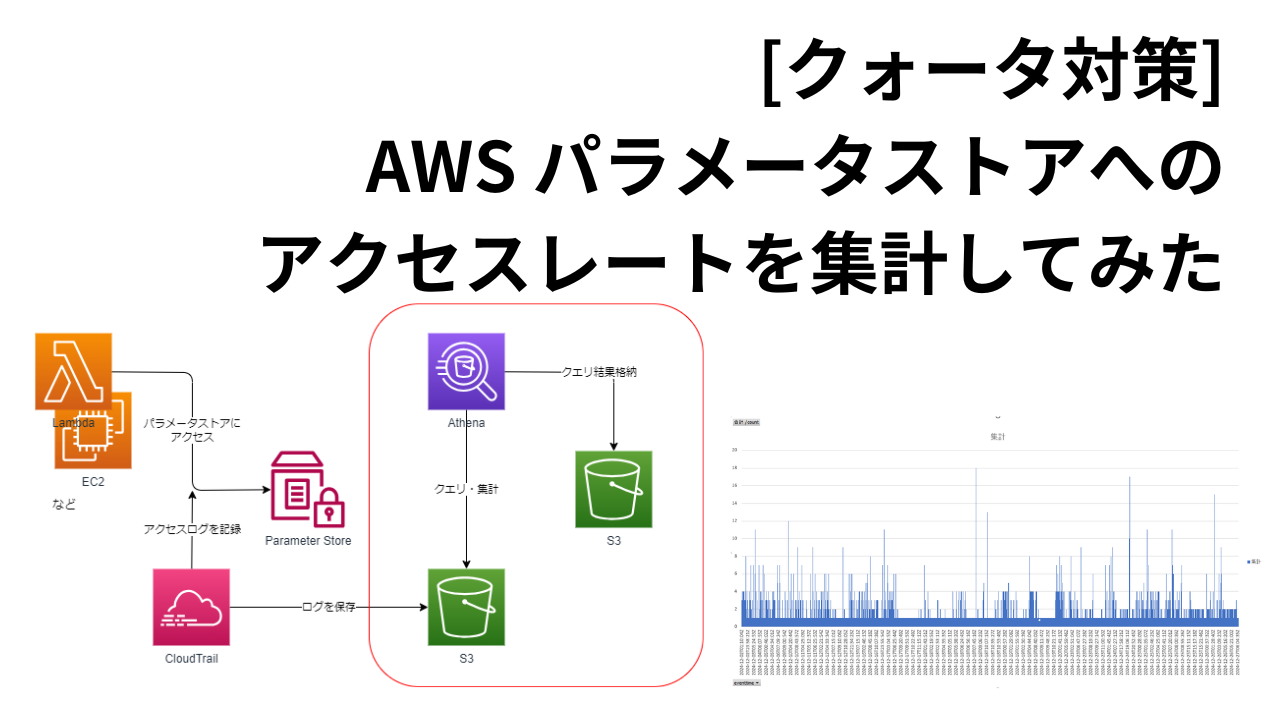
AWSシステムを運用する際、たびたび問題になるクォータ問題があります。クォータとはAWSを使う上で定められている上限です。パラメータストアは環境依存パラメータを保存するのに非常に便利ですが、クォータには注意する必要があります。
今回は「今のシステムはパラメータストアのクォータ(秒間呼出し制限)は大丈夫なのか?」を確認する方法をまとめます。
はじめに:パラメータストアのクォータと注意点
Systems Managerのリファレンスによるとスループットに関するクォータは以下の通りです。デフォルトである無課金状態では「標準スループット」です。
- 標準スループット: 40 (次のAPIアクションで共有:
GetParameter、GetParameters、GetParametersByPath) - スループットの向上: 10,000 (GetParameter)
- スループットの向上: 1,000 (GetParameters)
- 高スループット: 100 (GetParametersByPath)
上記の値は秒間です。標準スループットモードでは秒間40回に制限されます。
また、通常スループットではおおよそ70~80ms程度のレイテンシーのようです。

このレイテンシーが遅いか早いかはシステムの特性によるとは思いますが、DynamoDBからのGetItemが一桁ミリ秒なのでAWS関連サービスの中では遅めなようです。

パラメータストアへのアクセス頻度を調べる方法
パラメータストアへのアクセス頻度を表示するダッシュボードやメトリクスはありません。そのため工夫する必要があります。パラメータストアへのアクセスログがCloudTrailに記録されるのでこれを利用します。
CloudTrailのログを集計する手順は以下のClassmethod様の記事が大変参考になりました。本記事で紹介する手順においても大変参考にさせていただいています。
