタンスプロファイル
IAMロールは、AWSリソースに一時的な権限を付与するためのAWSのアイデンティティです:
- 一時的認証情報: STSによって発行される時限付きのアクセスキー
- 自動ローテーション: 認証情報が定期的に自動更新される
- インスタンスプロファイル: EC2インスタンスにIAMロールを関連付けるためのコンテナ
- メタデータサービス: EC2インスタンス内から認証情報を安全に取得
AWS Security Token Service (STS)
STSは一時的なセキュリティ認証情報を提供するサービスです:
- AssumeRole: IAMロールを引き受けて一時認証情報を取得
- 認証情報の有効期限: 通常15分から12時間の範囲で設定可能
- 最小権限: 必要最小限の権限のみを付与
- 監査: CloudTrailによるAPI呼び出しの完全な監査証跡
CloudWatchカスタムメトリクス
CloudWatchカスタムメトリクスは、アプリケーション固有の監視データを送信する機能です:
- PutMetricData API: カスタムメトリクスをCloudWatchに送信
- メトリクス名前空間: カスタムメトリクスを整理するための論理的グループ
- ディメンション: メトリクスをフィルタリングするためのキー値ペア
- 集計: 時間ベースでのメトリクス値の集計
Auto Scaling起動テンプレート
起動テンプレートは、EC2インスタンスの起動設定を定義するリソースです:
- IAMインスタンスプロファイル: インスタンスに関連付けるIAMロールを指定
- セキュリティグループ: ネットワークアクセス制御
- ユーザーデータ: インスタンス起動時に実行されるスクリプト
- タグ: リソース管理のためのメタデータ
解くための考え方
EC2インスタンスが安全にAWSサービスにアクセスするためには、IAMロールの使用が絶対的なベストプラクティスです。
IAMロールを使用することで、認証情報のハードコーディング、手動管理、漏洩リスクを完全に排除できます。EC2インスタンスはメタデータサービスを通じて自動的に一時認証情報を取得し、AWS STSによって定期的に更新されます。
Auto Scaling環境では、新しく作成されるインスタンスも自動的に同じロールを継承するため、スケーラビリティとセキュリティの両方が確保されます。起動テンプレートでIAMインスタンスプロファイルを指定することで、すべてのインスタンスが一貫したセキュリティ設定で起動されます。
最小権限の原則に従い、CloudWatch PutMetricData権限のみを持つ専用のIAMロールを作成することで、セキュリティリスクを最小化できます。
参考資料
問題文:
開発者は、お客様の注文を保存するためにOrdersというDynamoDBテーブルを使用しています。このテーブルでは、OrderIdがパーティションキーですが、ソートキーは設定されていません。テーブルには10万件以上のレコードが保存されており、OrderSource属性の値がMobileAppのレコードを効率よく取得する機能を追加する必要があります。最も効率的にこの要件を満たす方法を選んでください。
選択肢:
A. OrderSourceをソートキーとしてグローバルセカンダリインデックス(GSI)を作成し、MobileAppをキーとしてクエリ操作を実行します。
B. OrderSourceをパーティションキーとしてグローバルセカンダリインデックス(GSI)を作成し、MobileAppをキーとしてクエリ操作を実行します。
C. OrderSourceをパーティションキーとしてローカルセカンダリインデックス(LSI)を作成し、MobileAppをキーとしてクエリ操作を実行します。
D. OrdersテーブルでScan操作を実行し、QueryFilterを使用してOrderSource属性がMobileAppの項目のみをフィルタリングします。
正解: B
A. OrderSourceをソートキーとしてグローバルセカンダリインデックス(GSI)を作成し、MobileAppをキーとしてクエリ操作を実行します。
不正解 GSIでソートキーとしてOrderSourceを設定する場合、必ずパーティションキーも指定する必要があります。DynamoDBでは、Query操作を実行する際に必ずパーティションキーの値を指定する必要があり、ソートキーのみでのクエリはできません。この設定では、OrderSource = MobileAppという条件でクエリを実行するためには、パーティションキーの値も同時に指定する必要があり、効率的な検索ができません。また、どの属性をパーティションキーにするかが不明確で、実装が複雑になります。
B. OrderSourceをパーティションキーとしてグローバルセカンダリインデックス(GSI)を作成し、MobileAppをキーとしてクエリ操作を実行します。
正解 GSIを作成することで、既存のテーブル構造を変更することなく、新しいアクセスパターンに対応できます。OrderSourceをパーティションキーとしてGSIを作成すると、OrderSource = MobileAppという条件で効率的なQuery操作が可能になります。 Query操作はScan操作と比較して圧倒的に高速で、消費するRCUも少なく済みます。GSIは既存のテーブルに対して後から追加可能で、ダウンタイムなしで運用できます。また、GSIには独自のプロビジョニング設定があるため、メインテーブルとは独立してキャパシティを管理できます。
C. OrderSourceをパーティションキーとしてローカルセカンダリインデックス(LSI)を作成し、MobileAppをキーとしてクエリ操作を実行します。
不正解 LSI(ローカルセカンダリインデックス)には重要な制約があります。LSIは、メインテーブルと同じパーティションキーを使用し、異なるソートキーを設定する機能です。つまり、LSIではOrderIdがパーティションキーとして固定され、OrderSourceはソートキーとしてのみ設定可能です。この場合、クエリ時に必ず特定のOrderIdを指定する必要があり、OrderSourceの値のみでの検索はできません。また、LSIはテーブル作成時にのみ定義可能で、既存のテーブルに後から追加することはできません。この選択肢では、そもそもLSIの基本的な仕組みを誤解しています。
D. OrdersテーブルでScan操作を実行し、QueryFilterを使用してOrderSource属性がMobileAppの項目のみをフィルタリングします。
不正解 Scan操作は、テーブル内のすべてのアイテムを一つずつ確認する全体検索を行う操作です。10万件以上のレコードがあるテーブルに対してScan操作を実行すると、以下の問題が発生します。 まず、パフォーマンスが非常に悪く、レスポンス時間が長くなります。全データを読み取る必要があるため、読み込み容量単位(RCU)の消費量が非常に多くなり、コストが高額になります。 また、Scan操作では結果セットが大きすぎる場合に複数回のページネーションが必要になり、アプリケーションの実装も複雑になります。QueryFilterという用語も正確ではなく、ScanにおけるフィルタリングはFilterExpressionを使用します。
全体的な説明
問われている要件
- DynamoDBテーブルから特定の属性値(
OrderSource = MobileApp)を持つレコードを効率的に取得すること - 10万件以上の大規模データセットに対して高いパフォーマンスを実現すること
- 既存のテーブル設計を大幅に変更せずに新しいアクセスパターンに対応すること
前提知識
DynamoDBの基本構造
DynamoDBテーブルは以下の要素で構成されます:
パーティションキー(必須):テーブル内でアイテムを一意に識別するか、ソートキーと組み合わせて識別します
ソートキー(オプション):パーティションキーと組み合わせて複合主キーを形成し、同一パーティション内でのソート順を定義します
属性:アイテムに含まれるデータフィールドで、様々なデータ型をサポートします
クエリ操作とスキャン操作の違い
Query操作:
- パーティションキーの値を指定して、特定のパーティション内のアイテムを効率的に取得
- オプションでソートキーの条件も指定可能
- インデックスを活用するため高速で低コスト
- 結果は常にソート済み
Scan操作:
- テーブル全体またはインデックス全体を順次読み取り
- フィルタ条件に一致するアイテムのみを返す
- 全データを読み取るため低速で高コスト
- 結果の順序は保証されない
グローバルセカンダリインデックス(GSI)
GSIは、メインテーブルとは異なるパーティションキーとソートキーを持つインデックスです:
特徴:
- 既存テーブルに後から追加可能
- メインテーブルとは独立したキャパシティ設定
- 最大20個まで作成可能
- 非同期で更新される(結果整合性)
利点:
- 新しいアクセスパターンに対応
- 効率的なクエリが可能
- スケーラブルな設計
制約:
- 追加のストレージコストが発生
- 書き込み時に追加のWCUを消費
- 強整合性読み込みは不可
ローカルセカンダリインデックス(LSI)
LSIは、メインテーブルと同じパーティションキーを使用し、異なるソートキーを持つインデックスです:
特徴:
- テーブル作成時のみ定義可能
- メインテーブルと同じキャパシティを共有
- 最大10個まで作成可能
- 強整合性読み込みが可能
制約:
- パーティションサイズ上限(10GB)
- 既存テーブルに追加不可
- パーティションキーは変更不可
DynamoDBのパフォーマンス最適化
効率的なアクセスパターンを実現するための基本原則:
- 適切なパーティションキーの選択(均等な分散)
- ホットパーティションの回避
- インデックスの戦略的活用
- 不要なScan操作の回避
容量単位とコスト
読み込み容量単位(RCU):
- 1RCU = 最大4KBのアイテムに対する強整合性読み込み1回
- 結果整合性読み込みの場合は2回
書き込み容量単位(WCU):
- 1WCU = 最大1KBのアイテムに対する書き込み1回
GSI使用時は、インデックス用の追加RCU/WCUが必要です。
解くための考え方