ざっくり申し上げると、CloudTrailに記録されているパラメータストアのアクセスログをAthenaで集計するという手法です。
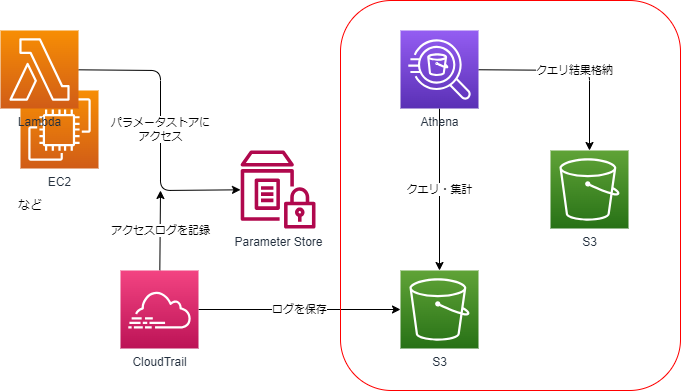
CloudTrailのログはS3に保存されるので、それをAthenaで集計していきます。
パラメータストアへのアクセス頻度を調べる詳細手順
Athenaでテーブルを作る
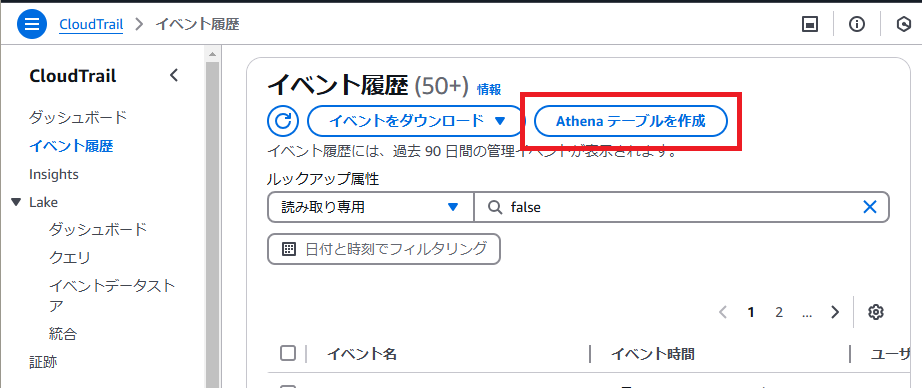
AthenaでCREATE TABLEを行ってテーブルを作成します。ただ、いきなりSQLを作成するのはハードルが高いと思います。CloudTrailの画面でAthenaテーブルを作成するためのSQLを生成することができます。
マネジメントコンソールでCloudTrail画面に遷移して「Athenaテーブルを作成」を押下しましょう。
するとSQLが生成されます。CloudTrailのログが格納されているS3バケットを選択すればSQLの中にS3を埋め込んでくれるので選択しましょう。
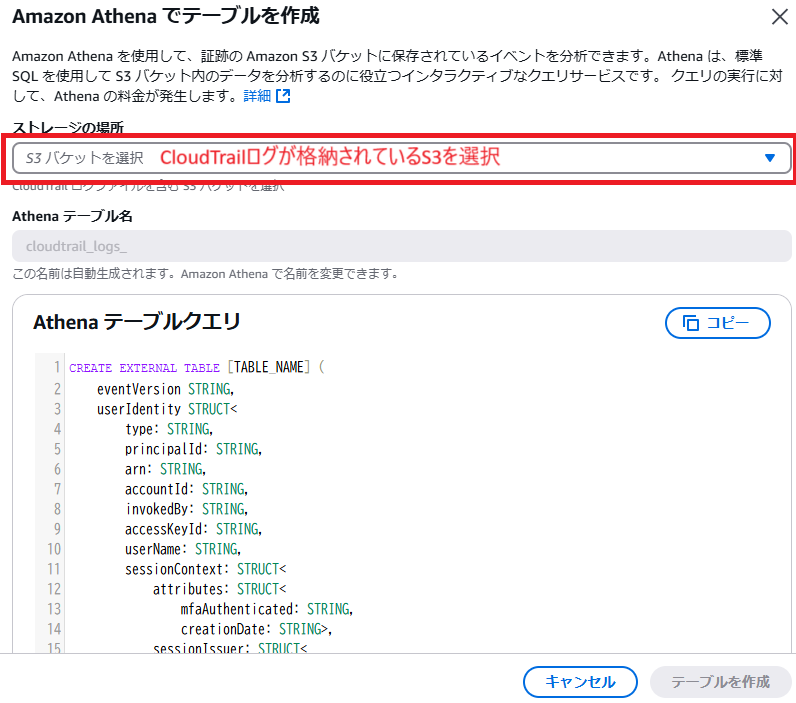
以下のようなSQLが出力されます。すべてのCloudTrailログをスキャンしてもよいのであれば「テーブルを作成」で問題ありませんが、対象を絞りたい場合は下部のLOCATION(58行目)でクエリ範囲をプレフックスで絞りましょう。編集する場合はいったんSQLをメモ帳などにコピーします。
CREATE EXTERNAL TABLE 【CloudTrailバケット名】 (
eventVersion STRING,
userIdentity STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
invokedBy: STRING,
accessKeyId: STRING,