この問題では、既存のパーティションキー(OrderId)では効率的に検索できない属性(OrderSource)に基づく新しいアクセスパターンが必要です。
Scan操作は全データを読み取るため、大規模データセットでは非効率的です。
GSIを活用することで、既存テーブル構造を維持しながら新しいクエリパターンを効率的に実現できます。
LSIは既存テーブルには追加できず、また異なるパーティションキーを設定することもできないため、この要件には適用できません。
参考資料
問題文:
ある企業では、毎日パートナーから注文のバッチを受け取るアプリケーションを運用しています。このアプリケーションはAWS Lambda関数を使ってバッチを処理します。ただし、バッチに注文が含まれていない場合、迅速にAmazon SNSを使用して通知を送信する必要があります。 この要件を満たすために、最小限の実装コストで対応できる方法を2つ選んでください。
選択肢:
A. 既存のLambda関数のコードを更新し、各パートナーの注文数をAmazon CloudWatchのカスタムメトリクスに送信します。
B. Amazon Kinesis Data Streamsを利用し、新しいLambda関数を設定して注文データを追跡し、注文がない場合にSNS通知を送信します。
C. 既存のLambda関数を変更して、注文データをAmazon Kinesis Data Streamsに記録します。
D. 新しいLambda関数をスケジュール実行し、CloudWatchメトリクスを24時間ごとに分析して注文がない場合にSNSトピックに通知を送信するよう設定します。
E. CloudWatchカスタムメトリクスの値が0の場合にSNS通知を送信するCloudWatchアラームを設定します。
正解: A, E
A. 既存のLambda関数のコードを更新し、各パートナーの注文数をAmazon CloudWatchのカスタムメトリクスに送信します。
正解 既存のLambda関数にCloudWatchのPutMetricData APIを使用してカスタムメトリクスを送信するコードを数行追加するだけで実装できます。この方法は既存のアーキテクチャを大幅に変更することなく、最小限のコード変更で注文数の監視が可能になります。カスタムメトリクスを使用することで、パートナーごとや日付ごとの詳細な追跡も可能であり、将来的な分析やレポート作成にも活用できます。実装コストが低く、保守も容易な方法です。
B. Amazon Kinesis Data Streamsを利用し、新しいLambda関数を設定して注文データを追跡し、注文がない場合にSNS通知を送信します。
不正解 Kinesis Data Streamsの導入に加えて、新しいLambda関数の作成、ストリーム処理ロジックの実装、エラーハンドリングの設定など、非常に多くの実装が必要になります。この方法は最も実装コストが高く、単純な通知要件に対して極めて複雑なアーキテクチャを構築することになります。また、Kinesisの継続的な運用コストも発生するため、コスト効率の面でも問題があります。
C. 既存のLambda関数を変更して、注文データをAmazon Kinesis Data Streamsに記録します。
不正解 Kinesis Data Streamsは、リアルタイムストリーミングデータの処理に特化したサービスです。単純な注文有無の通知という要件に対して、ストリーミング処理の仕組みを導入するのは明らかに過剰設計(オーバーエンジニアリング)です。Kinesisの設定、シャード管理、データ保持期間の設定など、追加の運用負荷が発生し、実装コストも大幅に増加します。この要件には不適切な技術選択です。
D. 新しいLambda関数をスケジュール実行し、CloudWatchメトリクスを24時間ごとに分析して注文がない場合にSNSトピックに通知を送信するよう設定します。
不正解 新しいLambda関数の作成、EventBridgeでのスケジュール設定、CloudWatchメトリクスの分析ロジックの実装など、複数のコンポーネントを追加する必要があり、実装コストが高くなります。また、24時間ごとの分析では、問題で要求されている「迅速な通知」に対応できません。さらに、メトリクス分析のための複雑なロジックを実装する必要があり、保守性の面でも劣ります。最小限の実装コストという要件に適合しません。
E. CloudWatchカスタムメトリクスの値が0の場合にSNS通知を送信するCloudWatchアラームを設定します。
正解 CloudWatchアラームは、AWSマネジメントコンソールから数分で設定できる標準機能です。メトリクス値が指定した条件(この場合は0)を満たした場合に、自動的にSNSトピックに通知を送信できます。追加のコード実装は一切不要で、設定のみで要件を満たすことができます。アラームの設定は非常にシンプルであり、閾値の変更や通知先の追加も容易です。運用コストも最小限に抑えられる理想的な解決方法です。
全体的な説明
問われている要件
- 毎日受け取るバッチに注文が含まれていない場合の迅速な通知
- Amazon SNSを使用した通知の実装
- 最小限の実装コストでの対応
前提知識
Amazon CloudWatchカスタムメトリクス
- メトリクス送信: PutMetricData APIを使用した独自メトリクスの作成
- ディメンション: パートナー名、日付などによるメトリクスの分類
- データポイント: タイムスタンプ付きの数値データ
- 名前空間: メトリクスの論理的なグループ化
- 統計: Sum、Average、Maximum、Minimumなどの集計値
CloudWatchアラームの機能
- 閾値監視: メトリクス値の上限・下限監視
- アラーム状態: OK、ALARM、INSUFFICIENT_DATAの3つの状態
- 通知アクション: SNS、Auto Scaling、EC2アクションとの連携
- 複合アラーム: 複数のアラーム条件を組み合わせた監視
- アラーム履歴: 状態変化の詳細なログ記録
Lambda関数での実装パターン
- メトリクス送信: boto3のCloudWatchクライアントを使用
- エラーハンドリング: メトリクス送信失敗時の適切な処理
- バッチ処理: 複数メトリクスの一括送信による効率化
- パフォーマンス: 非同期処理によるレスポンス時間最適化
Amazon SNSの通知機能
- トピック: メッセージの配信チャネル
- サブスクリプション: Email、SMS、HTTPエンドポイントなどの配信先
- メッセージフィルタリング: 条件に基づく選択的配信
- 配信ステータス: 成功・失敗の詳細なログ
- 重複除去: FIFOトピックでの重複排除機能
監視アーキテクチャのベストプラクティス
- メトリクス設計: ビジネス要件に基づく適切なメトリクス定義
- アラーム設定: 誤報を避ける適切な閾値設定
- 通知管理: 適切な通知頻度と受信者の設定
- ダッシュボード: 可視化による状況把握の向上
コスト最適化の考慮事項
- カスタムメトリクス料金: メトリクス数とAPI呼び出し回数に基づく課金
- アラーム料金: アラーム数に基づく月額料金
- SNS料金: 通知回数に基づく従量課金
- Lambda料金: 実行時間とメモリ使用量に基づく課金
実装の具体例(Python)
import boto3
import json
def lambda_handler(event, context):
# 注文処理のロジック
order_count = process_orders(event)
# CloudWatchにメトリクス送信
cloudwatch = boto3.client('cloudwatch')
cloudwatch.put_metric_data(
Namespace='OrderProcessing',
MetricData=[
{
'MetricName': 'OrderCount',
'Value': order_count,
'Unit': 'Count',
'Dimensions': [
{
'Name': 'Partner',
'Value': event.get('partner_name', 'Unknown')
}
]
}
]
)
return {
'statusCode': 200,
'body': json.dumps(f'Processed {order_count} orders')
}解くための考え方
この問題では、既存システムへの最小限の変更で監視・通知機能を追加することが求められています。
効果的なアプローチは、以下の2段階で構成されます:
- データ収集: 既存Lambda関数でのメトリクス送信
- 監視・通知: CloudWatchアラームによる自動通知
このアーキテクチャにより、コード変更を最小限に抑えながら、リアルタイムでの注文監視と迅速な通知が実現できます。正解選択肢の組み合わせは、実装の容易さ、運用コストの低さ、保守性の高さという3つの観点で最適解となります。
Kinesis Data Streamsや追加Lambda関数を使用する方法は、要件に対して過剰な複雑性を導入するため、最小限の実装コストという条件に適合しません。
参考資料
問題文:
ある企業は、認証が不要な統計情報をインターネット経由で提供するために Amazon API Gateway と AWS Lambda を使用しています。このサービスは人気があり、API の応答性を向上させたいと考えています。 この目標を達成するための適切な方法を選択してください。
選択肢:
A. API Gateway で使用量プランと API キーを設定する。
B. API の Cross-Origin Resource Sharing (CORS) を有効にする。
C. インターフェース VPC エンドポイントを使用するように API Gateway を設定する。
D. API Gateway で API キャッシュを有効にする。
正解: D
A. API Gateway で使用量プランと API キーを設定する。