userName: STRING,
sessionContext: STRUCT<
attributes: STRUCT<
mfaAuthenticated: STRING,
creationDate: STRING>,
sessionIssuer: STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
username: STRING>,
ec2RoleDelivery: STRING,
webIdFederationData: STRUCT<
federatedProvider: STRING,
attributes: MAP<STRING,STRING>>>>,
eventTime STRING,
eventSource STRING,
eventName STRING,
awsRegion STRING,
sourceIpAddress STRING,
userAgent STRING,
errorCode STRING,
errorMessage STRING,
requestParameters STRING,
responseElements STRING,
additionalEventData STRING,
requestId STRING,
eventId STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING>>,
eventType STRING,
apiVersion STRING,
readOnly STRING,
recipientAccountId STRING,
serviceEventDetails STRING,
sharedEventID STRING,
vpcEndpointId STRING,
tlsDetails STRUCT<
tlsVersion: STRING,
cipherSuite: STRING,
clientProvidedHostHeader: STRING>
)
COMMENT 'CloudTrail table for 【CloudTrailバケット名】 bucket'
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://【CloudTrailバケット名】/AWSLogs/123456789012/CloudTrail/'
TBLPROPERTIES ('classification'='cloudtrail');ここでは2024/12の東京リージョンで絞るために以下のようにしました。環境ごとにバケットのプレフィックス構造が変わっているかもしれないのでバケットを見に行ってください。
LOCATION 's3://【CloudTrailバケット名】/AWSLogs/123456789012/CloudTrail/ap-northeast-1/2024/12/'マネジメントコンソールでAthenaの画面に行ってクエリエディタを開きます。
SQLを実行する前に設定タブで「クエリの結果の場所」を設定しておかないとエラーになる可能性があります。適当に設定しておきましょう。
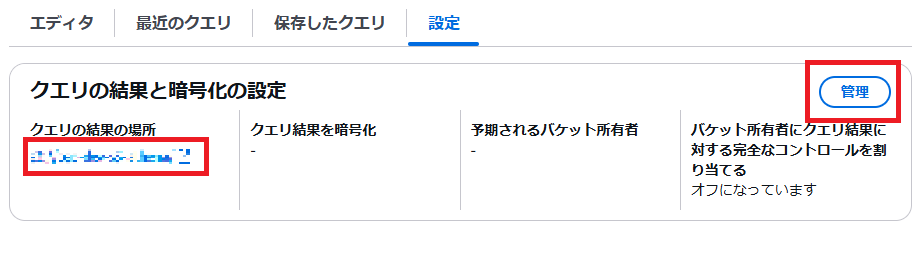
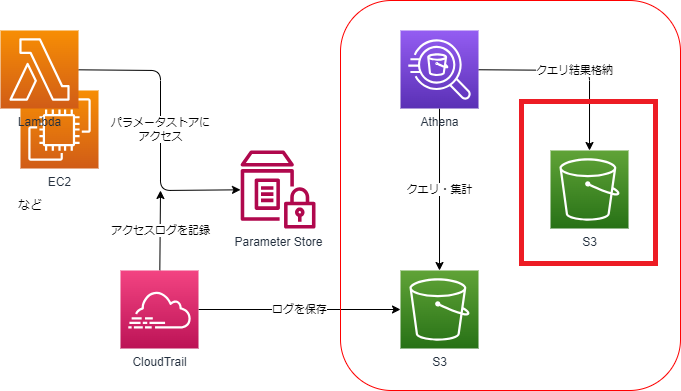
この設定はアーキテクチャ上では以下の赤枠のS3バケット(クエリ結果を格納するS3)を指定しています。
先ほど作成したSQLを実行します。
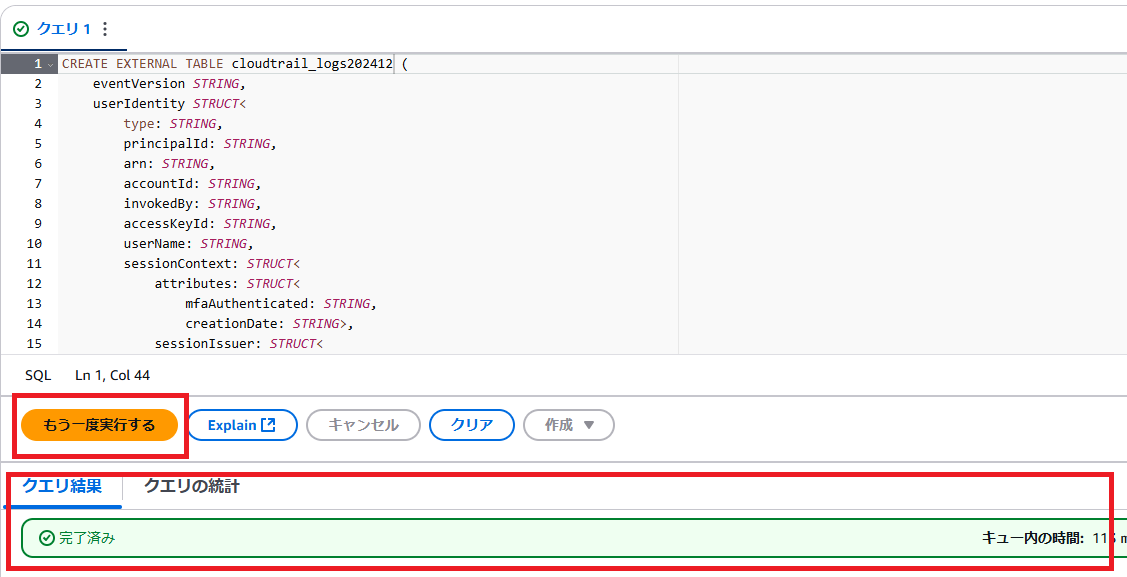
完了済みと出れば成功です。
AthenaでSELECTクエリを実行する
先ほどはテーブルを作成した状態なので、ここではテーブルに対してSELECTします。クォータではGetParameter、GetParameters、GetParametersByPathの合計で毎秒40回なので以下のようなSQLになります。