不正解 使用量プランとAPIキーは、API の利用制限と認証・認可を管理するための機能です。特定のクライアントに対してリクエスト数の上限(スロットリング)やクォータ制限を設定することで、API の利用状況をコントロールできます。しかし、これらの設定は API の応答性向上ではなく、むしろアクセス制御や課金管理を目的としています。問題では「認証が不要」と明記されているため、APIキーの設定は要件にも合致しません。
B. API の Cross-Origin Resource Sharing (CORS) を有効にする。
不正解 CORSは、Webブラウザのセキュリティ機能である同一オリジンポリシーを緩和するための仕組みです。異なるドメインからのJavaScriptによるAPIアクセスを許可する設定であり、セキュリティとアクセシビリティに関する機能です。CORS設定はHTTPヘッダーの追加処理にすぎず、API の応答性やパフォーマンスの向上には全く関係ありません。この設定は、ブラウザベースのWebアプリケーションからAPIを呼び出す際の制約を解除するためのものです。
C. インターフェース VPC エンドポイントを使用するように API Gateway を設定する。
不正解 インターフェース VPC エンドポイントは、VPC内からAPI Gatewayにプライベートアクセスするための仕組みです。この設定により、インターネットを経由せずにVPC内部からAPI Gatewayにアクセスできるようになりますが、問題で言及されている「インターネット経由で提供する」という要件と矛盾します。また、VPCエンドポイントの主な目的はセキュリティの向上であり、API の応答性向上には効果はありません。
D. API Gateway で API キャッシュを有効にする。
正解 API Gatewayのキャッシュ機能を有効にすることで、同じリクエストに対する応答をメモリ内に一定期間保存できます。統計情報のような頻繁に変更されないデータの場合、キャッシュされた応答を直接返すことで、バックエンドのLambda関数を実行する必要がなくなります。これにより、レスポンス時間が大幅に短縮され、同時にLambda関数の実行回数も削減されるため、コスト削減効果も期待できます。キャッシュのTTL(Time To Live)を適切に設定することで、データの鮮度と応答性のバランスを取ることが可能です。
全体的な説明
問われている要件
- 認証不要で統計情報をインターネット経由で提供するAPI
- 人気のあるサービスであることから高いトラフィックが予想される
- API の応答性(レスポンス時間)を向上させること
- パフォーマンス最適化による利用者体験の改善
前提知識
API Gatewayのキャッシュ機能
- キャッシュクラスター: 0.5GB から 237GB までのサイズを選択可能
- TTL設定: キャッシュの有効期限を0秒から3600秒(1時間)まで設定
- キャッシュキー: URLパス、クエリパラメータ、ヘッダーを組み合わせてキャッシュを識別
- キャッシュヒット率: 同じリクエストがキャッシュから返される割合
API Gatewayのパフォーマンス要素
- コールドスタート: Lambda関数の初回実行時の遅延
- バックエンド処理時間: Lambda関数やその他のバックエンドサービスの実行時間
- ネットワーク遅延: クライアントとAPI Gateway間、API Gatewayとバックエンドサービス間の通信時間
- スロットリング: 同時実行数制限による処理遅延
統計情報APIの特徴
- データの変更頻度: 統計データは通常、リアルタイムでの更新が不要
- 読み取り中心: 新しいデータの追加や更新よりも参照が多い
- 繰り返しアクセス: 同じ統計情報への複数回のアクセスが発生しやすい
- キャッシュ適性: データの特性上、キャッシュによる効果が高い
API Gatewayの他の最適化手法
- プロビジョンド同時実行: Lambda関数のコールドスタート削減
- リージョン選択: 利用者に地理的に近いリージョンでの配置
- CloudFrontとの連携: エッジロケーションでのキャッシュとCDN配信
- バックエンド最適化: データベースクエリやアルゴリズムの改善
VPCエンドポイントの用途
- プライベートアクセス: インターネットを経由しないAPI アクセス
- セキュリティ強化: ネットワークトラフィックの制御
- コンプライアンス: データがインターネットを経由しない要件への対応
- ネットワーク分離: 内部システム間の通信最適化
CORS の用途
- ブラウザセキュリティ: Same-Origin Policy の制御
- クロスドメインアクセス: 異なるドメイン間のJavaScript通信許可
- Webアプリケーション統合: フロントエンドとAPIの連携
- プリフライトリクエスト: 複雑なHTTPリクエストの事前確認
解くための考え方
この問題の核心は、API の応答性向上に最も効果的な手法を特定することです。
統計情報のような比較的静的なデータを提供するAPIでは、同じリクエストが繰り返し発生する傾向があります。このような状況では、キャッシュ機能が最も効果的な最適化手法となります。
API Gatewayのキャッシュを有効にすることで、初回リクエスト時にバックエンドのLambda関数から取得したレスポンスをメモリに保存し、同じリクエストに対しては保存されたレスポンスを直接返すことができます。これにより、Lambda関数の実行回数が削減され、レスポンス時間が大幅に短縮されます。
他の選択肢は、セキュリティ、アクセス制御、ネットワーク構成に関するものであり、直接的なパフォーマンス向上には寄与しません。
参考資料
問題文:
開発者はAmazon EC2インスタンス上で動作するアプリケーションを監視しています。このアプリケーションはAmazon DynamoDBのテーブルにアクセスしており、開発者は1秒間隔でカスタムAmazon CloudWatchメトリクスを設定しています。問題が発生した場合、開発者はAmazon SNSを使用して30秒以内に通知を受け取ることを希望しています。 この要件を満たす最適な方法を選択してください。
選択肢:
A. デフォルトのCloudWatchメトリクスに変更します。
B. カスタムAWS LambdaとAmazon CloudWatch Logsを設定します。
C. AWS Lambdaを使用してアラームを設定します。
D. 高解像度のCloudWatchアラームを設定します。
正解: D
A. デフォルトのCloudWatchメトリクスに変更します。
不正解 デフォルトのCloudWatchメトリクスは、EC2インスタンスの基本的な監視メトリクス(CPU使用率、ネットワーク使用量、ディスクI/Oなど)を提供しますが、これらは通常1分間隔または5分間隔で収集されます。アラームの評価間隔が1分以上になるため、30秒以内の通知要件を満たすことができません。
B. カスタムAWS LambdaとAmazon CloudWatch Logsを設定します。
不正解 この方法も技術的には実現可能ですが、要件に対して過度に複雑なアーキテクチャです。 CloudWatch Logsを使用する場合、以下の手順が必要になります: アプリケーションからCloudWatch Logsにメトリクスデータをログとして出力、ログデータを解析してメトリクス値を抽出するLambda関数の作成、しきい値監視とSNS通知のロジック実装、ログストリームを監視してLambda関数をトリガーする設定。 この方法では、ログの解析処理によるレイテンシが発生し、30秒以内の通知要件を満たすことが困難になる可能性があります。また、ログデータの処理とフィルタリングには追加の複雑さとコストが伴います。メトリクス監視という用途には、CloudWatch Metricsとアラームの組み合わせが最適です。
C. AWS Lambdaを使用してアラームを設定します。
不正解 AWS Lambdaを使用したカスタムアラーム設定は技術的には可能ですが、この要件に対しては過剰に複雑な方法です。 Lambda関数を使用する場合、以下の作業が必要になります: カスタムメトリクスを定期的に取得するLambda関数の作成、しきい値を監視するロジックの実装、SNS通知を送信する処理の実装、Lambda関数を1秒間隔で実行するためのCloudWatch EventsまたはEventBridgeの設定。 これらの実装には多くの開発工数が必要で、エラーハンドリングや可用性の確保も複雑になります。また、1秒間隔でLambda関数を実行するとコストも高くなります。CloudWatchの標準機能で要件を満たせる場合は、よりシンプルなアプローチを選択すべきです。
D. 高解像度のCloudWatchアラームを設定します。
正解 高解像度CloudWatchアラームは、1秒間隔で収集されるカスタムメトリクスを監視し、30秒以内の通知要件を満たすことができます。高解像度メトリクス(1秒、5秒、10秒、30秒間隔)に対応したアラームは、評価間隔を10秒または30秒に設定できるため、問題発生から30秒以内にSNS通知を送信することが可能です。設定も比較的簡単で、CloudWatchコンソールまたはAPIから期間(Period)を短く設定し、評価期間(Evaluation Periods)を適切に調整するだけです。高解像度アラームは追加コストが発生しますが、要件を満たす最も直接的で効率的な方法です。
全体的な説明
問われている要件
- 1秒間隔で収集されるカスタムCloudWatchメトリクスを監視すること
- 問題発生時に30秒以内にSNS通知を受け取ること
- EC2インスタンス上のアプリケーションとDynamoDBアクセスを監視すること
- 効率的で保守しやすい監視ソリューションを実装すること
前提知識
CloudWatchメトリクスの種類
CloudWatchには2種類のメトリクス解像度があります:
標準解像度メトリクス:
- 最小データ間隔:1分
- 保存期間:15か月
- コスト:比較的低い
- 用途:一般的な監視、長期トレンド分析
高解像度メトリクス:
- 最小データ間隔:1秒
- サポート間隔:1秒、5秒、10秒、30秒、1分の倍数
- 保存期間:3時間(1秒)、1日(1分未満)、15日(1分)
- コスト:標準解像度より高い
- 用途:リアルタイム監視、障害の迅速な検出
高解像度メトリクスの送信方法
AWS SDKを使用してメトリクスを送信する際は、以下のように設定します:
cloudwatch.put_metric_data(
Namespace='MyApplication',
MetricData=[
{
'MetricName': 'DynamoDB_ResponseTime',
'Value': response_time,
'Unit': 'Milliseconds',
'StorageResolution': 1 # 高解像度(1秒)
}
]
)高解像度アラームの特徴
アラーム評価間隔:
- 10秒、30秒、または60秒の倍数で設定可能
- 高解像度メトリクスと組み合わせて使用
- 迅速な問題検出と通知が可能
設定要素:
- 期間(Period):メトリクスを評価する時間間隔
- 評価期間(Evaluation Periods):アラーム状態を判定するために必要な期間数
- データポイント(Datapoints to Alarm):アラームをトリガーするために必要な条件を満たすデータポイント数
SNS通知との統合
CloudWatchアラームは、Amazon SNSと直接統合されており、以下の機能を提供します:
- アラーム状態変更時の自動通知送信
- 通知内容:アラーム名、現在の状態、メトリクス値、しきい値など
- 通知方法:Email、SMS、HTTPエンドポイント、Lambda関数など
- 複数の通知先への同時配信が可能
コストとパフォーマンス考慮
高解像度メトリクスの料金体系:
- カスタムメトリクス:月額0.30ドル/メトリクス(最初の10,000メトリクス)
- 高解像度アラーム:月額0.30ドル/アラーム(標準アラームは0.10ドル)
- API呼び出し:PutMetricData 1,000リクエストあたり0.01ドル
解くための考え方
この問題では、1秒間隔のメトリクス監視と30秒以内の通知という厳しい要件があります。
CloudWatchの高解像度機能は、このような要件に特化して設計されており、マネージドサービスとして高い信頼性を提供します。
カスタム実装(Lambda関数など)は技術的には可能ですが、開発・運用コストが高く、信頼性の確保も困難です。要件を満たす既存のマネージドサービスがある場合は、それを活用することが最適解となります。
参考資料
問題文:
金融会社は、法的な理由により、オリジナルのお客様レコードを 10 年間保存する必要があります。この記録には個人を特定できる情報(PII)が含まれています。規制では PII を社内の特定の人のみが利用でき、第三者とは共有してはいけないとされています。同社は、PII を含むドキュメントを Amazon S3 に保存し、第三者がアクセスする際に PII を削除して返却する必要があります。 開発者は、ドキュメントから PII を削除する AWS Lambda 関数を作成し、この関数を removePii と呼びます。 会社がドキュメントのコピーを1つだけ維持しながら PII要件を満たすための最適な方法を選択してください。
選択肢:
A. S3 GET リクエストが行われたときに removePii 関数を呼び出す S3 イベント通知をセットアップします。GET リクエストを使用して Amazon S3 を呼び出し、PII のないオブジェクトにアクセスします。
B. S3 PUT リクエストが行われたときに removePii 関数を呼び出す S3 イベント通知をセットアップします。PUT リクエストを使用して Amazon S3 を呼び出し、PII のないオブジェクトにアクセスします。
C. S3 コンソールから S3 アクセスポイントを作成し、アクセスポイント名を使用して GetObjectLegalHold S3 API 関数を呼び出します。removePii 関数名を渡して、PII のないオブジェクトにアクセスします。
D. S3 コンソールから S3 Object Lambda アクセスポイントを作成します。removePii 関数を選択します。S3 アクセスポイントを使用して、PII のないオブジェクトにアクセスします。
正解: D
A. S3 GET リクエストが行われたときに removePii 関数を呼び出す S3 イベント通知をセットアップします。GET リクエストを使用して Amazon S3 を呼び出し、PII のないオブジェクトにアクセスします。
不正解 S3イベント通知は、PUT、POST、COPY、DELETE、Restore操作などのオブジェクト変更イベントに対してトリガーされる機能です。GETリクエスト(オブジェクトの読み取り)に対してイベント通知を設定することはできません。GETは読み取り専用操作であり、オブジェクトの状態を変更しないため、イベント通知の対象外です。また、この方法では動的なデータ処理も実現できないため、技術的に実現不可能なアプローチです。
B. S3 PUT リクエストが行われたときに removePii 関数を呼び出す S3 イベント通知をセットアップします。PUT リクエストを使用して Amazon S3 を呼び出し、PII のないオブジェクトにアクセスします。
不正解 この方法では、オブジェクトがS3に保存される際にPIIが自動的に削除されてしまいます。しかし、規制要件として「オリジナルのお客様レコードを10年間保存する」ことが明記されており、PIIを含む元のドキュメントを保持する必要があります。PUTイベント時にPIIを削除すると、法的に必要なオリジナルデータが失われてしまい、規制要件を満たせません。また、この方法では元データと処理済みデータの両方を管理する複雑性が生じます。
C. S3 コンソールから S3 アクセスポイントを作成し、アクセスポイント名を使用して GetObjectLegalHold S3 API 関数を呼び出します。removePii 関数名を渡して、PII のないオブジェクトにアクセスします。
不正解 GetObjectLegalHoldは、S3 Object Lock機能の一部で、オブジェクトの法的保持(Legal Hold)ステータスを取得するためのAPIです。この機能は、法的な理由でオブジェクトの削除や変更を一時的に禁止するためのものであり、オブジェクトの内容を動的に処理したりPIIを削除する機能は提供していません。
D. S3 コンソールから S3 Object Lambda アクセスポイントを作成します。removePii 関数を選択します。S3 アクセスポイントを使用して、PII のないオブジェクトにアクセスします。
正解 S3 Object Lambdaは、S3 GETリクエストに対してカスタムコードを実行し、オブジェクトデータを動的に処理できる機能です。Object Lambdaアクセスポイントを作成し、removePii関数を関連付けることで、第三者がアクセスする際にリアルタイムでPIIを削除したバージョンを返すことができます。オリジナルのS3オブジェクトは変更されずに保持されるため、法的要件を満たしながら、アクセス時に動的にPIIを除去したデータを提供できます。これにより、「ドキュメントのコピーを1つだけ維持」という要件も満たせます。
全体的な説明
問われている要件
- 金融会社での10年間の顧客レコード保持義務
- 個人を特定できる情報(PII)を含むオリジナルドキュメントの保存
- 社内特定人員のみのPIIアクセス許可
- 第三者アクセス時のPII除去機能
- ドキュメントのコピーを1つだけ維持する効率的な管理
前提知識
Amazon S3 Object Lambda
S3 Object Lambdaは、S3 GETリクエストに対してカスタム処理を適用する機能です:
- 動的処理: オブジェクト取得時にリアルタイムでデータを変換
- オリジナル保持: 元のS3オブジェクトは変更されずに保持
- Lambda統合: 既存のLambda関数を直接利用可能
- アクセスポイント: 標準的なS3 APIを使用してアクセス
- 透過性: クライアントアプリケーションから見て通常のS3アクセスと同様
Object Lambdaアクセスポイントの構成
Object Lambdaアクセスポイントは以下の要素で構成されます:
- サポートアクセスポイント: 元のS3バケットへのアクセスを提供
- Lambda関数: GETリクエスト時に実行される処理ロジック
- 変換設定: リクエストとレスポンスの処理方法
- IAMポリシー: アクセス制御とセキュリティ設定
PII(個人を特定できる情報)管理
金融業界でのPII管理要件:
- データ分類: PII要素の特定と分類
- アクセス制御: 最小権限の原則による厳格な制御
- 監査証跡: すべてのアクセスの記録と監視
- データマスキング: 非認可ユーザーへの情報隠蔽
- 規制遵守: GDPR、PCI DSS、SOX法などの要件準拠
Lambda関数による動的データ処理
removePii関数の実装例:
- テキスト解析: 正規表現やNLPによるPII検出
- データマスキング: 検出されたPIIの匿名化処理
- 構造化データ: JSON、XMLなどの特定フィールド除去
- エラーハンドリング: 処理失敗時の適切な応答
- パフォーマンス: 大容量ファイルの効率的処理
法的要件とコンプライアンス
金融機関での記録保持要件:
- データ整合性: オリジナルデータの改ざん防止
- 保持期間: 法定期間中の確実なデータ保存
- アクセス監査: 誰がいつアクセスしたかの記録
- セキュリティ: 暗号化とアクセス制御
- 可用性: 必要時の確実なデータ取得
アーキテクチャのメリット
この設計による利点:
- 単一ソース: オリジナルデータの一元管理
- 動的処理: 需要に応じたリアルタイム変換
- コスト効率: 重複データストレージの排除
- メンテナンス: 処理ロジックの集中管理
- 拡張性: 新しい処理要件への対応
解くための考え方
この要件を満たすには、オリジナルデータを保持しながら、アクセス時に動的にPIIを除去する仕組みが必要です。
S3 Object Lambdaは、まさにこの用途に設計されたサービスです。Object Lambdaアクセスポイントを作成し、removePii関数を関連付けることで、第三者がアクセスする際に自動的にPIIが除去されたバージョンが返されます。