【テーブル名】はデフォルトではCloudTrailログのバケット名になっているかと思います。
SELECT eventtime
FROM "default"."【テーブル名(デフォルトはCloudTrailのS3)】"
WHERE eventsource = 'ssm.amazonaws.com'
AND eventname IN ('GetParameter', 'GetParameters', 'GetParametersByPath')上記のSQLではssm(パラメータストア)に対して’GetParameter’, ‘GetParameters’, ‘GetParametersByPath’を行った時刻を出力するような構文になっています。
完了すると以下のような画面になります。結果をダウンロードしましょう。
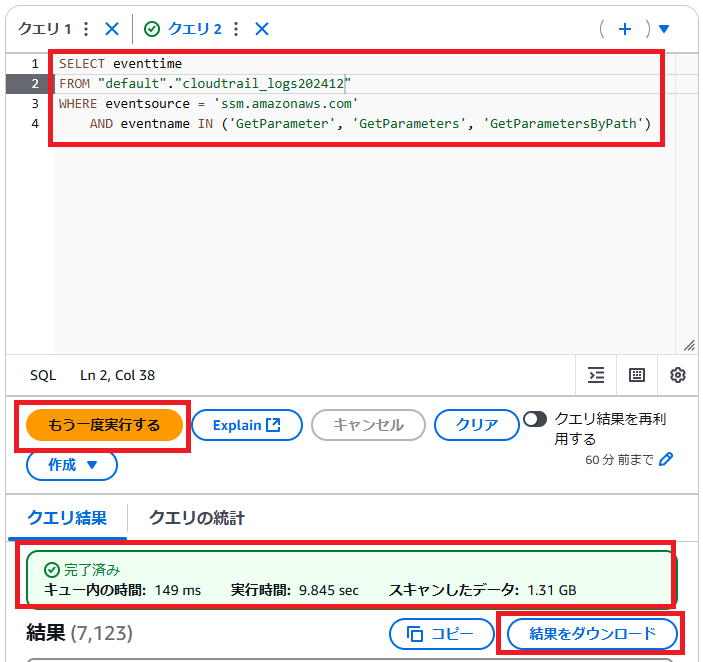
CSVがDLできるはずです。
Excelのピボットグラフで集計する
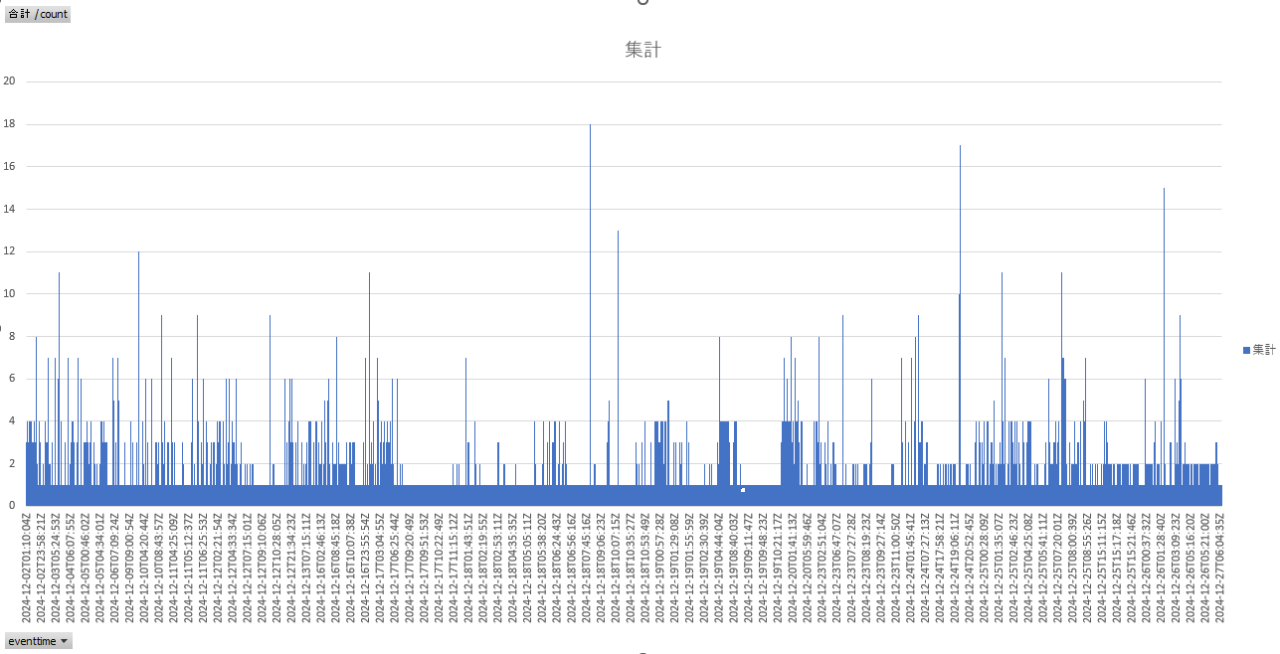
ダウンロードしたCSVにはパラメータストアへアクセスした日時が秒ごとに記載されています。
ここでダウンロードしたCSVをExcelで少し編集します。ピボットグラフを使用するため、保存したい場合は.xlsx形式に変換してください。そのままのcsvはeventtimeが記載されていますが、その隣の列にcountを追加してすべて1を入れます。
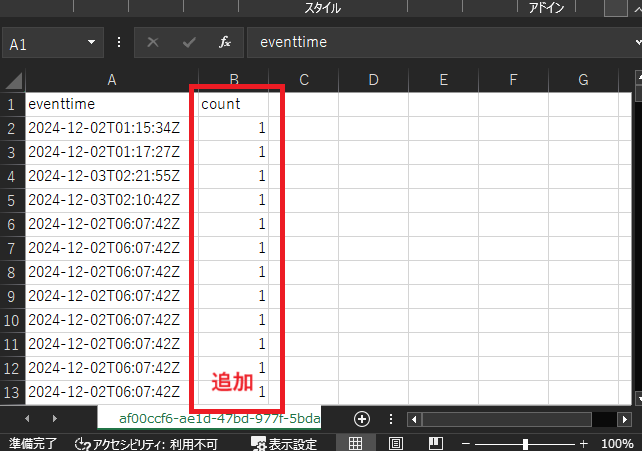
A列とB列を選択を選択した状態で「ピボットグラフ」を挿入します。
「eventtime」と「count」にチェックを入れるとグラフが生成されます。
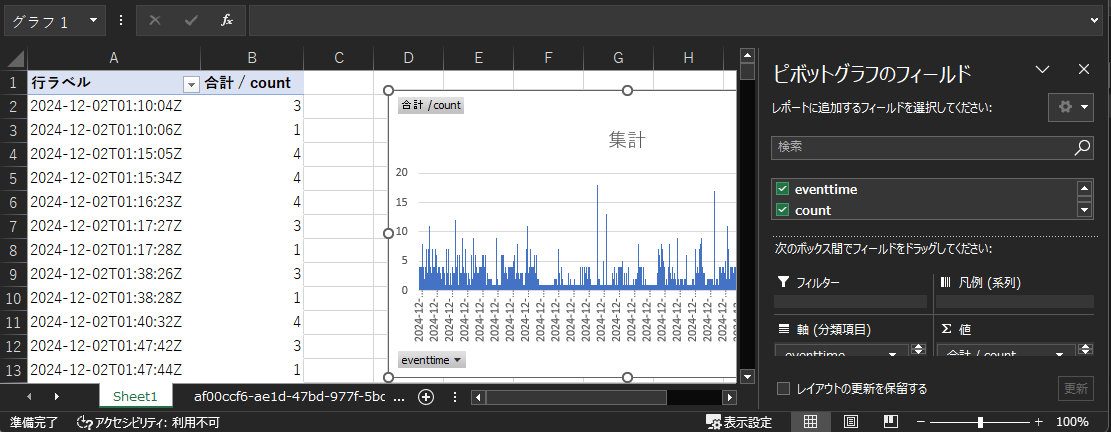