オリジナルのS3オブジェクトは一切変更されないため、法的要件である「オリジナルの10年間保存」を満たしながら、「ドキュメントのコピーを1つだけ維持」という効率性も実現できます。
社内の特定人員は通常のS3アクセスポイントを使用してPIIを含むオリジナルデータにアクセスし、第三者はObject LambdaアクセスポイントからPIIが除去されたデータにアクセスするという使い分けが可能です。
参考資料
問題文:
Amazon RDS のデータベースインスタンスは、多くのアプリケーションで履歴データの検索に使用されています。クエリレートは一定であり、クエリは変動する可能性があります。履歴データは毎日更新され、書き込みトラフィックが発生します。これにより、リアルタイムのデータが常に必要でない読み取りクエリのパフォーマンスが低下し、アプリケーションユーザーに影響を与える可能性があります。 アプリケーションユーザーのパフォーマンスに影響を与えず、リアルタイムデータの即時反映が常に必要でない場合に最適な方法を選択してください。
選択肢:
A. Amazon RDS の代わりに Amazon DynamoDB を使用して、読み取りトラフィックをバッファリングします。
B. RDS リードレプリカを作成し、すべての読み取りトラフィックをレプリカに転送します。
C. Amazon RDS がマルチ AZ であることを確認して、増加したトラフィックをより適切に吸収できるようにします。
D. Amazon RDS の前に Amazon ElastiCache を実装して、書き込みトラフィックをバッファリングします。
正解: B
A. Amazon RDS の代わりに Amazon DynamoDB を使用して、読み取りトラフィックをバッファリングします。
不正解 DynamoDBへの移行は、既存のRDSベースのアプリケーションに対して大幅なアーキテクチャ変更を要求します。データモデルの変更、アプリケーションコードの書き換え、SQLクエリからNoSQLクエリへの変換などが必要となり、開発コストと移行リスクが非常に高くなります。
B. RDS リードレプリカを作成し、すべての読み取りトラフィックをレプリカに転送します。
正解 RDSリードレプリカは読み取り専用のデータベースインスタンスで、プライマリインスタンスからデータを非同期で複製します。すべての読み取りクエリをリードレプリカにオフロードすることで、プライマリインスタンスは書き込み処理に専念でき、全体的なパフォーマンスが向上します。リアルタイムデータが常に必要でない履歴データの検索には、レプリケーション遅延があっても十分に対応可能です。
C. Amazon RDS がマルチ AZ であることを確認して、増加したトラフィックをより適切に吸収できるようにします。
不正解 マルチAZ構成は高可用性とディザスタリカバリを目的とした機能で、スタンバイインスタンスは読み取りトラフィックを処理できません。スタンバイインスタンスはプライマリに障害が発生した場合のフェイルオーバー用であり、通常時の負荷分散には寄与しません。読み取りトラフィックの増加に対する解決策にはなりません。
D. Amazon RDS の前に Amazon ElastiCache を実装して、書き込みトラフィックをバッファリングします。
不正解 ElastiCacheはインメモリキャッシングサービスであり、読み取りパフォーマンスの向上には適していますが、書き込みトラフィックのバッファリングには設計されていません。また、履歴データのような大量のデータセットを全てキャッシュすることは現実的ではなく、メモリコストも高くなります。書き込み処理の根本的な負荷軽減にはなりません。
全体的な説明
問われている要件
- 多くのアプリケーションが履歴データ検索でRDSを使用している
- 毎日の履歴データ更新による書き込みトラフィックが発生している
- 書き込み処理が読み取りクエリのパフォーマンスに悪影響を与えている
- リアルタイムデータの即時反映が常に必要でない読み取りクエリが対象
- アプリケーションユーザーのパフォーマンスに影響を与えない解決策が必要
前提知識
Amazon RDS リードレプリカ プライマリデータベースインスタンスの読み取り専用コピーを作成する機能です。
リードレプリカの特徴
- 非同期レプリケーション:プライマリからデータが複製される
- 読み取り専用:SELECT クエリのみ実行可能
- 複数作成可能:1つのプライマリに対して最大15個まで
- 異なるAZやリージョンに配置可能
レプリケーション遅延 プライマリからリードレプリカへのデータ複製には若干の遅延が発生します:
- 通常数秒から数分程度
- ネットワーク状況やデータ量に依存
- 履歴データのような用途では一般的に許容範囲
負荷分散の効果
- プライマリ:書き込み処理(INSERT、UPDATE、DELETE)
- リードレプリカ:読み取り処理(SELECT)
- 処理の分離により全体的なパフォーマンス向上
アプリケーション側の考慮事項
- 読み取り専用クエリをリードレプリカエンドポイントに向ける
- 書き込み処理は引き続きプライマリエンドポイントを使用
- 接続文字列の適切な管理
マルチAZ vs リードレプリカ
- マルチAZ:高可用性目的、スタンバイは読み取り不可
- リードレプリカ:読み取りスケーリング目的、アクティブに読み取り処理
他のソリューションとの比較
- ElastiCache:頻繁にアクセスされる小さなデータセット向け
- DynamoDB:NoSQLが適したワークロード向け
- Aurora:より高度な読み取りスケーリングが必要な場合
コスト効率 リードレプリカは追加のインスタンスコストが発生しますが:
- アプリケーションの大幅な変更不要
- 既存のSQLクエリをそのまま使用可能
- 段階的な実装が可能
解くための考え方
問題の核心は読み取りと書き込みトラフィックの競合による性能低下です。 特に「リアルタイムデータが常に必要でない」という条件が重要なヒントです。
RDSリードレプリカは、読み取り処理をプライマリインスタンスから分離することで根本的な解決を提供します。 履歴データの検索という用途に対して、若干のレプリケーション遅延は問題になりません。
他のソリューションは、アーキテクチャの大幅変更や適用範囲の制限があり、費用対効果の観点で最適ではありません。
参考資料
問題文:
開発者は、Amazon ElastiCache for Memcached を会社の既存のレコードストレージアプリケーションに追加しようとしています。開発者は、一般的なレコード処理パターンの分析に基づいて、遅延読み込みを使用することを決定しました。 遅延読み込みを正しく実装する疑似コードの例を選択してください。
選択肢:
A.
record_value = db.query(“UPDATE Records SET Details = {1} WHERE ID == {0}”, record_key, record_value)
cache.set(record_key, record_value)
B.
record_value = cache.get(record_key)
if (record_value == NULL)
record_value = db.query(“SELECT Details FROM Records WHERE ID == {0}”, record_key)
cache.set(record_key, record_value)
C.
record_value = db.query(“SELECT Details FROM Records WHERE ID == {0}”, record_key)
if (record_value != NULL)
cache.set(record_key, record_value)
D.
record_value = cache.get(record_key)
db.query(“UPDATE Records SET Details = {1} WHERE ID == {0}”, record_key, record_value)
正解: B
A.
record_value = db.query(“UPDATE Records SET Details = {1} WHERE ID == {0}”, record_key, record_value)
cache.set(record_key, record_value)
不正解 このコードはデータの更新(UPDATE)処理を行っていますが、遅延読み込みは読み取り処理の最適化手法です。UPDATEクエリでは既存データの変更を行うため、遅延読み込みの目的である「必要に応じてデータを読み込む」という概念に適合しません。また、キャッシュから読み取りを試行する処理が含まれていません。
B.
record_value = cache.get(record_key)
if (record_value == NULL)
record_value = db.query(“SELECT Details FROM Records WHERE ID == {0}”, record_key)
cache.set(record_key, record_value)
正解 これは遅延読み込みの典型的な実装パターンを正確に示しています。まずキャッシュからデータを取得し、データが存在しない場合(キャッシュミス)にのみデータベースからデータを取得します。その後、取得したデータをキャッシュに保存することで、次回のアクセス時にはキャッシュから高速にデータを取得できます。この流れが遅延読み込みの基本的なワークフローです。
C.
record_value = db.query(“SELECT Details FROM Records WHERE ID == {0}”, record_key)
if (record_value != NULL)
cache.set(record_key, record_value)
不正解 このコードは最初からデータベースに直接アクセスしており、キャッシュの恩恵を受けることができません。遅延読み込みの基本原則である「キャッシュを優先的に使用し、必要な場合のみデータベースにアクセスする」という考え方に反しています。毎回データベースアクセスが発生するため、パフォーマンス向上の効果が得られません。
D.
record_value = cache.get(record_key)
db.query(“UPDATE Records SET Details = {1} WHERE ID == {0}”, record_key, record_value)
不正解 キャッシュからのデータ取得は行っていますが、その後のUPDATE処理は遅延読み込みの目的に適合しません。また、キャッシュミスの場合の処理が定義されておらず、キャッシュとデータベース間の整合性も考慮されていません。遅延読み込みパターンの要件を満たしていません。
全体的な説明
問われている要件
- Amazon ElastiCache for Memcachedをレコードストレージアプリケーションに統合する
- 遅延読み込み(Lazy Loading)パターンを正しく実装する
- 一般的なレコード処理パターンに基づく効率的なキャッシング戦略
- 正しい疑似コードの実装パターンを選択する
前提知識
遅延読み込み(Lazy Loading) 必要な時にのみデータをロードするキャッシング戦略で、以下の特徴があります:
遅延読み込みの基本フロー
- アプリケーションがデータを要求
- キャッシュでデータの存在を確認
- キャッシュヒット:キャッシュからデータを返す
- キャッシュミス:データベースからデータを取得
- 取得したデータをキャッシュに保存
- データをアプリケーションに返す
遅延読み込みの利点
- 必要なデータのみがキャッシュされる(メモリ効率が良い)
- 読み取り頻度の高いデータが自然にキャッシュに残る
- 実装が比較的シンプル
- データベースの読み取り負荷を大幅に削減
遅延読み込みの欠点
- 初回アクセス時にキャッシュミスが発生(レイテンシの増加)
- キャッシュが古いデータを保持する可能性(データ整合性の課題)
- キャッシュの有効期限設定が重要
Amazon ElastiCache for Memcached 高性能なインメモリキャッシングサービスで、以下の特徴があります:
Memcachedの特徴
- シンプルなkey-value形式のデータストア
- マルチスレッド処理をサポート
- 水平スケーリングが容易
- データの永続化なし(メモリのみ)
他のキャッシング戦略との比較
- Write-Through:書き込み時にキャッシュとDBを同時更新(整合性重視)
- Write-Behind:書き込み時はキャッシュのみ更新、後でDBに反映(性能重視)
- Refresh-Ahead:期限切れ前にデータを自動的に更新
実装時の考慮事項
- TTL(Time To Live)の適切な設定
- キャッシュキーの命名規則
- エラーハンドリング(キャッシュ障害時の処理)
- メトリクス監視(ヒット率、ミス率など)
コード実装のベストプラクティス
- null値のチェックを適切に行う
- 例外処理を実装する(キャッシュ接続エラーなど)
- ログ出力でキャッシュヒット/ミスを追跡
- タイムアウト設定を適切に行う
解くための考え方
遅延読み込みの実装では、キャッシュを最初にチェックすることが重要です。 キャッシュにデータが存在する場合は高速にデータを返し、存在しない場合のみデータベースアクセスを行います。
正しい実装パターンは「キャッシュ確認 → キャッシュミス時のDB取得 → キャッシュへの保存」の順序です。 この順序を守ることで、パフォーマンス向上とデータベース負荷軽減を実現できます。
他の選択肢は更新処理や不適切な順序になっており、遅延読み込みの基本原則に合致していません。
参考資料
問題文:
ある開発者は、1 時間に 1 回実行される CPU 負荷の高い AWS Lambda 関数を構成しています。この関数は通常 45 秒で実行されますが、最大 1 分かかる場合もあります。タイムアウトパラメータは 3 分に設定されており、その他の設定はそのままです。 開発者は、この関数の実行時間を最適化する必要があります。
選択肢:
A. 関数のメモリを増やします。
B. 関数の予約済み同時実行数を増やします。
C. デフォルト VPC 内で関数を再デプロイします。
D. Lambda レイヤーを使用して関数を再デプロイします。
正解: A
A. 関数のメモリを増やします。
正解 AWS LambdaではメモリとCPUが比例関係にあり、メモリ設定を増やすことでCPU性能も向上します。128MBから10,240MBまでの範囲で設定可能で、メモリが増えるほどCPU処理能力も線形に増加します。CPU負荷の高いタスクでは、この追加のCPU性能により実行時間が大幅に短縮される可能性があります。料金は実行時間とメモリ使用量の積で計算されるため、メモリを増やしても実行時間が短縮されれば、全体的なコストが削減される場合もあります。
B. 関数の予約済み同時実行数を増やします。
不正解 予約済み同時実行数は、Lambda関数が同時に実行できるインスタンス数の上限を制御する設定です。複数のリクエストが同時に処理される場合のスケーラビリティとリソース管理に関連しますが、単一の関数実行における処理速度には影響しません。この問題では関数が1時間に1回実行されるため、同時実行の問題は発生しておらず、個々の実行の処理時間を短縮する必要があります。同時実行数を増やしても、CPU負荷の高いタスクの実行時間は改善されません。
C. デフォルト VPC 内で関数を再デプロイします。
不正解 Lambda関数をVPC内で実行すると、VPCリソース(ENI、セキュリティグループ、サブネットなど)への接続が必要になり、関数の初期化時間が増加する可能性があります。VPC設定は、関数がVPC内のリソース(RDS、ElastiCacheなど)にアクセスする必要がある場合にのみ使用すべきです。CPU負荷の高い処理の最適化という要件には関係なく、むしろパフォーマンスに悪影響を与える可能性があります。VPCの設定によってはネットワーク遅延も発生する場合があります。
D. Lambda レイヤーを使用して関数を再デプロイします。
不正解 Lambdaレイヤーは、複数の関数間で共有できるコード、ライブラリ、その他のファイルをパッケージ化する機能です。関数のデプロイパッケージサイズを削減し、コードの再利用性を向上させることができますが、関数の実行パフォーマンスや処理速度には直接的な影響を与えません。レイヤーの使用により初回実行時の関数初期化時間がわずかに改善される可能性はありますが、CPU負荷の高い処理の実行時間最適化という要件には適していません。
全体的な説明
問われている要件
- CPU負荷の高いLambda関数の実行時間最適化
- 現在45秒から最大60秒の実行時間を短縮
- 1時間に1回実行される定期処理の効率化
- タイムアウト設定は3分で問題なし
前提知識
AWS LambdaのメモリとCPU割り当ての関係
AWS Lambdaでは、メモリ設定がCPU性能を決定する唯一のパラメータです:
- 最小設定: 128MB(最小CPU割り当て)
- 最大設定: 10,240MB(最大CPU割り当て)
- 比例関係: メモリ設定に比例してCPU性能が向上
- vCPU基準: 1,769MBで1つのフルvCPU、6,144MBで約3.5vCPU相当
- ネットワーク性能: メモリ設定が高いほどネットワーク帯域幅も向上
CPU集約的タスクでのパフォーマンス特性
CPU負荷の高い処理では以下の特徴があります:
- 計算処理: 数値計算、暗号化、データ変換などの処理
- メモリアクセス: 大量データの読み書きとメモリ操作
- 並列処理: マルチコア処理による性能向上効果
- キャッシュ効率: CPUキャッシュサイズとアクセスパターンの最適化
Lambdaの料金体系とコスト最適化
Lambda料金は以下の要素で決まります:
- 実行時間: 100ms単位での課金
- メモリ使用量: 設定されたメモリサイズ
- リクエスト数: 関数呼び出し回数
- コスト計算: (実行時間 × メモリ設定) + リクエスト数
メモリを増やすことで実行時間が短縮されれば、全体的なコストが削減される場合があります。
パフォーマンス最適化のベストプラクティス
Lambda関数の最適化では以下を考慮します:
- 適切なメモリ設定: CPU要件に応じたメモリ配分
- コールドスタート最小化: Provisioned Concurrencyの利用
- 効率的なコード: アルゴリズムとデータ構造の最適化
- 外部依存関係の最小化: 不要なライブラリやSDKの除去
- ログレベルの調整: 本番環境での詳細ログ抑制
解くための考え方
CPU負荷の高いLambda関数の実行時間を最適化するには、CPU性能の向上が最も効果的です。
LambdaではメモリとCPUが比例関係にあるため、メモリ設定を増やすことで直接的にCPU性能が向上します。現在の実行時間が45-60秒という状況では、CPU性能を2倍にすることで実行時間を半分程度に短縮できる可能性があります。
例えば、現在512MBに設定されている場合、1,024MBや1,769MBに増やすことで大幅な性能向上が期待できます。特に1,769MB以上では1つのフルvCPUが利用できるため、CPU集約的な処理において顕著な改善が見込めます。
料金面でも、メモリを2倍にして実行時間が半分になれば、コストは変わらず、さらに短縮されればコスト削減も実現できます。
参考資料
問題文:
ある会社は、Amazon S3 で子会社の 1 つのクライアント側ウェブアプリケーションをホストしています。このウェブアプリケーションには、https://www.example.com から Amazon CloudFront を介してアクセスできます。展開が成功した後、会社は、残りの子会社用のクライアント側ウェブアプリケーションを、3 つの別々の S3 バケットでさらに 3 つホストしたいと考えています。 この目標を達成するために、開発者はすべての一般的な JavaScript ファイルとウェブフォントを、ウェブアプリケーションを提供する中央の S3 バケットに移動します。しかし、テスト中に、開発者は、ブラウザが JavaScript ファイルとウェブフォントをブロックすることに気づきました。 ブラウザが JavaScript ファイルとウェブフォントをブロックしないようにする最適な方法を選択してください。