このグラフを確認することでパラメータストアへのアクセスを秒単位に時系列で確認できました。私の環境ではパラメータストアへのアクセスは最大秒間18回程度でした。
本番環境では定期的に確認してチューニングするのが望ましいですね。
まとめ
AWSパラメータストアはシステムの運用において非常に便利なツールですが、クォータの制約によりパフォーマンスが低下するリスクがあります。本記事では、CloudTrailとAthenaを利用してパラメータストアへのアクセス頻度を可視化し、その結果をExcelで分析する方法を紹介しました。
この手法を活用することで、以下のメリットが得られます:
- クォータ対策:アクセス頻度を把握し、クォータの限界を超えるリスクを回避できます。
- パフォーマンス最適化:アクセス頻度のピークを特定し、必要に応じてスループットの向上やキャッシュの導入を検討できます。
- データドリブンな判断:可視化されたデータを基に、システム運用の改善点を明確にできます。
本番環境ではアクセス頻度の定期的な確認と、必要に応じたチューニングが重要です。本記事がシステム運用に役立つと幸いです。
この記事がお役に立ちましたら、コーヒー1杯分(300円)の応援をいただけると嬉しいです。いただいた支援は、より良い記事作成のための時間確保や情報収集に活用させていただきます。

システムエンジニア
AWSを中心としたクラウド案件に携わっています。
IoTシステムのバックエンド開発、Datadogを用いた監視開発など経験があります。
IT資格マニアでいろいろ取得しています。
AWS認定:SAP, DOP, SAA, DVA, SOA, CLF
Azure認定:AZ-104, AZ-300
ITIL Foundation
Oracle Master Bronze (DBA)
Oracle Master Silver (SQL)
Oracle Java Silver SE
■略歴
理系の大学院を卒業
IT企業に就職
AWSのシステム導入のプロジェクトを担当