選択肢:
A. 中央の S3 バケットにメッセージの整合性チェックを提供する Content-MD5 ヘッダーを作成します。ウェブアプリケーションリクエストごとに Content-MD5 ヘッダーを挿入します。
B. 中央の S3 バケットへのアクセスを許可する 4 つのアクセスポイントを作成します。各ウェブアプリケーションのバケットにアクセスポイントを割り当てます。
C. 中央の S3 バケットへのアクセスを許可する Cross-Origin Resource Sharing (CORS) 構成を作成します。CORS 構成を中央の S3 バケットに追加します。
D. 中央の S3 バケットへのアクセスを許可するバケットポリシーを作成します。バケットポリシーを中央の S3 バケットにアタッチします。
正解: C
A. 中央の S3 バケットにメッセージの整合性チェックを提供する Content-MD5 ヘッダーを作成します。ウェブアプリケーションリクエストごとに Content-MD5 ヘッダーを挿入します。
不正解 Content-MD5ヘッダーは、HTTPリクエストやレスポンスのデータ整合性を検証するためのものであり、データが転送中に破損していないことを確認する目的で使用されます。このヘッダーはCORSポリシーやクロスオリジンリソース共有とは全く無関係であり、ブラウザのセキュリティ制限を解除することはできません。
B. 中央の S3 バケットへのアクセスを許可する 4 つのアクセスポイントを作成します。各ウェブアプリケーションのバケットにアクセスポイントを割り当てます。
不正解 S3アクセスポイントは、大規模なS3バケットへのアクセス管理を簡素化し、異なるアプリケーションやユーザーグループに対して個別のアクセス制御を提供する機能です。しかし、アクセスポイントを作成してもCORSの問題は解決されません。ブラウザのクロスオリジン制限は依然として適用されるため、JavaScriptファイルやWebフォントのブロックは続きます。
C. 中央の S3 バケットへのアクセスを許可する Cross-Origin Resource Sharing (CORS) 構成を作成します。CORS 構成を中央の S3 バケットに追加します。
正解 これが問題の根本的な解決策です。異なるドメインやオリジンから中央のS3バケットのリソース(JavaScriptファイルやWebフォント)にアクセスする際、ブラウザのSame-Origin Policyによりブロックされます。S3バケットにCORS設定を追加することで、指定したオリジンからのクロスオリジンリクエストを許可し、ブラウザがリソースを正常にロードできるようになります。
D. 中央の S3 バケットへのアクセスを許可するバケットポリシーを作成します。バケットポリシーを中央の S3 バケットにアタッチします。
不正解 バケットポリシーはS3リソースへのアクセス権限を制御する機能ですが、今回の問題はアクセス権限の問題ではありません。ブラウザがJavaScriptファイルやWebフォントをブロックしているのは、異なるオリジン間でのリソース共有に対するブラウザのセキュリティポリシー(Same-Origin Policy)によるものです。バケットポリシーではCORS(Cross-Origin Resource Sharing)の問題を解決できません。
全体的な説明
問われている要件
- 複数の子会社のWebアプリケーションを異なるS3バケットでホスト
- 共通のJavaScriptファイルとWebフォントを中央のS3バケットに集約
- ブラウザによるJavaScriptファイルとWebフォントのブロックを解決
- 異なるオリジン間での安全なリソース共有を実現
前提知識
Same-Origin Policy(同一オリジンポリシー) Webブラウザが実装するセキュリティ機能で、異なるオリジン間でのリソースアクセスを制限します。
オリジンの定義 オリジンは以下の3つの要素で構成されます:
- プロトコル(http/https)
- ドメイン名(example.com)
- ポート番号(80/443)
CORS(Cross-Origin Resource Sharing) 異なるオリジン間でのリソース共有を安全に行うためのW3C標準です。
CORSの仕組み
- ブラウザがクロスオリジンリクエストを検出
- プリフライトリクエスト(OPTIONS)を送信(複雑なリクエストの場合)
- サーバーがCORSヘッダーでレスポンス
- ブラウザがレスポンスを検証してリクエストを許可/拒否
S3のCORS設定 S3バケットレベルで設定するJSON形式の設定ファイルです:
CORS設定の主要要素
- AllowedOrigins:許可するオリジンのリスト
- AllowedMethods:許可するHTTPメソッド(GET、POST等)
- AllowedHeaders:許可するリクエストヘッダー
- ExposedHeaders:ブラウザに公開するレスポンスヘッダー
- MaxAgeSeconds:プリフライトレスポンスのキャッシュ時間
典型的なCORS設定例
[
{
"AllowedOrigins": ["https://www.example.com"],
"AllowedMethods": ["GET", "HEAD"],
"AllowedHeaders": ["*"],
"MaxAgeSeconds": 3000
}
]Web開発におけるCORSの重要性
- 静的リソース(CSS、JS、フォント)の共有
- API呼び出しの許可
- 第三者サービスとの統合
- マイクロサービス間の通信
CloudFrontとCORSの関係 CloudFrontを使用する場合の追加考慮事項:
- オリジンリクエストヘッダーの転送設定
- CORSヘッダーのキャッシュ動作
- 複数オリジンでの設定管理
その他のクロスオリジン対策
- JSONP(古い手法、セキュリティリスクあり)
- プロキシサーバー経由のアクセス
- サーバーサイドでのリソース取得
解くための考え方
問題の症状(ブラウザによるJavaScriptファイルとWebフォントのブロック)から、これが典型的なCORSの問題であることが分かります。 異なるオリジン(子会社のWebアプリケーション)から中央のS3バケットのリソースにアクセスしようとしているためです。
CORSは、このような異なるオリジン間でのリソース共有を安全に行うために設計された標準的なメカニズムです。 S3バケットにCORS設定を追加することで、指定したオリジンからのアクセスを許可できます。
他の選択肢(バケットポリシー、アクセスポイント、Content-MD5)は、アクセス制御やデータ整合性に関する機能であり、ブラウザのセキュリティポリシーによる制限を解除することはできません。
参考資料
問題文:
開発者は AWS CodePipeline を使ってアプリケーションのデプロイ環境を構築しています。コードは GitHub リポジトリに保存されており、リポジトリパッケージの単体テストが新しいデプロイ環境で実行されることを確認したいと考えています。ソースプロバイダーとして GitHub が既に設定されています。 この要件を満たすために最適な手順を選択してください。
選択肢:
A. AWS CodeCommit プロジェクトを作成し、リポジトリのパッケージのビルドとテストを buildspec に追加します。
B. ソースステージにアクションを追加し、新しいプロジェクトをアクションプロバイダーとして指定し、ビルドアーティファクトを入力に使用します。
C. AWS CodeBuild プロジェクトを作成し、リポジトリのパッケージのビルドとテストを buildspec に追加します。
D. ソースステージの後に新しいステージを追加し、新しいアクションをアクションプロバイダーとして指定、入力アーティファクトをソースアーティファクトに設定します。
E. AWS CodeDeploy プロジェクトを作成し、リポジトリのパッケージのビルドとテストを buildspec に追加します。
正解: C, D
A. AWS CodeCommit プロジェクトを作成し、リポジトリのパッケージのビルドとテストを buildspec に追加します。
不正解 CodeCommitはAWSのマネージド型Git リポジトリサービスであり、ソースコード管理が目的です。ビルドやテストの実行機能は提供していません。さらに、問題文でGitHubが既にソースプロバイダーとして設定されているため、CodeCommitを追加で使用する必要はありません。
B. ソースステージにアクションを追加し、新しいプロジェクトをアクションプロバイダーとして指定し、ビルドアーティファクトを入力に使用します。
不正解 ソースステージはソースコードの取得を担当するステージであり、ここにビルドやテストのアクションを追加することは適切ではありません。また、ビルドアーティファクトを入力として使用するという説明も不正確です。ソースステージではソースアーティファクトが出力されるため、ビルドアーティファクトはまだ存在しません。
C. AWS CodeBuild プロジェクトを作成し、リポジトリのパッケージのビルドとテストを buildspec に追加します。
正解 CodeBuildはソースコードのコンパイル、テスト実行、デプロイ可能なアーティファクトの作成を行うサービスです。buildspecファイルにビルドコマンドとテストコマンドを記述することで、GitHubリポジトリのコードに対して単体テストを実行できます。これは要件を満たす適切なソリューションです。
D. ソースステージの後に新しいステージを追加し、新しいアクションをアクションプロバイダーとして指定、入力アーティファクトをソースアーティファクトに設定します。
正解 CodePipelineでは機能ごとにステージを分割することがベストプラクティスです。ソースステージの後にビルドステージを追加し、CodeBuildをアクションプロバイダーとして設定することで、ソースアーティファクトを入力としてビルドとテストを実行できます。この構成により要件が満たされます。
E. AWS CodeDeploy プロジェクトを作成し、リポジトリのパッケージのビルドとテストを buildspec に追加します。
不正解 CodeDeployはアプリケーションのデプロイを自動化するサービスであり、ビルドやテストの実行には使用されません。またCodeDeployではbuildspecファイルは使用せず、代わりにappspecファイルを使用してデプロイ手順を定義します。
全体的な説明
問われている要件
- AWS CodePipelineを使用してアプリケーションのデプロイ環境を構築する
- GitHubリポジトリに保存されているソースコードを使用する
- 新しいデプロイ環境でリポジトリパッケージの単体テストを実行する
- GitHubがソースプロバイダーとして既に設定されている状態からの対応
前提知識
AWS CodePipeline 継続的インテグレーション・継続的デリバリー(CI/CD)を実現するフルマネージドサービスです。ソフトウェアのリリースプロセスを自動化し、コードの変更から本番環境へのデプロイまでを一連のステージとして管理します。
パイプラインの基本構成
- ソースステージ:ソースコードリポジトリからコードを取得
- ビルドステージ:コードのコンパイル、テスト実行、アーティファクト作成
- デプロイステージ:アプリケーションを対象環境にデプロイ
AWS CodeBuild ソースコードをコンパイルし、テストを実行し、デプロイ可能なソフトウェアパッケージを作成するフルマネージドビルドサービスです。
buildspecファイル CodeBuildプロジェクトでビルド手順を定義するYAML形式の設定ファイルです。以下のフェーズで構成されます:
- install:ビルド環境のセットアップ
- pre_build:ビルド前の準備作業
- build:実際のビルドとテスト実行
- post_build:ビルド後の後処理
アーティファクト パイプラインの各ステージ間で受け渡される成果物です。ソースステージではソースアーティファクト、ビルドステージではビルドアーティファクトが生成されます。
その他の関連サービス
- CodeCommit:AWSのマネージド型Gitリポジトリサービス
- CodeDeploy:アプリケーションのデプロイ自動化サービス
解くための考え方
単体テストを実行するためには、CodeBuildサービスを使用する必要があります。 buildspecファイルにテストコマンドを記述することで、GitHubのソースコードに対してテストが実行されます。
パイプライン構成では、ソースステージの後にビルドステージを追加します。 ビルドステージではCodeBuildをアクションプロバイダーとして設定し、ソースアーティファクトを入力として使用します。 これにより機能ごとに明確に分離された、保守性の高いパイプラインが構築できます。
参考資料
問題文:
ある企業が外部ユーザーを対象としたセッションを開催することになり、参考資料を 7 日間共有したいと考えています。参考資料は、企業が管理する Amazon S3 バケットに保存されています。 この外部ユーザーと参考資料を共有する最も安全な方法を選択してください。
選択肢:
A. S3 バケットへの読み取り専用アクセス権を持つ一時的な IAM ユーザーを作成し、アクセスキーを外部ユーザーと共有します。7 日後に認証情報を失効させます。
B. 参考資料を Amazon WorkDocs フォルダに移動します。WorkDocs フォルダのリンクを外部ユーザーと共有します。
C. S3 バケットへの読み取り専用アクセス権を持つロールを作成し、このロールの Amazon リソースネーム (ARN) を外部ユーザーと共有します。
D. S3 署名付き URL を使用して、参考資料を外部ユーザーと共有します。有効期限を 7 日間に設定します。
正解: D
A. S3 バケットへの読み取り専用アクセス権を持つ一時的な IAM ユーザーを作成し、アクセスキーを外部ユーザーと共有します。7 日後に認証情報を失効させます。
不正解 IAMユーザーのアクセスキーを外部ユーザーと共有することは、重大なセキュリティリスクを伴います。アクセスキーが漏洩や悪用された場合、企業のAWSリソースに不正アクセスされる可能性があります。また、外部ユーザーがアクセスキーを適切に管理する保証がなく、メール、チャット、その他の通信手段で認証情報が露出するリスクがあります。さらに、IAMユーザーの管理、認証情報の配布、削除などの運用負荷も発生し、AWSセキュリティベストプラクティスにも反しています。
B. 参考資料を Amazon WorkDocs フォルダに移動します。WorkDocs フォルダのリンクを外部ユーザーと共有します。
不正解 Amazon WorkDocsはファイル共有とコラボレーション機能を提供するサービスですが、この選択肢には複数の問題があります。まず、既存のS3バケットからWorkDocsへのファイル移動という余分な作業が必要です。また、WorkDocsは通常、組織内でのファイル共有に使用されるサービスであり、短期間の外部ユーザー共有には適していません。WorkDocsのセットアップ、ユーザー管理、ライセンス費用なども考慮する必要があり、シンプルな7日間のファイル共有という要件に対して過剰なソリューションです。
C. S3 バケットへの読み取り専用アクセス権を持つロールを作成し、このロールの Amazon リソースネーム (ARN) を外部ユーザーと共有します。
不正解 IAMロールのARNを外部ユーザーと共有しても、外部ユーザーがそのロールを直接使用することはできません。IAMロールは、AWSサービス間や信頼されたエンティティ間でのアクセス権限委譲に使用される仕組みです。外部ユーザーがロールを引き受けるためには、適切な信頼関係の設定、STSトークンの取得、AWS CLIやSDKの使用などの複雑な手順が必要になります。また、このような設定は外部ユーザーに過度な技術的知識を要求し、一般的なファイル共有の用途には適していません。
D. S3 署名付き URL を使用して、参考資料を外部ユーザーと共有します。有効期限を 7 日間に設定します。
正解 S3署名付きURLは、外部ユーザーとファイルを安全に共有するための最適な方法です。署名付きURLは、指定した有効期限内でのみ特定のS3オブジェクトへのアクセスを許可する一時的なURLです。7日間の有効期限を設定することで、期限後は自動的にアクセスが無効になります。外部ユーザーはAWSアカウントやIAM認証情報を必要とせず、通常のWebブラウザでファイルにアクセスできます。また、最小権限の原則に従い、特定のファイルのみへのアクセスに限定できるため、セキュリティリスクを最小化できます。
全体的な説明
問われている要件
- 外部ユーザーを対象とした7日間限定のファイル共有
- 企業管理のAmazon S3バケットに保存された参考資料の共有
- セキュリティを確保した安全な共有方法の選択
- 期限付きアクセス制御の実装
前提知識
S3署名付きURL(Pre-signed URL)
S3署名付きURLは、S3オブジェクトへの一時的なアクセスを提供する仕組みです:
- 時限付きアクセス: 指定した有効期限後に自動的にアクセス無効化
- 署名による認証: AWS認証情報を使用してURLに署名を付与
- 特定オブジェクト限定: 個別のファイルのみへのアクセス許可
- HTTPメソッド制限: GET、PUT、DELETEなど特定の操作のみ許可可能
- IPアドレス制限: 特定のIPアドレスからのアクセスのみ許可可能
署名付きURLの生成方法
署名付きURLは以下の要素で構成されます:
- バケット名とオブジェクトキー: アクセス対象の特定
- AWS認証情報: URL署名のためのアクセスキーとシークレットキー
- 有効期限: URLの有効期限(最大7日間)
- 署名: リクエストの真正性を証明するハッシュ値
- 追加パラメータ: Content-Type、Content-Dispositionなどの制御
セキュリティ上の利点
署名付きURLの使用により以下のセキュリティメリットが得られます:
- 認証情報の非共有: IAMユーザーやアクセスキーの共有が不要
- 最小権限: 特定のファイルのみへのアクセス制限
- 時間制限: 自動的な期限切れによるアクセス無効化
- 監査証跡: CloudTrailでのアクセスログ記録
- 取り消し不可: 一度生成したURLは変更不可(セキュリティ特性)
外部ユーザー共有のベストプラクティス
外部ユーザーとのファイル共有では以下を考慮します:
- 必要最小限のアクセス: 特定ファイルのみへの読み取り専用アクセス
- 適切な有効期限: 業務要件に応じた期間設定
- HTTPSの使用: データ転送時の暗号化
- アクセス監視: CloudWatchやCloudTrailでのアクセス監視
- ファイル暗号化: S3での保存時暗号化の有効化
解くための考え方
外部ユーザーへの安全なファイル共有には、署名付きURLが最適な選択です。
この方法により、外部ユーザーはAWSアカウントや複雑な認証情報を必要とせず、通常のWebブラウザで簡単にファイルにアクセスできます。7日間の有効期限設定により、期限後の自動アクセス無効化が保証されます。
署名付きURLは、企業のセキュリティを維持しながら、外部ユーザーに必要最小限のアクセス権限を提供する理想的なソリューションです。設定も簡単で、運用負荷が少なく、AWSセキュリティベストプラクティスに完全に準拠しています。
他の選択肢は、セキュリティリスク、運用負荷、または過度な複雑性といった問題を抱えており、シンプルな外部ファイル共有という要件には適していません。
参考資料
筆者のUdemy講師ページはこちら。
スポンサーリンク
以下スポンサーリンクです。
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。